Согласованность данных
Согласованность данных (иногда консистентность данных, англ. data consistency) — согласованность данных друг с другом, целостность данных, а также внутренняя непротиворечивость.
Согласованность в ER-модели
В терминах ER-модели, условия согласованности могут включать в себя указание того, какие значения могут принимать атрибуты узлов, какие связи могут устанавливаться между узлами, каково минимальное и максимальное число связей определённого типа, в котором может участвовать один узел.
Согласованность в базах данных
Целостность базы данных означает соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам.
Согласованность в теории алгоритмов и структур данных
Чтобы сложные структуры данных выполняли свою функцию, на их содержимое приходится накладывать особые условия — условия согласованности. Другими словами: если записать случайные байты в числовой массив фиксированной длины, мы получим случайную кучу чисел, но ничего не «сломаем». Если записать случайные байты, например, в строку в UTF-8, мы можем получить цепочку, с точки зрения UTF-8 бессмысленную — целостность нарушена. Многие задачи, решаемые алгоритмистами и программистами, связаны с поиском эффективной структуры данных и реализацией механизмов поддержки её согласованности.
Например, условия согласованности двоичного дерева поиска таковы:
Одно из определений инкапсуляции в ООП — никакой вызов метода, никакое присваивание полей не сможет увести объект из согласованного состояния в несогласованное.


Согласованность данных относится к случаям, когда одни и те же данные, хранящиеся в разных местах, не совпадают.
Содержание
Стабильность на определенный момент времени
В качестве подходящего примера резервного копирования рассмотрим веб-сайт с базой данных, такой как онлайн-энциклопедия. Википедия, который должен работать круглосуточно, но также должен регулярно поддерживаться для защиты от стихийных бедствий. Разделы Википедии постоянно обновляются каждую минуту, каждый день, в то время как база данных Википедии хранится на серверах в виде одного или нескольких очень больших файлов, для резервного копирования которых требуются минуты или часы.
Эти большие файлы, как и любая база данных, содержат множество структур данных, которые ссылаются друг на друга по местоположению. Например, некоторые конструкции индексы которые позволяют подсистеме базы данных быстро находить результаты поиска. Если структуры данных перестают правильно ссылаться друг на друга, то можно сказать, что база данных испорченный.
Пример счетчика
Важность согласованности на определенный момент времени можно проиллюстрировать на примере того, что произошло бы, если бы резервная копия была сделана без нее.
Поскольку резервное копирование уже выполнено наполовину и индекс уже скопирован, резервная копия будет записана с данными статьи, но без ссылки на индекс. В результате несоответствия этот файл считается поврежденным.
В реальной жизни настоящая база данных, такая как Википедия, может редактироваться тысячи раз в час, а ссылки практически всегда разбросаны по всему файлу и могут исчисляться миллионами, миллиардами и более. Последовательная «копия» резервной копии буквально будет содержать так много мелких повреждений, что резервная копия будет полностью непригодной для использования без длительного процесса восстановления, который не может гарантировать полноты того, что было восстановлено.
Процесс резервного копирования, который должным образом учитывает согласованность данных, гарантирует, что резервная копия является моментальным снимком того, как вся база данных выглядела в один момент. В данном примере Википедии это гарантирует, что резервная копия была записана без добавленная статья на отметке 75%, чтобы данные статьи соответствовали ранее написанным данным индекса.
Системы кэширования дисков
Последовательность на определенный момент времени также актуальна для дисковых подсистем компьютера.
Конкретно, операционные системы и файловые системы разработаны с расчетом на то, что компьютерная система, на которой они работают, может потерять питание, выйти из строя, выйти из строя или иным образом прекратить работу в любое время. При правильном проектировании они гарантируют, что данные не будут безвозвратно повреждены в случае отключения питания. Операционные системы и файловые системы делают это, гарантируя, что данные записываются на жесткий диск в определенном порядке, и полагаются на это для обнаружения и восстановления после неожиданных отключений.
С другой стороны, строгая запись данных на диск в порядке, обеспечивающем максимальную целостность данных, также влияет на производительность. Процесс написать кеширование используется для консолидации и изменения последовательности операций записи, чтобы их можно было выполнять быстрее за счет минимизации времени, затрачиваемого на перемещение головок дисков.
Проблемы согласованности данных возникают, когда кэширование записи изменяет последовательность, в которой выполняются записи, поскольку существует возможность неожиданного завершения работы, которое нарушает ожидания операционной системы, что все записи будут выполняться последовательно.
Например, чтобы сохранить типичный документ или файл изображения, операционная система может записать на диск следующие записи в следующем порядке:
Операционная система полагается на предположение, что если она видит, что элемент № 1 присутствует (что файл собирается быть сохранен), но этот элемент № 4 отсутствует (подтверждая успех), то операция сохранения была неудачной и поэтому она должна отменить любые незавершенные шаги, уже предпринятые для его сохранения (например, отметка сектора 123 как свободного, поскольку он никогда не был заполнен должным образом, и удаление любой записи XYZ из каталога файлов). Он полагается на то, что эти элементы будут записаны на диск в последовательном порядке.
Кроме того, карта свободного пространства файловой системы не будет содержать никаких записей, показывающих, что сектор 123 занят, поэтому позже он, вероятно, назначит этот сектор следующему файлу для сохранения, полагая, что он доступен. Тогда в файловой системе будет два файла, оба неожиданно заявившие права на один и тот же сектор (известный как перекрестно связанный файл). В результате запись в один из файлов перезапишет часть другого файла, незаметно повредив его.
Подсистема кэширования диска, обеспечивающая согласованность на определенный момент времени, гарантирует, что в случае неожиданного отключения четыре элемента будут записаны одним из пяти возможных способов: полностью (1-2-3-4), частично (1, 1-2, 1-2-3) или не использовать вовсе.
Если питание отключается после того, как элемент 4 был записан, запоминающее устройство с батарейным питанием содержит запись об обязательствах для других трех элементов и гарантирует, что они будут записаны («сброшены») на диск при следующей возможности.
Согласованность транзакций
Согласованность (системы баз данных) в сфере Распределенная база данных систем относится к собственности многих КИСЛОТА баз данных, чтобы гарантировать, что результаты Транзакция базы данных видны всем узлам одновременно. То есть, как только транзакция была зафиксирована, все стороны, пытающиеся получить доступ к базе данных, могут видеть результаты этой транзакции одновременно.
Согласованность приложений
Консистентно о Консенсусе
Здравствуйте, меня зовут Дмитрий Карловский. А вы на канале Core Dump, где мы берём различные темы из компьютерной науки и раскладываем их по полочкам.
И на этот раз мы постараемся прийти к согласию касательно согласованной классификации алгоритмов обеспечения консенсуса в системах со множеством участников. Разберём разные виды блокировок, бесконфликтных алгоритмов. А так же попробуем выявить их фундаментальные особенности, проявляющиеся на самых разных масштабах.

Согласованность данных
Начнём с консистентности или согласованности. Это — логическая непротиворечивость хранимых данных.
Например, если у Алисы родителем значится Боб, а у Боба родителем значится Алиса, то это явно какая-то лажа. Не могут они быть родителями друг друга одновременно. Данные не консистентны!

Согласованность часто путают с консенсусом. Особенно, когда данные частично хранятся на одном сервере, а частично на другом, но при этом должны быть согласованы друг с другом. Однако, консенсус немного о другом..
Согласие между участниками
Консенсус — это согласие группы участников касательно значения некоторого состояния. Например, если все считают Боба мужчиной, но сам он считает себя вертолётом, то согласия тут не наблюдается. Консенсус не достигнут!

Важно понимать, что даже если у каждого участника состояние само по себе консистентно, между участниками согласия при этом может и не быть. И наоборот, участники могут достигнуть консенсуса касательно несогласованного состояния. Тогда… Эта база данных сломалась. Несите следующую!
Достижение согласия
Все подходы по достижению консенсуса можно разделить на две большие группы..

Первая — это конкуренция за единый источник истины. Участники толпятся вокруг него, толкаются локтями и пытаются внести в него свои изменения. Транзакции в базах данных, атомарные операции в процессоре, протоколы консенсуса в распределённых системах — это всё из этой оперы.
Совершенно иной подход — конвергенция. Она же сходимость. Это когда участники независимо друг от друга меняют каждый своё и только своё состояние. Но при этом они могут подглядывать к соседям и подливать их изменения к себе. А алгоритмы слияния строятся так, чтобы состояния всех участников в конечном счёте сошлись к одному и тому же значению.
Конкуренция за источник истины
Разберём подробнее конкуренцию за источник истины. Это может быть мастер-реплика СУБД, оракул в распределённых системах, основной поток приложения или просто общий участок памяти.
Читать из источника все могут одновременно. Но при попытке записать участник может быть заблокирован, пропуская вперёд более удачливых соседей.
Тут можно выделить два вида блокировок: пессимистичная и оптимистичная.
В базах данных это соответственно пессимистичные и оптимистичные транзакции. В распределённых системах это мастер-слейв репликация и двухфазные коммиты. А во многопоточке это мьютексы и lock-free алгоритмы.

Пессимистичная блокировка
Идея пессимистичной блокировки простая: сначала участник запирает ресурс, затем производит его обновление, по завершении которого ресурс отпирается. Это если ему повезло прийти первым. Если же он пришёл, а ресурс уже кем-то заперт, то он сидит, ничего не делает, и ждёт его отпирания.

Это самый простой и надёжный подход. Однако у него есть проблемы с производительностью. Либо из-за постоянных ожиданий, либо из-за холостых запираний, которые так-то весьма не бесплатны.
Смертельное запирание
Кроме того, этот подход подвержен проблеме смертельного запирания или dead-lock. Это когда два участника успешно запирают два разных ресурса, а потом блокируются при попытке запереть ресурс уже запертый оппонентом. Получается, что при неосторожном обращении с запиранием, участники могут заблокироваться одновременно. Из-за чего не смогут освободить запертые ими ресурсы.

Запирание разве не блокировка?
Тут стоит подчеркнуть разницу между запиранием и блокировкой.
Запирание (locking) — это воздействие на ресурс таким образом, чтобы никто другой не мог с ним взаимодействовать.
Блокировка же (blocking) — это когда мы сами не можем продолжать работу по той или иной причине. Например, когда ожидаем отпирания ресурса, завершения ввода-вывода или просто какого-либо события.
Однако, часто запирание называют блокировкой — к этому надо быть готовым и правильно интерпретировать. Особенно, когда говорят о неблокирующих алгоритмах, подразумевая на самом деле незапирающие.
Оптимистичная блокировка
Если конкуренция не слишком высока, оптимистичная блокировка может показать себя гораздо лучше.
Тут участник сначала готовит новое состояние, а потом атомарно применяет его к источнику истины. Если повезёт. А если не повезёт, и кто-то успеет раньше него, то вся проделанная работа выкидывается, и начинается заново.

Висеть в таком цикле участник может неограниченно долго. Формально при этом он не заблокирован и продолжает работу. Однако, фактически он работает вхолостую и не продвигается вперёд по выполняемой им задаче. Что логически эквивалентно блокировке.
Более того, один из вариантов реализации, например, мьютекса — это запирание с пробуксовкой, или spin-lock. То есть кручение в бесконечном цикле в ожидании отпирания ресурса, чтобы тут же рвануть на полной скорости получив зелёный свет.
Тут стоит обратить внимание на путаницу в терминах. Lock-free алгоритмы раньше назывались неблокирующими. Теперь же они считаются лишь частным случаем неблокирующих. Но на самом деле это всё же механизм хоть и оптимистичной, но блокировки.
Преимуществами данного подхода является высокая производительность в условиях низкой конкуренции, и существенно более сложное достижение взаимной блокировки, которая в этом случае уже называется оживлённым запиранием или live-lock.
К недостаткам же можно отнести большой объём холостой работы при высокой конкуренции, и существенно более сложные алгоритмы, чувствительные к архитектурным особенностям.
Задача византийских генералов
Проблему консенсуса обычно иллюстрируют на примере задачи византийских генералов, каждый из которых может принять решение наступить или отступить в условиях ненадёжной связи друг с другом. Если все нападают — есть шанс выиграть битву. Если все отступят, то смогут перегруппироваться и напасть позже. Но, представьте себе ситуацию..

Анжелла и Константин выступают на битву со вселенским злом, а Блейд такой: «Ой, я из другой франшизы, это не моя битва, всем пока». В результате наши герои терпят поражение в неравном бою. А ведь могли бы отступить, и например, позвать Бимэна с его кучей артефактов.
Так вот, чтобы прийти к общему решению они могут задействовать один из протоколов консенсуса. Самый простой из них — демократическое голосование. Тут единым источником истины является мнение большинства или кворум, за который и идёт конкуренция.
В случае же конвергенции, никто никого не спрашивает «отступать или нападать?». В бой идут все! И даже ты, Блейд, иначе снова отправим на нары. Так что догоняй!
Вы, возможно, спросите меня: «Кто все эти люди и при чём тут компьютеры?». Что ж, стоит пояснить, что в распределённых системах наступление — это применение изменений, а отступление — это их откат.
При пессимистичной стратегии мы сначала договариваемся применяем ли мы изменения и если да, то их принимают все. При оптимистичной мы сначала вносим изменения, а потом договариваемся, и если договориться не удалось, то откатывем. При конвергентной же мы применяем изменения и все остальные обязаны их рано или поздно тоже принять. Но об этом позже.
Терпимость к разделению
Отличительной особенностью источника истины является возможность гарантировать консенсус. Однако все участники должны при этом иметь постоянный доступ к этому источнику. Что в общем случае невозможно в распределённых системах, где соединение между участниками может временно пропадать.

Это — фундаментальная дилемма между консенсусом и доступностью также известная как CAP-теорема. Если мы выбираем консенсус, то участники, не имеющие доступа к источнику истины, не смогут изменить никакие данные. Если же им всё же позволить менять данные, то мы автоматически получаем ситуацию со множеством источников истины, которые могут друг другу противоречить.
И, как говорится, «Не можешь победить? Возглавь!». Так что давайте рассмотрим как можно жить без конкуренции за единый источник истины.
Сходимость к согласию
Если вы работали с распределёнными системами, то скорее всего вы слышали термин «Eventual Cоnsistency» или «Согласованность в конечном счёте». Так вот, оно на самом деле не про консистентность, а именно про конвергенцию или сходимость.
Wait-free алгоритмы межпоточного взаимодействия основаны на той же идее — отсутствие конкуренции за общий ресурс. Поэтому именно они, в отличие от lock-free, являются неблокирующими на самом деле.
Однако, важно понимать, что консистентность данных тут уже в общем случае не может быть гарантирована. Так как слияние консистентных по отдельности изменений может выдавать уже неконсистентное состояние. Но с этим можно жить, если правильно организовывать данные и уметь нормализовывать неконсистентное состояние.

Алгоритмы, обеспечивающие сходимость, можно разделить на 3 основных класса. Это: упорядоченные, полу-упорядоченные и… беспорядочные. Давайте рассмотрим их подробнее..
Упорядоченная сходимость
Алгоритмы операционных трансформаций основаны на идее, что все участники должны применить все изменения в одном и том же порядке. То есть после слияния всех изменений каждым участником, любой из них должен получить одну и ту же цепочку изменений, что даст им одно и то же финальное состояние. То есть конвергенцию.

Но как же так, Алиса ведь уже внесла своё красное изменение А3 после А1, сверху докинула С4, а тут прилетает В2 и его нужно как-то вставить задним числом?
В этом случае приходится отменять всю историю до точки А1, применять В2, а потом накатывать историю обратно. При этом, так как каждое изменение зависит от состояния, полученного от предыдущего изменения, то при накатывании истории может потребоваться её трансформация с учётом добавленных в её середину изменений.
Такое перебазирование истории — довольно медленная операция, в случае большого расхождения историй изменений разных участников. При этом всю эту историю от начала времён нужно хранить неограниченно долго. А каждый новый участник, чтобы получить актуальное состояние, должен загрузить и последовательно применить всю эту историю, размер которой многократно превышает размер финального состояния.
Разумеется, в таком наивном виде эти алгоритмы не применимы на практике. Поэтому к ним добавляют дополнительные костыли и идут на множество компромиссов. Например, обрезают старую историю, группируют изменения, делают периодические снепшоты состояния и тд. Это сглаживает углы, но не решает проблемы полностью. Зато ещё сильнее усложняет и без того не простые алгоритмы.
Полу-упорядоченная сходимость
А что если мы будем описывать наши изменения таким образом, что изменения любого участника можно будет просто подклеивать в конец истории любого другого участника без какого-либо перебазирования? Так появились коммутативные бесконфликтные реплицируемые типы данных или CmRDT.
CmRDT: Conflict-free Commutative Replicated Data Type
Они полагаются лишь на частичную упорядоченность изменений. То есть изменения от одного участника применяются лишь в том же порядке, в котором этот участник их вносил. А вот изменения разных участников можно переставлять друг относительно друга как угодно, но результат будет одинаковым.

Полу-упорядоченным алгоритмам уже не нужно хранить всю историю, а применение изменений получается крайне простым и быстрым. Однако, они сильно зависят от надёжности соединения: все изменения от одного участника должны без пропусков и без дублирования дойти до каждого участника в строго определённом порядке. Что порой не так-то просто обеспечить.
Беспорядочная сходимость
Оказывается, можно пойти ещё дальше и вообще не полагаться на порядок применения изменений. Так появились конвергентные бесконфликтные реплицируемые типы данных или CvRDT.
CvRDT: Conflict-free Convergent Replicated Data Type
Тут уже изменения могут приходить в произвольном порядке, могут дублироваться, а могут и вообще потеряться, но последующие изменения всё же обеспечат конвергенцию.

CROWD — CvRDT нового поколения
Именно на конвергентные типы данных я и делаю ставку в своих проектах, используя уникальные CROWD алгоритмы для синхронизации распределённых состояний..
Но это уже совсем другая история, достойная отдельного разбора.
Согласны?
Подведём итоги. Пройдя по всем ступеням эволюции алгоритмов обеспечения консенсуса, у нас получилась стройная, непротиворечивая классификация с чёткими границами между понятиями. Мы выявили общие подходы в самых разных областях компьютерной науки. А так же разобрали ряд популярных заблуждений.

Что ещё почитать?
Если вам захочется больше информации к размышлению, то могу порекомендовать статью Пэта Хелланда о конвергенции и консистентности.
Буду рад, если подкинете ещё каких-либо материалов по этой теме.
Продолжение следует..
Если мне с вами удалось сейчас достигнуть консенсуса, то дайте мне об этом знать посредством лайка. Если же нет — обязательно пришлите мне дельту в комментарии. Но в любом случае подписывайтесь на канал, чтобы не пропустить обновления. И, конечно, делитесь ссылкой на источник истины со знакомыми участниками во имя всеобщей конвергенции.
А на этом пока что всё. С вами был… беспорядочный программер Дмитрий Карловский.
Обмен данными. Консистентность vs Многопоточность
не должно быть такого валидного изменения системы А, которое приведет к тому, что обмен переведет систему Б в невалидное состояние
Какие же возможны варианты? Все богатство случаев с битыми ссылками, не хватающими остатками, разными ставками НДС и прочим и прочим можно свести к трем следующим вопросам:
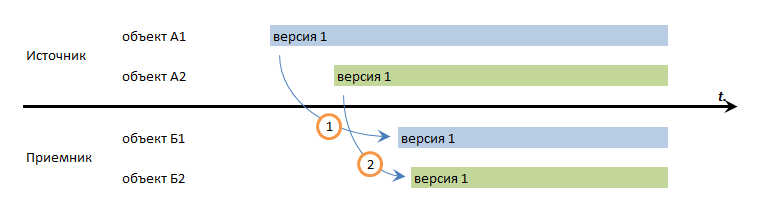
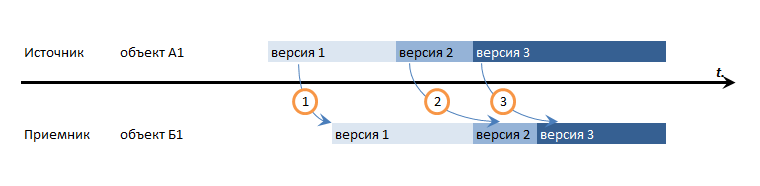
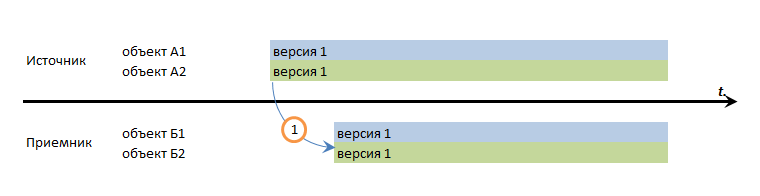
Транзакционная последовательность
Этот уровень последовательности похож на то как SQL сервер делает бэкапы: он просто хранит лог транзакций и в случае необходимости накатывает их последовательно на БД.
Это единственный вариант, который гарантированно разрулит вообще все возможные недоразумения, включая перекрестные ссылки. Но в 1С он не достижим: мы не можем контролировать начало и фиксацию транзакции в 1С с тем, чтобы повторить тоже самое в источнике. Можно конечно попробовать опуститься на уровень SQL, но этот путь полон граблей и мы тут в общем про 1С, а не про MS SQL.
Хронологическая последовательность
Нужно складывать все версии всех объектов в отдельное место, не допуская никаких пропусков, подобно тому, как это делает подсистема Версионирование объектов и на стороне приемника воспроизводить эту последовательность.
Этот обмен с высокой долей вероятности разрулит перекрестный ссылки (если они организованы пользователем, а не кодом в одной транзакции). Также он справится с жесткими последовательными переходами (это пояснено чуть ниже).
Что вообще может пойти не так
На самом деле, случаев когда ни один уровень гарантии последовательности (кроме транзакционной или хронологической) не может обеспечить согласованность данных больше чем кажется.
Партионно-последовательная
Основным плюсом этой истории являет значительно оптимизированная ресурсоемкость при частых изменениях и нечастых обменах: не нужно хранить безумное число копий одного и того же объекта, не нужно записать в приемнике по 100 раз то, что можно записать однажды. Также, если говорить о переходе от логики «НомерСообщения меньше или равно» к логике «НомерСообщения равно» есть некое ослабление эффекта снежного кома: во-первых объекты имеют тенденцию к «утеканию» из ранних партий, во-вторых, ограниченность каждой партии способствует продвижению вперед при проблемах: валится один конкретный кусочек, вместо большого снежного кома.
Последовательность основанная на данных
Этот алгоритм точно знает, что бизнес-логика такова, что одни объекты надо прогружать раньше чем другие (например, номенклатуру раньше поступлений, поступления раньше реализаций) и гарантирует эту последовательность. Вообще, в «чистой» реализации, этот принцип должен быть доведен до следующего абсолюта:
На практике же, обмены редко бывают онлайновыми и скорее всего, последовательность основанная на данных будет применяться внутри какой-то сессии обмена (а это собственно и есть уровень гарантий Конвертации данных)
Реализовать довольно просто: нужно иметь табличку приоритетов и табличку изменений и грузить изменения, отсортированные по приоритетам. Номера сообщений при этом можно выкинуть, не обращать на них никакого внимания.
Последовательность Шредингера или согласованность в конечном счете
О транспортном уровне
Вообще, транспортный уровень не такая интересная тема, но скажем пару слом и о нем. Лучшие результаты достигаются при отделении друг от друга процессов транспорта и распаковки от процессов применения изменений т.е. в результате работы транспортного слоя мы уже должны видеть что нам предстоит сделать в части записи и иметь возможность манипулировать этими задачами не на уровне одной большой черной коробки. Фактически, если использовать складскую аналогию, принятая в 1С тактика такова:
Сами понимаете, на складах это так не работает. Работает так:
В этом смысле, алгоритм принимающий решение о том что грузить, в какой последовательности и что делать при фэйлах должен иметь перед собой картину того что предстоит сделать. Это может быть таблица (регистр сведений) вида: тип объекта, идентификатор объекта, данные объекта и всякая мета-информация вроде того откуда и когда этот объект пришел и сколько раз и с каким результатом его пытались записать.
Графовая согласованность
Так же как согласованность в конечном счете, с дополнительной проверкой ссылочной целостности
Высокая производительность (оценить выше/ниже согласованности в конечном счете не так просто, поскольку дополнительные затраты на проверку графа в одном случае могут нивелироваться отсутствием некоторого количества неудачных попыток в другом), учет связей между объектами при независимости реализации от условий конкретной конфигурации.
Это нереализуемо на 1С: реляционная БД не позволит выстраивать граф с приемлемой производительностью. Для этого потребуются noSQL решения вроде ElasticSearch.



