Как случайность может помочь математикам
Случайность, казалось бы, усложняет доказательство теорем. Но на самом деле, часто её эффект получается противоположным

Из всех доступных математикам инструментов случайность, казалось бы, имеет меньше всего преимуществ. Математика оперирует логикой и строгими понятиями. Её общие цели – поиск порядка и структуры в огромном море объектов. Вся математическая история кажется возможной именно потому, что мир математики не случаен.
И всё же недавняя статья «Случайные поверхности скрывают в себе замысловатый порядок» касалась нового доказательства, в котором всё решает случайность. Результат включает появление закономерностей типа шахматных клеток, появляющихся на геометрических пространствах, построенных случайным образом. Авторы доказательства обнаружили, что случайность в геометрическом пространстве упрощает описание этих закономерностей. «Довольно неожиданно, что добавление случайности позволяет вам сделать больше», чем без неё, сказал Николас Курьен, математик из университета Париж-юг XI, соавтор той работы.
И оказывается, что случайность помогает в математике множеством способов.
К примеру, математики часто хотят доказать, что существует объект с определёнными свойствами, к примеру, геометрическая фигура с определёнными симметриями. Наиболее прямой способ решить задачу существования – найти пример объекта, обладающего нужными вам свойствами. Однако попробуйте-ка это сделать. «Бывает очень сложно представить один конкретный объект с нужным свойством», — сказал Мартин Хэйрер, обладатель медали Филдса, работа которого связана со случайными процессами.
Если лобовая атака на проблему вряд ли увенчается успехом, можно попробовать зайти с фланга. К примеру, можно показать, что если бы мы рассмотрели все объекты определённого типа, и затем выбрали один из них случайным образом, то существует ненулевой шанс выбрать объект с нужным свойствам. Такой «вероятностный метод» первым применил математик Пал Эрдёш.
Случайность также можно использовать для поиска решений неслучайных задач. Так было сделано в недавнем доказательстве, касающемся шахматных закономерностей на решётке. Исследователи заинтересовались процессом под названием просачивание, когда вам нужно понять, при каких условиях можно пройти по точкам только одного цвета с одной части решётки до другой.
Рисуя такую закономерность по детерминистским правилам – по чётко определённым линиям правильной решётки – каждый следующий шаг на пути будет зависеть от каждого из предыдущих шагов. В случае сложной решётки это требование становится грузом. Это похоже на то, как легко разместить самые первые элементы в игре «Тетрис» – их можно класть куда угодно – но поздние размещать уже сложнее, поскольку им приходится удовлетворять положению всех предыдущих.
А когда ваш путь оказывается случайным, вам уже не нужно беспокоиться о предыдущих шагах. Каждый новый шаг становится в каком-то смысле первым: подкиньте монетку, чтобы решить, куда идти далее.
Математики пытаются использовать этот факт. Существует гипотетическая взаимосвязь, известная под названием уравнение Кардара-Паризи-Жанга (КПЖ), позволяющая математикам превращать результат, полученный на случайной решётке, в результат для детерминистской, и наоборот. «В теории это означает, что вы можете проводить вычисления и там и там», либо со случайной, либо с детерминистской стороны, сказал Оливье Бернарди, математик из Брандейского университета, и соавтор недавней работы. Эта работа соответствует предыдущим результатам (которые гораздо труднее доказать) по поводу просачивания по стандартной решётке, что подтверждает верность уравнения КПЖ.
Если бы математика была проще, математикам, возможно, не приходилось бы прибегать к случайности. Однако на наиболее важные математические вопросы математикам слишком сложно найти ответы. «Это может показаться очевидным, но полезно помнить, что в большинстве случаев при постановке задачи в математике или теоретической физике её невозможно решить»,- сказал Пол Бургад, математик из Нью-Йоркского университета. «У нас просто нет инструментов для её решения». В некоторых из этих ситуаций случайность упрощает ситуацию как раз достаточно для того, чтобы сделать решение возможным.
Краеугольный камень псевдослучайности: с чего начинается поиск чисел

(с)
Случайные числа постоянно генерируются каждой машиной, которая может обмениваться данными. И даже если она не обменивается данными, каждый компьютер нуждается в случайности для распределения программ в памяти. При этом, конечно, компьютер, как детерминированная система, не может создавать истинные случайные числа.
Когда речь заходит о генераторах случайных (или псевдослучайных) чисел, рассказ всегда строится вокруг поиска истинной случайности. Пока серьезные математики десятилетиями ведут дискуссии о том, что считать случайностью, в практическом отношении мы давно научились использовать «правильную» энтропию. Впрочем, «шум» — это лишь вершина айсберга.
С чего начать, если мы хотим распутать клубок самых сильных алгоритмов PRNG и TRNG? На самом деле, с какими бы алгоритмами вы не имели дело, все сводится к трем китам: seed, таблица предопределенных констант и математические формулы.
Каким бы ни был seed, еще есть алгоритмы, участвующие в генераторах истинных случайных чисел, и такие алгоритмы никогда не бывают случайными.
Что такое случайность
Первое подходящее определение случайной последовательности дал в 1966 году шведский статистик Пер Мартин-Лёф, ученик одного из крупнейших математиков XX века Андрея Колмогорова. Ранее исследователи пытались определить случайную последовательность как последовательность, которая проходила все тесты на случайность.
Основная идея Мартина-Лёфа заключалась в том, чтобы использовать теорию вычислимости для формального определения понятия теста случайности. Это контрастирует с идеей случайности в вероятности; в этой теории ни один конкретный элемент пространства выборки не может быть назван случайным.
«Случайная последовательность» в представлениях Мартина-Лёфа должна быть типичной, т.е. не должна обладать индивидуальными отличительными особенностями.
Было показано, что случайность Мартина-Лёфа допускает много эквивалентных характеристик, каждая из которых удовлетворяет нашему интуитивному представлению о свойствах, которые должны иметь случайные последовательности:
Существование множественных определений рандомизации Мартина-Лёфа и устойчивость этих определений при разных моделях вычислений свидетельствуют о том, что случайность Мартина-Лёфа является фундаментальным свойством математики.
Seed: основа псевдослучайных алгоритмов
Первые алгоритмы формирования случайных чисел выполняли ряд основных арифметических действий: умножить, разделить, добавить, вычесть, взять средние числа и т.д. Сегодня такие мощные алгоритмы, как Fortuna и Yarrow (используется в FreeBSD, AIX, Mac OS X, NetBSD) выглядят как генераторы случайных чисел для параноиков. Fortuna, например, это криптографический генератор, в котором для защиты от дискредитации после выполнения каждого запроса на случайные данные в размере 220 байт генерируются еще 256 бит псевдослучайных данных и используются в качестве нового ключа шифрования — старый ключ при этом каждый раз уничтожается.
Прошли годы, прежде чем простейшие алгоритмы эволюционировали до криптографически стойких генераторов псевдослучайных чисел. Частично этот процесс можно проследить на примере работы одной математической функции в языке С.
Функция rand () является простейшей из функций генерации случайных чисел в C.
В этом примере рандома используется вложенный цикл для отображения 100 случайных значений. Функция rand () хороша при создании множества случайных значений, но они являются предсказуемыми. Чтобы сделать вывод менее предсказуемым, вам нужно добавить seed в генератор случайных чисел — это делается с помощью функции srand ().
Seed — это стартовое число, точка, с которой начинается последовательность псевдослучайных чисел. Генератор псевдослучайных чисел использует единственное начальное значение, откуда и следует его псевдослучайность. Генератор истинных случайных чисел всегда имеет в начале высококачественную случайную величину, предоставленную различными источниками энтропии.
srand() принимает число и ставит его в качестве отправной точки. Если seed не выставить, то при каждом запуске программы мы будем получать одинаковые случайные числа.
Вот пример простой формулы случайного числа из «классики» — книги «Язык программирования C» Кернигана и Ричи, первое издание которой вышло аж в 1978 году:
Эта формула предполагает существование переменной, называемой random_seed, изначально заданной некоторым числом. Переменная random_seed умножается на 1 103 535 245, а затем 12 345 добавляется к результату; random_seed затем заменяется этим новым значением. Это на самом деле довольно хороший генератор псевдослучайных чисел. Если вы используете его для создания случайных чисел от 0 до 9, то первые 20 значений, которые он вернет при seed = 10, будут такими:
Если у вас есть 10 000 значений от 0 до 9, то распределение будет следующим:
0 — 10151 — 10242 — 10483 — 9964 — 9885 — 10016 — 9967 — 10068 — 9659 — 961
Любая формула псевдослучайных чисел зависит от начального значения. Если вы предоставите функции rand() seed 10 на одном компьютере, и посмотрите на поток чисел, которые она производит, то результат будет идентичен «случайной последовательности», созданной на любом другом компьютере с seed 10.
К сожалению, у генератора случайных чисел есть и другая слабость: вы всегда можете предсказать, что будет дальше, основываясь на том, что было раньше. Чтобы получить следующее число в последовательности, мы должны всегда помнить последнее внутреннее состояние генератора — так называемый state. Без state мы будем снова делать одну и ту же математическую операцию с одинаковыми числами, чтобы получить тот же ответ.
Как сделать seed уникальным для каждого случая? Самое очевидное решение — добавить в вычисления текущее системное время. Сделать это можно с помощью функции time().
Функция time() возвращает информацию о текущем времени суток, значение, которое постоянно изменяется. При этом метод typecasting гарантирует, что значение, возвращаемое функцией time(), является целым числом.
Итак, в результате добавления «случайного» системного времени функция rand() генерирует значения, которые являются более случайными, чем мы получили в первом примере.
Однако в этом случае seed можно угадать, зная системное время или время запуска приложения. Как правило, для приложений, где случайные числа являются абсолютно критичными, лучше всего найти альтернативное решение.
Но опять же, все эти числа не случайны.
Лучшее, что вы можете сделать с детерминированными генераторами псевдослучайных чисел — добавить энтропию физических явлений.
Период (цикл) генератора
Одними из наиболее часто используемых методов генерации псевдослучайных чисел являются различные модификации линейного конгруэнтного метода, схема которого была предложена Дерриком Лемером еще в 1949 году:
Рассмотрим случай, когда seed равен 1, а период — 100 (на языке Haskell):
В результате мы получим следующий ответ:
Это лишь пример и подобную структуру в реальной жизни не используют. В Haskell, если вы хотите построить случайную последовательность, можно воспользоваться следующим кодом:
Выбор случайного Int дает вам обратно Int и новый StdGen, который вы можете использовать для получения более псевдослучайных чисел. Многие языки программирования, включая Haskell, имеют генераторы случайных чисел, которые автоматически запоминают свое состояние (в Haskell это randomIO).
Чем больше величина периода, тем выше надежность создания хороших случайных значений, однако даже с миллиардами циклов крайне важно использовать надежный seed. Реальные генераторы случайных чисел обычно используют атмосферный шум (поставьте сюда любое физическое явление — от движения мыши пользователя до радиоактивного распада), но мы можем и схитрить программным методом, добавив в seed асинхронные потоки различного мусора, будь то длины интервалов между последними heartbeat потоками или временем ожидания mutual exclusion (а лучше добавить все вместе).
Истинная случайность бит
Итак, получив seed с примесью данных от реальных физических явлений (либо максимально усложнив жизнь будущему взломщику самым большим набором потоков программного мусора, который только сможем придумать), установив state для защиты от ошибки повтора значений и добавив криптографических алгоритмов (или сложных математических задач), мы получим некоторый набор данных, который будем считать случайной последовательностью. Что дальше?
Дальше мы возвращаемся к самому началу, к одному из фундаментальных требований — тестам.
Национальный институт стандартов и технологий США вложил в «Пакет статистических тестов для случайных и псевдослучайных генераторов чисел для криптографических приложений» 15 базовых проверок. Ими можно и ограничиться, но этот пакет вовсе не является «вершиной» проверки случайности.
Одни из самых строгих статистических тестов предложил профессор Джордж Марсалья из Университета штата Флорида. «Тесты diehard» включают 17 различных проверок, некоторые из них требуют очень длинных последовательностей: минимум 268 мегабайт.
Случайность можно проверить с помощью библиотеки TestU01, представленной Пьером Л’Экуйе и Ричардом Симардом из Монреальского университета, включающей классические тесты и некоторые оригинальные, а также посредством общедоступной библиотеки SPRNG.
Еще один полезный сервис для количественного измерения случайности.
Что такое случайность в математике
Случайность в арифметике

Ч то может быть бесспорнее того факта, что 2 плюс 2 равняется 4? Со времён древних греков математики считали, что более несомненной вещи, чем доказанная теорема, не сыскать. Действительно, математические утверждения, истинность которых может быть доказана, часто считались более надёжным основанием для системы мышления, чем любой моральный или даже физический принцип. Немецкий философ и математик XVII века Готфрид Вильгельм Лейбниц считал возможным создать «исчисление» рассуждений, которое когда-нибудь позволит улаживать все споры с помощью слов: «Давайте вычислим, господа!». К началу нашего столетия прогресс в разработке символической логики дал основание немецкому математику Давиду Гильберту заявить, что все математические вопросы в принципе разрешимы, и провозгласить окончательную кодификацию методов математического рассуждения.
В 30-е годы нашего столетия этот оптимизм совершенно развеялся под влиянием удивительных и глубоких открытий К. Гёделя и А. Тьюринга. Гёдель доказал, что не существует системы аксиом и методов рассуждения, охватывающей все математические свойства целых положительных чисел. Позднее Тьюринг облёк остроумные, но сложные гёделевы доказательства в более понятную форму. Как показал Тьюринг, гёделева теорема о неполноте эквивалентна утверждению, что не существует общего метода для систематического принятия решения о том, остановится ли когда-нибудь компьютерная программа, т.е. приведёт ли она когда-нибудь компьютер к остановке. Разумеется, если некоторая конкретная программа приводит к остановке компьютера, этот факт легко может быть доказан непосредственным выполнением этой программы. Трудность заключается в доказательстве того, что произвольно взятая программа не останавливается.
 «Любая определённая математическая задача должна обязательно поддаваться точному решению, либо в виде непосредственного ответа на заданный вопрос, либо в виде доказательства невозможности её решения и, кроме того, неизбежности неудач всех попыток её решения. Однако, как бы трудны эти проблемы ни казались нам, и как бы ни были мы беспомощны перед ними, у нас имеется тем не менее твёрдая уверенность в том, что их решение будет получено в результате конечного числа чисто логических процессов. Мы слышим внутри нас постоянный призыв: «Вот проблема, ищи решение. Ты можешь найти его с помощью чистого мышления. «.» |  «Оказалось, что решение некоторых арифметических задач требует использования предложений, по существу выходящих за рамки арифметики. Разумеется, в подобных обстоятельствах математика может потерять часть своей «абсолютной истинности», но под влиянием современной критики оснований это происходило не раз. » |
Недавно мне удалось сделать ещё один шаг по пути, намеченному Гёделем и Тьюрингом. Преобразовав некоторую конкретную компьютерную программу в алгебраическое уравнение такого типа, который был знаком ещё древним грекам, я показал, что область чистой математики, известная под названием теории чисел, содержит в себе случайность. Это исследование демонстрирует, говоря словами Эйнштейна, что Бог порой использует целые числа для игры в кости.
Полученный результат, входящий составной частью в то, что было названо алгоритмической теорией информации, не является причиной для пессимизма; он не вносит в математику анархию. (В самом деле, большинство математиков продолжают работать над своими проблемами, как и раньше.) Он означает лишь, что в некоторых ситуациях должны применяться математические законы особого рода статистические. Подобно тому как физика не в состоянии предсказать, в какой именно момент распадётся данный атом радиоактивного вещества, математика порой бессильна дать ответ на некоторые вопросы. Однако физики могут надёжно предсказать средние значения физических величин, отнесённые к большому количеству атомов. Математики в некоторых случаях должны, вероятно, ограничиваться таким же подходом.
М оя работа служит естественным продолжением работы Тьюринга, однако если Тьюринг анализировал, остановится или нет произвольная программа, я рассматриваю вероятность того, что универсальный компьютер прекратит работу, если его программа выбрана совершенно случайно. Что я имею в виду, говоря «выбрана совершенно случайно»? Поскольку любая программа может быть сведена к последовательности двоичных разрядов битов (каждый из которых может принимать значение 0 или 1), «считываемых» и «интерпретируемых» компьютером, смысл упомянутой фразы состоит в том, что совершенно случайная программа, состоящая из n битов, эквивалентна результату n бросаний монеты (где «орёл» представляется нулём, а «решка» единицей, или наоборот).
Вероятность того, что такая совершенно случайная программа остановится (обозначим эту вероятность символом Ω), выражается вещественным числом, заключённым между 0 и 1. (Утверждение будет означать, что никакая случайная программа не остановится, a что всякая случайная программа остановится. Если мы имеем дело с универсальным компьютером, ни одно из этих крайних значений не реализуемо.) Поскольку Ω вещественное число, полностью представить его можно лишь как бесконечную последовательность разрядов. В двоичной системе это последовательность нулей и единиц.
Наверное, самым интересным свойством этой бесконечной цепочки является то, что она алгоритмически случайна: она не может быть сжата в программу (рассматриваемую как цепочка битов) длиной, меньшей чем она сама. Это определение случайности, играющее основную роль в алгоритмической теории информации, было независимо сформулировано в середине годов советским академиком А. Н. Колмогоровым и мною. (Впоследствии это определение мне пришлось подправить.)
Основная идея такого определения проста. Некоторые последовательности битов могут быть сжаты в программы, более короткие, чем сами эти последовательности, потому что они построены по схеме или подчиняются правилу. Например, последовательность вида 0101010101. может быть сильно сжата, если её задать как «100 повторений Безусловно, такие последовательности не являются случайными. С другой стороны, последовательность, порождённая бросанием монеты, не может быть сжата, поскольку для этого процесса, вообще говоря, отсутствует закономерность в чередовании нулей и единиц; это совершенно случайная последовательность.
Из всех возможных последовательностей битов большинство несжимаемы и, следовательно, случайны. Поскольку последовательность битов можно рассматривать как представление по любого вещественного числа (если допускать бесконечные последовательности), отсюда вытекает, что большинство вещественных чисел на самом деле случайны. Нетрудно показать, что алгоритмически случайное число, такое, как Ω, проявляет обычные статистические свойства, связанные в нашем представлении со случайностью. Одним из таких свойств является нормальность: каждый возможный разряд появляется в числе с равной частотой. Если речь идёт о двоичном представлении, то при стремлении числа разрядов к бесконечности, нулей и единиц будет в точности
Для того чтобы Ω имела смысл, должно выполняться одно техническое условие: программа на входе должна быть самоограничивающейся. Иными словами, информация о её общей длине (в битах) должна содержаться в самой программе. (Это на первый взгляд малозначительное условие, тормозившее прогресс в данной области в течение почти десятка лет, заставило переопределить понятие алгоритмической случайности.) Существующие языки программирования предназначены для построения самоограничивающихся программ, поскольку в этих языках предусмотрены механизмы начала и окончания программы. Такие конструкции позволяют программе содержать правильно определённые подпрограммы, которые в свою очередь могут включать в себя другие вложенные подпрограммы. Поскольку самоограничивающиеся программы строятся при помощи конкатенации (объединения двух последовательностей, скажем, строк или файлов, в одну. и вложения самоограничивающихся подпрограмм, программа синтаксически полна лишь тогда, когда последняя открытая подпрограмма «закрыта». По сути механизмы начала и окончания программ и подпрограмм функционируют соответственно как левая и правая скобка в математических выражениях.
Если бы программы не были самоограничивающимися, их нельзя было бы построить из подпрограмм, и суммирование вероятностей остановки для всех программ дало бы бесконечный результат. Если же вы рассматриваете лишь самоограничивающиеся программы, то Ω не только ограничена 0 и 1, но её можно явно вычислить «в пределе снизу». Другими словами, можно вычислять элементы бесконечной последовательности рациональных чисел (выраженных конечной последовательностью битов), каждое из которых ближе к точному значению Ω, чем предыдущее.
Один из способов сделать это систематически вычислять Ω n для возрастающих значений n ; здесь Ω n вероятность того, что совершенно случайная программа длиной до n битов остановится через n секунд, если она выполняется на данном компьютере. Поскольку имеется 2 k возможных программ длиной k битов, Ω n можно в принципе вычислить: для каждого значения k от 1 до n надо определить, сколько из этих возможных программ на самом деле останавливается через n секунд, умножить это число на а затем просуммировать все полученные произведения. Иначе говоря, каждая такая останавливающаяся программа вносит свой вклад, равный в значение Ω; вклад программ, которые не останавливаются,
Д о сих пор при обсуждении проблемы остановки я обращался исключительно к её компьютерно-программной интерпретации, но в свете работы Дж. Джоунса из Университета в Калгари и Ю. В. Матиясевича из Ленинградского отделения Математического института им. Стеклова АН СССР в этой проблеме появляется новое «измерение». Исследования упомянутых авторов дают метод, позволяющий представить эту проблему в виде утверждений о диофантовых уравнениях определённого класса. Эти алгебраические уравнения, составленные при помощи операций над целыми числами умножения, сложения и возведения в целую степень, названы по имени греческого математика Диофанта Александрийского, жившего в
Выражаясь точнее, метод Джоунса и Матиясевича позволяет отождествить утверждение о том, что некоторая конкретная программа не остановится, с утверждением о том, что одно из уравнений из определённого класса диофантовых уравнений не имеет решений в целых числах. Как и в оригинальной версии проблемы остановки для компьютеров, здесь, если решение существует, это легко доказать: всё, что требуется, это подставить правильные числа и проверить, равными ли получились левая и правая части уравнения. Доказать же несуществование решения (если оно действительно отсутствует) намного сложнее.
 |
Мой подход к непредсказуемости в математике подобен этому, но он приводит к гораздо более высокой степени случайности. Вместо «арифметизации» компьютерных программ (которые могут или не могут останавливаться) как класса диофантовых уравнений, я применяю метод Джоунса и Матиясевича для арифметизации единственной программы вычисления
Э тот метод основан на любопытном свойстве чётности биномиальных коэффициентов, которое было замечено Э. Люка сто лет назад, но до сих пор оставалось неоценённым по достоинству. Биномиальные коэффициенты представляют собой множители при степенях x k в разложении выражений вида Эти коэффициенты легко вычисляются с помощью так называемого треугольника Паскаля (см. рисунок ниже).
 |
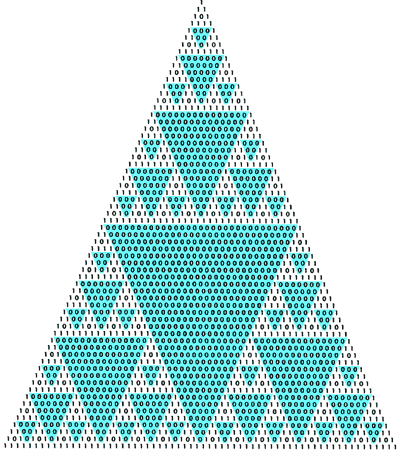 |
Хотя идея арифметизации проста и изящна, выполнение этого построения представляет собой громоздкую программистскую задачу. Тем не менее мне казалось, что это может быть интересным. Поэтому я разработал программу «компилятор» для получения уравнений из программ для «регистровой машины». Регистровая машина представляет собой компьютер, состоящий из небольшого множества регистров для хранения чисел произвольной величины. Разумеется, это абстракция, поскольку любой реальный компьютер имеет регистры ограниченного объёма.
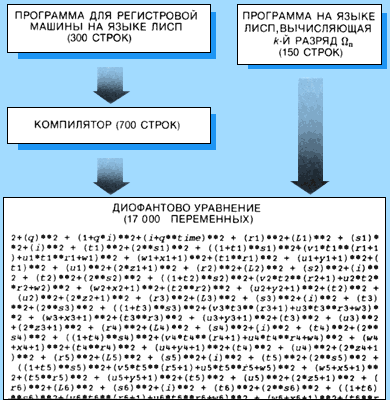 |
Н а первый взгляд может показаться, что мы мало выигрываем, спрашивая «имеет ли уравнение бесконечно много решений», вместо «имеет ли оно вообще решения». Но на самом деле это очень важное различие: ответы на эти вопросы логически независимы. Два математических утверждения считаются логически независимыми, если одно нельзя вывести из другого, т.е. если ни одно из них не является логическим следствием другого. Это понятие независимости обычно отличают от понятия независимости, используемого в статистике. Последнее заключается в том, что два случайных события называются независимыми, если исход одного из них не оказывает влияния на исход другого. Например, результат бросания монеты никоим образом не влияет на результат следующего бросания: эти результаты статистически независимы.
Математическое рассуждение оказывается в этом случае в принципе бесполезным, поскольку нет логических взаимосвязей между полученными таким способом диофантовыми уравнениями. Будь ты хоть семи пядей во лбу, выведи длиннейшее доказательство, используй сложнейшие математические аксиомы, построенный бесконечный ряд предложений, устанавливающий, конечно или бесконечно число решений диофантова уравнения, окажется бесполезным, если k увеличить. Итак, даже в элементарных разделах теории чисел, связанных с диофантовыми уравнениями, возникают случайность, неопределённость и непредсказуемость.
Н о каким же образом теорема Гёделя о неполноте, проблема остановки Тьюринга и моя работа влияют на математику? Большинство математиков не обращают внимания на эти результаты. Конечно, в принципе они согласны, что любая конечная система аксиом неполна, но на практике они игнорируют этот факт, как непосредственно не относящийся к их работе. Но иногда, к сожалению, его нельзя игнорировать. Хотя в исходном виде теорема Гёделя казалась применимой лишь к необычным математическим предложениям, не имеющим практического интереса, алгоритмическая теория информации показала, что неполнота и случайность являются естественными и распространёнными повсюду свойствами. Это подсказывает мне, что следует более серьёзно относиться к возможности поиска новых аксиом относительно целых чисел.
Тот факт, что многие математические проблемы оставались веками и даже тысячелетиями нерешёнными, похоже, подтверждает мою точку зрения. Математики непоколебимо стоят на том, что причина неудач в решении подобных проблем заключена только в самих проблемах, но не заключается ли она в неполноте системы их аксиом? Например, вопрос о том, существуют ли нечётные совершенные числа, не поддаётся решению со времён древних греков. (Совершенным называется число, равное сумме своих делителей, исключая само это число. Например, 6 совершенное число, поскольку Не может ли быть так, что утверждение «Не существует нечётных совершенных чисел» недоказуемо? Если это так, то не лучше ли принять его за аксиому?
Большинству математиков это предположение может показаться смехотворным, но для физика или биолога оно не выглядит столь уж абсурдным. Для тех, кто работает в эмпирических областях науки, основным критерием, позволяющим судить о том, следует ли рассматривать некоторое суждение как основание теории, служит полезность этого суждения, а вовсе не обязательно его «самоочевидная истинность». Если имеется много догадок, которые можно обосновать обращением к некоторой гипотезе, учёные-эмпирики принимают эту гипотезу. (Из несуществования нечётных совершенных чисел, не следует важных выводов, и, согласно этому критерию, такая аксиома не является полезной.)
На самом деле в некоторых случаях математики в своей работе опираются на недоказанные, но полезные предположения. Например, так называемая гипотеза Римана, хотя она никогда не была доказана, часто считается верной, потому что на ней основано много важных теорем. Более того, эта гипотеза была эмпирически проверена с помощью самых мощных компьютеров, и ни один опровергающий её пример не был найден. Компьютерные программы (которые, как я уже сказал, эквивалентны математическим утверждениям) проверяются таким же способом тестированием некоторого числа вариантов, а не строгим математическим доказательством.
С уществуют ли проблемы в других областях науки, для решения которых был бы полезен этот экскурс в основания математики? Я думаю, алгоритмическая теория информации может применяться в биологии. Регуляторные гены развивающегося зародыша являются по существу вычислительной программой построения организма. «Сложность» этой биохимической компьютерной программы можно, как мне думается, определить в терминах, аналогичных тем, что я развил при квантификации информационного
В конце своей жизни Дж. фон Нейман призвал математиков заняться созданием абстрактной математической теории происхождения и эволюции жизни. Эта фундаментальная проблема, подобно большинству проблем такого масштаба, бесконечно трудна. Возможно, алгоритмическая теория информации позволит найти путь, по которому следует идти.



