Разница между форматами сжатия видео с потерями и без потерь

Файлы видео занимают много места. Несжатое 1080p HD видео занимает около 10,5 ГБ места на каждую минуту видео, но точный показатель может варьироваться в зависимости от частоты кадров. Если вы используете смартфон для съемки видео, отснятый материал с разрешением 1080p со стандартными 30 кадрами в секунду занимает 130 МБ за минуту, а 4K-видео занимает 375 МБ на каждую минуту фильма.
Поскольку видео занимает много места, а пропускная способность ограничена, сжатие видео используется для уменьшения размера файла. Сжатие включает в себя упаковку информации файла в меньшем пространстве. Это работает через два различных типа сжатия: с потерями и без потерь.
Форматы сжатия видео с потерями
Сжатие видео с потерями означает, что сжатый файл содержит меньше данных, чем исходный файл. Изображения и звуки, которые повторяются по всему видео, могут быть удалены, чтобы эффективно вырезать части видео, которые рассматриваются как ненужные. В некоторых случаях это приводит к ухудшению качества файлов, поскольку информация была утеряна, отсюда и обозначение «с потерями».
Большинство видеофайлов, загружаемых в Интернет, используют сжатие с потерями, чтобы сохранить небольшой размер файла при одновременной доставке продукта относительно высокого качества. Если бы видео оставалось с его (в некоторых случаях) чрезвычайно высококачественным размером файла, загрузка контента не только заняла бы целую вечность, но пользователи с медленным интернет-соединением имели бы ужасное время потоковой передачи видео или загрузки его на свои компьютеры.
Хотя использование формата сжатия с потерями приводит к уменьшению размера файлов, данные теряются и не могут быть восстановлены.
Форматы сжатия видео без потерь
Сжатие видео без потерь – именно то, на что это похоже: оригинальная и сжатая версии почти идентичны. Ни какая часть данных не теряется в процессе сжатия. Форматы сжатия без потерь во многих случаях не так полезны, как сжатие с потерями, поскольку файлы часто имеют тот же размер, что и до сжатия.
Использование сжатия видео без потерь может показаться бессмысленным, учитывая, что уменьшение размера файла является основной целью сжатия. Однако, если размер файла не является проблемой, использование сжатия без потерь приводит к идеальному качеству изображения.
Например, видеоредактор, передающий файлы с одного компьютера на другой с помощью внешнего жесткого диска, может выбрать сжатие без потерь для сохранения качества во время работы. В этом случае, поскольку на внешнем жестком диске достаточно свободного места для хранения огромного видеофайла, это не проблема.
Однако тот, кто хочет загрузить двухчасовое видео 4K на сайт потокового видео, вероятно, не будет использовать сжатие без потерь. Файл будет настолько большим, что его загрузка займет много времени.
Если вам важно качество, а не размер, используйте формат сжатия без потерь, который совместим с вашим предполагаемым использованием.
Сжатие информации с потерями и без потерь
Еще вчера казалось, что диск размером в один гигабайт — это так много, что даже неясно, чем его заполнить, и уж конечно, каждый про себя думал: был бы у меня гигабайт памяти, я бы перестал «жадничать» и сжимать свою информацию какими-то архиваторами. Но, видимо, мир так устроен, что «свято место пусто не бывает», и как только у нас появляется лишний гигабайт — тут же находится чем его заполнить. Да и сами программы, как известно, становятся все более объемными. Так что, видимо, с терабайтами и экзабайтами будет то же самое.
Поэтому, как бы ни росли объемы памяти диска, упаковывать информацию, похоже, не перестанут. Наоборот, по мере того как «места в компьютере» становится все больше, число новых архиваторов увеличивается, при этом их разработчики не просто соревнуются в удобстве интерфейсов, а в первую очередь стремятся упаковать информацию все плотнее и плотнее.
Однако очевидно, что процесс этот не бесконечен. Где лежит этот предел, какие архиваторы доступны сегодня, по каким параметрам они конкурируют между собой, где найти свежий архиватор — вот далеко не полный перечень вопросов, которые освещаются в данной статье. Помимо рассмотрения теоретических вопросов мы сделали подборку архиваторов, которые можно загрузить с нашего диска, чтобы самим убедиться в эффективности той или иной программы и выбрать из них оптимальную — в зависимости от специфики решаемых вами задач.
Совсем немного теории для непрофессионалов
Позволю себе начать эту весьма серьезную тему со старой шутки. Беседуют два пенсионера:
— Вы не могли бы сказать мне номер вашего телефона? — говорит один.
— Вы знаете, — признается второй, — я, к сожалению, точно его не помню.
— Какая жалость, — сокрушается первый, — ну скажите хотя бы приблизительно…
Действительно, ответ поражает своей нелепостью. Совершенно очевидно, что в семизначном наборе цифр достаточно ошибиться в одном символе, чтобы остальная информация стала абсолютно бесполезной. Однако представим себе, что тот же самый телефон написан словами русского языка и, скажем, при передаче этого текста часть букв потеряна — что произойдет в подобном случае? Для наглядности рассмотрим себе конкретный пример: телефонный номер 233 34 44.
Соответственно запись «Двсти трцать три трицть четре сорк чтре», в которой имеется не один, а несколько пропущенных символов, по-прежнему легко читается. Это связано с тем, что наш язык имеет определенную избыточность, которая, с одной стороны, увеличивает длину записи, а с другой — повышает надежность ее передачи. Объясняется это тем, что вероятность появления каждого последующего символа в цифровой записи телефона одинакова, в то время как в тексте, записанном словами русского языка, это не так. Очевидно, например, что твердый знак в русском языке появляется значительно реже, чем, например, буква «а». Более того, некоторые сочетания букв более вероятны, чем другие, а такие, как два твердых знака подряд, невозможны в принципе, и так далее. Зная, какова вероятность появления какой-либо буквы в тексте, и сравнив ее с максимальной, можно установить, насколько экономичен данный способ кодирования (в нашем случае — русский язык).
Еще одно очевидное замечание можно сделать, вернувшись к примеру с телефоном. Для того чтобы запомнить номер, мы часто ищем закономерности в наборе цифр, что, в принципе, также является попыткой сжатия данных. Вполне логично запомнить вышеупомянутый телефон как «два, три тройки, три четверки».
Избыточность естественных языков
Теория информации гласит, что информации в сообщении тем больше, чем больше его энтропия. Для любой системы кодирования можно оценить ее максимальную информационную емкость (Hmax) и действительную энтропию (Н). Тогда случай Н
Измерение избыточности естественных языков (тех, на которых мы говорим) дает потрясающие результаты: оказывается, избыточность этих языков составляет около 80%, а это свидетельствует о том, что практически 80% передаваемой с помощью языка информации является избыточной, то есть лишней. Любопытен и тот факт, что показатели избыточности разных языков очень близки. Данная цифра примерно определяет теоретические пределы сжатия текстовых файлов.
Кодирование информации
Факт избыточности свидетельствует о возможностях перехода на иную систему кодирования, которая уменьшила бы избыточность передаваемого сообщения. Говоря о переходе на коды, которые позволяют уменьшить размер сообщения, вводят понятие «коды сжатия». В принципе, кодирование информации может преследовать различные цели:
Сжатие с потерями
Говоря о кодах сжатия, различают понятия «сжатие без потерь» и «сжатие с потерями». Очевидно, что когда мы имеем дело с информацией типа «номер телефона», то сжатие такой записи за счет потери части символов не ведет ни к чему хорошему. Тем не менее можно представить целый ряд ситуаций, когда потеря части информации не приводит к потери полезности оставшейся. Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где в силу огромных размеров файлов степень сжатия очень важна, и можно пожертвовать деталями, не существенными для восприятия этой информации человеком. Особые возможности для сжатия информации имеются при компрессии видео. В ряде случаев большая часть изображения передается из кадра в кадр без изменений, что позволяет строить алгоритмы сжатия на основе выборочного отслеживания только части «картинки». В частном случае изображение говорящего человека, не меняющего своего положения, может обновляться только в области лица или даже только рта — то есть в той части, где происходят наиболее быстрые изменения от кадра к кадру.
В целом ряде случаев сжатие графики с потерями, обеспечивая очень высокие степени компрессии, практически незаметно для человека. Так, из трех фотографий, показанных ниже, первая представлена в TIFF-формате (формат без потерь), вторая сохранена в формате JPEG c минимальным параметром сжатия, а третья с максимальным. При этом можно видеть, что последнее изображение занимает почти на два порядка меньший объем, чем первая.Однако методы сжатия с потерями обладают и рядом недостатков.
Первый заключается в том, что компрессия с потерями применима не для всех случаев анализа графической информации. Например, если в результате сжатия изображения на лице изменится форма родинки (но лицо при этом останется полностью узнаваемо), то эта фотография окажется вполне приемлемой, чтобы послать ее по почте знакомым, однако если пересылается фотоснимок легких на медэкспертизу для анализа формы затемнения — это уже совсем другое дело. Кроме того, в случае машинных методов анализа графической информации результаты кодирования с потерей (незаметные для глаз) могут быть «заметны» для машинного анализатора.
Вторая причина заключается в том, что повторная компрессия и декомпрессия с потерями приводят к эффекту накопления погрешностей. Если говорить о степени применимости формата JPEG, то, очевидно, он полезен там, где важен большой коэффициент сжатия при сохранении исходной цветовой глубины. Именно это свойство обусловило широкое применение данного формата в представлении графической информации в Интернете, где скорость отображения файла (его размер) имеет первостепенное значение. Отрицательное свойство формата JPEG — ухудшение качества изображения, что делает практически невозможным его применение в полиграфии, где этот параметр является определяющим.
Теперь перейдем к разговору о сжатии информации без потерь и рассмотрим, какие алгоритмы и программы позволяют осуществлять эту операцию.
Сжатие без потерь
Сжатие, или кодирование, без потерь может применяться для сжатия любой информации, поскольку обеспечивает абсолютно точное восстановление данных после кодирования и декодирования. Сжатие без потерь основано на простом принципе преобразования данных из одной группы символов в другую, более компактную.
Наиболее известны два алгоритма сжатия без потерь: это кодирование Хаффмена (Huffman) и LZW-кодирование (по начальным буквам имен создателей Lempel, Ziv, Welch), которые представляют основные подходы при сжатии информации. Кодирование Хаффмена появилось в начале 50-х; принцип его заключается в уменьшении количества битов, используемых для представления часто встречающихся символов и соответственно в увеличении количества битов, используемых для редко встречающихся символов. Метод LZW кодирует строки символов, анализируя входной поток для построения расширенного алфавита, основанного на строках, которые он обрабатывает. Оба подхода обеспечивают уменьшение избыточной информации во входных данных.
Кодирование Хаффмена
Кодирование Хаффмена [1] — один из наиболее известных методов сжатия данных, который основан на предпосылке, что в избыточной информации некоторые символы используются чаще, чем другие. Как уже упоминалось выше, в русском языке некоторые буквы встречаются с большей вероятностью, чем другие, однако в ASCII-кодах мы используем для представления символов одинаковое количество битов. Логично предположить, что если мы будем использовать меньшее количество битов для часто встречающихся символов и большее для редко встречающихся, то мы сможем сократить избыточность сообщения. Кодирование Хаффмена как раз и основано на связи длины кода символа с вероятностью его появления в тексте.
Статическое кодирование
Статическое кодирование предполагает априорное знание таблицы вероятностей символов. К примеру, если вы сжимаете файл, состоящий из текста, написанного на русском языке, то такая информация может быть получена из предварительного статистического анализа русского языка.
Динамическое кодирование
В том случае, когда вероятности символов входных данных неизвестны, используется динамическое кодирование, при котором данные о вероятности появления тех или иных символов уточняются «на лету» во время чтения входных данных.
LZW-сжатие
Алгоритм LZW [2], предложенный сравнительно недавно (в 1984 году), запатентован и принадлежит фирме Sperry.
LZW-алгоритм основан на идее расширения алфавита, что позволяет использовать дополнительные символы для представления строк обычных символов. Используя, например, вместо 8-битовых ASCII-кодов 9-битовые, вы получаете дополнительные 256 символов. Работа компрессора сводится к построению таблицы, состоящей из строк и соответствующих им кодов. Алгоритм сжатия сводится к следующему: программа прочитывает очередной символ и добавляет его к строке. Если строка уже находится в таблице, чтение продолжается, если нет, данная строка добавляется к таблице строк. Чем больше будет повторяющихся строк, тем сильнее будут сжаты данные. Возвращаясь к примеру с телефоном, можно, проведя весьма упрощенную аналогию, сказать, что, сжимая запись 233 34 44 по LZW-методу, мы придем к введению новых строк — 333 и 444 и, выражая их дополнительными символами, сможем уменьшить длину записи.
Какой же выбрать архиватор?
Наверное, читателю будет интересно узнать, какой же архиватор лучше. Ответ на этот вопрос далеко не однозначен.
Если посмотреть на таблицу, в которой «соревнуются» архиваторы (а сделать это можно как на соответствующем сайте в Интернете [3], так и на нашем CD-ROM), то можно увидеть, что количество программ, принимающих участие в «соревнованиях», превышает сотню. Как же выбрать из этого многообразия необходимый архиватор?
Вполне возможно, что для многих пользователей не последним является вопрос способа распространения программы. Большинство архиваторов распространяются как ShareWare, и некоторые программы ограничивают количество функций для незарегистрированных версий. Есть программы, которые распространяются как FreeWare.
Если вас не волнуют меркантильные соображения, то прежде всего необходимо уяснить, что имеется целый ряд архиваторов, которые оптимизированы на решение конкретных задач. В связи с этим существуют различные виды специализированных тестов, например на сжатие только текстовых файлов или только графических. Так, в частности, Wave Zip в первую очередь умеет сжимать WAV-файлы, а мультимедийный архиватор ERI лучше всех упаковывает TIFF-файлы. Поэтому если вас интересует сжатие какого-то определенного типа файлов, то можно подыскать программу, которая изначально предназначена специально для этого.
Существует тип архиваторов (так называемые Exepackers), которые служат для сжатия исполняемых модулей COM, EXE или DLL. Файл упаковывается таким образом, что при запуске он сам себя распаковывает в памяти «на лету» и далее работает в обычном режиме.
Одними из лучших в данной категории можно назвать программы ASPACK и Petite. Более подробную информацию о программах данного класса, а также соответствующие рейтинги можно найти по адресу [4].
Если же вам нужен архиватор, так сказать, «на все случаи жизни», то оценить, насколько хороша конкретная программа, можно обратившись к тесту, в котором «соревнуются» программы, обрабатывающие различные типы файлов. Просмотреть список архиваторов, участвующих в данном тесте, можно на нашем CD-ROM.
При этом необходимо отметить, что в тестах анализируются лишь количественные параметры, такие как скорость сжатия, коэффициент сжатия и некоторые другие, однако существует еще целый ряд параметров, которые определяют удобство пользования архиваторами. Перечислим некоторые из них.
Поддержка различных форматов
Большинство программ поддерживают один или два формата. Однако некоторые, такие, например, как программа WinAce, поддерживают множество форматов, осуществляя компрессию в форматах ACE, ZIP, LHA, MS-CAB, JAVA JAR и декомпрессию в форматах ACE, ZIP, LHA, MS-CAB, RAR, ARC, ARJ, GZip, TAR, ZOO, JAR.
Умение создавать solid-архивы
Создание solid-архивов — это архивирование, при котором увеличение сжатия возрастает при наличии большого числа одновременно обрабатываемых коротких файлов. Часть архиваторов, например ACB, всегда создают solid-архивы, другие, такие как RAR или 777, предоставляют возможность их создания, а некоторые, например ARJ, этого делать вообще не умеют.
Возможность создавать многотомные архивы
Многотомные архивы необходимы, когда файлы переносятся с компьютера на компьютер с помощью дискет и архив не помещается на одной дискете.
Возможность работы в качестве менеджера архивов
Различные программы в большей или меньшей степени способны вести учет архивам на вашем диске. Некоторые архиваторы, например WinZip, позволяют быстро добраться до любого архивного файла (и до его содержимого), в каком бы месте диска он ни находился.
Возможность парольной защиты
В принципе, архивирование есть разновидность кодирования, и если раскодирование доступно по паролю, то это, естественно, может использоваться как средство ограничения доступа к конфиденциальной информации.
Удобство в работе
Не последним фактором является удобство в работе — наличие продуманного меню, поддержка мыши, оптимальный набор опций, наличие командной строки и т.д. При этом необходимо отметить, что для многих (особенно непрофессионалов) важен фактор привычки. Если вы привыкли работать с определенной программой и вам сообщают, что есть альтернативная программа, которая на каком-либо тесте выигрывает у вашей десять пунктов, — это вполне может означать, что программа-победитель сжимает файлы лишь на 2% лучше, а для вас это не принципиально. При этом вероятно, что эта программа менее удобна в работе и т.д. Однако если вам не хватает именно 2%, чтобы сжать распространяемую вами программу до размера дискеты, то подобный архиватор для вас — находка.
Я отнюдь не сторонник консервативной позиции «раз все работает, то главное — ничего не менять», я лишь подчеркиваю, что переход на новую программу должен быть обоснованным.
В каких случаях используется сжатие без потерь
Содержание урока
Вопросы и задания
Вопросы и задания
1. За счёт чего удаётся сжать данные без потерь? Когда это сделать принципиально невозможно?
2. Какие типы файлов сжимаются хорошо, а какие — плохо? Почему?
3. Текстовый файл, записанный в однобайтной кодировке, содержит только 33 заглавные русские буквы, цифры и пробел. Ответьте на следующие вопросы:
• какое минимальное число битов нужно выделить на символ при передаче, если каждый символ кодируется одинаковым числом битов?
• сколько при этом будет занимать заголовок пакета данных?
• при какой минимальной длине текста коэффициент сжатия будет больше 1?
4. На чём основан алгоритм сжатия RLE? Когда он работает хорошо? Когда нет смысла его использовать?
5. Что такое префиксный код?
6. В каких случаях допустимо сжатие с потерями?
7. Опишите простейшие методы сжатия рисунков с потерями. Приведите примеры.
8. На чём основан алгоритм JPEG? Почему это алгоритм сжатия с потерями?
9. Что такое артефакты?
10. Для каких типов изображений эффективно сжатие JPEG? Когда его не стоит применять?
11. На чём основано сжатие звука в алгоритме MP3?
12. Что такое битрейт? Как он связан с качеством звука?
13. Какое качество звука принимается за эталон качества на непрофессиональном уровне?
14. Какие методы используются для сжатия видео?
Подготовьте сообщение
а) «Программы для сжатия данных»
б) «Алгоритмы сжатия изображений»
в) «Аудиокодеки»
г) «Видеокодеки»
Следующая страница  Задачи
Задачи
Cкачать материалы урока
Сжатие данных без потерь (англ. lossless data compression ) — класс алгоритмов сжатия данных (видео, аудио, графики, документов, представленных в цифровом виде), при использовании которых закодированные данные однозначно могут быть восстановлены с точностью до бита, пикселя, вокселя и т.д. При этом оригинальные данные полностью восстанавливаются из сжатого состояния. Этот тип сжатия принципиально отличается от сжатия данных с потерями. Для каждого из типов цифровой информации, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
Сжатие данных без потерь используется во многих приложениях. Например, оно используется во всех файловых архиваторах. Оно также используется как компонент в сжатии с потерями.
Сжатие без потерь используется, когда важна идентичность сжатых данных оригиналу. Обычный пример — исполняемые файлы и исходный код. Некоторые графические файловые форматы (например PNG) используют только сжатие без потерь, тогда как другие (TIFF, FLIF или GIF) могут использовать сжатие как с потерями, так и без потерь.
Содержание
Сжатие и комбинаторика [ править | править код ]
Легко доказывается теорема.
Для любого N > 0 нет алгоритма сжатия без потерь, который:
Доказательство. Не ограничивая общности, можно предположить, что уменьшился файл A длины ровно N. Обозначим алфавит как Σ  . Рассмотрим множество Σ 0 ∪ Σ 1 ∪ … ∪ Σ N − 1 ∪ cup Sigma ^ cup ldots cup Sigma ^cup > . В этом множестве 256 0 + 256 1 + … + 256 N − 1 + 1 +256^ +ldots +256^+1> исходных файлов, в то время как сжатых не более чем 256 0 + 256 1 + … + 256 N − 1 +256^ +ldots +256^> . Поэтому функция декомпрессии неоднозначна, противоречие. Теорема доказана.
. Рассмотрим множество Σ 0 ∪ Σ 1 ∪ … ∪ Σ N − 1 ∪ cup Sigma ^ cup ldots cup Sigma ^cup > . В этом множестве 256 0 + 256 1 + … + 256 N − 1 + 1 +256^ +ldots +256^+1> исходных файлов, в то время как сжатых не более чем 256 0 + 256 1 + … + 256 N − 1 +256^ +ldots +256^> . Поэтому функция декомпрессии неоднозначна, противоречие. Теорема доказана.
Впрочем, данная теорема нисколько не бросает тень на сжатие без потерь. Дело в том, что любой алгоритм сжатия можно модифицировать так, чтобы он увеличивал размер не более чем на 1 бит: если алгоритм уменьшил файл, пишем «1», потом сжатую последовательность, если увеличил — пишем «0», затем исходную.
Так что несжимаемые фрагменты не приведут к бесконтрольному «раздуванию» архива. «Реальных» же файлов длины N намного меньше, чем 256 N > (говорят, что данные имеют низкую информационную энтропию) — например, маловероятно, чтобы буквосочетание «щы» встретилось в осмысленном тексте, а в оцифрованном звуке уровень не может за один семпл прыгнуть от 0 до 100 %. К тому же за счёт специализации алгоритмов на некоторый тип данных (текст, графику, звук и т. д.) удаётся добиться высокой степени сжатия: так, применяющиеся в архиваторах универсальные алгоритмы сжимают звук примерно на треть (в 1,5 раза), в то время как FLAC — в 2,5 раза. Большинство специализированных алгоритмов малопригодны для файлов «чужих» типов: например, звуковые данные плохо сжимаются алгоритмом, рассчитанным на тексты.
Метод сжатия без потерь [ править | править код ]
В общих чертах смысл сжатия без потерь таков: в исходных данных находят какую-либо закономерность и с учётом этой закономерности генерируют вторую последовательность, которая полностью описывает исходную. Например, для кодирования двоичных последовательностей, в которых много нулей и мало единиц, мы можем использовать такую замену:
В таком случае шестнадцать битов
будут преобразованы в тринадцать битов
Такая подстановка является префиксным кодом, то есть обладает такой особенностью: если мы запишем сжатую строку без пробелов, мы всё равно сможем расставить в ней пробелы — а значит, восстановить исходную последовательность. Наиболее известным префиксным кодом является код Хаффмана.
Большинство алгоритмов сжатия без потерь работают в две стадии: на первой генерируется статистическая модель для входящих данных, вторая отображает входящие данные в битовом представлении, используя модель для получения «вероятностных» (то есть часто встречаемых) данных, которые используются чаще, чем «невероятностные».
Статистические модели алгоритмов для текста (или текстовых бинарных данных, таких как исполняемые файлы) включают:
Алгоритмы кодирования через генерирование битовых последовательностей:
Сжатие информации
Кодирование делится на три большие группы – сжатие (эффективные коды), помехоустойчивое кодирование и криптография.
Коды, предназначенные для сжатия информации, делятся, в свою очередь, на коды без потерь и коды с потерями.
Кодирование без потерь подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации.
Кодирование с потерями имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных.
Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где мелкие отклонения от оригинала незаметны или несущественны, а степень сжатия в силу огромных размеров файлов очень важна.
Сжатие без потерь применяется во всех остальных случаях – для текстов, исполняемых файлов, высококачественного звука и графики и т.д. и т.п.
Сжатие необходимо для сокращения длины сообщения и уменьшения времени для его передачи по каналам связи. Все используемые методы упаковки информации можно разделить на два класса: упаковка без потери информации и упаковка с потерей информации.
Сжатие представляет собой предмет выбора оптимального решения. Более эффективный алгоритм требует больше процессорной мощности или времени, необходимого для декодирования информации.
Один из самых простых способов сжатия информации – групповое кодирование. В соответствии с этой схемой серии повторяющихся величин (например, число) заменяются единственной величиной и количеством. Например, аbbbbccdddeeee заменяется на 1a4b2c3d4e. Формат графических файлов PCX использует этот метод.
Простейшие алгоритмы сжатия, называемые также алгоритмами оптимального кодирования, основаны на учете распределения вероятностей элементов исходного сообщения (текста, изображения, файла). На практике обычно в качестве приближения к вероятностям используют частоты встречаемости элементов в исходном сообщении. Вероятность — абстрактное математическое понятие, связанное с бесконечными экспериментальными выборками данных, а частота встречаемости — величина, которую можно вычислить для конечных множеств данных. При достаточно большом количестве элементов в множестве экспериментальных данных можно говорить, что частота встречаемости элемента близка (с некоторой точностью) к его вероятности.
Если вероятности неодинаковы, то имеется возможность наиболее вероятным (часто встречающимся) элементам сопоставить более короткие кодовые слова и, наоборот, маловероятным элементам сопоставить более длинные кодовые слова. Таким способом можно уменьшить среднюю длину кодового слова. Оптимальный алгоритм кодирования делает это так, чтобы средняя длина кодового слова была минимальной, т. е. при меньшей длине кодирование станет необратимым. Такой алгоритм существует, он был разработан Хаффманом и носит его имя. Этот алгоритм используется, например, при создании файлов в формате JPEG.
Методом Хаффмана представляет общую схему сжатия, которая имеет много вариантов. Основная схема – присвоение двоичного кода каждой уникальной величине, причем длина этих кодов различна.
Для того чтобы сформировать минимальный код для каждого символа сообщения, используется двоичное дерево. В основном алгоритме метода объединяются вместе элементы, повторяющиеся наименее часто, затем пара рассматривается как один элемент и их частоты объединяются. Это повторяется до тех пор, пока все элементы не объединятся в пары.
Рассмотрим пример. Пусть дано сообщение abbbcccddeeeeeeeeef.
Частоты символов: а: 1, b: 3, c: 3, d: 2, e: 9, f: 1.
 Наиболее редко используемы в этом примере a и f, так что они становятся первой парой: a – присваивается нулевая ветвь, а f – первая. Это означает, что 0 и 1 будут младшими битами для a и f соответственно. Старшие биты будут получены после построения дерева (рис. 2.4).
Наиболее редко используемы в этом примере a и f, так что они становятся первой парой: a – присваивается нулевая ветвь, а f – первая. Это означает, что 0 и 1 будут младшими битами для a и f соответственно. Старшие биты будут получены после построения дерева (рис. 2.4).
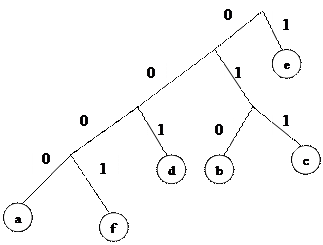 |
Частоты первых двух символов (a и f) суммируются, что дает 2. Поскольку теперь самая низкая частота 2, эта пара объединяется с d (тоже имеет частоту – 2). Исходной паре присваивается нулевая ветвь, а d – первая. Теперь код для a заканчивается на 00, f – на 01, d – на 1. Код для d будет короче на 1 бит. Дерево строится подобным образом для всех символов. Получаем следующие коды:
Исходная последовательность будет закодирована следующим образом: 00000100100100110110110010011111111110001.
Полученная таблица кодов передается приемнику информации и используется при декодировании. По алгоритму Хаффмана наименее распространенные символы кодируются более длинным кодом, наиболее распространенные – коротким.
В результате может быть получена степень сжатия 8:1, что зависит от исходного формата представления информации (1 байт на 1 символ, например, или 2 байта).
Схема Хаффмана работает не так хорошо для информации, содержащей длинные последовательности повторяющихся символов, которые могут быть сжаты лучше с использованием групповой или какой-либо другой схемы кодирования.
Вследствие того, что алгоритм Хаффмана реализуется в два прохода (1 – накопление статистики при построении статистической модели, 2 – кодирование), компрессия и декомпрессия в данном алгоритме – сравнительно медленные процессы.
Другая проблема заключается в чувствительности к отброшенным или добавленным битам. Поскольку все биты сжимаются без учета границ байта, единственный способ, при помощи которого дешифратор может узнать о завершении кода, – достигнуть конца ветви. Если бит отброшен или добавлен, дешифратор начинает обработку с середины кода, и остальная часть данных становится бессмыслицей.Полученная таблица кодов передается приемнику информации и используется при декодировании. По алгоритму Хаффмана наименее распространенные символы кодируются более длинным кодом, наиболее распространенные – коротким.
В результате может быть получена степень сжатия 8:1, что зависит от исходного формата представления информации (1 байт на 1 символ, например, или 2 байта).
Схема Хаффмана работает не так хорошо для информации, содержащей длинные последовательности повторяющихся символов, которые могут быть сжаты лучше с использованием групповой или какой-либо другой схемы кодирования.
Вследствие того, что алгоритм Хаффмана реализуется в два прохода (1 – накопление статистики при построении статистической модели, 2 – кодирование), компрессия и декомпрессия в данном алгоритме – сравнительно медленные процессы.
Другая проблема заключается в чувствительности к отброшенным или добавленным битам. Поскольку все биты сжимаются без учета границ байта, единственный способ, при помощи которого дешифратор может узнать о завершении кода, – достигнуть конца ветви. Если бит отброшен или добавлен, дешифратор начинает обработку с середины кода, и остальная часть данных становится бессмыслицей.
| | | следующая лекция ==> | |
| Параметры семплирования | | | Информационные революции |
Дата добавления: 2014-01-06 ; Просмотров: 372 ; Нарушение авторских прав? ;
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет



