Распределенные базы данных
Распределённые базы данных (РБД) — совокупность логически взаимосвязанных баз данных, распределённых в компьютерной сети.
Основные принципы
РБД состоит из набора узлов, связанных коммуникационной сетью, в которой:
а)каждый узел — это полноценная СУБД сама по себе;
б)узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле.
Каждый узел сам по себе является системой базы данных. Любой пользователь может выполнить операции над данными на своём локальном узле точно так же, как если бы этот узел вовсе не входил в распределённую систему. Распределённую систему баз данных можно рассматривать как партнёрство между отдельными локальными СУБД на отдельных локальных узлах.
Фундаментальный принцип создания распределённых баз данных («правило 0»): Для пользователя распределённая система должна выглядеть так же, как нераспределённая система.
Фундаментальный принцип имеет следствием определённые дополнительные правила или цели. Таких целей всего двенадцать:
1.Локальная независимость. Узлы в распределённой системе должны быть независимы, или автономны. Локальная независимость означает, что все операции на узле контролируются этим узлом.
2.Отсутствие опоры на центральный узел. Локальная независимость предполагает, что все узлы в распределённой системе должны рассматриваться как равные. Поэтому не должно быть никаких обращений к «центральному» или «главному» узлу с целью получения некоторого централизованного сервиса.
3.Непрерывное функционирование. Распределённые системы должны предоставлять более высокую степень надёжности и доступности.
4.Независимость от расположения. Пользователи не должны знать, где именно данные хранятся физически и должны поступать так, как если бы все данные хранились на их собственном локальном узле.
5.Независимость от фрагментации. Система поддерживает независимость от фрагментации, если данная переменная-отношение может быть разделена на части или фрагменты при организации её физического хранения. В этом случае данные могут храниться в том месте, где они чаще всего используются, что позволяет достичь локализации большинства операций и уменьшения сетевого трафика.
6.Независимость от репликации. Система поддерживает репликацию данных, если данная хранимая переменная-отношение — или в общем случае данный фрагмент данной хранимой переменной-отношения — может быть представлена несколькими отдельными копиями или репликами, которые хранятся на нескольких отдельных узлах.
7.Обработка распределённых запросов. Суть в том, что для запроса может потребоваться обращение к нескольким узлам. В такой системе может быть много возможных способов пересылки данных, позволяющих выполнить рассматриваемый запрос.
8.Управление распределёнными транзакциями. Существует 2 главных аспекта управления транзакциями: управление восстановлением и управление параллельностью обработки. Что касается управления восстановлением, то чтобы обеспечить атомарность транзакции в распределённой среде, система должна гарантировать, что все множество относящихся к данной транзакции агентов (агент — процесс, который выполняется для данной транзакции на отдельном узле) или зафиксировало свои результаты, или выполнило откат. Что касается управления параллельностью, то оно в большинстве распределённых систем базируется на механизме блокирования, точно так, как и в нераспределённых системах.
9.Аппаратная независимость. Желательно иметь возможность запускать одну и ту же СУБД на различных аппаратных платформах и, более того, добиться, чтобы различные машины участвовали в работе распределённой системы как равноправные партнёры.
10.Независимость от операционной системы. Возможность функционирования СУБД под различными операционными системами.
11.Независимость от сети. Возможность поддерживать много принципиально различных узлов, отличающихся оборудованием и операционными системами, а также ряд типов различных коммуникационных сетей.
12.Независимость от типа СУБД. Необходимо, чтобы экземпляры СУБД на различных узлах все вместе поддерживали один и тот же интерфейс, и совсем необязательно, чтобы это были копии одной и той же версии СУБД.
Типы Распределённых Баз Данных
1) Распределённые Базы Данных
3) Федеративные базы данных. В отличие от мультибаз не располагают глобальной схемой, к которой обращаются все приложения. Вместо этого поддерживается локальная схема импорта-экспорта данных. На каждом узле поддерживается частичная глобальная схема, описывающая информацию тех удалённых источников, данные с которых необходимы для функционирования.
Направления развития баз данных
14.2. Распределенные базы данных
База данных – интегрированная совокупность данных, с которой работают много пользователей. Изложение всех предыдущих разделов предполагало единую базу данных, размещаемую на одном компьютере. Напомним основные принципы, положенные в основу теории баз данных:
Заметим, что базы данных появились в период господства больших ЭВМ. База данных велась на одной ЭВМ, все пользователи работали именно на ЭВМ (возможные режимы работы описаны в «Различные архитектурные решения, используемые при реализации многопользовательских СУБД. Краткий обзор СУБД» ). Других вариантов использования вычислительной техники в то время просто не существовало. Если проанализировать работу пользователей с данными в компаниях, организациях, предприятиях в «докомпьютерное» время, то нетрудно заметить, что на отдельных участках пользователи работали со «своими» данными (осуществляли сбор определенных данных, их хранение, обработку, передачу обработанных данных на другие участки или уровни управления).
Развитие вычислительных компьютерных сетей обусловило новые возможности в организации и ведении баз данных, позволяющие каждому пользователю иметь на своем компьютере свои данные и работать с ними и в то же время позволяющие работать всем пользователям со всей совокупностью данных как с единой централизованной базой данных. Соответствующая совокупность данных называется распределенной базой данных.
Распределенная база данных – совокупность логически взаимосвязанных разделяемых данных (и описаний их структур), физически распределенных в компьютерной сети.
Система управления распределенной базой данных – программная система, обеспечивающая работу с распределенной базой данных и позволяющая пользователю работать как с его локальными данными, так и со всей базой данных в целом.
Объединение данных организуется виртуально. Соответствующий подход, по сути, отражает организационную структуру предприятия (и даже общества в целом), состоящего из отдельных подразделений. Причем, хотя каждое подразделение обрабатывает свой набор данных (эти наборы, как правило, пересекаются), существует необходимость доступа к этим данным как к единому целому (в частности, для управления всем предприятием).
Одним из примеров реализации такой модели может служить сеть Интернет : данные вводятся и хранятся на разных компьютерах по всему миру, любой пользователь может получить доступ к этим данным, не задумываясь о том, где они физически расположены.
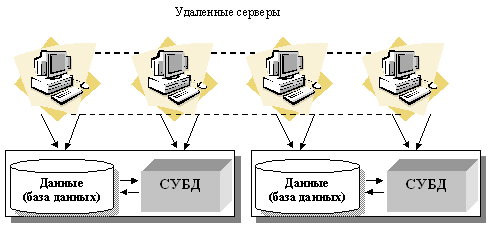
К.Дж. Дейт провозглашает следующий фундаментальный принцип распределенной базы данных [ [ 2.1 ] ]. Для пользователя распределенная система должна выглядеть точно так же, как нераспределенная. Из этого принципа следует ряд правил:
Заметим, что понятие распределенной базы данных можно интерпретировать как следующий шаг в развитии понятий о данных (см. «Введение в базы данных. Общая характеристика основных понятий» ), обусловленный распределенностью данных в реальных предметных областях, а также новым этапом развития средств вычислительной техники – широким использованием вычислительных сетей.
В этой интерпретации распределенную базу данных можно понимать как совокупность логически взаимосвязанных распределенных по разным компьютерам баз данных.
Поэтому очевидно, что задача проектирования, создания и функционирования распределенных баз данных является весьма существенной, активно изучается в настоящее время и будет решаться и далее.
Распределённые СУБД для энтерпрайза
CAP-теорема является краеугольным камнем теории распределённых систем. Конечно, споры вокруг неё не утихают: и определения в ней не канонические, и строгого доказательства нет… Тем не менее, твёрдо стоя на позициях бытового здравого смысла™, мы интуитивно понимаем, что теорема верна.

Единственное, что не очевидно, так это значение буквы «P». Когда кластер разделился, он решает – то ли не отвечать, пока не будет набран кворум, то ли отдавать те данные, которые есть. В зависимости от результатов этого выбора система классифицируется либо как CP, либо как AP. Cassandra, например, может вести себя и так и так, в зависимости даже не от настроек кластера, а от параметров каждого конкретного запроса. Но если система не «P», и она разделилась, тогда – что?
Ответ на этот вопрос несколько неожиданный: CA-кластер не может разделиться.
Что же это за кластер, который не может разделиться?
Непременный атрибут такого кластера – общая система хранения данных. В подавляющем большинстве случаев это означает подключение через SAN, что ограничивает применение CA-решений крупными предприятиями, способными содержать SAN-инфраструктуру. Для того, чтобы несколько серверов могли работать с одними и теми же данными, необходима кластерная файловая система. Такие файловые системы есть в портфелях HPE (CFS), Veritas (VxCFS) и IBM (GPFS).
Oracle RAC
Опция Real Application Cluster впервые появилась в 2001 году в релизе Oracle 9i. В таком кластере что несколько экземпляров сервера работают с одной и той же базой данных.
Oracle может работать как с кластерной файловой системой, так и с собственным решением – ASM, Automatic Storage Management.
Каждый экземпляр ведёт свой журнал. Транзакция выполняется и фиксируется одним экземпляром. В случае сбоя экземпляра один из выживших узлов кластера (экземпляров) считывает его журнал и восстанавливают потерянные данные – за счёт этого обеспечивается доступность.
Все экземпляры поддерживают собственный кэш, и одни и те же страницы (блоки) могут находиться одновременно в кэшах нескольких экземпляров. Более того, если какая-то страница нужна одному экземпляру, и она есть в кэше другого экземпляра, он может получить его у «соседа» при помощи механизма cache fusion вместо того, чтобы читать с диска.
Но что произойдёт, если одному из экземпляров потребуется изменить данные?
Особенность Oracle в том, что у него нет выделенного сервиса блокировок: если сервер хочет заблокировать строку, то запись о блокировке ставится прямо на той странице памяти, где находится блокируемая строка. Благодаря такому подходу Oracle – чемпион по производительности среди монолитных баз: сервис блокировок никогда не становится узким местом. Но в кластерной конфигурации такая архитектура может приводить к интенсивному сетевому обмену и взаимным блокировкам.
Как только запись блокируется, экземпляр оповещает все остальные экземпляры о том, что страница, в которой хранится эта запись, захвачена в монопольном режиме. Если другому экземпляру понадобится изменить запись на той же странице, он должен ждать, пока изменения на странице не будут зафиксированы, т. е. информация об изменении не будет записана в журнал на диске (при этом транзакция может продолжаться). Может случиться и так, что страница будет изменена последовательно несколькими экземплярами, и тогда при записи страницы на диск придётся выяснять, у кого же хранится актуальная версия этой страницы.
Случайное обновление одних и тех же страниц через разные узлы RAC приводит к резкому снижению производительности базы данных – вплоть до того, что производительность кластера может быть ниже, чем производительность единственного экземпляра.
Правильное использование Oracle RAC – физическое деление данных (например, при помощи механизма секционированных таблиц) и обращение к каждому набору секций через выделенный узел. Главным назначением RAC стало не горизонтальное масштабирование, а обеспечение отказоустойчивости.
Если узел перестаёт отвечать на heartbeat, то тот узел, который обнаружил это первым, запускает процедуру голосования на диске. Если и здесь пропавший узел не отметился, то один из узлов берёт на себя обязанности по восстановлению данных:
IBM Pure Data Systems for Transactions
Кластерное решение для СУБД появилось в портфеле Голубого Гиганта в 2009 году. Идеологически оно является наследником кластера Parallel Sysplex, построенным на «обычном» оборудовании. В 2009 году вышел продукт DB2 pureScale, представляющий собой комплект программного обеспечения, а в 2012 года IBM предлагает программно-аппаратный комплект (appliance) под названием Pure Data Systems for Transactions. Не следует путать его с Pure Data Systems for Analytics, которая есть не что иное, как переименованная Netezza.
Архитектура pureScale на первый взгляд похожа на Oracle RAC: точно так же несколько узлов подключены к общей системе хранения данных, и на каждом узле работает свой экземпляр СУБД со своими областями памяти и журналами транзакций. Но, в отличие от Oracle, в DB2 есть выделенный сервис блокировок, представленный набором процессов db2LLM*. В кластерной конфигурации этот сервис выносится на отдельный узел, который в Parallel Sysplex называется coupling facility (CF), а в Pure Data – PowerHA.
PowerHA предоставляет следующие сервисы:
Если узлу нужна страница, и этой страницы нет в кэше, то узел запрашивает страницу в глобальном кэше, и только в том случае, если и там её нет, читает её с диска. В отличие от Oracle, запрос идёт только в PowerHA, а не в соседние узлы.
Если экземпляр собирается менять строку, он блокирует её в эксклюзивном режиме, а страницу, где находится строка, – в разделяемом режиме. Все блокировки регистрируются в глобальном менеджере блокировок. Когда транзакция завершается, узел посылает сообщение менеджеру блокировок, который копирует изменённую страницу в глобальный кэш, снимает блокировки и инвалидирует изменённую страницу в кэшах других узлов.
Если страница, в которой находится изменяемая строка, уже заблокирована, то менеджер блокировок прочитает изменённую страницу из памяти узла, сделавшего изменения, снимет блокировку, инвалидирует изменённую страницу в кэшах других узлов и отдаст блокировку страницы узлу, который её запросил.
«Грязные», то есть изменённые, страницы могут быть записаны на диск как с обычного узла, так и с PowerHA (castout).
При отказе одного из узлов pureScale восстановление ограничено только теми транзакциями, которые в момент сбоя ещё не были завершены: страницы, изменённые этим узлом в завершившихся транзакциях, есть в глобальном кэше на PowerHA. Узел перезапускается в урезанной конфигурации на одном из серверов кластера, откатывает незавершённые транзакции и освобождает блокировки.
PowerHA работает на двух серверах, и основной узел синхронно реплицирует своё состояние. При отказе основного узла PowerHA кластер продолжает работу с резервным узлом.
Разумеется, если обращаться к набору данных через один узел, общая производительность кластера будет выше. PureScale даже может заметить, что некоторая область данных обрабатываются одним узлом, и тогда все блокировки, относящиеся к этой области, будут обрабатываться узлом локально без коммуникаций с PowerHA. Но как только приложение попытается обратиться к этим данным через другой узел, централизованная обработка блокировок будет возобновлена.
Внутренние тесты IBM на нагрузке, состоящей из 90% чтения и 10% записи, что очень похоже на реальную промышленную нагрузку, показывают почти линейное масштабирование до 128 узлов. Условия тестирования, увы, не раскрываются.
HPE NonStop SQL
Своя высокодоступная платформа есть и в портфеле Hewlett-Packard Enterprise. Это платформа NonStop, выпущенная на рынок в 1976 году компанией Tandem Computers. В 1997 году компания была поглощена компанией Compaq, которая, в свою очередь, в 2002 году влилась в Hewlett-Packard.
NonStop используется для построения критичных приложений – например, HLR или процессинга банковских карт. Платформа поставляется в виде программно-аппаратного комплекса (appliance), включающего в себя вычислительные узлы, систему хранения данных и коммуникационное оборудование. Сеть ServerNet (в современных системах – Infiniband) служит как для обмена между узлами, так и для доступа к системе хранения данных.
В ранних версиях системы использовались проприетарные процессоры, которые были синхронизированы друг с другом: все операции исполнялись синхронно несколькими процессорами, и как только один из процессоров ошибался, он отключался, а второй продолжал работу. Позднее система перешла на обычные процессоры (сначала MIPS, затем Itanium и, наконец, x86), а для синхронизации стали использоваться другие механизмы:
Вся база данных делится на части, и за каждую часть отвечает свой процесс Data Access Manager (DAM). Он обеспечивает запись данных, кэшировние и механизм блокировок. Обработкой данных занимаются процессы-исполнители (Executor Server Process), работающие на тех же узлах, что и соответствующие менеджеры данных. Планировщик SQL/MX делит задачи между исполнителями и объединяет результаты. При необходимости внести согласованные изменения используется протокол двухфазной фиксации, обеспечиваемый библиотекой TMF (Transaction Management Facility).
NonStop SQL умеет приоритезировать процессы так, чтобы длинные аналитические запросы не мешали исполнению транзакций. Однако её назначение – именно обработка коротких транзакций, а не аналитика. Разработчик гарантирует доступность кластера NonStop на уровне пять «девяток», то есть простой составляет всего 5 минут в год.
SAP HANA
Первый стабильный релиз СУБД HANA (1.0) состоялся в ноябре 2010 года, а пакет SAP ERP перешёл на HANA с мая 2013 года. Платформа базируется на купленных технологиях: TREX Search Engine (поиска в колоночном хранилище), СУБД P*TIME и MAX DB.
Само слово «HANA» – акроним, High performance ANalytical Appliance. Поставляется эта СУБД в виде кода, который может работать на любых серверах x86, однако промышленные инсталляции допускаются только на оборудовании, прошедшем сертификацию. Имеются решения HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi, NEC. Некоторые конфигурации Lenovo допускают даже эксплуатацию без SAN – роль общей СХД играет кластер GPFS на локальных дисках.
В отличие от перечисленных выше платформ, HANA – СУБД в памяти, т. е. первичный образ данных хранится в оперативной памяти, а на диск записываются только журналы и периодические снимки – для восстановления в случае аварии.
Каждый узел кластера HANA отвечает за свою часть данных, а карта данных хранится в специальном компоненте – Name Server, расположенном на узле-координаторе. Данные между узлами не дублируются. Информация о блокировках также хранится на каждом узле, но в системе есть глобальный детектор взаимных блокировок.
Клиент HANA при соединении с кластером загружает его топологию и в дальнейшем может обращаться напрямую к любому узлу в зависимости от того, какие данные ему нужны. Если транзакция затрагивает данные единственного узла, то она может быть выполнена этим узлом локально, но если изменяются данные нескольких узлов, то узел-инициатор обращается к узлу-координатору, который открывает и координирует распределённую транзакцию, фиксируя её при помощи оптимизированного протокола двухфазной фиксации.
Узел-координатор дублирован, поэтому в случае выхода координатора из строя в работу немедленно вступает резервный узел. А вот если выходит из строя узел с данными, то единственный способ получить доступ к его данным – перезапустить узел. Как правило, в кластерах HANA держат резервный (spare) сервер, чтобы как можно быстрее перезапустить на нём потерянный узел.
Распределение базы данных
Онлайн-конференция
«Современная профориентация педагогов
и родителей, перспективы рынка труда
и особенности личности подростка»
Свидетельство и скидка на обучение каждому участнику

Описание презентации по отдельным слайдам:
Описание слайда:
Распределенные базы данных
Описание слайда:
Общие принципы
Под распределенной базой данных (РБД) понимается набор логически связанных между собой разделяемых данных, которые физически распределены по разных узлам компьютерной сети.
СУРБД – это программный комплекс (СУБД), предназначенный для управления РБД и позволяющий сделать распределенность прозрачной для конечного пользователя. Прозрачность РБД заключается в том, что с точки зрения конечного пользователя она должна вести себя точно также, как централизованная.
Логически единая БД разделяется на фрагменты, каждый из которых хранится на одном компьютере, а все компьютеры соединены линиями связи. Каждый из этих фрагментов работает под управлением своей СУБД.
Описание слайда:
Критерии распределенности (по К. Дейту)
Локальная автономность. Локальные данные принадлежат локальным узлам и управляется администраторами локальных БД.
Локальные процессы в РБД остаются локальными.
Все процессы на локальном узле контролируются только этим узлом.
Отсутствие опоры на центральный узел.
В системе не должно быть узла, без которого система не может функционировать, т.е. не должно быть центральных служб.
Непрерывное функционирование.
Удаление или добавление узла не должно требовать остановки системы в целом.
Независимость от местоположения.
Пользователь должен получать доступ к любым данным в системе, независимо от того, являются эти данные локальными или удалёнными.
Независимость от фрагментации.
Доступ к данным не должен зависеть от наличия или отсутствия фрагментации и от типа фрагментации.
Независимость от репликации.
Доступ к данным не должен зависеть от наличия или отсутствия реплик данных.
Описание слайда:
Критерии распределенности (по К. Дейту)
Обработка распределенных запросов.
Система должна автоматически определять методы выполнения соединения (объединения) данных.
Обработка распределенных транзакций.
Протокол обработки распределённой транзакции должен обеспечивать выполнение четырёх основных свойств транзакции: атомарность, согласованность, изолированность и продолжительность.
Независимость от типа оборудования.
СУРБД должна функционировать на оборудовании с различными вычислительными платформами.
Независимость от операционной системы.
СУРБД должна функционировать под управлением различных ОС.
Независимость от сетевой архитектуры.
СУРБД должна быть способной функционировать в сетях с различной архитектурой и типами носителя.
Независимость от типа СУБД.
СУРБД должна быть способной функционировать поверх различных локальных СУБД, возможно, с различными моделями данных (требование гетерогенности).
Описание слайда:
Методы поддержки распределенных данных
Существуют различные методы поддержки распределенности:
Фрагментация – разбиение БД или таблицы на несколько частей и хранение этих частей на разных узлах РБД.
Репликация – создание и хранение копий одних и тех же данных на разных узлах РБД.
Распределенные ограничения целостности – ограничения, для проверки выполнения которых требуется обращение к другому узлу РБД.
Распределенные запросы – это запросы на чтение, обращающиеся более чем к одному узлу РБД.
Распределенные транзакции – команды на изменение данных, обращающиеся более чем к одному узлу РБД.
Описание слайда:
Фрагментация
Фрагментация – основной способ организации РБД.
Назначение: хранение данных на том узле, где они чаще используются.
Основные проблемы, которые при этом возникают:
– прозрачность написания запросов к данным;
– поддержка распределенных ограничений целостности.
Схема фрагментации отношения должна удовлетворять трем условиям:
Полнота: если отношение R разбивается на фрагменты R1, R2,…, Rn, то
URi = R
(Каждый кортеж должен входить хотя бы в один фрагмент).
Восстановимость: должна существовать операция реляционной алгебры, позволяющая восстановить отношение R из его фрагментов. Это правило гарантирует сохранение функциональных зависимостей.
Непересекаемость: если элемент данных dj Ri, то он не должен присутствовать одновременно в других фрагментах. Исключение составляет первичный ключ при вертикальной фрагментации. Это правило гарантирует минимальную избыточность данных.
Описание слайда:
Фрагментация
Типы фрагментации:
а) горизонтальная;
б) вертикальная;
в) смешанная;
г) производная.
Производная фрагментация строится для подчиненного отношения на основе фрагментов родительского отношения. Например, для фрагментов отношения Emp (сотрудники) Ei подчиненное отношение «Дети» (Child), информацию о которых также целесообразно хранить в соответствующих узлах, имеет смысл разбить на три горизонтальных фрагмента:
C1 = C ►tabNo Е1
C2 = C ►tabNo Е2
C3 = C ►tabNo Е3
где символ ► обозначает естественное полусоединение отношения C и фрагмента Еi (включает кортежи отношения С, которые могут быть соединены с соответствующим кортежем фрагмента Еi по значению внешнего ключа).
Описание слайда:
Репликация данных
Репликация – это поддержание двух и более идентичных копий (реплик) данных на разных узлах РБД.
Реплика может включать всю базу данных (полная репликация), одно или несколько взаимосвязанных отношений или фрагмент отношения.
Достоинства репликации:
– повышение доступности и надежности данных;
– повышение локализации ссылок на реплицируемые данные.
Недостатки репликации:
– сложность поддержания идентичности реплик;
– увеличение объема памяти для хранения данных.
Поддержание идентичности реплик называется распространение изменений и реализуется службой тиражирования.
Описание слайда:
Служба тиражирования
Служба тиражирования должна выполнять следующие функции:
Обеспечение масштабируемости, т.е. эффективной обработки больших и малых объемов данных.
Преобразование типов и моделей данных (для гетерогенных РБД).
Репликация объектов БД, например, индексов, триггеров и т.п.
Инициализация вновь создаваемой реплики.
Обеспечение возможности «подписаться» на существующие реплики, чтобы получать их в определенной периодичностью.
Для выполнения этих функций в языке, поддерживаемом СУБД, предусматривается наличие средств определения схемы репликации, механизма подписки и механизма инициализации реплик (создания и заполнения данными).
Описание слайда:
Репликация с основной копией
Существуют следующие варианты:
Классический подход заключается в наличии одной основной копии, в которую можно вносить изменения; остальные копии создаются с определением read only.
Асимметричная репликация: основная копия фрагментирована и распределена по разным узлам РБД, и другие узлы могут являться подписчиками отдельных фрагментов (read only).
Рабочий поток. При использовании этого подхода право обновления не принадлежит постоянно одной копии, а переходит от одной копии в другой в соответствии с потоком операций. В каждый момент времени обновляться может только одна копия.
Консолидация данных:
Описание слайда:
Репликация без основной копии
Симметричная репликация (без основной копии). Все копии реплицируемого набора могут обновляться одновременно и независимо друг от друга, но все изменения одной копии должны попасть во все остальные копии.
Существует два основных механизма распространения изменений при симметричной репликации:
синхронный: изменения во все копии вносятся в рамках одной транзакции;
асинхронный: подразумевает отложенный характер внесения изменений в удаленные копии.
Достоинство синхронного распространения изменений – полная согласованность копий и отсутствие конфликтов обновления.
Недостатки:
– трудоемкость и большая длительность модификации данных,
– низкая надежность работы системы.
Описание слайда:
Репликация без основной копии
Конфликтные ситуации:
Добавление двух записей с одинаковыми первичными или уникальными ключами. Для предотвращения таких ситуаций обычно каждому узлу РБД выделяется свой диапазон значений ключевых (уникальных) полей.
Конфликты удаления: одна транзакция пытается удалить запись, которая в другой копии уже удалена другой транзакцией. Если такая ситуация считается конфликтом, то она разрешаются вручную.
Конфликты обновления: две транзакции в разных копиях обновили одну и ту же запись, возможно, по-разному, и пытаются распространить свои изменения. Для идентификации конфликтов обновления необходимо передавать с транзакцией дополнительную информацию: старое и новое содержимое записи. Если старая запись не может быть обнаружена, налицо конфликт обновления.
Описание слайда:
Репликация без основной копии
Методы разрешения конфликтов обновления:
Разрешение по приоритету узлов: для каждого узла назначается приоритет, и к записи применяется обновление, поступившее с узла с максимальным приоритетом.
Разрешение по временной отметке: все транзакции имеют временную отметку, и к записи применяется обновление с минимальной или максимальной отметкой. Использовать ли для этого минимальную или максимальную отметку – зависит от предметной области и, обычно, может регулироваться.
Аддитивный метод (add – добавить): может применяться в тех случаях, когда изменения основаны на предыдущем значении поля, например, salary = salary + X. При этом к значению поля последовательно применяются все обновления.
Использование пользовательских процедур.
Разрешение конфликтов вручную. Сведения о конфликте записываются в журнал ошибок для последующего анализа и устранения администратором.
Описание слайда:
Репликация без основной копии
Способы реализации распространения изменений:
Использование триггеров.
Внутрь триггера помещаются команды, проводящие на других копиях обновления, аналогичные тем, которые вызвали выполнение триггера. Этот подход достаточно гибкий, но он обладает рядом недостатков:
триггеры создают дополнительную нагрузку на систему;
триггеры не могут выполняться по графику (время срабатывания триггера не определено);
с помощью триггеров сложнее организовать групповое обновление связанных таблиц (из-за проблемы мутирующих таблиц).
2. Поддержка журналов изменений для реплицируемых данных. Рассылка этих изменений входит в задачу сервера СУБД или сервера тиражирования (входящего в состав СУБД). Основные принципы, которых необходимо придерживаться при этом:
Для сохранения согласованности данных должен соблюдаться порядок внесения изменений.
Информация об изменениях должна сохраняться в журнале до тех пор, пока не будут обновлены все копии этих данных.
Описание слайда:
Распределенные запросы
Распределенным называется запрос, который обращается к двум и более узлам РБД, но не обновляет на них данные.
Запрашивающий узел должен определить, что в запросе идет обращение к данным на другом узле, выделить подзапрос к удаленному узлу и перенаправить его этому узлу.
Самой сложной проблемой выполнения распределенных запросов является оптимизация, т.е. поиск оптимального плана выполнения запроса. Информация, которая требуется для оптимизации запроса, распределена по узлам. Если выбрать центральный узел, который соберет эту информацию, построит оптимальный план и отправит его на выполнение, то теряется свойство локальной автономности.
Поэтому обычно распределенный запрос выполняется так: запрашивающий узел собирает все данные, полученные в результате выполнения подзапросов, у себя, и выполняет их соединение (или объединение), что может занять очень много времени.
Описание слайда:
Описание слайда:
Распределенные запросы. Пример
Условия:
скорость передачи 10000 б/с;
задержка передачи – 1 с,
все кортежи по 100 байт,
существует 10 покупателей, согласных заплатить не менее 200000,
в Абердине было проведено 100000 осмотров.
Ротни (Rothnie) проанализировал 6 стратегий выполнения этого запроса:
Переслать Renter в Лондон и выполнить обработку запроса там:1+(100000*100)/10000 =
Переслать Viewing и Property в Глазго и выполнить обработку запроса там: 2+((1000000+10000)*100)/10000 =
Соединить Renter и Property в Лондоне и для каждого кортежа проверить покупателя: 100000*(2+100/10000) +1*100000 =
Выбрать в Глазго нужных покупателей и проверить для каждого город:10*(1+100/10000) +1*10 =
Соединить Renter и Property в Лондоне, выполнить проекцию полей pNo и rNo и переслать её в Глазго: 1+(100000*100)/10000 =
Выбрать клиентов по Max_price и переслать в Лондон: 1+(10*100)/10000 =
16,7 мин.
28 ч
2,3 дня
20 с
16,7 мин.
1 с
Описание слайда:
Распределенные ограничения целостности
Распределенные ограничения целостности возникают тогда, когда для проверки соблюдения какого-либо ограничения целостности системе необходимо обратиться к другому узлу.
Примеры:
База данных разделена на фрагменты таким образом, что родительская таблица находится на одном узле, а дочерняя, связанная с ней по внешнему ключу, – на другом. При добавлении записи в дочернюю таблицу система обратится к узлу, на котором расположена родительская таблица, для проверки наличия соответствующего значения ключа.
Разбиение одной таблицы на фрагменты и размещение этих фрагментов по разным узлам сети. Здесь будет необходима проверка соблюдения ограничений первичного ключа и уникальных ключей.
Описание слайда:
Распределенные транзакции
Распределенные транзакции обращаются к двум и более узлам и обновляют на них данные.
Основная проблема распределенных транзакций – соблюдение логической целостности данных. Транзакция на всех узлах должна завершиться одинаково: или фиксацией, или откатом.
Выполнение распределенных транзакций осуществляется с помощью специального алгоритма, который называется двухфазная фиксация.
Координатор транзакции – узел, который контролирует выполнение этого протокола (обычно, тот узел, который инициирует данную транзакцию).
Остальные узлы, на которых выполняется транзакция, называются участниками транзакции.
Описание слайда:
Протокол двухфазной фиксации
Описание слайда:
Действия координатора транзакции
Координатор выполняет протокол 2ФФ по следующему алгоритму:
I. Фаза 1 (голосование).
Занести запись begin_commit в системный журнал и обеспечить ее перенос из буфера в ОП на ВЗУ. Отправить всем участникам команду PREPARE.
Ожидать ответов всех участников в пределах установленного тайм-аута.
II. Фаза 2 (принятие решения).
При поступлении сообщения ABORT: занести в системный журнал запись abort и обеспечить ее перенос из буфера в ОП на ВЗУ; отправить всем участникам сообщение GLOBAL_ABORT и ждать ответов участников (тайм-аут).
Если участник не отвечает в течение установленного тайм-аута, координатор считает, что данный участник откатит свою часть транзакции и запускает протокол ликвидации.
Если все участники прислали COMMIT, поместить в системный журнал запись commit и обеспечить ее перенос из буфера в ОП на ВЗУ. Отправить всем участникам сообщение GLOBAL_COMMIT и ждать ответов всех участников.
После поступления подтверждений о фиксации от всех участников: поместить в системный журнал запись end_transaction и обеспечить ее перенос из буфера в ОП на ВЗУ.
Если некоторые узлы не прислали подтверждения фиксации, координатор заново направляет им сообщения о принятом решении и поступает по этой схеме до получения всех требуемых подтверждений.
Описание слайда:
Действия участника транзакции
Участник выполняет протокол 2ФФ по следующему алгоритму:
При получении команды PREPARE, если он готов зафиксировать свою часть транзакции, он помещает запись ready_commit в файл журнала транзакций и отправляет координатору сообщение READY_COMMIT. Если он не может зафиксировать свою часть транзакции, он помещает запись abort в файл журнала транзакций, отправляет координатору сообщение ABORT и откатывает свою часть транзакции (не дожидаясь общего сигнала GLOBAL_ABORT).
Если участник отправил координатору сообщение READY_COMMIT, то он ожидает ответа координатора в пределах установленного тайм-аута.
При получении GLOBAL_ABORT участник помещает запись abort в файл журнала транзакций, откатывает свою часть транзакции и отправляет координатору подтверждение отката.
При получении GLOBAL_COMMIT участник помещает запись commit в файл журнала транзакций, фиксирует свою часть транзакции и отправляет координатору подтверждение фиксации.
Если в течение установленного тайм-аута участник не получает сообщения от координатора, он откатывает свою часть транзакции.
Описание слайда:
Протоколы ликвидации
Протокол ликвидации для координатора:
Тайм-аут в состоянии WAITING: координатор не может зафиксировать транзакцию, потому что не получены все подтверждения от участников о фиксации. Ликвидация заключается в откате транзакции.
Тайм-аут в состоянии DECIDED: координатор повторно рассылает сведения и принятом глобальном решении и ждет ответов от участников.
Простейший протокол ликвидации для участника заключается в блокировании процесса до тех пор, пока сеанс связи с координатором не будет восстановлен. Но в целях повышения производительности (и автономности) узлов могут быть предприняты и другие действия:
Тайм-аут в состоянии INITIAL: участник не может сообщить о своем решении координатору и не может зафиксировать транзакцию. Но может откатить свою часть транзакции. Если он позднее получит команду PREPARE, он может проигнорировать ее или отправить координатору сообщение ABORT.
Тайм-аут в состоянии PREPARED: участник уже известил координатор о решении COMMIT, то он не может его изменить. Участник оказывается заблокированным.
Описание слайда:
Протоколы восстановления
Действия, которые выполняются на отказавшем узле после его перезагрузки, называются протоколом восстановления.
Они зависят от того, в каком состоянии находился узел, когда произошел сбой, и какую роль выполнял этот узел в момент отказа: координатора или участника.
При отказе координатора:
В состоянии INITIAL: процедура 2ФФ еще не запускалась, поэтому после перезагрузки следует ее запустить.
В состоянии WAITING: координатор уже направил команду PREPARE, но еще не получил всех ответов и не получил ни одного сообщения ABORT. В этом случае он перезапускает процедуру 2ФФ.
В состоянии DECIDED: координатор уже направил участникам глобальное решение. Если после перезапуска он получит все подтверждения, то транзакция считается успешно зафиксированной. В противном случае он должен прибегнуть к протоколу ликвидации.
Описание слайда:
Протоколы восстановления
При отказе участника цель протокола восстановления – гарантировать, что после восстановления узел выполнит в отношении транзакции то же действие, которое выполнили другие участники, и сделает это независимо от координатора, т.е. по возможности без дополнительных подтверждений.
Рассмотрим три возможных момента возникновения отказа:
В состоянии INITIAL: участник еще не успел сообщит о своем решении координатору, поэтому он может выполнить откат, т.к. координатор не мог принять решение о глобальной фиксации транзакции без голоса этого участника.
В состоянии PREPARED: участник уже направил сведения о своем решении координатору, поэтому он должен запустить свой протокол ликвидации.
В состоянии ABORTED/COMMITED: участник уже завершил обработку своей части транзакции, поэтому никаких дополнительных действий не требуется.
Описание слайда:
Реализация протокола 2ФФ
Описание слайда:
Поддержка распределенности в Oracle
Прозрачность распределенности.
Каждая часть данных, хранимых на одном компьютере в сети, оформлена как самостоятельная база данных.
Одна логическая таблица может быть распределена по разным узлам в сети.
Каждый сервер БД в системе распределенной базы данных (РБД) управляет доступом к своей локальной БД; за управление системой в целом не отвечает ни один сервер.
Поддержка целостности и согласованности данных осуществляется на уровне взаимодействия между серверами, что является расширением модели клиент-сервер (Distributed Oracle).
Связь осуществляется по сети с помощью программного средства Oracle – дополнительной утилиты Net8.
Распределенная БД может быть неоднородной, при этом один или несколько узлов должны быть Oracle-серверами, а связь с серверами других типов осуществляется через открытый шлюз (дополнительный программный пакет Open Gateways).
Описание слайда:
Описание слайда:
Связи в распределенной БД Oracle
Примеры.
Локальная база данных – HQ.ACME.COM.
Удаленная база данных – SALES.ACME.COM.
Создание общей связи баз данных к удаленной базе данных SALES:
CREATE PUBLIC DATABASE LINK sales.acme.com USING ‘dbstring’;
Создание личной связи баз данных для создателя этой связи:
CREATE DATABASE LINK sales CONNECT TO scott IDENTIFIED BY tiger;
Фраза CONNECT TO специфицирована явно. При установлении сессии в удаленной базе данных через эту связь баз данных будет использоваться идентификация SCOTT/TIGER.
Фраза USING опущена. Поэтому, когда используется эта личная связь баз данных, должна существовать одноименная общая или сетевая связь баз данных, содержащая строку базы данных для установления соединения с удаленной базой данных.
Описание слайда:
Работа в распределенной БД Oracle
Oracle различает следующие виды обработки данных в РБД:
удаленный запрос – это оператор SELECT, считывающий информацию из одной или нескольких таблиц на одном из удаленных узлов сети;
распределенный запрос – это оператор SELECT, считывающий информацию из одной или нескольких удаленных таблиц, которые расположены на разных узлах;
удаленное обновление – это модификация, затрагивающая таблицы из одного удаленного узла;
распределенное обновление – это модификация данных двух или более узлов сети;
вызовы удаленных процедур – запуск процедуры, находящейся на удаленном сервере;
удаленная транзакция – это транзакция, содержащая хотя бы один удаленный запрос и относящаяся к одному удаленному узлу;
распределенная транзакция – это транзакция, содержащая одно или несколько распределенных обновлений или удаленные транзакции для разных серверов. За выполнение распределенных транзакций отвечает механизм двухфазной фиксации.
Описание слайда:
Моментальные снимки в Oracle
Oracle поддерживает два типа тиражирования:
базовое – копия обеспечивает доступ «только для чтения».
усовершенствованное – приложения могут считывать и обновлять тиражируемые копии таблиц по всей системе (поддерживается специальными средствами СУБД – Replication Option).
Базовое тиражирование осуществляется (после установления связи с удаленной БД) с помощью создания моментальных снимков (snapshot), например:
CREATE SNAPSHOT sales.parts AS
SELECT * FROM sales.parts@central.compworld;
Моментальные снимки бывают:
простые – создаются по однотабличному запросу SELECT, содержащему простые условия отбора.
сложные – создаются по запросам, содержащим сложные условия отбора, фразы group by, having, обращающимся к двум и более таблицам и проч.
Описание слайда:
Моментальные снимки в Oracle
Примеры:
Моментальный снимок, основой которого является запрос
select * from employee@hr_link;
является простым.
Моментальный снимок, основанный на запросе
select dept, max(salary)
from employee@hr_link
group by dept;
сложный, так как в нем используются функции группирования.
С помощью моментального снимка в локальной базе данных будет создано несколько объектов, поэтому пользователь, создающий моментальный снимок, должен иметь привилегии CREATE TABLE, CREATE VIEW и CREATE INDEX.
Описание слайда:
Моментальные снимки в Oracle
Синтаксис создания моментального снимка:
create snapshot [имя_схемы.]имя_снимка
[ < pctfree целое | pctused целое | initrans целое |
maxtrans целое | tablespace имя_табличной_области |
storage размер_памяти >]
[ cluster имя_кластера (имя_столбца[,…]) ]
[ using index ]
[ < pctfree целое | pctused целое | initrans целое |
maxtrans целое | tablespace имя_табличной_области |
storage размер_памяти >]
[refresh [< fast | complete | force >]
[ start with дата_1 ] [ next дата_2 ]]
[for update]
as запрос;
Описание слайда:
Моментальные снимки в Oracle
Пример создания МС на локальном сервере:
create snapshot emp_dept_count
pctfree 5
tablespace snap
storage (initial 100k next 100k pctincrease 0)
refresh complete
start with sysdate
next sysdate+7
as select deptno, count(*) dept_count
from employee@hr_link
group by deptno;
Описание слайда:
Моментальные снимки в Oracle
При создании моментального снимка в локальной базе данных создается:
таблица для хранения записей, получаемых в результате выполнения запроса моментального снимка (с именем SNAP$_имя_моментального_снимка);
представление этой таблицы «только для чтения», называемое в соответствии с именем моментального снимка;
представление, называемое MVIEW$_имя_моментального_снимка – для обращения к удаленной основной таблице (или таблицам). Это представление будет использоваться во время регенерации.
Для модификации снимка, например, с целью установки частоты автоматического изменения в 1 час можно воспользоваться командой ALTER SNAPSHOT:
alter snapshot emp_dept_count refresh complete
start with sysdate next sysdate + 1/24;
Для удаления моментальных снимков применяется команда drop snapshot:
drop snapshot emp_dept_count;
Описание слайда:
Регенерация моментальных снимков Oracle
Возможны два варианта:
REFRESH FAST (быстрая регенерация).
REFRESH COMPLETE (полная регенерация).
Описание слайда:
Регенерация моментальных снимков Oracle
Для быстрой регенерации необходим журнал моментальных снимков (snapshot log) – это таблица, обеспечивающая регистрацию в моментальном снимке изменений, происшедших в основной таблице. Имя журнала (таблицы) – MLOG$_имя_таблицы.
Команда CREATE SNAPSHOT LOG. Пример:
create snapshot log on employee
tablespace data
storage (initial 10k next 10k pctincrease 0);
Изменения в журнал моментальных снимков попадают с помощью триггера AFTER типа FOR EACH ROW, который называется TLOG$_имя_таблицы.
В журнале моментальных снимков данные находятся очень непродолжительное время: записи вводятся в журнал моментальных снимков, используются во время регенерации, а затем удаляются из журнала автоматически.
Описание слайда:
Усовершенствованное тиражирование Oracle
Производится с помощью двух средств Oracle:
Многоабонентского тиражирования.
Узлов обновляемых моментальных снимков.
Распространение изменений:
на уровне строк: сервер записывает изменения, сделанные каждой DML-транзакцией, и рассылает эти изменения в удаленные узлы.
путем процедурного тиражирования: тиражируется вызов удаленной процедуры, выполняющей в удаленном узле те же изменения, что и в вызывающем.
Различают асинхронное и синхронное распространение изменений.
Внесение изменений в тиражируемые данные происходит в несколько этапов:
локальный узел вносит изменения в свою копию данных (ОМС);
локальный узел запускает отложенную транзакцию на основном узле;
через некоторое время локальный узел выполняет быструю (или полную) регенерацию локальной копии данных, после чего приложение всегда может проверить, выполнена ли инициированная им транзакция. Если она не выполнена, то происходит рестарт транзакции и все повторяется.
Если Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с сайта, Вы можете оставить жалобу на материал.



