Распределенная обработка данных




![]()
![]()
Одной из важнейших и динамично развивающихся сетевых технологий являются технологии распределенной обработки данных. Использование этих технологий позволяет существенно улучшить информационное обеспечение территориально распределенного производства. При этом для администрации фирмы безразлично, где именно находится производство: в этом же здании, за 100 м или за 10 000 км. Появляются совсем другие проблемы, такие как межконтинентальное снабжение, поясное время и т.д.
Персональные компьютеры стоят на рабочих местах, т.е. в местах возникновения и использования информации (например, в иногороднем филиале фирмы, в пункте обмена валют коммерческого банка и т.д.). Они соединены каналами связи. Использование технологии распределенной обработки данных дает возможность распределить ресурсы всех компьютеров такой корпоративной (региональной) компьютерной сети по отдельным функциональным сферам деятельности и изменить технологию обработки данных в направлении децентрализации.
Преимущества распределенной обработки данных:
Распределенная обработка и распределенная база данных не синонимы. Если при распределенной обработке производится работа с базой, то подразумевается, что представление данных, их содержательная обработка, работа с базой на логическом уровне выполняются на персональном компьютере клиента, а поддержание базы в актуальном состоянии (состоянии, соответствующем состоянию реальной системы) — на сервере. В случае использования распределенной базы данных последняя размещается на нескольких серверах. Работа с ней осуществляется на тех же персональных компьютерах либо на других, и для доступа к удаленным данным надо использовать сетевую СУБД.
В системе распределенной обработки клиент может послать запрос как к собственной локальной базе данных, так и к удаленной. Удаленный запрос — единичный запрос к одному серверу. Несколько удаленных запросов к одному серверу объединяются в удаленную транзакцию. Если отдельные запросы транзакции обрабатываются различными серверами, то транзакция называется распределенной. При этом один запрос транзакции обрабатывается одним сервером. Распределенная же СУБД позволяет обрабатывать один запрос несколькими серверами. Такой запрос называется распределенным. Только обработка распределенного запроса поддерживает концепцию распределенной базы данных.
Организация обработки данных зависит от способа их распределения. Существуют централизованный, децентрализованный и смешанный способы распределения данных
Централизованная организация данных является самой простой для реализации (рис. 3.2.). На одном сервере находится единственная копия базы данных. Все операции с базой данных обеспечиваются этим сервером. Отсюда — ограничение на параллельную обработку. Доступ к данным выполняется с помощью удаленного запроса или удаленной транзакции. Достоинством такого способа являлся легкая поддержка базы данных в актуальном состояние а недостатками — то, что размер базы ограничен размером внешней памяти сервера; все запросы направляются к единственному серверу с соответствующими затратами на стоимость связи и временную задержку. Кроме того, база может стать полностью недоступной для удаленных пользователей при появлении ошибок связи или при отказе центрального сервера.
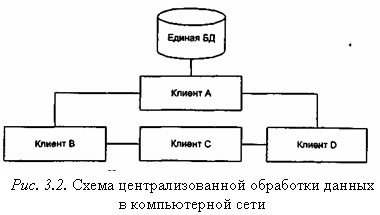
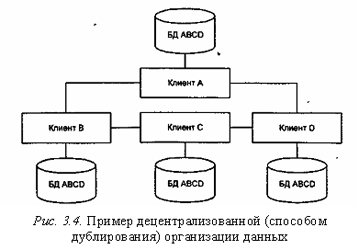
Децентрализованная организация данных предполагает разбиение информационной базы на несколько физически распределенных. Каждый клиент пользуется своей базой данных, которая может быть либо частью общей информационной базы (рис. 3.3), либо копией информационной базы в целом (рис. 3.4), что приводит к ее дублированию для каждого клиента.
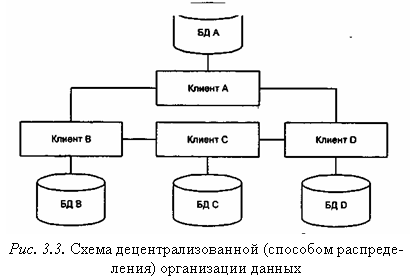
При распределении данных на основе разбиения база данных размещается на нескольких серверах. Существование копий отдельных частей недопустимо. Достоинства этого метода: большинство запросов удовлетворяются локальными серверами, что сокращает время получения ответа и снижает стоимость обработки запроса; система остается частично работоспособной при выходе из строя одного из серверов. Имеются и недостатки: часть удаленных запросов или транзакций может потребовать доступ к нескольким или даже всем серверам, что увеличит время ожидания; постоянно необходимо иметь сведения о размещении данных в различных БД. Расчленение базы данных наиболее подходит в случае совместного использования локальных и глобальных сетевых коммуникаций, поскольку обеспечивает безопасное использование внутрикорпоративных данных.

Способ дублирования заключается в том, что на каждом сервере сети размещается полная база данных (рис. 3.4). Это обеспечивает наибольшую надежность хранения данных. Недостатки способа: повышенные требования к объему внешней памяти клиентских компьютеров; усложнение корректировки баз, так как требуется синхронизация в целях согласования копий. Достоинства — все запросы выполняются локально, что обеспечивает быстрый доступ. Данный способ используется, когда фактор надежности является критическим, база небольшая, интенсивность обновления невелика.
Возможна и смешанная организация хранения данных, которая объединяет два способа распределения: разбиение и дублирование (рис. 3.5), приобретая при этом и преимущества, и недостатки обоих способов.
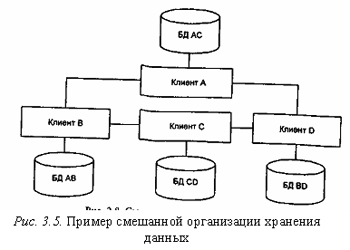
Появляется необходимость хранить информацию о том, где находятся данные в сети. При этом достигается компромисс между объемом памяти под базу в целом и под базу на каждом сервере, чтобы обеспечить надежность и эффективность работы сети; легко реализуется параллельная обработка. Смешанный способ организации данных можно использовать лишь при наличии сетевой СУБД.
В базах данных коллективного пользования центральным технологическим звеном становятся серверы баз данных. Программные средства серверов баз данных обеспечивают реализацию многопользовательских приложений, централизованное хранение, целостность и безопасность данных. Производительность серверов баз данных на порядок выше по сравнению с файл-серверами, которые используются в локальных сетях.
Серверы баз данных рассчитаны на поддержку большого числа различных типов приложений. Для реализации интерфейса с сервером базы данных можно использовать объектно-ориентированные средства, электронные таблицы, текстовые процессоры, графические пакеты, настольные издательские системы и другие информационные технологии.
Технология клиент-сервер, как более мощная, заменила технологию файл-сервер. Она позволила совместить достоинства однопользовательских систем (высокий уровень диалоговой поддержки, дружественный интерфейс, низкая цена) с достоинствами более крупных компьютерных систем (поддержка целостности, защита данных, многозадачность). Основная идея технологии клиент-сервер заключается в том, чтобы серверы расположить на мощных машинах, а приложения клиентов — на менее мощных машинах. Тем самым будут задействованы ресурсы более мощного сервера и менее мощных машин клиентов. Ввод-вывод к базе основан не на физическом дроблении данных, а на логическом, т.е. сервер отправляет клиентам не полную копию базы, а только логически необходимые порции, тем самым сокращая трафик сети (поток сообщений сети). В технологии клиент-сервер программы клиента и его запросы хранятся отдельно от БД. Сервер обрабатывает запросы клиентов, выбирает необходимые данные из базы данных, посылает их клиентам по сети, производит обновление информации, обеспечивает целостность и сохранность данных.
Недостаток технологии клиент-сервер заключается в повышении требований к производительности ЭВМ-сервера, в усложнении управления вычислительной сетью, а при отсутствии сетевой СУБД — в сложности организации распределенной обработки.
Тема 5. Распределённые технологии обработки и хранения данных.
Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи. Необходимо также иметь динамичные способы обращения к информации, способы поиска данных в заданные временные интервалы, чтобы реализовывать сложную математическую и логическую обработку данных.
Управление крупными предприятиями, управление экономикой на уровне региона или страны требуют участия в этом процессе достаточно крупных коллективов. Такие коллективы могут располагаться в различных районах города, в различных регионах страны и даже в различных странах. Для решения задач управления, обеспечивающих реализацию экономической стратегии, становятся важными и актуальными скорость и удобство обмена информацией, а также возможность тесного взаимодействия всех участвующих в процессе выработки управленческих решений.
Распределенная обработка данных – обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему. (Макарова)
Впервые задача об исследовании основ и принципов создания и функционирования распределенных информационных систем была поставлена известным специалистом в области баз данных К. Дейтом
В основе распределенной обработки лежат две основные идеи:
¾ работа множества пользователей с общими данными – общей базой данных (пользователи с разными именами, в том числе располагающимися на различных вычислительных установках, с различными полномочиями и задачами);
¾ объединение распределенных данных на логическом и физическом уровнях в общей БД.
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных.
Перечислим основные принципы создания и функционирования распределенных баз данных:
o прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная);
o изолированность пользователей друг от друга (пользователь должен «не чувствовать», «не видеть» работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные);
o синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени.
Из основных вытекает ряд дополнительных принципов:
1. локальная автономия (ни одна вычислительная установка
для своего успешного функционирования не должна зависеть
от любой другой установки);
2. отсутствие центральной установки (следствие предыдущего пункта);
3. независимость от местоположения (пользователю все равно где физически находятся данные, он работает так, как будто они находятся на его локальной установке);
4. непрерывность функционирования (отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД);
5. независимость от реплицирования (дублирования) данных (когда какая-либо таблица базы данных, или ее часть физически может быть представлена несколькими копиями, расположенными на различных установках, причем «прозрачно» для пользователя);
6. независимость от аппаратуры (желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов);
7. независимость от типа операционной системы (система должна функционировать вне зависимости от возможного различия ОС на различных вычислительных установках);
8. независимость от коммуникационной сети (возможность функционирования в разных коммуникационных средах);
9. независимость от СУБД (на разных установках могут
функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL ) и др.
2. Способы реализации распределенной обработки данных.
Для реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих направлений:
¾ многомашинные вычислительные комплексы (МВК);
¾ компьютерные (вычислительные) сети.
Многомашинный вычислительный комплекс (МВК) – группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс.
Пример 1. Три ЭВМ объединены в комплекс для распределения заданий, поступающих на обработку. Одна из них выполняет диспетчерскую функцию и распределяет задания в зависимости от занятости одной из двух других обрабатывающих ЭВМ. Это локальный многомашинный комплекс.
Пример 2. ЭВМ, осуществляющая сбор данных по некоторому региону, выполняет их предварительную обработку и передает для дальнейшего использования на центральную ЭВМ по телефонному каналу связи. Это дистанционный многомашинный комплекс.
Компьютерные сети классифицируются по различным признакам. В частности по характеру реализуемых функций сети подразделяются на:
¾ вычислительные, предназначенные для решения задач управления на основе вычислительной обработки исходной информации;
¾ информационные, предназначенные для получения справочных данных по запросу пользователя;
¾ смешанные, в которых реализуются вычислительные и информационные функции.
Выделим основные отличия КВС от МВК.
1. Размерность. В состав МВК входят обычно две, максимум три ЭВМ, расположенные преимущественно в одном помещении. Вычислительная сеть может состоять из десятков и даже сотен ЭВМ, расположенных на расстоянии друг от друга от нескольких метров до десятков, сотен и даже тысяч километров.
2. Распределение функций между ЭВМ. Если в МВК функции обработки и передачи данных, управления системой могут быть реализованы в одной ЭВМ, то в вычислительных сетях эти функции распределены между различными ЭВМ.
3. Необходимость решения в сети задачи маршрутизации сообщений – сообщение от одной ЭВМ к другой в сети может быть передано по различным маршрутам в зависимости от состояния каналов связи, соединяющих ЭВМ друг с другом.
3. Технологии распределенной обработки информации.
Практическая реализация распределенных информационных систем осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости от того, какой принцип приносится в «жертву» (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем:
¾ технологии объектного связывания;
Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно.
Системы на основе технологий «Клиент-сервер» исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах, и получили наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций.
При реализации данной технологии отступают от одного из основных принципов создания распределенных систем – отсутствия центрального узла. Принцип централизации хранения и обработки данных является базовым принципом технологии клиент-сервер.
Один из основных принципов технологии «клиент-сервер» заключается в разделении операций обработки данных на три группы, имеющие различную природу. Первая группа – это ввод и отображение данных. Вторая группа объединяет прикладные операции обработки данных, характерные для решения задач данной предметной области. К третьей группе относятся операции хранения и управления данными (базами данных или файловыми системами). Выделяют также служебный компонент, реализующий служебные функции, играющие роль связок между функциями первых групп.
Согласно этой классификации в любом техпроцессе можно выделить программы трёх видов:
В соответствии с этим выделяют следующие модели реализации технологии «клиент-сервер»:
2. модель доступа к удалённым данным ( Remote Data Access – RDA );
3. модель сервера базы данных ( DataBase Server – DBS );
4. модель сервера приложений ( Application Server – AS ).
Модель файлового сервера (FS)
Модель файлового сервера является наиболее простой.
Суть FS- модели иллюстрируется схемой, приведенной на рис. 2.2.1
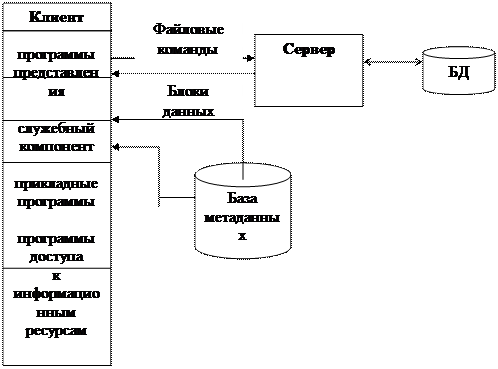 |
Один из компьютеров сети выделяется и определяется файловым сервером, т. е. общим хранилищем любых данных.
В FS-модели все основные компоненты размещаются на клиентской установке: программы представления, прикладные программы, программы доступа к информационным ресурсам, база метаданных и собственно СУБД.
Каков алгоритм выполнения запроса клиента?
Запрос клиента формулируется в командах языка SQL. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации и т. д. Перекачка информации с сервера на клиент производится до тех пор, пока не будет получен ответ на запрос клиента.
Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное, требуемый объем дискового пространства).
¾ высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению, и достигающий пиковых значений в момент массового вхождения в систему пользователей, например в начале рабочего дня;
¾ узкий спектр операций манипулирования с данными, который определяется только файловыми командами;
¾ отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
Модель удаленного доступа к данным (RDA)
На рис. 2.2.2 представлена модель удалённого доступа.
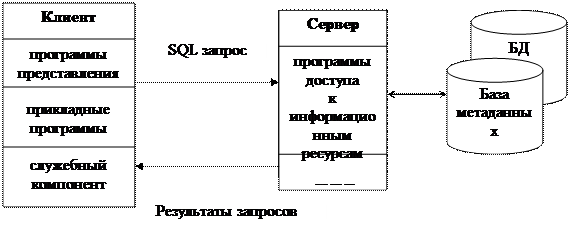 |
Рис. 2.2.2 Модель удаленного доступа (RDA)
Преимущества данной модели;
¾ перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД: процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций;
¾ резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, релевантные запросу, а не блоки файлов, как в FS-модели.
Основное достоинство RDA-модели — унификация интерфейса «клиент-сервер», стандартом при общении приложения-клиента и сервера становится язык SQL.
¾ запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть;
¾ так как в этой модели на клиенте располагаются и программы представления, и прикладные программы, то при повторении аналогичных функций в разных приложениях код соответствующей прикладной программы должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование кода приложений;
¾ высокие требования к клиентским вычислительным установкам, так как прикладные программы обработки данных, определяемые спецификой предметной области информационной системы, выполняются на них.
Модель сервера базы данных ( DBS )
На рис. 2.2.3 представлена модель сервера базы данных.
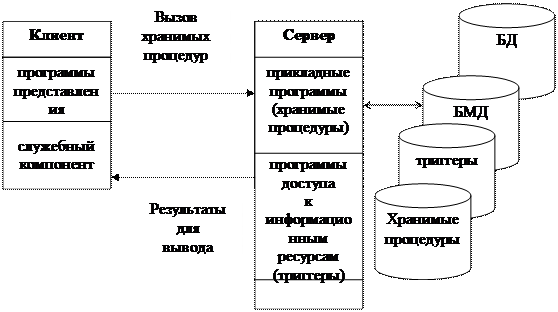 |
Рис. 2.2.3 Модель сервера БД (D BS )
Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server.
Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры.
К достоинствам DBS-модели, помимо разгрузки сети, относится и более активная роль сервера сети, возможность более адекватно и эффективно «настраивать» распределенную информационную систему на все нюансы предметной области.
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции:
¾ осуществляет мониторинг событий, связанных с триггерами;
¾ обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
¾ обеспечивает исполнение внутренней программы каждого триггера;
¾ запускает хранимые процедуры по запросам пользователей;
¾ запускает хранимые процедуры из триггеров;
¾ возвращает требуемые данные клиенту;
¾ обеспечивает все функции СУБД: доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД.
Если мы переложили на сервер большую часть приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом», в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом».
Для разгрузки сервера была предложена трехуровневая модель.
Модель сервера приложений ( AS )
Архитектура трехуровневой модели приведена на рис. 2.2.4.
Результаты для вывода
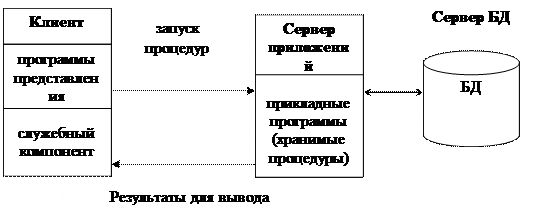 |
Рис. 2.2.4 Модель сервера приложений (А S )
Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот промежуточный уровень содержит один или несколько серверов приложений.
В AS-модели, как и в DBS-модели, на клиентских установках располагается только интерфейсная часть системы, т. е. компонент представления. Прикладные программы выполняются одним либо группой серверов приложений (удаленный компьютер или несколько компьютеров).
Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных. На них возлагаются также функции создания резервных копий БД и восстановления БД после сбоев.
Доступ к информационным ресурсам, необходимым для решения прикладных задач, обеспечивается так же, как и в RDA-модели, т.е. доступ к информационным ресурсам обеспечивается или операторами языка SQL, если идёт речь о базах данных, или вызовами функций специальной библиотеки. Запросы к информационным ресурсам направляются по сети удалённому компьютеру, например серверу базы данных, который обрабатывает запросы и возвращает клиенту необходимые для обработки блоки данных.
AS-модель, сохраняя сильные стороны DBS-модели, позволяет оптимально построить вычислительную схему информационной системы, однако, как и в случае RDA-модели, повышает трафик сети. Эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-приложений. (On-line analytical processing).
Технологии объектного связывания
С узкой точки зрения, технология объектного связывания данных решает задачу обеспечения доступа из одной локальной базы, открытой одним пользователем, к данным в другой локальной базе (в другом файле), возможно находящейся на другой вычислительной установке, открытой и эксплуатируемой другим пользователем.
Подобный принцип построения распределенных систем при больших объемах данных в связанных таблицах приведет к существенному увеличению трафика сети, так как по сети постоянно передаются страницы файлов баз данных, что может приводить к пиковым перегрузкам сети.
Не менее существенной проблемой является отсутствие надежных механизмов безопасности данных и обеспечения ограничений целостности. Так же как и в модели файлового сервера, совместная работа нескольких пользователей с одними и теми же данными обеспечивается только функциями операционной системы по одновременному доступу к файлу нескольких приложений.
Т.о., определенной проблемой технологий объектного связывания является появление «брешей» в системах защиты данных и разграничения доступа.
Во многих случаях узким местом распределённых систем, построенных на основе технологий «Клиент – сервер» или объектного связывания данных, является недостаточно высокая производительность из-за необходимости передачи по сети большого количества данных. Определённую альтернативу построения быстродействующих распределённых систем предоставляют технологии реплицирования данных.
Репликой называют особую копию базы данных для размещения на другом компьютере сети с целью автономной работы пользователей с одинаковыми (согласованными) данными общего пользования.
Основная идея реплицирования заключается в том, что пользователи работают автономно с одинаковыми (общими) данными, растиражированными по локальным базам данных. Производительность работы системы повышается из-за отсутствия необходимости передачи и обмена данными по сети.
Программное обеспечение СУБД для реализации такого подхода соответственно дополняется функциями тиражирования (реплицирования) баз данных.
Технологии репликации данных в тех случаях, когда не требуется обеспечивать большие потоки и интенсивность обновляемых в информационной сети данных, являются экономичным решением проблемы создания распределенных информационных систем с элементами централизации по сравнению с использованием дорогостоящих клиент-серверных систем.
На практике для совместной коллективной обработки данных применяются смешанные технологии, включающие элементы объектного связывания данных, репликаций и клиент-серверных решений. Развитие и все более широкое распространение распределенных информационных систем является основной перспективой развития автоматизированных информационных систем.
Вопросы к теме.
1. В связи с чем возникает потребность в организации распределённой обработки данных? Дайте понятие распределённой обработки данных.
2. Назовите две основные идеи, лежащие в основе распределённых АИС.
3. Перечислите основные принципы создания и функционирования распределённых баз данных.
4. Назовите дополнительные принципы создания и функционирования распределённых баз данных.
5. Способы реализации распределённой обработки данных – краткая характеристика.
6. Назовите основные отличия КВС от МВК.
7. От какого принципа создания распределённых систем отступают при реализации технологии «клиент-сервер»?
8. Назовите модели реализации технологии «клиент-сервер».
9. Краткая характеристика модели файлового сервера. Достоинства и недостатки.
10. Краткая характеристика модели доступа к удалённым данным. Достоинства и недостатки.
11. Краткая характеристика модели сервера базы данных. Достоинства и недостатки.
12. Краткая характеристика модели сервера приложений. Достоинства и недостатки.
13. Краткая характеристика технологии объектного связывания данных.
14. Проблемы технологии объектного связывания данных.
15. Дайте понятие реплики. В чём заключается основная идея реплицирования?
16 Какие проблемы возникают при использовании технологии реплицирования?



