ВЫБРАТЬ ИЗ в запросе 1С 8.3

ВЫБРАТЬ
В предложении ВЫБРАТЬ указываются поля выборки запроса. Полей может быть несколько, между собой они разделяются запятой.
Можно использовать литералы примитивных типов:

С числами можно выполнять арифметические операции прямо в полях выборки:

Также можно использовать унарный минус:

Можно складывать строки, но только если их длина меньше 1024 символов:

Псевдонимы полей
Псевдоним поля выборки в запросе указывается после ключевого слова КАК. При этом можно вообще не задавать псевдоним для поля, можно указать после ключевого слова КАК, а можно просто через пробел, без указания ключевого слова КАК:

Псевдоним поля должен удовлетворять правилам наименования переменных в 1С. Например, в псевдониме нельзя использовать пробел, он не может начинаться с цифры и т.п. В рамках одного запроса нельзя использовать одинаковые псевдонимы, иначе будет ошибка «Повторяющийся псевдоним».
В предложении ИЗ указываются таблицы-источники, из которых выполняется выборка. Например, в конфигурации есть справочник «КамерыХранения». Для выборки полей из данного справочника нужно выполнить следующий запрос:
Запросы 1С:Предприятие 8. Основы работы
Этой статьей мы начинаем цикл, посвященный работе с запросами в системе 1С:Предприятие версии 8.1 и выше.
Запрос — это мощнейший инструмент, служащий для быстрого (по сравнению со всеми другими способами) получения и обработки данных, содержащихся в различных объектах информационной базы 1С.
Создание запроса
Запрос создается как отдельный объект, который имеет обязательный атрибут Текст, куда собственно и помещается сам запрос. Кроме этого, в запрос могут быть переданы различные параметры, необходимые для его выполнения. После того, как текст и параметры запроса заполнены, запрос необходимо выполнить и поместить результат выполнения в выборку или таблицу значений. Выглядит это все примерно так:
//Создаем запрос
Запрос = новый Запрос ;
Основы языка запросов 1С
Простейшие и наиболее часто применяемые запросы служат для получения данных из какого-то источника. Источником могут являться практически все объекты, содержащие какие-либо данные: справочники, документы, регистры, константы, перечисления, планы видов характеристик и т.д.
Из этих объектов с помощью запроса можно получать значения реквизитов, табличных частей, реквизитов табличных частей, изменений, ресурсов и т.д.
Для получения текста запроса часто бывает удобно пользоваться Конструктором запроса. Он вызывается при щелчке правой кнопкой в любом месте программного модуля.
Например, если необходимо получить значения всех реквизитов справочника Контрагенты, то запрос будет выглядеть так:
Если же нужно получить только отдельные реквизиты, то — так:
Для получения такого текста запроса в Конструкторе запроса нужно выбрать соответствующие поля на вкладке Таблицы и поля.
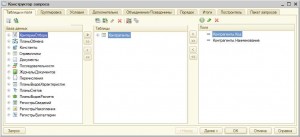 Выбираемым в запросе элементам и источникам можно присваивать псевдонимы и использовать их в дальнейшем как в самом запросе, так и при работе с результатом. Кроме того, в запросе могут присутствовать поля с заранее определенным конкретным значением, или с рассчитываемым значением:
Выбираемым в запросе элементам и источникам можно присваивать псевдонимы и использовать их в дальнейшем как в самом запросе, так и при работе с результатом. Кроме того, в запросе могут присутствовать поля с заранее определенным конкретным значением, или с рассчитываемым значением:
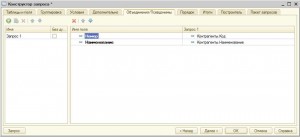
Для задания псевдонимов служит вкладка Объединения/Псевдонимы в Конструкторе запросов.
 А поле с фиксированным или рассчитываемым значением создается вручную на вкладке Таблицы и поля, в колонке Поля.
А поле с фиксированным или рассчитываемым значением создается вручную на вкладке Таблицы и поля, в колонке Поля.
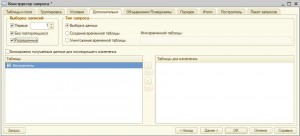
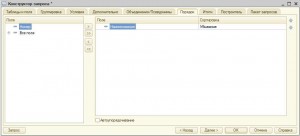
Все выбранные элементы можно упорядочивать как в прямом, так и в обратном порядке. При этом можно выбирать один или несколько полей для упорядочивания. Вместе с упорядочиванием иногда бывает полезно выбрать только один или несколько первых элементов.
Можно ограничить выборку элементов теми, на которые пользователь имеет права доступа. Или убрать из результата запроса повторяющиеся строки.
Порядок задается на вкладке Порядок в Конструкторе запросов, количество выбираемых элементов, параметры разрешенности и повторяемости — на вкладке Дополнительно.
 Продолжение следует…
Продолжение следует…
Конструктор запросов 1С — обучение на примерах
Урок 4. Объединение запросов 1с при помощи конструктора
Задача: выбрать запросом все проведенные документы Поступление товаров и услуг и Возврат товаров поставщику за указанный период.
Новые вкладки: Объединения/Псевдонимы.
Теоретическая часть урока №4
Конструктор запросов 1с позволяет создавать объединения запросов. При их помощи можно последовательно выводить в результат данные, полученные из нескольких запросов, не используя при этом связи. Единственной условие для объединения — одинаковый набор полей в каждом отдельном запросе.
В конструкторе перейдем на вкладку Объединения/Псевдонимы. Она предназначена для создания объединений запросов и для задания псевдонимов для полей запроса. Псевдонимы полей нужны, если вас не устраивают стандартные имена полей базы данных. Если поле запроса состоит только из поля таблицы базы данных, то псевдоним для него не обязателен. Если же при создании поля вы использовали функции языка запросов, то псевдоним для такого поля обязателен. Для таких полей конструктор запросов создает стандартные псевдонимы Поле1…ПолеN, эти псевдонимы можно заменить на те, которые удобны для вас.

Рассмотрим разделы вкладки Объединения /Псевдонимы:





Практическая часть урока №4
Разберем решение задачи, приведенной в начале урока. Напомню условия:
Задача: выбрать запросом все проведенные документы Поступление товаров и услуг и Возврат товаров поставщику за указанный период.
В итоге у нас получится запрос со следующим текстом:
Также прочтите статьи о языке запросов 1с 8:
Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Базы данных
SQL псевдонимы
В этом учебном материале вы узнаете, как использовать SQL псевдонимы (временные имена для столбцов или таблиц) с синтаксисом и примерами.
Описание
SQL ALIASES можно использовать для создания временного имени для столбцов или таблиц.
Синтаксис
Синтаксис псевдонима столбца в SQL:
Или
Синтаксис псевдонима таблицы в SQL:
Параметры или аргументы
Примечание
Обычно псевдонимы используются для облегчения чтения заголовков столбцов в наборе результатов. Чаще всего вы будете использовать псевдоним столбца при использовании в запросе статистической функции, такой как MIN, MAX, AVG, SUM или COUNT.
Давайте рассмотрим пример использования псевдонима имени столбца в SQL.
В этом примере у нас есть таблица employees со следующими данными:
| employee_number | first_name | last_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Justin | Bieber | 62000 | 500 |
| 1002 | Selena | Gomez | 57500 | 500 |
| 1003 | Mila | Kunis | 71000 | 501 |
| 1004 | Tom | Cruise | 42000 | 501 |
Продемонстрируем, как создать псевдоним столбца. Введите следующий SQL оператор:
Будет выбрано 2 записи. Вот результаты, которые вы получите:
| dept_id | total |
|---|---|
| 500 | 2 |
| 501 | 2 |
В этом примере мы для COUNT(*) использовали псевдоним total. В результате итоговое значение будет отображаться в качестве заголовка для второго столбца при возврате набора результатов. Поскольку в нашем псевдониме не было пробелов, нам не нужно заключать псевдоним в кавычки.
Теперь давайте перепишем наш запрос, чтобы включить пробел в псевдоним столбца:
Будет выбрано 2 записи. Вот результаты, которые вы получите:
| dept_id | total employees |
|---|---|
| 500 | 2 |
| 501 | 2 |
В этом примере мы добавили в поле COUNT(*) псевдоним «total employees», поэтому он станет заголовком для второго столбца в нашем наборе результатов. Поскольку в псевдониме этого столбца есть пробелы, «total employees» должны быть заключены в кавычки в операторе SQL.
Пример псевдоним для имени таблицы
Когда вы создаете псевдоним таблицы, это происходит потому, что вы планируете перечислить одно и то же имя таблицы более одного раза в FROM, или вы хотите сократить имя таблицы, чтобы сделать SQL оператор короче и проще для чтения.
Давайте рассмотрим пример псевдонима имени таблицы в SQL.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
И таблица с именем categories со следующими данными:
| category_id | category_name |
|---|---|
| 25 | Deli |
| 50 | Produce |
| 75 | Bakery |
| 100 | General Merchandise |
| 125 | Technology |
Теперь давайте объединим эти 2 таблицы и псевдонимы каждого из имен таблиц. Введите следующий SQL оператор:
Что такое псевдонимы в языке запросов
Войдите как ученик, чтобы получить доступ к материалам школы
Язык запросов 1С 8.3 для начинающих программистов: соединения
Автор уроков и преподаватель школы: Владимир Милькин
Соединения в запросах
Соединения используются для того, чтобы сопоставить строки одной таблицы строкам другой таблицы.
Для того, чтобы осознать необходимость соединений давайте решим следующую задачу.
У нас в базе есть справочник Клиенты:


И справочник Ассоциации:

Наша задача вывести любимые ассоциации клиентов, основываясь на цвете.
Для Андрея вообще нет подходящей ассоциации, так его любимый цвет красный, а ассоциаций красного цвета в базе нет.
Будем решать задачу постепенно.
Сначала запросим всех клиентов и их любимые цвета :

Затем запросим все ассоциации и их цвета :

Теперь нам каким-то образом следует совместить первую и вторую таблицу. Чтобы это сделать запросим информацию сразу из двух таблиц. Для этого перечислим обе таблицы в секции ИЗ через запятую. Вы читаете ознакомительную версию урока, полноценные уроки находятся здесь. А в секции ВЫБРАТЬ укажем поля из обеих таблиц:
Если мы попробуем выполнить этот запрос, то получим ошибку:

Причина ошибки в том, что поле Наименование присутствует сразу в обеих таблицах (Клиенты и Ассоциации) и система просто не знает поле из какой именно таблицы имеется в виду.
Чтобы устранять подобные неоднозначности при выборке из более чем одной таблицы принято указывать полные названия полей. Полное название поля включает в себя полное имя таблицы (например, Справочник.Клиенты) и имя самого поля (например, Наименование).
Таким образом полное название поля Наименование из таблицы Клиенты будет Справочник.Клиенты.Наименование.
А полное названия поля Наименование из таблицы Ассоциации будет Справочник.Ассоциации.Наименование.
Перекрёстное соединение
Перепишем предыдущий запрос с полными именами полей:

Только что мы произвели перекрёстное соединение двух таблиц. Обратите внимание на то, каким образом сформировался результат:

Внутреннее соединение
Очевидно, что результат перекрестного соединения двух таблиц не есть решение нашей задачи. Нам нужны не все записи из перекрёстного соединения, а только те у которых поля ЛюбимыйЦвет и Цвет имеют одинаковое значение:

Чтобы получить эти записи добавим к предыдущему запросу секцию ГДЕ:


Есть ещё один вариант написания того же самого внутреннего соединения :
Сравните этот и предыдущий запрос. Они совершенно одинаковы с точки зрения платформы, просто имеют разный синтаксис. И этот и предыдущий запросы содержат внутреннее соединение таблицы Клиенты с таблицей Ассоциации по полям ЛюбимыйЦвет и Цвет соответственно.
Левое внешнее соединение
Обратите внимание на то, что в результат внутреннего соединения не попал Андрей. А всё потому, что его любимый цвет красный, а красных ассоциаций у нас в базе нет вовсе.
Получается, что для Андрея с его красным цветом просто не нашлось пары из таблицы ассоциаций.
Перепишем запрос так, чтобы в результат попадали в том числе те записи из первой таблицы, для которых не нашлось ни одной пары из второй таблицы (в данном случае Андрей):

Такое соединение называется левым внешним соединением (слово внешнее можно опускать для простоты).


Правое внешнее соединение
Но давайте снова вернёмся к внутреннему соединению:
Обратите внимание на то, что результат внутреннего соединения не содержит ассоциацию белый снег, так как не нашлось ни одного клиента, у которого любимым цветом был бы белый.
Перепишем запрос так, чтобы в результат попадали в том числе те записи из второй таблицы, для которых не нашлась ни одной пары из первой таблицы (в данном случае белый снег):

Такое соединение называется правым внешним соединением (слово внешнее можно опускать для простоты).


Полное соединение
А что если нам нужно, чтобы в результат запроса попадали помимо внутреннего соединения Андрей и Снег одновременно?
Для этого потребуется совместить результаты левого и правого соединений. Такой вид соединения уже придуман и называется полным соединением:

Результат полного соединения представляет из себя: все записи из внутреннего соединения ПЛЮС все записи из первой таблицы, не попавшие во внутреннее соединение (для которых не нашлось пары) ПЛЮС все записи из второй таблицы, не попавшие во внутреннее соединение (для которых не нашлось пары).


Псевдонимы таблиц
Согласитесь, что все запросы, которые мы писали в этом уроке выглядят довольно громоздко. Это связано с тем, что мы вынуждены указывать полные имена полей, чтобы избежать возникновение неоднозначности.
А чтобы результат запроса был ещё нагляднее добавим псевдонимы полей, которые мы уже рассматривали на одном из прошлых уроков:

Обработка NULL
Присмотритесь к результатам последнего запроса (как впрочем и многих предыдущих на этом уроке).
Чему равны значения полей Ассоциация и ЕёЦвет для первой строчки? А что вы скажете насчет полей Клиент и ЕгоЦвет для последней строки?
Они равны NULL, которое как мы уже знаем означает отсутствие какого либо значения:

Поэтому обязательной считается обработка значений NULL всегда, когда они могут возникнуть.
Под обработкой подразумевается то, что мы должны сказать в нашем запросе, что если одно из полей будет равно NULL, то в это поле следует подставить какое-то другое значение.
В данном случае для полей Клиент и Ассоциация в случае обнаружения NULL мы будем подставлять пустую строку «».
А вот поля ЕгоЦвет и ЕёЦвет являются ссылками на элементы справочника Цвета, поэтому в них можно подставлять только значения являющиеся ссылками указанных типов. Каждый ссылочный тип (например, Справочник или Документ) имеет предопределенный элемент ПустаяСсылка. Чтобы указать его значение в запросе воспользуемся функцией ЗНАЧЕНИЕ.
Для определения того, что в поле попало NULL будем использовать уже знакомую нам по прошлым урокам функцию ЕСТЬNULL:

С виду (из консоли запросов) результат не изменился. Мы по-прежнему видим пустые поля. Но это только потому, что строковые представления у NULL и у пустых полей всех типов совпадают и равны пустой строке.
На самом же деле эти пустые поля уже не есть NULL (отсутствие значения), теперь в них появились значения (пустые), с которыми уже можно работать (совершать операции).
Соединение более двух таблиц
Можно последовательно соединять сколько угодно таблиц.
Предположим нужно решить следующую задачу. Вы читаете ознакомительную версию урока, полноценные уроки находятся здесь. Вывести все возможные варианты клиентов и их любимых ассоциаций и их любимых продуктов исходя из их любимого цвета.
Для этого последовательно соединим по цвету таблицу Клиенты с таблицей Ассоциации, а затем (получившийся результат) с таблицей Еда:



