Что такое пуш передача домена
Так что такое «пуш» домена?
Пуш (от англ. push) — это перемещение домена с одного аккаунта на другой, в пределах текущего Регистратора или системы…
Одновременно с пушем может происходить смена Владельца домена (необязательно).
Какие основные отличия, пуша домена от трансфера?
1. Пуш домена… может происходить только в пределах одного Регистратора, в то время как при трансфере происходит смена Регистратора
2. Пуш домена… происходит мгновенно (или с незначительными временными задержками), в то время как трансфер длиться обычно 5-7 дней
3. Пуш домена… может быть осуществлен практически для любой доменной зоны, в то время, как операцию трансфера можно проводить лишь для основных зон
4. Пуш домена… происходит бесплатно2 и срок регистрации домена не изменяется. В случае трансфера, новый Регистратор взимает плату (при этом обычно домен продляется на год вперед)3
Примечания:
Как правило, пуш домена происходит бесплатно, однако некоторые Регистраторы, взимают за него отдельную плату.
В некоторых случаях, при трансфере не происходит продление домена (например, если домен зарегистрирован на максимально возможный срок, то происходит просто смена Регистратора, и пр..).
Подпишись на этот крутой блог по RSS
Похожие записи
Комментарии
Большое спасибо за инфу. Нашёл у вас определение термина “пуш”. На самом деле смена владельца домена – процедура всегда немного нервная (для меня).
Исчерпывающее руководство по использованию HTTP/2 Server Push

Привет! Меня зовут Александр, и я – фронтенд-разработчик в компании Badoo. Пожалуй, одной из самых обсуждаемых тем в мире фронтенда в последние несколько лет является протокол HTTP/2. И не зря – ведь переход на него открывает перед разработчиками много возможностей по ускорению и оптимизации сайтов. Этот пост посвящён как раз одной из таких возможностей – Server Push. Cтатья Джереми Вагнера показалась мне интересной, и поэтому делюсь полезной информацией с вами.
Не так давно возможности разработчиков, ориентированных на производительность, заметно изменились. И появление HTTP/2 стало, возможно, самым значительным изменением. HTTP/2 больше не является фичей, которую мы с нетерпением ждём, — он уже существует (и успешно помогает справляться с проблемами вроде блокировки начала очереди и несжатых заголовков, существующими в HTTP/1), а «в комплекте» с ним идёт Server Push!
Эта технология позволяет отправлять пользователям ресурсы сайта, прежде чем они их попросят. Это элегантный способ добиться преимущества в производительности методов оптимизации HTTP/1, таких как, например, встраивание, и избежать недостатков, связанных с этой практикой.
Из этой статьи вы узнаете всё о Server Push – от принципа её работы до решаемых ею проблем: как её использовать, как определить, работает ли она и каково её влияние на производительность, и многое другое.
Что такое Server Push?
Доступ к веб-сайтам всегда осуществляется по шаблону «Запрос – ответ»: пользователь отправляет запрос на удалённый сервер, который с некоторой задержкой присылает ответ с запрошенным контентом.
В первоначальном запросе к веб-серверу обычно запрашивается HTML-документ. Сервер отвечает запрошенным HTML-ресурсом. Полученный HTML-документ анализируется браузером, в результате чего из него извлекаются ссылки на другие ресурсы, такие как таблицы стилей, скрипты и изображения. После их обнаружения браузер отправляет отдельный запрос для каждого ресурса и получает соответствующие ответы.

Проблема этого механизма заключается в том, что он заставляет пользователя ждать, пока браузер обнаружит и извлечёт необходимые ресурсы уже после того, как HTML- документ загружен. Это задерживает рендеринг и увеличивает время загрузки.
У нас есть решение этой проблемы. Server Push позволяет серверу превентивно «проталкивать» ресурсы веб-сайта клиенту, прежде чем пользователь запросит их явно. То есть мы можем заранее отправить то, что, как мы знаем, понадобится пользователю для запрашиваемой страницы.
Как видите, использование Server Push позволяет уменьшить время рендеринга страницы. А также – решить некоторые другие проблемы, особенно в части фронтенд-разработки.
Какие проблемы решает Server Push?
Уменьшение количества обращений к серверу для получения критически важного контента – лишь одна из проблем, решаемых Server Push, но далеко не единственная.
Так, Server Push является подходящей альтернативой ряда антипаттернов оптимизации HTTP/1, таких как встраивание CSS и JavaScript непосредственно в HTML или использование data URI scheme для внедрения бинарных данных в CSS и HTML. Эти методы имеют ценность при оптимизации HTTP/1, поскольку они уменьшают субъективное время загрузки страницы. Это означает, что, хотя общее время загрузки страницы не может быть уменьшено, страница будет загружаться быстрее для пользователя.
Похоже, это хороший способ решить проблему, не так ли? Для HTTP/1, где у вас нет другого выбора, – конечно! Но обратной стороной медали является то, что встроенное содержимое не может быть эффективно кешировано. Если ресурс (например, таблица стилей или файл JavaScript) остаётся внешним и модульным, его можно кешировать намного эффективнее. И когда пользователь переходит на следующую страницу, требующую этот же ресурс, его можно вытащить из кеша, устранив необходимость в дополнительных запросах к серверу.
Однако, когда мы встраиваем контент, он не имеет собственного контекста кеширования – его контекст кеширования совпадает с ресурсом, в который он встроен. Возьмём, например, HTML-документ со встроенным CSS. Если политика кеширования HTML-документа заставляет всегда загружать свежую копию разметки с сервера, то встроенный CSS никогда не будет кешироваться сам по себе. Конечно, документ, в который он встроен, может быть кеширован, но другие страницы, содержащие этот же дублированный CSS, будут загружаться повторно. И даже если политика кеширования менее строгая, документы HTML обычно имеют ограниченный срок хранения. Однако это компромисс, на который мы готовы пойти при оптимизации HTTP/1. Это действительно работает, и это довольно эффективно для посещающих сайт впервые. А ведь первое впечатление часто является определяющим.
Это те проблемы, которыми и занимается Server Push. Когда вы проталкиваете ресурсы, вы получаете те же практические преимущества, что и при встраивании, но ещё сохраняете свои ресурсы во внешних файлах, которые имеют собственную политику кеширования. Правда, в этом процессе есть один нюанс, который будет рассмотрен в конце статьи. А пока давайте продолжим.
Я достаточно подробно объяснил, почему вам следует рассмотреть возможность использования Server Push, а также обозначил круг проблем, которые эта технология решает как для пользователя, так и для разработчика. Теперь поговорим о том, как она используется.
Как использовать Server Push?
Использование Server Push обычно предполагает применение HTTP-заголовка Link в следующем формате:
Установка заголовка Link в настройках веб-сервера
На данный момент Nginx не поддерживает HTTP/2 Server Push, и до сих пор в списке изменений программного обеспечения не указано, что его поддержка была добавлена. Это может измениться по мере развития реализации Nginx HTTP/2.
Установка заголовка Link в бэкенд-коде
Другой способ установить заголовок Link – использование серверного языка. Это поможет, если вы не можете изменить настройки веб-сервера. Ниже приведён пример использования PHP-функции header для установки заголовка Link :
Если ваше приложение находится на виртуальном хостинге, где нет возможности изменить настройки сервера, тогда этот метод – то, что вам нужно. Вы должны иметь возможность установить этот заголовок на любом серверном языке. Просто убедитесь, что сделали это, прежде чем приступать к отправке тела ответа, во избежание возможных ошибок времени выполнения.
Проталкивание нескольких ресурсов
Все наши примеры иллюстрируют проталкивание одного ресурса. Но что, если вы хотите протолкнуть несколько? Сделать это было бы разумно, не так ли? В конце концов, сеть состоит не только из таблиц стилей. Вот как это можно сделать:
Этот синтаксис более удобен, чем объединение нескольких значений, разделённых запятыми, а работает не хуже. Единственным минусом является его недостаточная компактность, но удобство стоит нескольких лишних байтов, передаваемых по сети.
Теперь, когда вы знаете, как проталкивать ресурсы, давайте посмотрим, как определить, работает ли это.
Как определить, работает ли Server Push?
Это зависит от браузера. В последних версиях Google Chrome проталкиваемый ресурс можно выявить по столбцу Initiator вкладки Network в окне Developer Tools.
Кроме того, если на этой же вкладке навести курсор мыши на столбец Waterfall, мы получим подробную информацию о времени проталкивания ресурса:
Инструменты Mozilla Firefox менее наглядны в определении проталкиваемых ресурсов. Статус таких ресурсов в сетевой утилите инструментов разработчика браузера помечается серой точкой.
Если вы ищете точный способ определить, был ли ресурс протолкнут сервером, вы можете использовать клиент командной строки nghttp для проверки ответа от HTTP/2-сервера, например:
Таким образом вы получите краткую информацию о ресурсах, участвующих в транзакции. Протолкнутые ресурсы будут помечены звёздочкой, например:
Теперь, когда мы можем определить, когда проталкиваются ресурсы, давайте посмотрим, как Server Push влияет на производительность реального веб-сайта.
Замер производительности Server Push
Измерение эффекта любого повышения производительности требует хорошего инструмента тестирования. Sitespeed.io – отличный инструмент, доступный через npm; он автоматизирует тестирование страниц и собирает ценные показатели производительности.
Итак, мы выбрали подходящий инструмент – переходим к методологии тестирования.
Методология тестирования
Я хотел измерить влияние Server Push на производительность веб-сайта. Чтобы результаты были релевантными, мне нужно было установить точки сравнения по шести отдельным сценариям. Эти сценарии разделены на два аспекта: используется HTTP/2 или HTTP/1. На серверах HTTP/2 мы измеряем влияние Server Push по ряду показателей; на серверах HTTP/1 – хотим увидеть, как встраивание ресурсов влияет на производительность по тем же показателям, поскольку встраивание должно обладать примерно теми же преимуществами, которые обеспечивает Server Push.
Для каждого сценарии я инициировал тестирование с помощью следующей команды:
Если вы хотите узнать, что делает эта команда, вы можете посмотреть документацию. Если вкратце, она проверяет домашнюю страницу моего сайта по адресу https://jeremywagner.me со следующими условиями:
Для каждого теста были собраны и отображены три показателя:
First Paint Time
Это момент времени, когда страница начала отображаться в браузере. Чтобы казалось, что страница загружается быстро, этот показатель нужно уменьшать как можно больше.
DOMContentLoaded Time
Это время, когда HTML документ был полностью загружен и разобран. Синхронный JavaScript-код блокирует парсер и увеличивает этот показатель. Использование атрибута async в тегах
Способы взаимодействия сервисов друг с другом. Пулинг/пуш. Достоинства/недостатки. Выбор

Курьер доставил заказ. По смене статуса заказа надо уведомить заинтересованные стороны об этих событиях.
Клиент отправляет сообщение в чат поддержки. Нужно уведомить сервисы поддержки о поступивших данных от клиента.
Построение отчёта завершено. Ожидающий отчёт пользователь может его загрузить. Надо его уведомить об этом.
Знакомые/типовые ситуации. Одному сервису надо уведомить другой (другие) о происшедших событиях.
Давайте немного усложним:
Какие способы уведомления есть?
Активность со стороны сервера
Это, в общем-то, типовое решение. Сервер держит список заинтересованных сторон. По мере появления событий выполняет HTTP-запросы к клиентам.
Подвариант этого решения: Websocket. Сервер отправляет события в сокеты всем подписанным сторонам.
Повторы, обработка ошибок
Рано или поздно любой TCP/HTTP-канал сталкивается с недоступностью другой стороны. Что делать после возникновения ошибки? Повторять запросы? Что делать с вновь поступающими запросами? Ждать, пока успешно выполнятся предыдущие?
Рассмотрим виды ошибок:
Получив неустранимую ошибку, клиент может только записать её в лог. То есть, если полная остановка доставки сообщений не приемлема, то, получив неустранимую ошибку, типовым решением будет считать, что «уведомление доставлено», и переходить к доставке следующих уведомлений. Вероятно, это единственный нормальный путь.
Идя по этому пути, надо постоянно и внимательно следить за мониторами таких ошибок. Анализировать трафик на тему «почему возникла неустранимая ошибка?» и «можно ли жить дальше с этой ошибкой».
Но это не самая большая проблема.
Более интересными являются проблемы:
500-е ошибки
Мы выполняем запрос-передачу данных для сервера X. Происходит 500-я ошибка. Что это?
Возможны два варианта:
Сервис-приёмник данных по какой-то причине именно сейчас не работает (перегружается, переключается БД итп). В этом случае повтор запроса в дальнейшем приведёт нас к успеху.
В сервисе допущена ошибка, приводящая к 500. В этом случае, сколько бы повторов мы ни сделали, до исправления кода в приёмнике ситуация не изменится.
То есть, по повторяемости запросов ошибки у нас делятся на три вида:
Те, которым повтор поможет (сетевые, устранимые 500-ки).
Те, которым повтор не поможет, но выглядят как те, которым поможет (неустранимые 500-ки).
Те, которым повтор не поможет (например 40x-ки).
Разрабатывая политику повторов, помимо указанной проблемы, имеем ещё множество других проблем:
Как часто повторять запросы?
Не будем ли мы «укладывать» внешний сервис, повторяя запросы?
Не будем ли сами «укладываться», если одна из внешних систем по какой-то причине имеет некорректный TCP-стек ( iptables DROP )?
Если посмотреть на систему повторов запросов, то обнаружится, что практически в каждом случае она выбирается индивидуально.
Если сервис, генерирующий событие, и занимается доставкой его до заинтересованных сторон, то имеем
минимальный лаг доставки
минимальная нагрузка на хранилище сообщений;
необходимость повторов в случае неуспеха доставок
необходимость ведения реестра, кому что доставлено и кому что нужно доставить
двусмысленность некоторых ошибок: непонятно, можно (нужно) ли повторять, или нет
система повторов может быть причиной DDoS для клиентских сервисов.
Также есть некоторое количество организационных минусов:
После того, как клиент прекратил де-факто работу (тут два варианта: сервера выключены, сервера не выключены), система продолжает доставлять ему уведомления.
Вебсокет в режиме клиент-сервер
Часть описанных проблем решает постоянное соединение, инициируемое клиентом. Однако именно часть.
Пулинг
Достоинства пулинга
Максимально быстрое восстановление работоспособности после факапов.
Недостатки пулинга
минимальный лаг доставки сообщений равен интервалу пулинга, который обычно выбирается ненулевым
множество сервисов пулящих один создают существенно бОльшую нагрузку, нежели случай с активным сервисом. Сервисы, для которых нет сейчас никаких сообщений, всё равно создают нагрузку на подсистему доставки сообщений.
Ещё один неочевидный, организационный недостаток пулинга: часто способ получения новой порции данных связан со структурой хранения данных.
отсутствие двусмысленности, описанной выше
наиболее быстрое восстановление работоспособности после сбоя
максимальная независимость от сетевого стека TCP на клиенте
нет необходимости хранить/майнтенить список клиентов.
Лаг доставки
Как правило, запросы для пулинга формулируются как «есть ли данные для меня; если есть, то какие?». Такие запросы (в случае, если они некорректно спроектированы) зачастую имеют следующие проблемы:
при перегрузках количество данных в ответе может расти, или время выполнения запроса ухудшаться.
В случае, если получение очередной порции данных сопровождается простой выборкой из BTREE индекса, то и ответ на вопрос «есть ли данные?», как правило, сравнительно бесплатен. Об индексах поговорим ниже.
А сейчас давайте рассмотрим алгоритм работы традиционного пулера.
Обрабатываем полученные данные
Пауза соответствующая интервалу
Если рассматривать этот алгоритм, то видим, что переменная index и есть то, что связывает нас со структурой хранения данных.
Такой алгоритм, как правило, используют новички и. приводят себя к трудноустранимой проблеме: запросы с большими значениями index сделать индексируемыми крайне сложно. Почти невозможно.
Почему разработчик попадает в такую ситуацию? Потому что проектирует БД и API отдельно друг от друга. А нужно посмотреть на все компоненты в целом и на влияние их друг на друга.
Проблема состоит в том, что в БД, как правило, данные хранятся в виде плоских таблиц. Когда мы получаем очередную порцию данных с одними и теми же условиями фильтрации, то приходится делать что-то вроде следующего:
Как сделать план независящим от положения смещения? Использовать вместо смещения выборку из индекса:
Первичная инициализация. index := 0
Выполняем запрос limit данных, передавая в запрос index
Пауза, соответствующая интервалу
В системе с такой архитектурой, как правило, уже нет существенных препятствий к снижению интервала до минимальных значений (вплоть до нуля).
Но давайте ещё порефлексируем над архитектурой. Что плохого в ней?
Алгоритм привязан к структуре данных
Выполняется практически полностью на стороне клиента
Вследствие предыдущей проблемы сложно, например, централизованно модифицировать его на иную работу после факапов/проблем.
Пользователь может сам подставлять в index произвольные значения. Иногда это может быть нежелательно или приводить к багам, которые разработчику сервера сложно понять.
Давайте ещё раз модифицируем алгоритм. Заменим index на state и управлять им будем с сервера:
Выполняем запрос limit данных, передавая в запрос значение state
Что мы получили? Гибкость.
Переменная state определяется только сервером и не обязана быть привязанной к числу смещения. При желании в этой переменной можем хранить JSON со многими полями.
Если в переменной state хранится не только позиция окна, а, например, и значения фильтров и криптоподпись, то эту переменную имеет смысл называть курсором. Переименуем переменную ещё раз и избавимся от постоянных задержек:
Если данные были, перейти к шагу 2
Таким образом, получаем алгоритм, минимизирующий число запросов, если данных для клиента нет, и запрашивающий данные с максимальной производительностью, если таковые имеются.
Рекомендации по работе с курсорами:
Поскольку хранением курсора между запросами озадачен клиент, то имеет смысл хранить в курсоре и версию ПО сервера. В этом случае можно написать дополнительный код, обеспечивающий обратную совместимость (конвертацию форматов курсоров).
Во избежание трудных багов весь набор фильтров, полученных в первом запросе, хорошо хранить в курсоре и в последующих запросах игнорировать параметры фильтрации не из курсора. Перфекционисты могут даже выделить инициализацию курсора в отдельный запрос.
Во избежание введения в соблазн пользователей использовать в своём коде какие-то данные из курсора, лучше не использовать человекочитаемую строку в значении курсора. JSON, пропущенный через base64-кодирование (и криптоподписанный) подходит идеально.
Пример. Изменение алгоритма после сбоя.
Любая система гарантированной доставки сообщений из точки А в точку B в случае факапов будет накапливать пул недоставленных сообщений. После восстановления работоспособности будет период времени, когда приёмник данных сильно отстаёт от источника.
В случае, если порядок доставки сообщений возможно нарушать, то обработчик запроса с курсором может (продетектировав значительное отставание) начать возвращать два потока данных: тот, на который подписан клиент, и тот же, но с более актуальными данными.
Таким образом, пользователи, запросившие отчёт прямо во время факапа, продолжат его ждать (и дождутся). А пользователи, запросившие отчёт после факапа, получат его с небольшой задержкой.
Пример алгоритма серверной стороны, включающего второй поток в случае сильного отставания, приведён на рисунке.
Пофантазировав, схему можно дополнить не одним, а несколькими фолбеками.
Курсорная репликация
Описанные курсоры можно использовать для репликации данных с сервиса на сервис.
Часто один сервис должен иметь у себя кеш/реплику части данных другого сервиса. При этом требований синхронности к этой реплике нет. Поменялись данные в сервисе A. Они должны максимально быстро поменяться и в сервисе B.
Например, мы хотим реплицировать табицу пользователей с сервиса на сервис.
Для такой репликации можно использовать что-то готовое из инструментария баз данных, а можно сделать небольшой «велосипед». Предположим, что пользователи хранятся в БД PostgreSQL. Тогда делаем следующее:
модифицируем изменяющие пользователей запросы, чтобы на каждое изменение записи пользователя значение lsn устанавливалось бы из растущей последовательности
строим по полю lsn (уникальный) BTREE индекс.
В этом случае обновление записи пользователя будет выглядеть примерно так:
А запрос для работы курсора будет выглядеть как-то так:
Итоги
Почти во всех случаях, когда применяется активная система уведомлений зависимых сервисов, её можно заменить описанной курсорной подпиской.
При этом проблемы доступности клиентов, настроек, работоспособности TCP-стека останутся у клиентов
Максимально быстрое и простое восстановление после простоя/сбоев. Отсутствие двусмысленностей в кодах ошибок.
Проще и быстрее: что такое безбумажные операции с доменами и как их подключить
Но есть способ сэкономить время и деньги — воспользоваться безбумажной передачей доменов. Что это такое? Рассказываем.
Что такое безбумажные операции?
Безбумажные операции с доменами — услуга передачи доменного имени.Заявление на совершение безбумажных операций подписывается бесплатно и только один раз, после чего можно совершать важные действия с доменными именами в режиме онлайн — прямо из дома, без посещения офиса REG.RU.
Так, после подключения безбумажных операций, чтобы передать домен другому администратору (владельцу), достаточно подтвердить операцию на сайте REG.RU даже без авторизации — по почте или SMS ;).
Услугу достаточно подключить один раз и дальше пользоваться ей бессрочно.
Что входит в безбумажные операции
Это безопасно?
Да, безбумажные операции с доменами безопасны для клиентов: — email и номер телефона, которые указываются при оформлении, затем нигде не отображаются;
— сотрудники взаимодействуют с данными клиентов лишь на этапе оформления, в дальнейшем все операции, где необходимы персональные данные, клиенты выполняют самостоятельно;
— для безопасной работы с услугой можете настроить двухфакторную аутентификацию для почты, которую будете использовать для подтверждения операции.
Кому подойдёт услуга?
Безбумажные операции с доменами в первую очередь будут полезны тем, кто работает с большим количеством доменных имён, например, домейнерам, предпринимателям, у которых несколько проектов. Также безбумажные операции удобны тем, кто физически находится далеко от офисов компании — жителям небольших городов, гражданам иностранных государств — им больше не нужно будет заверять документы у нотариуса при каждой операции, а затем отправлять почтой или курьерской службой, где не исключены сбои в доставке.
Тысячи пользователей уже выбрали удобный формат работы: актуальная статистика
В 2015 году клиенты REG.RU совершили 4 300 безбумажных операций с доменами, в 2020-м — уже 170 600. Так, за последние 3 года количество таких операций выросло в 10 раз.
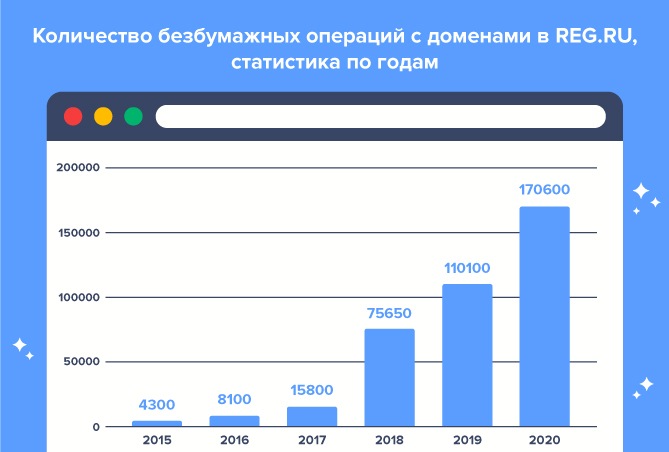
Основной рост количества безбумажных операций начался в 2018 году. Тогда услуга активно продвигалась в рамках снижения бумажного документооборота. В 2020 году высокий спрос был связан с пандемией коронавируса: несмотря на многие ограничения люди могли свободно продолжать работы, связанные с передачей или продажей доменов.
Всего с момента запуска услуги клиенты провели 431 150 операций с доменами.
Как оформить безбумажные операции?
Есть два способа оформления процедуры. Процедура проста: вы можете прийти в офис REG.RU или передать заполненное завявление почтой. При личном посещении у вас примут заявление, проверят данные, сделают скан паспорта и отправят документы в наш центральный офис за пару рабочий дней. Также если у вас есть электронная подпись, то можете отправить заявление через службу поддержки.
Расскажите в комментариях успели ли вы попробовать безбумажные операции? Какие впечатления от услуги у вас остались? А если вы ещё не подписали соглашение для безбумажных операций — самое время сделать это сейчас. Это удобно и отвечает современным трендам, когда многие вопросы можно решить удалённо и без бюрократии. Управляйте услугами в онлайн-режиме и оптимизируйте бизнес-процессы вместе с нами!



