Разбор кода и построение синтаксических деревьев с PLY. Основы

Что такое PLY?
PLY — это аббревиатура из первых букв выражения: Python Lex-Yacc.
Фактически, это порт утилит lex и yacc на python в красивой обертке.
Работать с ply очень просто и порог входа для начала использования практически нулевой.
Написан он на чистом питоне и представляет из себя LALR(1) парсер, но кому это интересно?
Я по натуре практик (как и большинсво из вас) поэтому пошли в бой!
Что будем делать?
На сайте есть пример написания очередного калькулятора, поэтому повторяться не будем. А сделаем что-то навроде парсера очень очень узкого подмножества PHP 🙂
Наша задача в конце статьи построить синтаксическое дерево для такого примера:
Пример очень маленький и взят с потолка. Но чтобы построить дерево кода нужно много и походу мы задействуем такой механизм PLY как state.
Lex — это штука, которая разбивает текст на базовые элементы языка. Ну или группирует текст в базовые элементы. Как-то так.
Что мы здесь видим, кроме бесполезного кода? Видим токены (базовые элементы):
PHP_START — ‘ _. Ниже приведены измененные токены.
Кстати, заметили это: LexToken(PHPFUNC,’echo’,5,59)?
PLY перед построением таблицы сортирует регулярные выражения по возрастанию и в процессе парсинга побеждает длиннейшее. Вот поэтому echo и не парсится как PHPECHO. Как это обойти? Легко. Просто изменим тип возвращаемого токена в функции.
Вот так:
Теперь echo возвращается как нужно. Кстати о декораторе TOKEN: вместо того, чтобы писать регулярку в начале тела функции, можно просто поместить её в переменную и применить к функции как декоратор. Что мы и сделали.
Вот. Теперь вроде все. Да не все.
Неплохо бы игнорировать комментарии.
Что же, добавим еще одну маленькую функцию в лексер:
Вот теперь переходим к парсеру (parser.py).
Yacc — это штука (парсер), в которую мы передаем токены и описываем правила их соединения (грамматику). Походу работы этой программы мы можем создать абстрактное дерево или же сразу выполнять программу (как это сделано в примере с калькулятором на сайте).
В PLY для описания грамматики существует класс ply.yacc.
Описывать граматику в ply очень просто и это доставляет даже некоторое наслаждение. Для описания у нас снова существуют специальные функции p_имяфункции, где в doc-строках мы и описываем эту самую грамматику.
Давайте попробуем написать очень простую грамматику для нашего абстрактного примера с php:
Текста написано уже много, и рассказывать еще можно очень долго. Но для понимания основ ply.yacc достаточно разобрать один пример. А дальше я уже выложу исходник парсера.
Итак, выдранный кусок из парсера:
По сути правило выше — это скомбинированное (слитое) правило. ‘|’ как несложно догадаться — это ИЛИ, ну или различные варианты токена.
Между двоеточием и левой/правой частью обязателен пробел. Так любит ply. Если правая часть может быть пустой, то после двоеточия ничего не пишем. Токены должны быть написаны большими буквами, а правила маленькими, без префикса p_. Т.е. в примере выше использовались правила p_str и p_phpvar.
Кстати, иногда более удобен вариант с разделенными вариантами (тафтология, простите):
Он абсолютно идентичен предыдущему варианту кода. Просто фломастеры другие. Функции имеют разные названия (потому что разделять их надо в питоне), но префиксы идентичные (str), что и заставляет ply группировать их вместе как варианты одного правила.
Для удобства построения дерева я использовал такой простенький и эффективный класс:
Он одновременно и хранит все нужное, и структурирует вывод, что чень удобно при отладке.
Работа с абстрактными синтаксическими деревьями JavaScript
Зачем парсить свой код? Например, для того, чтобы найти забытый console.log перед коммитом. А что делать, если вам надо изменить сигнатуру функции в сотнях вхождений в коде? Справятся ли тут регулярные выражения? В этой статье будет показано, какие возможности перед разработчиком открывают абстрактные синтаксические деревья.
Под катом — видео и текстовая расшифровка доклада Кирилла Черкашина (z6Dabrata) с конференции HolyJS 2018 Piter.
Об авторе
Кирилл родился в Москве, сейчас живет в Нью-Йорке и работает в Firebase. Обучает Angular не только в Google, но и во всем мире. Организатор самого большого Angular-митапа в мире — AngularNYC (а также VueNYC и ReactNYC). В свободное от программирования время увлекается танго, книгами и приятными беседами.
Ножовка или дерево?
Начнем с примера: допустим, вы отладили программу и отправили внесенные изменения в git, после чего спокойно отправились спать. Утром оказалось, что коллеги скачали себе ваши изменения и, так как вы накануне забыли убрать вывод отладочной информации в консоль, она у них выводится и засоряет вывод. С подобной проблемой сталкивались многие.
Я написал 17 тестов, пытаясь придумать различные способы сломать нашу функцию. Этот список далеко не полный.
Самый простой тест пройден.
А если вдруг какая-либо функция содержит в своем названии строку «console.log»?
Добавили символ, который обозначает, что console.log должно встречаться в начале слова.
Пройдено лишь два теста, но что если console.log находится в комментарии и его не нужно удалять?
Перепишем так, чтобы парсер не трогал комментарии.
Исключаем удаление «console.log» из строк:
Не забываем, что у нас есть еще пробелы и другие символы, которые могут не дать пройти некоторым тестам:
Несмотря на то, что затея оказалась не совсем простой, все 17 тестов, используя регулярные выражения, пройти можно. Вот так, в данном случае, будет выглядеть код решения:
Проблема в том, что этот код не покрывает все возможные случаи, и поддерживать его довольно сложно.
Рассмотрим, как решить эту задачу при помощи АСД.
Как выращиваются деревья?
В результате его работы получается JSON-файл размером около 300 строк. Исключим из их числа строки со служебной информацией. Нас интересует раздел body. Метаинформация нас тоже не интересует. В итоге получается около 100 строк. По сравнению с тем, какую структуру генерирует браузер для одной переменной body (около 300 строк) – это немного.
Рассмотрим несколько примеров, как представляются различные литералы в коде в синтаксическом дереве:
Это выражение, в котором есть Numeric Literal, числовой литерал.
Уже знакомое нам выражение console.log. В нем есть объект, у которого есть свойство.
Если log – это вызов функции, тогда описание выглядит следующим образом: есть выражение вызова, у него есть аргументы – числовые литералы. В то же время у вызывающего выражения есть имя – log.
Литералы бывают разными: числа, строки, регулярные выражения, boolean, null.
Вернемся к вызову «console.log»
Это выражение вызова, внутри которого есть Member Expression. Из него понятно, что у объекта console внутри есть свойство, которое называется log.
Обход АСД
Теперь попробуем поработать с этой структурой в коде. Для обхода дерева будет использована библиотека babel-traverse.
Даны те же 17 тестов. Такой код получается при анализе синтаксического дерева программы и поиске вхождений «console.log»:
Разберем, что здесь написано. const ast = babylon.parse(code); в переменную ast парсим синтаксическое дерево из кода. Далее даем библиотеке babel-parse это дерево на обработку. Ищем в нем узлы и свойства с совпадающими именами внутри выражений вызовов. Выставляем переменную hasConsoleLog в true, если требуемое сочетание узлов и их названий найдено.
Мы может перемещаться по дереву, брать родителей узлов, потомков, искать, какие у них есть аргументы и свойства, смотреть названия этих свойств, типы – это очень удобно.
Перепишем предыдущий код с использованием babel-types:
Трансформируем АСД с помощью babel-traverse
Для сокращения трудозатрат нам нужно, чтобы console.log сразу удалялся из кода — вместо сигнала о том, что он есть в коде.
Из функции removeConsoleLog у нас все еще возвращается булево значение. Мы заменяем его вывод на код, который сгенерирует babel-generator, вот так:
hasConsoleLog => babelGenerator(ast).code
А если нужно найти debugger?
На этот раз для выполнения задачи мы будем использовать ASTexplorer. Debugger относится к типу узлов debugger statement. Нам не нужно смотреть всю структуру, так как это особый вид узла, достаточно просто найти debugger statement. Мы напишем плагин для ESLint (на ASTexplorer).
ASTexplorer устроен таким образом, что вы пишите кода слева, а справа получаете готовое АСД. Можно выбрать, в каком формате вы хотите его получить: JSON или в формате древа.
Так как мы используем ESLint, он выполнит за нас всю работу по поиску файлов и отдаст нам нужный файл, чтобы мы могли найти в нем строку debugger. В данном инструменте используется другой парсер АСД. Впрочем и самих АСД в JavaScript существует несколько видов. Чем-то напоминает прошлое, когда разные браузеры по-разному реализовывали спецификацию. Таким образом, мы реализуем поиск debugger’а:
Проверка работы написанного плагина:
Точно так же можно удалить debugger из кода.
Чем еще полезны АСД
Я лично использую АСД для упрощения работы с Angular и другими фронтенд фреймворками. Можно нажатием одной кнопки что-то импортировать, расширять, добавлять интерфейс, метод, декоратор и что-либо еще. Хотя речь в данном случае идет о Javascript, тем не менее, в TypeScript тоже есть свои АСД, разница только в отличии названий типов узлов и структуре. В том же ASTExplorer можно выбрать в качестве языка TypeScript.
Несколько полезных ссылок для Babel
Бонус
Как еще можно найти наш console.log в коде? Использовать вашу IDE! С помощью инструмента «найти и заменить», предварительно выбрав, в каких местах кода искать.
Также в Intellij IDEA есть инструмент «структурный поиск», который может помочь найти нужные места в коде, к слову, он использует АСД.
24-25 ноября Кирилл выступит на московской HolyJS с докладом «JavaScript *LOVES* binary data»: опустимся на уровень бинарных данных, покопаемся в бинарных файлах на примере *.gif-файлов и разберемся с сериализующими фреймворками, такими как Protobuf или Thrift. После доклада можно будет пообщаться с Кириллом и обсудить все интересующие вопросы в дискуссионной зоне.

СОДЕРЖАНИЕ
Номенклатура

Деревья синтаксического анализа на основе избирательных округов
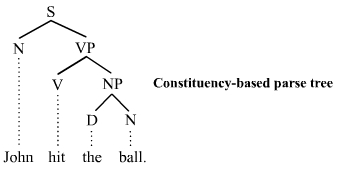
Деревья синтаксического анализа грамматик избирательных округов (= грамматик структуры фраз ) различают терминальные и нетерминальные узлы. В внутренних узлах помечены нетерминальными категориями грамматики, а листовые узлы помечены терминальные категории. На изображении ниже представлено дерево синтаксического анализа на основе избирательных округов; он показывает синтаксическую структуру английского предложения John hit the ball :
Деревья синтаксического анализа на основе зависимостей
Основанные на зависимостях деревья синтаксического анализа грамматик зависимостей рассматривают все узлы как терминальные, что означает, что они не признают различия между терминальными и нетерминальными категориями. В среднем они проще, чем деревья синтаксического анализа на основе избирательных округов, поскольку содержат меньше узлов. Дерево синтаксического анализа на основе зависимостей для приведенного выше примера предложения выглядит следующим образом:
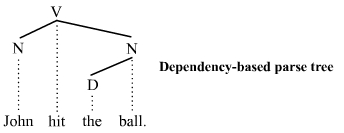
В этом дереве синтаксического анализа отсутствуют фразовые категории (S, VP и NP), которые можно найти в приведенном выше аналоге на основе избирательных округов. Как и в дереве на основе избирательных округов, структура участников признается. Любое полное поддерево дерева является составной частью. Таким образом, это основанное на зависимостях дерево синтаксического анализа признает подлежащее существительное Джон и объектное существительное, выражающее мяч, как составные части, как и дерево синтаксического анализа на основе избирательных округов.
Различие между контингентом и зависимостью имеет далеко идущие последствия. Вопрос о том, нужна ли дополнительная синтаксическая структура, связанная с деревьями синтаксического анализа на основе избирательных округов, является предметом споров.
Маркеры фраз
Маркеры фраз могут быть представлены в виде деревьев (как в приведенном выше разделе о деревьях синтаксического анализа на основе избирательных округов ), но вместо этого часто даются в виде «выражений в квадратных скобках», которые занимают меньше места в памяти. Например, выражение в квадратных скобках, соответствующее приведенному выше дереву на основе избирательных округов, может выглядеть примерно так:
Как и в случае с деревьями, точное построение таких выражений и количество показываемых деталей может зависеть от применяемой теории и от моментов, которые автор запроса хочет проиллюстрировать.
Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Все мы знаем о том, что JavaScript-код веб-проектов может разрастаться до прямо-таки огромных размеров. А чем больше размер кода — тем дольше браузер будет его загружать. Но проблема тут не только во времени передачи данных по сети. После того, как программа загрузится, её ещё надо распарсить, скомпилировать в байт-код, и, наконец, выполнить. Сегодня мы представляем вашему вниманию перевод 14 части серии материалов об экосистеме JavaScript. А именно, речь пойдёт о синтаксическом анализе JS-кода, о том, как строятся абстрактные синтаксические деревья, и о том, как программист может повлиять на эти процессы, добившись повышения скорости работы своих приложений.

Как устроены языки программирования
Прежде чем говорить об абстрактных синтаксических деревьях, остановимся на том, как устроены языки программирования. Вне зависимости от того, какой именно язык вы используете, вам всегда приходится применять некие программы, которые принимают исходный код и преобразуют его в нечто такое, что содержит конкретные команды для машин. В роли таких программ выступают либо интерпретаторы, либо компиляторы. Неважно, пишете ли вы на интерпретируемом языке (JavaScript, Python, Ruby), или на компилируемом (C#, Java, Rust), ваш код, представляющий собой обычный текст, всегда будет проходить этап парсинга, то есть — превращения обычного текста в структуру данных, которая называется абстрактным синтаксическим деревом (Abstract Syntax Tree, AST).
Абстрактные синтаксические деревья не только дают структурированное представление исходного кода, они, кроме того, играют важнейшую роль в семантическом анализе, в ходе которого компилятор проверяет правильность программных конструкций и корректность использования их элементов. После формирования AST и выполнения проверок эта структура используется для генерирования байт-кода или машинного кода.
Применение абстрактных синтаксических деревьев
Абстрактные синтаксические деревья используются не только в интерпретаторах и компиляторах. Они, в мире компьютеров, оказываются полезными и во многих других областях. Один из наиболее часто встречающихся вариантов их применения — статический анализ кода. Статические анализаторы не выполняют передаваемый им код. Однако, несмотря на это, им нужно понимать структуру программ.
Предположим, вы хотите разработать инструмент, который находит в коде часто встречающиеся структуры. Отчёты такого инструмента помогут в рефакторинге, позволят уменьшить дублирование кода. Сделать это можно, пользуясь обычным сравнением строк, но такой подход окажется весьма примитивным, возможности его будут ограниченными. На самом деле, если вы хотите создать подобный инструмент, вам не нужно писать собственный парсер для JavaScript. Существует множество опенсорсных реализаций подобных программ, которые полностью совместимы со спецификацией ECMAScript. Например — Esprima и Acorn. Существуют и инструменты, которые могут помочь в работе с тем, что генерируют парсеры, а именно, в работе с абстрактными синтаксическими деревьями.
Абстрактные синтаксические деревья, кроме того, широко используются при разработке транспиляторов. Предположим, вы решили разработать транспилятор, преобразующий код на Python в код на JavaScript. Подобный проект может быть основан на идее, в соответствии с которой используется транспилятор для создания абстрактного синтаксического дерева на основе Python-кода, которое, в свою очередь, преобразуется в код на JavaScript. Вероятно, тут вы зададитесь вопросом о том, как такое возможно. Всё дело в том, что абстрактные синтаксические деревья — это всего лишь альтернативный способ представления кода на некоем языке программирования. Прежде чем код преобразуется в AST, он выглядит как обычный текст, при написании которого следуют определённым правилам, которые формируют язык. После парсинга этот код превращается в древовидную структуру, которая содержит ту же информацию, что и исходный текст программы. В результате можно осуществить не только переход от исходного кода к AST, но и обратное преобразование, превратив абстрактное синтаксическое дерево в текстовое представление кода программы.
Парсинг JavaScript-кода
Поговорим о том, как строятся абстрактные синтаксические деревья. В качестве примера рассмотрим простую JavaScript-функцию:
Парсер создаст абстрактное синтаксическое дерево, которое схематично представлено на следующем рисунке.
Абстрактное синтаксическое дерево
Обратите внимание на то, что это — упрощённое представление результатов работы парсера. Настоящее абстрактное синтаксическое дерево выглядит гораздо сложнее. В данном случае наша главная цель — получить представление о том, во что, в первую очередь, превращается исходный код прежде чем он будет выполнен. Если вам интересно взглянуть на то, как выглядит реальное абстрактное синтаксическое дерево — воспользуйтесь сайтом AST Explorer. Для того, чтобы сгенерировать AST для некоего фрагмента JS-кода, его достаточно поместить в соответствующее поле на странице.
Возможно, тут у вас возникнет вопрос о том, зачем программисту знать о том, как работает JS-парсер. В конце концов, парсить и выполнять код — это задача браузера. В каком-то смысле вы правы. На рисунке ниже показаны затраты времени, требующиеся некоторым известным веб-проектам на выполнение различных шагов в процессе выполнения JS-кода.
Присмотритесь к этому рисунку, возможно, вы увидите там кое-что интересное.
Временные затраты на выполнение JS-кода
Видите? Если нет — посмотрите ещё раз. Собственно говоря, речь идёт о том, что, в среднем, браузеры тратят 15-20% времени на парсинг JS-кода. И это — не некие условные данные. Перед вами — статистические сведения о работе реальных веб-проектов, которые так или иначе используют JavaScript. Возможно, показатель в 15% может показаться вам не таким уж и большим, но, поверьте, это много. Типичное одностраничное приложение загружает примерно 0.4 Мб JavaScript-кода, а чтобы распарсить этот код браузеру надо примерно 370 мс. Опять же, вы можете сказать, что в этом нет ничего страшного. И да, само по себе это немного. Однако не стоит забывать о том, что это — лишь время, которое нужно на то, чтобы разобрать код и превратить его в AST. Сюда не входит время, необходимое на выполнение кода, или время, которое нужно на решение других задач, сопутствующих загрузке страницы, например — задач обработки HTML и CSS и рендеринга страницы. Причём, речь тут идёт лишь о настольных браузерах. В случае с мобильными системами всё ещё хуже. В частности, время парсинга одного и того же кода на мобильных устройствах может быть в 2-5 раз больше, чем на настольных. Взгляните на следующий рисунок.

Время парсинга 1 Мб JS-кода на различных устройствах
Здесь показано время, необходимое для разбора 1 Мб JS-кода на различных мобильных и настольных устройствах.
Кроме того, веб-приложения постоянно усложняются, на сторону клиента переносится решение всё большего количества задач. Направлено всё это на то, чтобы улучшить ощущения пользователей от работы с веб-сайтами, чтобы приблизить эти ощущения к тем, которые пользователи испытывают, взаимодействуя с традиционными приложениями. Несложно выяснить то, насколько сильно всё это воздействует на веб-проекты. Для этого достаточно открыть в браузере инструменты разработчика, зайти на какой-нибудь современный сайт и посмотреть, сколько времени тратится на парсинг кода, на компиляцию, и на всё остальное, происходящее в браузере при подготовке страницы к работе.
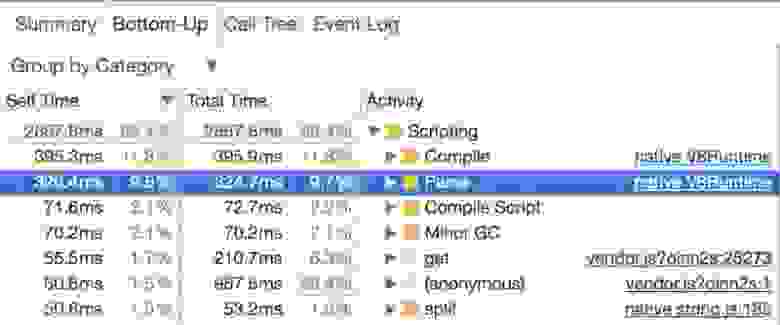
Анализ сайта с помощью инструментов разработчика в браузере
К несчастью, мобильные браузеры не обладают подобными инструментами. Однако, это не означает, что мобильные версии сайтов невозможно анализировать. Тут нам на помощь придут инструменты вроде DeviceTiming. С помощью DeviceTiming можно измерить время, необходимое для парсинга и выполнения скриптов в управляемых окружениях. Работает это благодаря помещению локальных скриптов в окружение, формируемое вспомогательным кодом, что приводит к тому, что каждый раз, когда страница загружается с различных устройств, у нас появляется возможность локально измерить время парсинга и выполнения кода.
Оптимизация парсинга и JS-движки
JS-движки делают много полезного для того, чтобы избежать ненужной работы и оптимизировать процессы обработки кода. Вот несколько примеров.
Движок V8 поддерживает потоковую передачу скриптов и кэширование кода. Под потоковой передачей в данном случае понимается то, что система занимается парсингом скриптов, загружающихся асинхронно, и скриптов, выполнение которых отложено, в отдельном потоке, начиная это делать с момента начала загрузки кода. Это ведёт к тому, что парсинг завершается практически одновременно с завершением загрузки скрипта, что даёт примерно 10% уменьшение времени, необходимого на подготовку страниц к работе.
JavaScript-код обычно компилируется в байт-код при каждом посещении страницы. Этот байт-код, однако, теряется после того, как пользователь переходит на другую страницу. Происходит это из-за того, что скомпилированный код сильно зависит от состояния и контекста системы во время компиляции. Для того чтобы улучшить ситуацию в Chrome 42 появилась поддержка кэширования байт-кода. Благодаря этому новшеству скомпилированный код хранится локально, в результате, когда пользователь возвращается на уже посещённую страницу, для подготовки её к работе не нужно выполнять загрузку, парсинг и компиляцию скриптов. Это позволяет Chrome сэкономить примерно 40% времени на задачах парсинга и компиляции. Кроме того, в случае с мобильными устройствами, это ведёт к экономии заряда их аккумуляторов.
Движок Carakan, который применялся в браузере Opera и уже довольно давно заменён на V8, мог повторно использовать результаты компиляции уже обработанных скриптов. При этом не требовалось, чтобы эти скрипты были бы подключены к одной и той же странице или даже были бы загружены с одного домена. Эта техника кэширования, на самом деле, весьма эффективна и позволяет полностью отказаться от шага компиляции. Она полагается на типичные сценарии поведения пользователей, на то, как люди работают с веб-ресурсами. А именно, когда пользователь следует определённой последовательности действий, работая с веб-приложением, загружается один и тот же код.
Интерпретатор SpiderMonkey, используемый в FireFox, не занимается кэшированием всего подряд. Он поддерживает систему мониторинга, которая подсчитывает количество вызовов определённого скрипта. На основе этих показателей определяются участки кода, которые нуждаются в оптимизации, то есть — те, на которые приходится максимальная нагрузка.
Конечно, некоторые разработчики браузеров могут решить, что кэширование их продуктам и вовсе не нужно. Так, Масей Стачовяк, ведущий разработчик браузера Safari, говорит, что Safari не занимается кэшированием скомпилированного байт-кода. Возможность кэширования рассматривалась, но она до сих пор не реализована, так как генерация кода занимает менее 2% общего времени выполнения программ.
Эти оптимизации не влияют напрямую на парсинг исходного кода на JS. В ходе их применения делается всё возможное, чтобы, в определённых случаях, полностью пропустить этот шаг. Каким бы быстрым ни был парсинг, он, всё же, занимает некоторое время, а полное отсутствие парсинга — это, пожалуй, пример идеальной оптимизации.
Сокращение времени подготовки веб-приложений к работе
Как мы выяснили выше, хорошо было бы свести необходимость в парсинге скриптов к минимуму, но совсем избавиться от него нельзя, поэтому поговорим о том, как сократить время, необходимое для подготовки веб-приложений к работе. На самом деле, для этого можно сделать очень много всего. Например, можно минимизировать объём JS-кода, входящего в приложение. Код маленького объёма, готовящий страницу к работе, можно быстрее разобрать, да и его выполнение, вероятнее всего, займёт меньше времени, чем у кода более объёмного.
Для того чтобы сократить объём кода, можно организовать загрузку на страницу только того, что ей действительно необходимо, а не некоего огромного куска кода, в который входит абсолютно всё, нужное для веб-проекта в целом. Так, например, паттерн PRPL продвигает именно такой подход к загрузке кода. В качестве альтернативного варианта можно проверить зависимости и посмотреть, есть ли в них что-то избыточное, такое, что приводит лишь к неоправданному разрастанию кодовой базы. На самом деле, тут мы затронули большую тему, достойную отдельного материала. Вернёмся к парсингу.
Итак, цель данного материала заключается в обсуждении методик, позволяющих веб-разработчику помочь парсеру быстрее делать его работу. Такие методики существуют. Современные JS-парсеры используют эвристические алгоритмы для того, чтобы определить, понадобится ли выполнить некий фрагмент кода как можно скорее, или его нужно будет выполнить позже. Основываясь на этих предсказаниях, парсер либо полностью анализирует фрагмент кода, применяя алгоритм жадного синтаксического анализа (eager parsing), либо использует ленивый алгоритм синтаксического анализа (lazy parsing). При полном анализе разбираются функции, которые нужно скомпилировать как можно скорее. В ходе этого процесса выполняется решение трёх основных задач: построение AST, создание иерархии областей видимости и поиск синтаксических ошибок. Ленивый анализ, с другой стороны, используется только для функций, которые пока не нуждаются в компиляции. Здесь не создаётся AST и не выполняется поиск ошибок. При таком подходе лишь создаётся иерархия областей видимости, что позволяет сэкономить примерно половину времени в сравнении с обработкой функций, которые нужно выполнить как можно скорее.
На самом деле, концепция это не новая. Даже устаревшие браузеры вроде IE9 поддерживают подобные подходы к оптимизации, хотя, конечно, современные системы ушли далеко вперёд.
Разберём пример, иллюстрирующий работу этих механизмов. Предположим, у нас имеется следующий JS-код:
Как и в предыдущем примере, код попадает в парсер, который выполняет его синтаксический анализ и формирует AST. В результате парсер представляет код, состоящий из следующих основных частей (на функцию foo обращать внимания не будем):
Результат разбора кода примера без применения оптимизации
В результате, в предыдущем примере, настоящий парсер сформирует структуру, напоминающую следующую схему.
Результат разбора кода примера с оптимизацией
В вышеописанной концепции нет ничего сложного, но её практическая реализация — задача не из лёгких. Здесь мы рассмотрели очень простой пример, а, на самом деле, при принятии решения о том, будет ли некий фрагмент кода востребован в программе, нужно анализировать и функции, и циклы, и условные операторы, и объекты. В целом можно сказать, что парсеру нужно обработать и проанализировать абсолютно всё, что есть в программе.
Вот, например, весьма распространённый паттерн реализации модулей в JavaScript:
Большинство современных JS-парсеров распознают этот паттерн, он для них является сигналом того, что код, расположенный внутри модуля, нужно полностью проанализировать.
А что если бы парсеры всегда использовали ленивый синтаксический анализ? Это, к сожалению, не самая хорошая идея. Дело в том, что при таком подходе, если некий код надо выполнить как можно скорее, мы столкнёмся с замедлением работы системы. Парсер выполнит один проход ленивого синтаксического анализа, после чего тут же примется за полный анализ того, что нужно выполнить как можно скорее. Это приведёт к примерно 50% замедлению в сравнении с подходом, когда парсер сразу приступает к полному разбору самого важного кода.
Оптимизация кода с учётом особенностей его разбора
Теперь, когда мы немного разобрались с тем, что происходит в недрах парсеров, пришло время подумать о том, что можно сделать для того, чтобы им помочь. Мы можем писать код так, чтобы синтаксический анализ функций производился в нужное нам время. Тут существует один паттерн, который понимают большинство парсеров. Он выражается в том, что функции заключают в скобки. Такая конструкция практически всегда сообщает парсеру о том, что функцию надо разобрать безотлагательно. Если парсер обнаруживает открывающую скобку, сразу после которой следует объявление функции, он немедленно приступит к синтаксическому анализу функции. Мы можем помочь парсеру, применяя этот приём при описании функций, которые нужно выполнить как можно скорее.
Предположим, у нас имеется функция foo :
Так как в этом фрагменте кода нет явного указания на то, что эту функцию планируется выполнить немедленно, браузер выполнит лишь её ленивый синтаксический анализ. Однако мы уверены в том, что эта функция понадобится нам очень скоро, поэтому мы можем прибегнуть к следующему приёму.
Для начала сохраним функцию в переменной:
После вышеописанного изменения парсер продолжит использовать ленивый синтаксический анализ. Для того чтобы это изменить, достаточно одной небольшой детали. Функцию надо заключить в скобки:
Подобные оптимизации может оказаться непросто выполнять вручную, так как для этого нужно знать то, в каких случаях парсер будет выполнять ленивый синтаксический анализ, а в каких — полный. Кроме того, для этого нужно потратить время на принятие решения о том, нуждается ли конкретная функция в как можно более быстрой готовности к работе или нет.
Программистам, наверняка, не захочется взваливать на себя всю эту дополнительную работу. Кроме того, что не мене важно чем всё то, о чём уже было сказано, код, обработанный таким образом, будет сложнее читать и понимать. В этой ситуации нам на помощь готовы прийти специальные программные пакеты вроде Optimize.js. Их основная цель заключается в оптимизации времени первоначальной загрузки исходного кода на JS. Они выполняют статический анализ кода и модифицируют его так, чтобы функции, которые нужно выполнить как можно скорее, были бы заключены в скобки, что приводит к тому, что браузер немедленно займётся их разбором и подготовкой к выполнению.
Итак, предположим, что мы программируем, ни о чём особо не задумываясь, и у нас имеется следующий фрагмент кода:
Вроде и тут всё нормально, код работает так же, как работал раньше. Однако если присмотреться, окажется что кое-чего в этом минифицированном фрагменте исходной программы не хватает.
Минификатор убрал скобки, в которые было заключено объявление функции, поместив в начало строки восклицательный знак. Это означает, что парсер данную строчку пропустит, то, что она будет обработана с использованием ленивого синтаксического анализа. Более того, для того, чтобы выполнить эту функцию, системе придётся выполнять полный анализ сразу после ленивого. Всё это приведёт к тому, что такой вот минифицированный код будет работать медленнее, чем его исходный вариант. Теперь пришло время вспомнить об инструментах вроде вышеупомянутого Optimize.js. Если обработать минифицированный код с помощью Optimize.js, на выходе получится следующее:
Это уже больше похоже на то, что нам нужно. Мы получаем и минификацию, и оптимизацию кода. Текст программы занимает меньше места на диске, а парсеру понятно, какие фрагменты нужно разбирать полностью и как можно скорее, а какие — используя методику ленивого синтаксического анализа.
Предварительная компиляция
Как видите, подготовка JS-кода к работе — дело, требующее немалых системных ресурсов. Почему бы не выполнять всё это на сервере? В конце концов, гораздо лучше один раз подготовить программу к выполнению и передавать то, что получилось, клиентам, нежели принуждать каждую клиентскую систему каждый раз обрабатывать исходный код. На самом деле, эта возможность сейчас обсуждается, в частности, вопрос заключается в том, должны ли браузерные JS-движки предлагать механизмы выполнения предварительно скомпилированных скриптов, чтобы освободить браузеры от задач по подготовке кода к выполнению. В целом, идея заключается в том, чтобы у нас был некий серверный инструмент, умеющий генерировать байт-код, который достаточно передать клиенту по сети и выполнить. Это даст значительное сокращение времени подготовки веб-страниц к работе. И хотя выглядит подобный механизм довольно соблазнительно, на самом деле, не всё так просто. Подготовка кода к работе на сервере может произвести обратный эффект, так как объём передаваемых данных, вероятно, возрастёт, может возникнуть необходимость в подписывании кода и в его проверке для целей обеспечения безопасности. Кроме того, JS-движки развиваются в уже сформировавшемся русле, в частности, команда разработчиков V8 работает над внутренними механизмами движка, направленными на то, чтобы избавиться от повторного парсинга. Подобные подходы к оптимизации на стороне клиента могут сделать предварительную компиляцию на сервере уже не столь привлекательной.
Советы по оптимизации
Вот несколько рекомендаций, которыми вы можете воспользоваться для оптимизации веб-приложений:
Итоги
Автор этого материала говорит, что в его компании, которая занимается разработкой системы SessionStack, предназначенной для мониторинга и записи того, что происходит на веб-страницах, вышеописанные приёмы оптимизации начали использовать сравнительно недавно. Это позволяет им сделать так, чтобы код приложения быстрее загружался и готовился к работе. Чем быстрее это происходит — тем приятнее пользователям будет работать с системой. Пожалуй, обеспечение удобства работы пользователей — это одна из задач, которую стремятся решить разработчики любого веб-проекта, и то, о чём шла речь в этом материале, вполне способно помочь в решении этой задачи.
Уважаемые читатели! Оптимизируете ли вы ваши веб-проекты с учётом скорости загрузки и разбора их JavaScript-кода?



