Garbage Collection наглядно
В последнее время я работаю с клиентами над вопросами настроек JVM. Смахивает ситуация на то, что далеко не все из разработчиков и администраторов знают о том, как работает garbage collection и о том, как JVM использует память. Поэтому я решил дать вводную в эту тему с наглядным примером. Пост не претендует на то, чтобы покрыть весь объем знаний о garbage collection или настройке JVM (он огромен), ну и, в конце концов, об этом много чего хорошего написано уже в Сети.
Пост посвящён HotSpot JVM – ‘обычной’ JVM от Oracle (раньше Sun), JVM, которую вы скорее всего будете использовать в Windows. В случае Linux это может быть open source JVM. Или JVM может идти в комплекте с другим ПО, например WebLogic, или даже можно использовать Jrockit JVM от Oracle (раньше BEA). Или другие JVM от IBM, Apple и др. Большинство этих «других» JVM работают по похожей на HotSpot схеме, за исключением Jrockit, чье управление памятью отлично от других и который, например, не имеет выделенного Permanent Generation (см. ниже).
Давайте начнём с того, как JVM использует память. В JVM память делится на два сегмента – Heap и Permanent Generation. На диаграмме Permanent Generation обозначено зеленым, остальное – heap.
The Permanent Generation
Permanent generation используется только JVM для хранения необходимых данных, в том числе метаданные о созданных объектах. При каждом создании объекта JVM будет «класть» некоторый набор данных в PG. Соответственно, чем больше вы создаете объектов разных типов, тем больше «жилого пространства» требуется в PG.
Размер PG можно задать двумя параметрами JVM: -XX:PermSize – задаёт минимальный, или изначальный, размер PG, и -XX:MaxPermSize – задаёт максимальный размер. При запуске больших Java-приложений мы часто задаём одинаковые значения для этих параметров, так что PG создаётся сразу с размером «по-максимуму», что может увеличить производительность, так как изменение размера PG – дорогостоящая (трудоёмкая) операция. Определение одинаковых значений для этих двух параметров может избавить JVM от выполнения дополнительных операций, таких как проверки необходимости изменения размера PG и, естественно, непосредственного изменения.
Garbage collection – это круто! Если вы когда-либо программировали на языках типа C или Objective-C, то вы знаете, что ручное управление памятью – вещь утомительная и порой вызывающая ошибки. Наличие JVM, которая автоматически позаботится о неиспользуемых объектах, делает разработку проще и сокращает время отладки. Если же вы никогда не писали на подобных языках, значит возьмите С и попробуйте написать программу, и ощутите, как ценно то, что предоставляется вашим языком совершенно бесплатно.
Существует множество алгоритмов, которыми может воспользоваться JVM для проведения garbage collection. Можно указать, какие из них будут использоваться JVM с помощью параметров.
Давайте посмотрим на пример. Допустим, у нас есть следующий код:
В Eden создаётся («размещается») пять объектов, как показано пятью желтыми квадратиками на диаграмме. После «чего-нибудь» мы освобождаем a,b,c и e, присваивая ссылкам null. Имея в виду, что больше ссылок на них нет, они теперь не нужны, и показаны красным на второй диаграмме. При этом мы всё ещё нуждаемся в String d (показано зелёным).
Если мы попробуем разместить ещё объект, JVM обнаружит, что Eden полон и надо провести чистку. Самый простой алгоритм для garbage collection называется Copy Collection, и работает он так, как показано на диаграмме. На первом этапе Mark помечаются неиспользуемые объекты (красные). На втором (Copy) объекты, которые ещё нужны (d) копируется в сегмент survivor – квадрат справа. Сегментов Survivor два, и они меньше Eden. Теперь все объекты, которые мы хотим, чтобы они были сохранены, скопированы в Survivor, и JVM просто удаляет всё из Eden. На этом всё.
Этот алгоритм создаёт кое-что, что называется моментом, «когда мир остановился». Во время выполнения GC все другие треды в JVM переводятся в состояние паузы, ради того, чтобы никакой из них не попробовал влезть в память после того, как мы скопировали всё оттуда, что привело бы к потере того, что сделано. Это не великая проблема, если она в небольшом приложении, но если у нас на руках серьёзная программа, скажем, с 8-гигабайтным heap, то выполнение GC займёт много времени – секунды или даже минуты. Естественно, что каждый раз останавливать приложение – вариант не подходящий. Потому и существуют другие алгоритмы, и используются часто. Copy Collection же работает хорошо в том случае, если у нас много мусора и мало полезных объектов.
В этом посте мы поговорим насчёт двух распространённых алгоритмов. Для интересующихся есть много информации в Сети и несколько хороших книг.
Следующий алгоритм называется Mark-Sweep-Compact Collection. У алгоритма три этапа:
1) «Mark»: помечаются неиспользуемые объекты (красные).
2) «Sweep»: эти объекты удаляются из памяти. Обратите внимание на пустые слоты на диаграмме.
3) «Compact»: объекты размещаются, занимая свободные слоты, что освобождает пространство на тот случай, если потребуется создать «большой» объект.

Но это всё теория, так что давайте посмотрим, как это работает, на примере. К счастью, JDK имеет визуальный инструмент для наблюдения за JVM в реальном времени, а именно jvisualvm. Лежит он прямо в bin JDK. Воспользуемся ею немного позже, сначала займёмся приложением.
Для разработки, билдов и зависимостей я воспользовался Maven, но вам он не нужен – просто скомпилируйте и запустите приложение, если вам так угодно.
Я выбрал простой JAR (98) и все по умолчанию для остального. Дальше переключился в директорию memoryTool и отредактировал pom.xml (ниже, добавил блок plugin). Это позволило мне запустить приложение прямо из Maven, передав необходимые параметры.
Если вы предпочитаете не использовать Maven, то можете запустить приложение следующей командой:
Ниже – код main-класса. Простая программа, в которой мы создаём объекты и далее выкидываем их, так что понятно, сколько памяти используется и мы можем посмотреть, что происходит с JVM.
Для сборки и выполнения кода используем следующую команду Maven:
mvn package exec:exec
Как только скомпилируете и будете готовы к дальнейшим действиям, запускайте ее и jvisualvm. Если вы не использовали jvisualvm ранее, то нужно установить плагин VisualGC: выберите Plugins в меню Tools, дальше вкладку Available Plugins. Выберите Visual GC и нажмите Install.
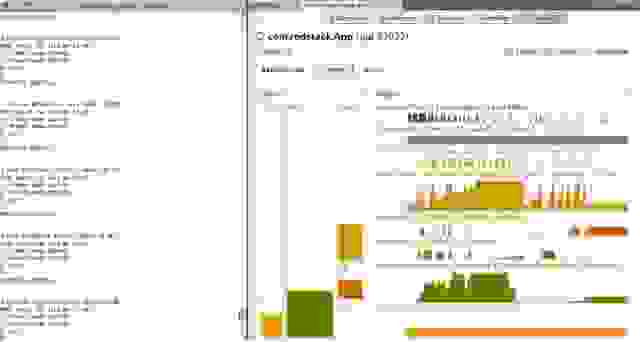
Вы должны увидеть список процессов JVM. Два раза кликните на том, в котором исполняется ваше приложение (в данном примере com.redstack.App) и откройте вкладку Visual GC. Должно появиться что-то типа того, что на скриншоте ниже.
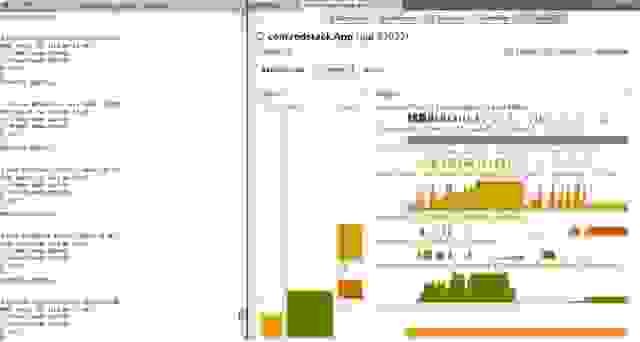
Обратите внимание, что можно визуально наблюдать состояние permanent generation, old generation, eden и сегментов survivor (S0 и S1). Цветные колонки показывают используемую память. Справа находится historical view, которое показывает, когда JVM проводило garbage collections и количество памяти в каждом из сегментов.
В окне приложения начните создавать объекты (опция 1) и наблюдайте, что будет происходить в Visual GC. Обратите внимание на то, что новые объекты всегда создаются в eden. Теперь сделайте пару объектов ненужными (опция 2). Возможно, вы не увидите изменений в Visual GC. Это потому, что JVM не чистит это пространство до тех пор, пока не закончена процедура garbage collection.
Чтобы инициировать garbage collection, создайте ещё объектов, заполнив Eden. Обратите внимание, что произойдет в момент заполнения. Если в Eden много мусора, вы увидите, как объекты из Eden «переезжают» в survivor. Однако, если в Eden мало мусора, вы увидите, как объекты «переезжают» в old generation. Это случается тогда, когда объекты, которые необходимо оставить, больше чем survival.
Пронаблюдайте также за постепенным увеличением Permanent Generation.
Попробуйте заполнить Eden, но не до конца, потом выбросьте почти все объекты, оставьте только 20 мб. Получиться так, что Eden на большую часть заполнен мусором. После этого создайте ещё объектов. На этот раз вы увидите, что объекты из Eden переходят в Survivor.
А теперь давайте посмотрим, что будет, если у нас не хватит памяти. Создавайте объекты до тех пор, пока их не будет на 460 мб. Обратите внимание, что и Eden и Old Generation заполнены практически полностью. Создайте ещё пару объектов. Когда больше не останется памяти, приложение «упадёт» с исключением OutOfMemoryException. Вы уже могли сталкиваться с подобным поведением и думать, почему же это произошло – особенно, если у вас большой объем физической памяти на компьютере и вы удивлялись, как такое вообще могло произойти, что не хватает памяти – теперь вы знаете, почему. Если так случится, что Permanent Generation заполнится (довольно сложно в случае нашего примера добиться этого), у вас будет брошено другое исключение, сообщающее, что PermGen заполнен.
И, наконец, ещё один способ посмотреть, что происходило, это обратиться к логу. Вот немного из моего:
В логе можно увидеть, что происходило в JVM — обратите внимание, что использовался алгоритм Concurrent Mark Sweep Compact Collection algorithm (CMS), есть описание этапов и YG — Young Generation.
Можно воспользоваться этими настройками и в «продакшене». Есть даже инструменты, визуализирующие лог.
Ну, вот и закончилось наше краткое введение в теории и практики JVM garbage collection. Надеюсь, что приложение из примера помогло вам чётко представить, что происходит в JVM когда запущено ваше приложение.
Спасибо Rupesh Ramachandran за то, чему он научил меня относительно настроек JVM и garbage collection.
Сборка мусора в Java: что это такое и как работает в JVM

May 11 · 12 min read

Что такое сборка мусора в Java?
Сборка мусора — это процесс восстановления заполненной памяти среды выполнения путем уничтожения неиспользуемых объектов.
В таких языках, как C и C++, программист отвечает как за создание, так и за уничтожение объектов. Иногда программист может забыть уничтожить бесполезные объекты, и выделенная им память не освобождается. Расходуется все больше и больше системной памяти, и в конечном итоге она больше не выделяется. Такие приложения страдают от “утечек памяти”.
Сборка мусора в Java — это процесс, с помощью которого программы Java автоматически управляют памятью. Java-программы компилируются в байт-код, который запускается на виртуальной машине Java (JVM).
Когда Java-программы выполняются на JVM, объекты создаются в куче, которая представляет собой часть памяти, выделенную для них.
Пока Java-приложение работает, в нем создаются и запускаются новые объекты. В конце концов некоторые объекты перестают быть нужны. Можно сказать, что в любой момент времени память кучи состоит из двух типов объектов.
Сборщик мусора находит эти неиспользуемые объекты и удаляет их, чтобы освободить память.
Как разыменовать объект в Java
Основная цель сборки мусора — освободить память кучи, уничтожив объекты, которые не содержат ссылку. Когда на объект нет ссылки, предполагается, что он мертв и больше не нужен. Таким образом, память, занятая объектом, может быть восстановлена.
Есть несколько способов убрать ссылки на объект и сделать его кандидатом на сборку мусора. Вот некоторые из них.
Сделать ссылку нулевой
Назначить ссылку другому объекту
Использовать анонимный объект
Как работает сборка мусора в Java?
Сборка мусора в Java — автоматический процесс. Программисту не нужно явно отмечать объекты, подлежащие удалению.
Сборка мусора производится в JVM. Каждая JVM может реализовать собственную версию сборки мусора. Однако сборщик должен соответствовать стандартной спецификации JVM для работы с объектами, присутствующими в памяти кучи, для маркировки или идентификации недостижимых объектов и их уничтожения через уплотнение.
Каковы источники для сборки мусора в Java?
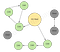
Сборщики мусора работают с концепцией корней сбора мусора (GC Roots) для идентификации живых и мертвых объектов.
Примеры таких корней.
Сборщик мусора просматривает весь граф объектов в памяти, начиная с этих корней и следуя ссылкам на другие объекты.
Этапы сборки мусора в Java
Стандартная реализация сборки мусора включает в себя три этапа.
Пометка объектов как живых
На этом этапе GC (сборщик мусора) идентифицирует все живые объекты в памяти путем обхода графа объектов.
Когда GC посещает объект, то помечает его как доступный и, следовательно, живой. Все объекты, недоступные из корней GC, рассматриваются как кандидаты на сбор мусора.

Зачистка мертвых объектов
После фазы разметки пространство памяти занято либо живыми (посещенными), либо мертвыми (не посещенными) объектами. Фаза зачистки освобождает фрагменты памяти, которые содержат эти мертвые объекты.

Компактное расположение оставшихся объектов в памяти
Мертвые объекты, которые были удалены во время предыдущей фазы, не обязательно находились рядом друг с другом. Поэтому вы рискуете получить фрагментированное пространство памяти.
Память можно уплотнить, когда сборщик мусора удалит мертвые объекты. Оставшиеся будут располагаться в непрерывном блоке в начале кучи.
Процесс уплотнения облегчает последовательное выделение памяти для новых объектов.

Что такое сбор мусора по поколениям?
Сборщики мусора в Java реализуют стратегию сбора мусора поколений, которая классифицирует объекты по возрасту.
Необходимость отмечать и уплотнять все объекты в JVM неэффективна. По мере выделения все большего количества объектов их список растет, что приводит к увеличению времени сбора мусора. Эмпирический анализ приложений показал, что большинство объектов в Java недолговечны.
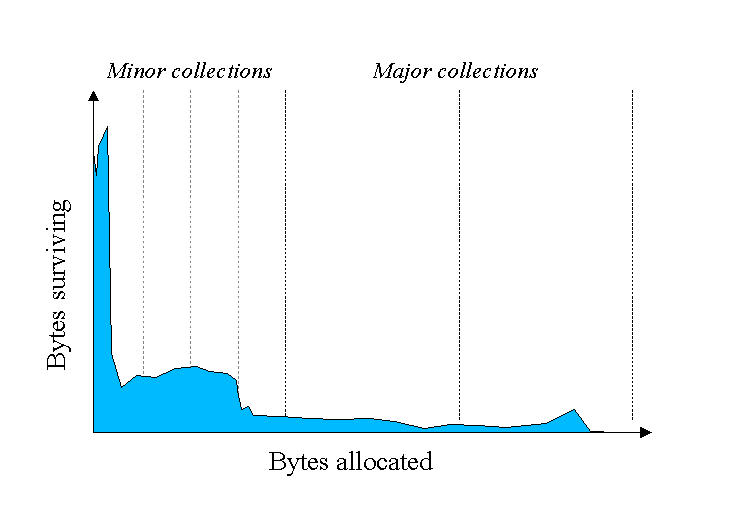
В приведенном выше примере ось Y показывает количество выделенных байтов, а ось X — количество выделенных байтов с течением времени. Как видно, со временем все меньше и меньше объектов сохраняют выделенную память.
Большинство объектов живут очень мало, что соответствует более высоким значениям в левой части графика. Вот почему Java классифицирует объекты по поколениям и выполняет сборку мусора в соответствии с ними.
Область памяти кучи в JVM разделена на три секции:

Молодое поколение
Вновь созданные объекты начинаются в молодом поколении. Молодое поколение далее подразделяется на две категории.
Процесс, когда объекты собираются в мусор из молодого поколения, называется малым событием сборки мусора.
Когда пространство Эдема заполнено объектами, выполняется малая сборка мусора. Все мертвые объекты удаляются, а все живые — перемещаются в одно из оставшихся двух пространств. Малая GC также проверяет объекты в пространстве выживших и перемещает их в другое (следующее) пространство выживших.
Возьмем в качестве примера следующую последовательность.
Таким образом, в любое время одно из пространств для выживших всегда пусто. Когда выжившие объекты достигают определенного порога перемещения по пространствам выживших, они переходят в старшее поколение.
Старшее поколение
Объекты-долгожители в конечном итоге переходят из молодого поколения в старшее. Оно также известно как штатное поколение и содержит объекты, которые долгое время оставались в пространствах выживших.
Пороговое значение срока службы объекта определяет, сколько циклов сборки мусора он может пережить, прежде чем будет перемещен в старшее поколение.
Процесс, когда объекты отправляются в мусор из старшего поколения, называется основным событием сборки мусора.
Поскольку Java задействует сборку мусора по поколениям, то чем больше событий сборки мусора переживает объект, тем дальше он продвигается в куче. Он начинает в молодом поколении и в конечном итоге заканчивает в штатном поколении, если проживет достаточно долго.
Чтобы понять продвижение объектов между пространствами и поколениями, рассмотрим следующий пример.
Когда объект создается, он сначала помещается в пространство Эдема молодого поколения. Как только происходит малая сборка мусора, живые объекты из Эдема перемещаются в пространство FromSpace. Когда происходит следующая малая сборка мусора, живые объекты как из Эдема, так и из пространства перемещаются в пространство ToSpace.
Этот цикл продолжается определенное количество раз. Если объект все еще “в строю” после этого момента, следующий цикл сборки мусора переместит его в пространство старшего поколения.
Постоянное поколение
Метаданные, такие как классы и методы, хранятся в постоянном поколении. JVM заполняет его во время выполнения на основе классов, используемых приложением. Классы, которые больше не используются, могут переходить из постоянного поколения в мусор.
Мета-пространство
Начиная с Java 8, на смену пространству постоянного поколения (PermGen) приходит пространство памяти MetaSpace. Реализация отличается от PermGen — это пространство кучи теперь изменяется автоматически.
Это позволяет избежать проблемы нехватки памяти у приложений, которая возникает из-за ограниченного размера пространства PermGen в куче. Память мета-пространства может быть собрана как мусор, и классы, которые больше не используются, будут автоматически очищены, когда мета-пространство достигнет максимального размера.
Типы сборщиков мусора в виртуальной машине Java
Сборка мусора повышает эффективности памяти в Java, поскольку объекты без ссылок удаляются из памяти кучи и освобождается место для новых объектов.
У виртуальной машины Java есть восемь типов сборщиков мусора. Рассмотрим каждый из них в деталях.
Серийный GC
Это самая простая реализация GC. Она предназначена для небольших приложений, работающих в однопоточных средах. Все события сборки мусора выполняются последовательно в одном потоке. Уплотнение выполняется после каждой сборки мусора.

Запуск сборщика приводит к событию “остановки мира”, когда все приложение приостанавливает работу. Поскольку на время сборки мусора все приложение замораживается, не следует прибегать к такому в реальной жизни, если требуется, чтобы задержки были минимальными.
Параллельный GC
Параллельный сборщик мусора предназначен для приложений со средними и большими наборами данных, которые выполняются на многопроцессорном или многопоточном оборудовании. Это реализация GC по умолчанию, и она также известна как сборщик пропускной способности.
Несколько потоков предназначаются для малой сборки мусора в молодом поколении. Единственный поток занят основной сборкой мусора в старшем поколении.

Запуск параллельного GC также вызывает “остановку мира”, и приложение зависает. Такое больше подходит для многопоточной среды, когда требуется завершить много задач и допустимы длительные паузы, например при выполнении пакетного задания.
Старый параллельный GC
Это версия Parallel GC по умолчанию, начиная с Java 7u4. Это то же самое, что и параллельный GC, за исключением того, что в нем применяются несколько потоков как для молодого поколения, так и для старшего поколения.
CMS (Параллельная пометка и зачистка) GC
Также известен как параллельный сборщик низких пауз. Для малой сборки мусора задействуются несколько потоков, и происходит это через такой же алгоритм, как в параллельном сборщике. Основная сборка мусора многопоточна, как и в старом параллельном GC, но CMS работает одновременно с процессами приложений, чтобы свести к минимуму события “остановки мира”.
Из-за этого сборщик CMS потребляет больше ресурсов процессора, чем другие сборщики. Если у вас есть возможность выделить больше ЦП для повышения производительности, то CMS предпочтительнее, чем простой параллельный сборщик. В CMS GC не выполняется уплотнение.
G1 (Мусор — первым) GC
G1GC был задуман как замена CMS и разрабатывался для многопоточных приложений, которые характеризуются крупным размером кучи (более 4 ГБ). Он параллелен и конкурентен, как CMS, но “под капотом” работает совершенно иначе, чем старые сборщики мусора.
Хотя G1 также действует по принципу поколений, в нем нет отдельных пространств для молодого и старшего поколений. Вместо этого каждое поколение представляет собой набор областей, что позволяет гибко изменять размер молодого поколения.
G1 разбивает кучу на набор областей одинакового размера (от 1 МБ до 32 МБ — в зависимости от размера кучи) и сканирует их в несколько потоков. Область во время выполнения программы может неоднократно становиться как старой, так и молодой.
После завершения этапа разметки G1 знает, в каких областях содержится больше всего мусора. Если пользователь заинтересован в минимизации пауз, G1 может выбрать только несколько областей. Если время паузы неважно для пользователя или предел этого времени установлен высокий, G1 пройдет по большему числу областей.
Поскольку G1 GC идентифицирует регионы с наибольшим количеством мусора и сначала выполняет сбор мусора в них, он и называется: “Мусор — первым”.

Помимо областей Эдема, Выживших и Старой памяти, в G1GC присутствуют еще два типа.
Сборщик мусора Эпсилон
Epsilon — сборщик мусора, который был выпущен как часть JDK 11. Он обрабатывает выделение памяти, но не реализует никакого реального механизма восстановления памяти. Как только доступная куча исчерпана, JVM завершает работу.
Его можно задействовать для приложений, чувствительных к сверхвысокой задержке, где разработчики точно знают объем памяти приложения или даже добиваются ситуации (почти) полной свободы от мусора. В противном случае пользоваться Epsilon GC не рекомендуется.
Шенандоа
Shenandoah — новый GC, выпущенный как часть JDK 12. Ключевое преимущество Shenandoah перед G1 состоит в том, что большая часть цикла сборки мусора выполняется одновременно с потоками приложений. G1 может эвакуировать области кучи только тогда, когда приложение приостановлено, а Shenandoah перемещает объекты одновременно с приложением.
Shenandoah может компактировать живые объекты, очищать мусор и освобождать оперативную память почти сразу после обнаружения свободной памяти. Поскольку все это происходит одновременно, без приостановки работы приложения, то Shenandoah более интенсивно нагружает процессор.
ZGC — еще один GC, выпущенный как часть JDK 11 и улучшенный в JDK 12. Он предназначен для приложений, которые требуют низкой задержки (паузы в менее чем 10 мс) и/или задействуют очень большую кучу (несколько терабайт).
Основные цели ZGC — низкая задержка, масштабируемость и простота в применении. Для этого ZGC позволяет Java-приложению продолжать работу, пока выполняются все операции по сбору мусора. По умолчанию ZGC освобождает неиспользуемую память и возвращает ее в операционную систему.
Таким образом, ZGC привносит значительное улучшение по сравнению с другими традиционными GCS, обеспечивая чрезвычайно низкое время паузы (обычно в пределах 2 мс).

Примечание: как Shenandoah, так и ZGC планируется вывести из экспериментальной стадии в продакшен при выпуске JDK 15.
Как правильно выбрать сборщик мусора
Если у вашего приложения нет строгих требований ко времени задержки, вам стоит просто запустить приложение и предоставить выбор правильного сборщика самой JVM.
В большинстве случаев настройки по умолчанию отлично работают. При необходимости можно настроить размер кучи для повышения производительности. Если производительность по-прежнему не соответствует ожиданиям, попробуйте изменить сборщик в соответствии с требованиями вашего приложения.
Преимущества сборки мусора
У сборки мусора в Java множество преимуществ.
Прежде всего, это упрощает код. Не нужно беспокоиться о правильном назначении памяти и циклах высвобождения. Вы просто прекращаете использовать объект в коде, и память, которую он занимал, в какой-то момент автоматически восстановится.
Программистам, работающим на языках без сборки мусора (таких как C и C++), приходится реализовывать ручное управление памятью у себя в коде.
Также повышается эффективность памяти Java, поскольку сборщик мусора удаляет из памяти кучи объекты без ссылок. Это освобождает память кучи для размещения новых объектов.
Некоторые программисты выступают за ручное управление памятью вместо сборки мусора, но сборка мусора — уже стандартный компонент многих популярных языков программирования.
Для сценариев, когда сборщик мусора негативно влияет на производительность, Java предлагает множество вариантов настройки, повышающих эффективность GC.
Рекомендации по сбору мусора
Избегайте ручных триггеров
Помимо основных механизмов сборки мусора, один из важнейших моментов относительно этого процесса в Java — недетерминированность. То есть невозможно предсказать, когда именно во время выполнения она произойдет.
С помощью методов System.gc() или Runtime.gc() можно включить в код подсказку для запуска сборщика мусора, но это не гарантирует, что он действительно запустится.
Пользуйтесь инструментами для анализа
Если у вас недостаточно памяти для запуска приложения, вы столкнетесь с замедлениями, длительным временем сбора мусора, событиями “остановки мира” и, в конечном итоге, ошибками из-за нехватки памяти. Возможно, это указывает, что куча слишком мала, но также может и значить, что в приложении произошла утечка памяти.
Вы можете прибегнуть к помощи инструмента мониторинга, например jstat или Java Flight Recorder, и увидеть, растет ли использование кучи бесконечно, что может указывать на ошибку в коде.
Отдавайте предпочтение настройкам по умолчанию
Если у вас небольшое автономное Java-приложение, вам, скорее всего, не понадобится настраивать сборку мусора. Настройки по умолчанию отлично вам послужат.
Пользуйтесь флагами JVM для настройки
Лучший подход к настройке сборки мусора в Java — установка JVM-флагов. С помощью флагов можно задать сборщик мусора (например, Serial, G1 и т.д.), начальный и максимальный размер кучи, размер разделов кучи (например, Молодого поколения, Старшего поколения) и многое другое.
Выбирайте сборщик правильно
Хороший ориентир в плане начальных настроек — характер настраиваемого приложения. К примеру, параллельный сборщик мусора эффективен, но часто вызывает события “остановки мира”, что делает его более подходящим для внутренней обработки, где допустимы длительные паузы.
С другой стороны, сборщик мусора CMS предназначен для минимизации задержек, а значит идеально подходит для веб-приложений, где важна скорость реагирования.
Вывод
В этой статье мы обсудили сборку мусора Java, механизм ее работы и ее типы.
Для многих простых Java-приложений программисту нет необходимости сознательно отслеживать сборку мусора. Однако тем, кто хочет развить навыки работы с Java, важно понимать, как происходит данный процесс.
Это также очень популярный вопрос на собеседованиях: как на миддл-, так и на сеньор-позиции в бэкенд-разработке.



