DMA для новичков или то, что вам нужно знать
Всем привет, сегодня мы с вами поговорим о DMA: именно о той технологии, которая помогает вашему компьютеру воспроизводить для вас музыку, выводить изображение на экран, записывать информацию на жесткий диск, и при этом оказывать на центральный процессор просто мизерную нагрузку.
DMA, что это? О чем вы говорите?
DMA, или Direct Memory Access – технология прямого доступа к памяти, минуя центральный процессор. В эпоху 486-ых и первых Pentium во всю царствовала шина ISA, а также метод обмена данными между устройствами – PIO (Programmed Input/Output).
Когда объемы данных, которыми оперирует процессор начали возрастать, стало понятно, что нужно минимизировать участие процессора в цепочке обмена данными, а то прийдется туго. И вот тогда активное применение нашла технология прямого доступа к памяти.
Кстати говоря, DMA используется не только для обмена данными между устройством и ОЗУ, но также между устройствами в системе, возможен DMA трансфер между двумя участками ОЗУ (хотя данный маневр не применим к x86 архитектуре). Также в своем процессоре Cell, IBM использует DMA как основной механизм обмена данными между синергетическими процессорными элементами (SPE) и центральным процессорным элементом (PPE). Также каждый SPE и PPE может обмениватся данными через DMA с оперативной памятью. Данный прием – на самом деле большое преимущество Cell, ибо избавляет от проблем когерентности кешей при мультипроцессорной обработке данных.
И снова теория
Прежде чем мы перейдем к практике, я бы хотел осветить несколько важных аспектов программирования PCI, PCI-E устройств.
Я вскользь упомянул о регистрах устройства, но как же к ним имеет доступ центральный процессор? Как многие из вас знают, есть такая сущность в компьютерных технологиях, как IO порты (Input/Output ports). Они предназначены для обмена информацией между центральным процессором и периферийными устройствами, а доступ к ним возможен с помощью специальных ассемблерных инструкций — in/out. BIOS (или OpenFirmware на PPC based системах) на ранних этапах инициализации PCI устройств, а также некоторых других (Super IO контроллера, контроллера PS/2 устройств, ACPI timer и т.д.), закрепляет за определенным контроллером собственный диапазон IO портов, куда и отображаются регистры устройства.
Итак, существует два метода утилизации DMA: contiguous DMA и scatter/gather DMA.
Contiguous DMA
Scatter/gather DMA
С ростом скорости Ethernet адаптеров, contiguous DMA показал свою несостоятельность. В основном из-за того, что требовались области памяти достаточно большого размера, которые подчас невозможно было выделить, так как в современных системах фрагментация физической памяти достаточно высока. Во всем виноват механизм виртуальной памяти, без которого нынче никуда 🙂
Решение напрашивается само собой: использовать вместо одного большого участка памяти несколько, но в разных регионах этой самой памяти. Возникает вопрос, но как же сообщить контроллеру устройства, как инициировать DMA трансфер и по какому адресу писать данные? И тут нашли решение, использовать дескрипторы, чтобы описывать каждый вот такой участок в оперативной памяти.
На сегодня пожалуй все, иначе информации станет слишком много. В следующей статье я покажу вам, как с этой уличной магией работает IOKit. Жду отзывов и дополнений 😉
Прямой доступ к памяти
Прямой доступ к памяти (англ. Direct Memory Access, DMA ) — режим обмена данными между устройствами или же между устройством и основной памятью (RAM) без участия Центрального Процессора (ЦП). В результате скорость передачи увеличивается, так как данные не пересылаются в ЦП и обратно.
Кроме того, данные пересылаются сразу для многих слов, расположенных по подряд идущим адресам, что позволяет использование т. н. «пакетного» (burst) режима работы шины — 1 цикл адреса и следующие за ним многочисленные циклы данных. Аналогичная оптимизация работы ЦП с памятью крайне затруднена.
В оригинальной архитектуре IBM PC (шина ISA) был возможен лишь при наличии аппаратного DMA-контроллера (микросхема с индексом Intel 8237).
DMA-контроллер может получать доступ к системной шине независимо от центрального процессора. Контроллер содержит несколько регистров, доступных центральному процессору для чтения и записи. Регистры контроллера задают порт (который должен быть использован), направление переноса данных (чтение/запись), единицу переноса (побайтно/пословно), число байтов, которое следует перенести.
ЦП программирует контроллер DMA, устанавливая его регистры. Затем процессор даёт команду устройству (например, диску) прочитать данные во внутренний буфер. DMA-контроллер начинает работу, посылая устройству запрос чтения (при этом устройство даже не знает, пришёл ли запрос от процессора или от контроллера DMA). Адрес памяти уже находится на адресной шине, так что устройство знает, куда следует переслать следующее слово из своего внутреннего буфера. Когда запись закончена, устройство посылает сигнал подтверждения контроллеру DMA. Затем контроллер увеличивает используемый адрес памяти и уменьшает значение своего счётчика байтов. После чего запрос чтения повторяется, пока значение счётчика не станет равно нулю. По завершении цикла копирования устройство инициирует прерывание процессора, означающее завершение переноса данных. Контроллер может быть многоканальным, способным параллельно выполнять несколько операций.
Содержание
Захват шины (bus mastering)
В шинах MicroChannel, SBus, разработанной под их большим влиянием PCI и её концептуальных производных AGP и PCI-X, используется иная реализация DMA. Эти шины позволяют любому устройству заявить о возникновении потребности к захвату шины, таковая потребность удовлетворяется т. н. арбитром при первой возможности. Устройство, успешно осуществившее захват шины, самостоятельно выставляет на шину сигналы адреса и управления и исполняет в течение какого-то времени ту же ведущую роль на шине, что и ЦП. Доступ ЦП к шине при этом кратковременно блокируется.
В такой реализации DMA не существует DMA-контроллера, а также номера входа DMA-контроллера.
Некоторые старые устройства PCI, а именно, реализации звуковых карт семейства Sound Blaster, использовали тот же DMA-контроллер 8237 из оригинальной архитектуры IBM PC. Такое использование является, безусловно, устаревшим для PCI, но поддерживалось с целью обеспечить полную совместимость по ПО и драйверам с версиями Sound Blaster для шины ISA.
Данная поддержка называется Distributed DMA (D-DMA) и реализована аппаратным образом как в устройстве, так и в логике моста PCI-ISA, в которой на PCI-системах размещена и логика оригинального IBM PC DMA контроллера 8237. Реализация включает в себя 2 запроса: сначала от устройства мосту PCI-ISA, затем от моста основной памяти.
Кроме упомянутых реализаций Sound Blaster, практически никакие устройства PCI не используют понятие «номер входа DMA-контроллера», как и 8237 вообще.
DMA и виртуальная память, IOMMU и AGP GART
В операционных системах со страничной виртуальной памятью, таких, как Windows и семейство UNIX, непрерывный регион виртуальных адресов может быть реализован разрывно расположенными физическими страницами.
Исполнение DMA по такому региону представляет собой довольно сложную задачу. Также сложной задачей является исполнение DMA по отгружаемой памяти.
Решение этой задачи требует выявления физических страниц, реализующих регион, и их блокировку от отгрузки обращением к подсистеме виртуальной памяти. Далее становится возможным нахождение физических адресов страниц региона, которые в общем случае не являются непрерывными и формируют так называемый «список рассеяния/сборки» (англ. scatter-gather list — SGL).
Задача исполнения DMA по таковому списку может быть решена одним из следующих способов.
1. Выделение подряд идущей физической памяти в ядре операционной системы и промежуточное копирование всех данных туда/оттуда (т. н. «буфер отскока» — англ. bounce buffer ).
Недостатки: трата времени процессора на копирование, потребление крайне ограниченного ресурса непрерывной физической памяти, занятие места в ограниченной части памяти, к которой есть доступ у DMA (первый гигабайт на x86).
2. Разбиение операции на подоперации по границам элементов SGL, с прерыванием в конце каждой операции.
Использовалось в старых 8-битных SCSI-контроллерах, поставляемых со сканерами типа HP ScanJet.
Недостатки: большое количество прерываний.
3. Поддержка SGL самим устройством, с требованием копирования SGL, преобразованного в формат, специфичный для устройства, в устройство через многочисленные обращения к регистрам устройства.
Недостатки: крайне высокая сложность устройства, невысокая производительность большого числа записей в регистры.
4. Поддержка SGL самим устройством, с требованием размещения SGL, преобразованного в формат, специфичный для устройства, в физически непрерывном регионе основной памяти.
Устройство читает SGL тем же механизмом DMA с захватом шины, что и собственно данные, тем самым реализуя функциональность некоего процессора, читающего и исполняющего свою собственную «программу», реализованную как список дескрипторов SGL. Данная архитектура называется «цепной DMA» (англ. chain DMA ), реализована в практически всем стандартном оборудовании современного компьютера — Intel IDE (в примитивном виде), UHCI и OHCI USB, OHCI 1394, а также в большинстве PCI-адаптеров, Ethernet и SCSI (даже в устаревшем AIC78xx). Хороший пример реализации данной архитектуры в очень сложном и развитом виде дан в спецификации оборудования OHCI 1394. По некоторым сведениям, данная архитектура под названием «канальные программы» использовалась ещё в IBM 360, известных в СССР как ЕС ЭВМ.
Недостатки: высокая сложность устройства, хотя и ниже в числе транзисторов, чем предыдущий вариант. Например, контроллер UHCI USB (согласно спецификации на сайте Intel) требует около 5000 транзисторов.
5. Поддержка SGL в межшинном оборудовании, при которой представление физически разрывного буфера для стороны устройства выглядит физически непрерывным.
Недостатки: требование сложной логики уже не в устройстве, а в платформе.
DMA и IDE/ATA, Ultra DMA
Первоначальный контроллер жесткого диска IBM PC/AT не поддерживал DMA, и требовал передачи всех данных дискового ввода/вывода инструкциями REP INSW/REP OUTSW через порт 0x1f0.
В начале 90х годов диски MFM/RLL вымерли, сменившись дисками IDE, но регистровый интерфейс ПО к контроллеру не изменился.
Низкая производительность такого контроллера стала серьёзной проблемой, особенно на системах PCI. Помимо требования нескольких циклов PCI на 2 байта переданных данных, это приводило к загрузке процессора дисковым вводом-выводом.
Для решения проблемы ряд компаний, в том числе Intel, разработали контроллеры IDE с поддержкой DMA. Контроллеры были и есть несовместимы по ПО между различными производителями, хотя совместимость всех Intel IDE/ATA/SATA снизу вверх более или менее поддерживается.
Также особенностью этой поддержки является использование новых команд протокола IDE/ATA, а значит, и требование поддержки DMA не только контроллером, но и самим жестким диском.
Около 2000 года поддержка DMA по шине IDE/ATA развилась в сторону увеличения тактовой частоты шины, что потребовало нового типа кабеля от контроллера к диску с удвоенным числом проводников меньшего размера. Эта технология называлась Ultra DMA (UDMA).
Многие операционные системы требовали действий администратора для использования IDE DMA. Так, например, стандартные ядра Linux до примерно 2004 года не имели такой поддержки, требовалось перестроение ядра с отредактированным файлом конфигурации.
В семействе Windows поддержка IDE DMA появилась сначала только для Intel в пакетах обновлений к Windows NT4, и требовала на большинстве систем ручного редактирования реестра для задействования.
В Windows 2000 это требование исчезло, но появилось требование обязательной вписки даже не-загрузочных дисков в BIOS и обязательного выставления режима DMA для них в настройках BIOS. Эти настройки BIOS становились видимы ядру ОС через технологию ACPI, и ОС не позволяла включить DMA для диска, не вписанного в BIOS. Для сравнения: NT4 поддерживала и произвольный размер диска, и DMA без вписки диска в BIOS.
В системах Linux для включения или выключения IDE DMA вручную может применяться команда hdparm (см. ниже). Современные версии ядра автоматически включают DMA режим, что можно наблюдать в сообщениях отладки (строки вида ata1.00: configured for UDMA/133 или hda: UDMA/33 mode selected).
Прямой доступ к памяти: схема организации, типы процессоров
 Необходимость организации канала прямого доступа к памяти
Необходимость организации канала прямого доступа к памяти
 Необходимость организации канала прямого доступа к памяти
Необходимость организации канала прямого доступа к памятиИнформация, хранимая во внешних устройствах памяти большой емкости, таких, как накопители на магнитных дисках и лентах, организована в виде блоков размером единицы и более килобайт. Для обмена данными между указанными устройствами памяти и основной (оперативной) памятью микропроцессора не подходят ни программный способ обмена, ни прерывания. Это обусловлено тем, что обмен производится блоками фиксированного размера в строгой последовательности, соответствующей расположению информации на магнитном носителе. Время на обмен одного байта данных строго фиксировано, ограничено скоростью передвижения носителя относительно магнитных головок и составляет весьма малое значение (единицы микросекунд и меньше). При программно–управляемом обмене и обмене с использованием прерываний на передачу байта данных затрачивается большее время. Для обмена данными в указанных условиях организуется прямой доступ к памяти (ПДП), или Direct Memory Access ( DMA ).
Каналом прямого доступа к памяти называют средства, позволяющие осуществить быстрый обмен данными непосредственно между основной памятью и внешним устройством (ВУ) без участия процессора. При этом способе обмена процедура ввода/вывода полностью осуществляется аппаратными средствами и возлагается на контроллер ПДП.
Отметим, что обычный обмен между внешним устройством и памятью реализуются за два командных цикла: вначале данные поступают от источника в центральный процессор, а затем — из процессора в приемник. При ПДП данные не проходят через процессор, и передача слова производится за один цикл. Поэтому основное достоинство обмена по каналу ПДП — высокая скорость обмена, ограниченная только временем доступа к памяти.

Принципы организации ПДП. Структурная схема организации канала ПДП показана на рис. 3.10.1. Прямой доступ к памяти предоставляется по завершении текущего машинного цикла процессора. В отличие от прерывания обмен по каналу ПДП выполняется без участия программы, поэтому содержимое рабочих регистров процессора сохраняется и на вхождение в режим ПДП не требуется затрат времени (отсутствует необходимость хранения в стеке содержимого рабочих регистров процессора).
Центральный процессор выполняет программирование контроллера, настраивая его на требуемый режим работы, и следит за состоянием контроллера. Во время обмена данными по каналу ПДП процессор отключен, а контроллер вырабатывает сигналы управления обменом для памяти и внешнего устройства. Связь внешнего устройства памятью осуществляется по шинам адреса и данных системного интерфейса. Проблема совместного использования шин центрального процессора и внешнего устройства решается двумя способами: организацией режима обмена с «захватом цикла» и (пакетного, или непрерывного) режима с блокировкой центрального процессора.
В режиме с «захватом цикла» обмен ведется одиночными передачами, когда для прямого доступа к памяти выделяются отдельные циклы (такты), т. е. передача данных (слов) перемежается с выполнением программы.
Один из вариантов обмена с «захватом цикла» состоит в использовании тех тактов, в которых центральный процессор не обменивается данными с памятью. Такие такты должны быть известны контроллеру ПДП. Некоторые процессоры вырабатывают специальный сигнал, указывающий используется ли процессором в данном цикле память. Например, Такой сигнал VMA вырабатывает микропроцессор
Motorola 6800
Процессор Intel 8080 никогда не использует четвертый и пятый такты машинных циклов для доступа к внешней памяти. Кроме того, каждый командный цикл начинается с машинного цикла М1 — выборки команды. В такте декодирования принятой процессором команды этого машинного цикла системные шины не используются. На это время системные шины можно отдать для передачи одного слова по каналу ПДП. Применение рассмотренного способа организации обмена не снижает производительности процессоров, однако:
● требует дополнительных аппаратных затрат и позволяет реализовать только случайные, нерегулярные передачи;
● скорость обмена будет не быстрой, темп обмена нерегулярен, так как длительности циклов различных команд различны, и, кроме того, прямой доступ может все–таки замедлить выполнение программы, если цикл ПДП не превышает интервал, соответствующий такту процессора.
Более распространенным является вариант способа с «захватом цикла», при котором центральный процессор принудительно отключается от системных шин адреса и данных. Его реализация связана с введением двух линий для передачи сигналов запроса на захват шин (ЗЗхв) и подтверждения захвата (ПЗхв). Сигнал ЗЗхв формируется контроллером ПДП.
После получения сигнала ЗЗхв процессор:
● приостанавливает выполнение очередной команды, не дожидаясь ее завершения;
● выдает в системный интерфейс сигнал подтверждения захвата ПЗхв;
● отключается от шин адреса и данных, переводя в высокоомное состояние шинные формирователи.
После получения сигнала ПЗхв контроллер ПДП использует шины системного интерфейса для обмена байтом или словом между ВУ и памятью. Затем снимает сигнал запроса ЗЗхв и возвращает управление шинами центральному процессору. Подготовив очередной байт или слово данных, контроллер ПДП вновь посылает сигнал ЗЗхв процессору и т. д.
Как уже отмечалось, режим ПДП не требует сохранения состояния регистров процессора в стеке. Поэтому передача данных с «захватом цикла» происходит с большей скоростью, чем при обмене в режиме прерываний.
Способ ПДП с блокировкой процессора отличается от способа с «захватом цикла» тем, что управление шинами контроллеру передается на время обмена блоком данных, а не на время обмена байтом или словом. Его следует применять, когда время обмена байтом сопоставимо с циклом процессора. В этом случае между двумя операциями обмена процессор не успевает выполнить ни одной команды. При непрерывной передаче массива данных скорость обмена ограничивается длительностью циклов устройства памяти, быстродействием самого контроллера и скоростью выдачи/приема данных внешним устройством.
Обмен данными по каналу ПДП требует предварительной подготовки контроллера. Она заключается в том, что программа загрузки устанавливает необходимые параметры для передачи:
● количество байтов (слов) данных, которые должны быть переданы;
● начальный адрес передаваемых данных (адрес первого байта или слова);
● направление передачи (запись/чтение).
Для занесения этих параметров в контроллере предусмотрены регистр адреса и счетчик байтов (слов).
Реализация прямого доступа к памяти. В качестве примера рассмотрим особенности схемной реализации и работы канала ПДП при передаче из внешнего устройства в память блоков данных в режиме с «захватом цикла». Схема такого устройства ПДП приведена на рис. 3.10.2. В устройстве можно выделить три вида аппаратных средств.

Средства адресации и контроля переданных слов:
● суммирующий 16–разрядный счетчик текущего адреса, разделенный на две половины для младших (МР) и старших (СР) разрядов. Каждая половина имеет свой адрес, по которому происходит начальная загрузка счетчика. На выходе счетчиков включены управляемые буферы для передачи адреса в память;
● вычитающий 8–разрядный счетчик слов, контролирующий число оставшихся для передачи слов. На его выходе включен логический элемент ИЛИ–НЕ, формирующий для внешнего устройства Флаг = 1 по завершении передачи блока данных, когда на вход ИЛИ–НЕ (10) поступает код 000000002;
DС с тремя логическими элементами ИЛИ–НЕ (1, 2, 3), включенными на его выходе. Дешифратор с логическими элементами инициирует загрузку счетчиков адреса и слов.
Средство хранения данных, в качестве которого используется восьмиразрядный буферный регистр. К выходу регистра подключен управляемый буфер, обеспечивающий побайтное считывание данных из регистра и запись их в память.
Средства управления
● двухразрядный двоичный счетчик, управляющий записью данных в память и состоянием счетчиков адреса и слов;
● триггер запроса ТЗ, предназначенный для формирования сигнала запроса на ПДП (ЗПДП) для центрального процессора по стробу, поступающему от внешнего устройства, и хранения сигнала ЗПДП до конца передачи блока данных;
● логические элементы 4–9, обеспечивающие требуемый алгоритм управления. Назначение используемых сигналов приведено в табл. 3.10.1.
Принцип работы устройства ПДП. Программа, выполняемая центральным процессором, задает необходимые параметры для передачи данных:
● 16–разрядный адрес ячейки памяти для хранения первого слова путем последовательной загрузки в счетчик адреса младшего (МБ) и старшего (СБ) байтов;
● количество передаваемых слов путем загрузки числа л в счетчик слов. Из внешнего устройства ВУ поступают байт данных и строб, по которому байт данных заносится в буферный регистр. Строб также устанавливает триггер запроса ТЗ в единичное состояние. С выхода триггера ТЗ снимается сигнал запроса ПДП (ЗПДП). Получив сигнал ЗПДП, процессор приостанавливает выполнение программы, отключается от шин, предоставляя их устройству ПДП, и посылает сигнал разрешения ПДП (РПДП).
Сигнал РПДП выполняет следующие функции:
● открывает буфер для передачи содержимого буферного регистра на ШД;
● открывает буферы для передачи содержимого счетчика адреса на 16–разрядную шину адреса ША;
● запускает двухразрядный счетчик подачей сигнала на вход «Сброс» через инвертор (5);
● открывает элемент И (4) для поступления тактовых импульсов на вход «Счет» счетчика.
При втором тактовом импульсе ТИ на выходе счетчика появляются сигналы
Q0 = 0. При комбинации
Q0 =10 элемент 8 закрыт, элементы 7 и 9 — открыты. Сигнал «Запись в память» ЗпП, проходя через элемент И (9), инициирует запись в память байта данных из буферного регистра по адресу, выставленному на ША счетчиком адреса.
Третий ТИ переводит двухразрядный счетчик в состояние Q1
Q0 = 11, благодаря чему открывается элемент И (8). На его выходе формируется сигнал «Счет», который:
● увеличивает на 1 содержимое счетчика адреса;
● уменьшает на 1 содержимое счетчика слов;
● производит сброс триггера запроса ТЗ, снимая сигнал запроса ПДП.
В результате этих операций процессор возобновляет работу, а счетчики подготовлены к передаче следующего слова (байта данных). Процессор продолжает работать до тех пор, пока не будет загружен буферный регистр новым словом и не будет послан новый запрос на ПДП. Далее процесс передачи слов по каналу ПДП повторяется. После того, как содержимое счетчика слов станет равным нулю (000000002), включенный на его выходе элемент ИЛИ–НЕ (10) установит флаг в единичное состояние, свидетельствующее об окончании передачи блока данных.
Внешние запоминающие устройства
Загрузка процессора
Прямой доступ к памяти
Интерфейс
Механизм загрузки
Существует три принципиально разных типа загрузки компакт-дисков: в контейнеры накопителя, в выдвижные лотки и механизмы автозагрузки.
Выдвижные лотки
В большинстве простых накопителей на компакт-дисках для установки диска используются выдвижные лотки. Для того чтобы заменить диск, необходимо выдвинуть лоток из накопителя, вынуть диск, положить его в прозрачную пластмассовую коробочку, вынуть новый диск из другой такой же коробочки, положить в лоток и задвинуть его обратно.
Контейнеры
Механизм автозагрузки
В некоторых моделях накопителей используется механизм автозагрузки, т.е. вы помещаете компакт-диск в щель на передней панели, а механизм автозагрузки самостоятельно «засасывает» его внутрь. Однако этот механизм не позволяет использовать диски диаметра 80 мм, а также прочие диски с модифицированными физическими форматами или формами.
Другие особенности накопителей на компакт-дисках
Безусловно, достоинства устройств в первую очередь определяются их техническими характеристиками, но существуют и другие немаловажные факторы.
Помимо качества конструкции и надежности, при выборе накопителя необходимо учитывать такие его свойства:
Автоматическая очистка линз
Если линзы лазерного устройства загрязнены, считывание данных замедляется, поскольку очень много времени уходит на повторные операции поиска и чтения (в худшем случае данные могут вообще не считываться). В подобной ситуации следует использовать специальные чистящие диски. Некоторые современные высококачественные модели накопителей имеют встроенное устройство очистки линз.
Записывающие накопители на компакт-дисках
Накопители CD-R
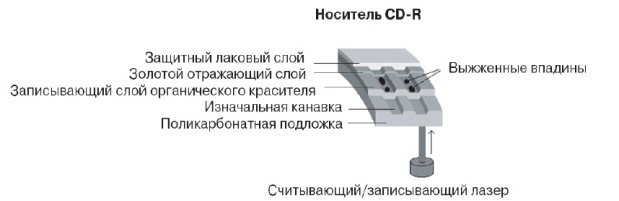
Запись CD-R начинается еще до того, как вы вставите диск в накопитель. Процесс изготовления носителей CD-R и стандартных компакт-дисков практически одинаков. В том и в другом случае выполняется прессование расплавленной поликарбонатной массы с использованием формообразующей матрицы. Но вместо штамповки впадин и площадок матрица формует на диске спиральную бороздку (которая называется изначальной бороздкой (pre)groove )). Если смотреть со стороны считывающего (и записывающего) лазера, расположенного под диском, эта канавка представляет собой спиральный выступ, а не углубление.
Процесс изготовления CD-R завершается нанесением с помощью метода центрифугирования равномерного слоя органического красителя. Затем создается золотой отражающий слой. После этого поверхность диска покрывается акриловым лаком, затвердевающим в ультрафиолетовых лучах, который используется для защиты ранее созданных золотого и окрашенного слоев диска. Исследования показали, что алюминий, используемый с органическим красителем, подвержен сильному окислению. Поэтому в дисках CD-R используется золотое покрытие, обладающее высокой коррозионной стойкостью и имеющее максимально возможную отражательную способность. На поверхность диска, покрытую слоем лака, методом трафаретной печати наносится слой краски, используемый для идентификации и дополнительной защиты диска. Лазерный луч, применяемый при чтении и записи диска, вначале проходит через прозрачный поликарбонатный слой, слой органического красителя и, отразившись от золотого слоя, снова проходит через слой красителя и поликарбонатной массы, после чего улавливается сенсором оптического датчика накопителя.
Отражающий слой и слой органического красителя имеют те же оптические свойства, что и неразмеченный компакт-диск. Другими словами, дорожка незаписанного (чистого) диска CD-R воспринимается считывающим устройством компакт-дисков как одна длинная площадка. Лазерный луч дисковода CD-R имеет одну и ту же длину волны (780 нм), но мощность лазера, используемого для выполнения записи, в частности для нагрева окрашенного слоя, в 10 раз выше. Лазер, работающий в импульсном режиме, нагревает слой органического красителя до температуры 482-572 °F (250-300 °С). При этой температуре слой красителя буквально выгорает и становится непрозрачным. В результате лазерный луч не доходит до золотого слоя и не отражается обратно, чем достигается тот же эффект, что и при погашении отраженного лазерного сигнала, происходящем при чтении штампованных компакт-дисков.
Во время чтения диска накопитель считывает несуществующие впадины, в качестве которых выступают участки с низкой отражательной способностью. Эти участки появляются при нагревании органического красителя, поэтому часто процесс записи диска называют выжиганием. Выжженные участки красителя изменяют свои оптические свойства и становятся не отражающими. Изменение этих свойств возможно лишь один раз, поэтому CD-R называются носителями с однократной записью.



