Ввод-вывод
В информатике, ввод/вывод (в англ. языке часто используется сокращение I/O) означает взаимодействие между обработчиком информации (например, компьютер) и внешним миром, который может представлять как человек, так и любая другая система обработки информации. Ввод — сигнал или данные, полученные системой, а вывод — сигнал или данные, посланные ею (или из нее). Термин также может использоваться как обозначение (или дополнение к обозначению) определенного действия: «выполнять ввод/вывод» означает выполнение операций ввода или вывода. Устройства ввода-вывода используются человеком (или другой системой) для взаимодействия с компьютером. Например, клавиатуры и мыши — специально разработанные компьютерные устройства ввода, а мониторы и принтеры — компьютерные устройства вывода. Устройства для взаимодействия между компьютерами, как модемы и сетевые карты, обычно служат устройствами ввода и вывода одновременно.
Стоит отметить, что назначение устройства в качестве устройства ввода или вывода зависит от перспективы. Мыши и клавиатуры принимают физическое взаимодействие, осуществляемое человеком-пользователем (ктстати, относительно него это будут действия по выводу информации), и превращает его в сигналы, понятные компьютеру. Вывод информации из этих устройств является вводом ее в компьютер. Аналогично, принтеры и мониторы получают на входе сигналы, которые выводит компьютер. Затем они преобразуют эти сигналы в такой вид, который человек сможет увидеть или прочитать. (Для людей-пользователей процесс чтения или просмотра подобных вариантов представления информации является вводом или получением информации).
В компьютерной архитектуре объединение процессора и основной памяти (то есть памяти, из которой процессор может читать и записывать в нее напрямую с помощью особых инструкций) составляет «мозг» компьютера, и с этой точки зрения, любой обмен информацией с этим объединением, например, с дисковым накопителем, подразумевает ввод-вывод. Процессор и его сопутсвующие электроные цепи реализуют ввод-вывод с распределением памяти, используемый в низкоуровневом программировании при реализации драйверов устройств.
Высокоуровневая операционная система и программное обеспечение используют другие, более абстрактные концепции и примитивы ввода-вывода. Например, большинство операционных систем реализуют прикладные программы через концепцию файлов. Языки программирования Си и C++, а также операционные системы семейства Unix, традиционно абстрагируют файлы и устройства в виде потоков данных, из которых можно читать и в которые можно записывать, или и то и другое вместе. Стандартная библиотека языка Си реализует функции для работы с потоками для ввода и вывода данных.
Альтернативой специальным простейшим функциям служит монада ввода-вывода, которая позволяет программам просто описывать ввод-вывод, а действия выносятся за рамки программы. Это весьма примечательно, так как функции ввода-вывода имеют побочные эффекты в любом языке программирования, но сейчас получило распространение чисто функциональное программирование.
Интерфейс ввода-вывода требует управления процессором каждого устройства. Интерфейс должен иметь соответствующую логику для интерпретации адреса устройства, генерируемого процессором.
Установление контакта должно быть реализовано интерфейсом при помощи соответствующих команд типа (ЗАНЯТО, ГОТОВ, ЖДУ), чтобы процессор мог взаимодействовать с устройством ввода-вывода через интерфейс.
Если существует необходимость передачи различающихся форматов данных, то интерфейс должен уметь конвертировать последовательные (упорядоченные) данные в параллельную форму и наоборот.
Должна быть возможность для генерации прерываний и соответствующих типов чисел для дальнейшей обработки процессором (при необходимости).
Компьютер, использующий ввод-вывод с распределением памяти, обращается к аппаратному обеспечению при помощи чтения и записи в определенные ячейки памяти, используя те же самые инструкции языка ассемблера, которые компьютер обычно использует при обращении к памяти.
Содержание
Режимы адресации
Существует несколько способов, которыми даные могут быть прочитаны или помещены в память. Каждый метод представляет из себя режим адресации и имеет собственные преимущества и ограничения.
Режимы адресации делятся на множество типов, как например, прямая адресация, косвенная (непрямая) адресация, непосредственная адресация, индексная адресация, базовая адресация, базово-индексная адресация, предполагаемая адресация и т.д.
Прямая адресация
В этом типе адрес данных сам является частью инструкции. Когда процессор декодирует инструкцию, он получает адрес ячейки памяти, откуда может быть считана (куда может быть записана) требуемая информация.
В данном случае операнд Addr указывает на область памяти, содержащее данные и копирует их в указанный регистр Reg.
Косвенная адресация
В этом случае адрес может храниться в регистре. Инструкции будут обращаться к регистру, содержащему адрес. То есть, для получения данных, инструкция должна декодировать данные соответствующего регистра. Содержимое регистра будет обработано как адрес, используя который, будет считана/записана информация из/в соответствующую область памяти.
Ввод-вывод с распределением (вводимой информации) по портам (памяти)
Ввод-вывод с распределением (вводимой информации) по портам (памяти) обычно требует применения инструкций, специально разработанных для выполнения операций ввода-вывода.
Ввод/вывод
С информатике, ввод/вывод (в англ. языке часто используется сокращение I/O — input/output) означает взаимодействие между обработчиком информации (например, компьютер) и внешним миром, который может представлять как человек, так и любая другая система обработки информации. Ввод — сигнал или данные, полученные системой, а вывод — сигнал или данные, посланные ею (или из нее). Термин также может использоваться как обозначение (или дополнение к обозначению) определенного действия: «выполнять ввод/вывод» означает выполнение операций ввода или вывода. Устройства ввода-вывода используются человеком (или другой системой) для взаимодействия с компьютером. Например, клавиатуры и мыши — специально разработанные компьютерные устройства ввода, а мониторы и принтеры — компьютерные устройства вывода. Устройства для взаимодействия между компьютерами, как модемы и сетевые карты, обычно служат устройствами ввода и вывода одновременно.
Стоит отметить, что назначение устройства в качестве устройства ввода или вывода зависит от перспективы. Мыши и клавиатуры принимают физическое взаимодействие, осуществляемое человеком-пользователем (кстати, относительно него это будут действия по выводу информации), и превращает его в сигналы, понятные компьютеру. Вывод информации из этих устройств является вводом ее в компьютер. Аналогично, принтеры и мониторы получают на входе сигналы, которые выводит компьютер. Затем они преобразуют эти сигналы в такой вид, который человек сможет увидеть или прочитать. (Для людей-пользователей процесс чтения или просмотра подобных вариантов представления информации является вводом или получением информации).
В компьютерной архитектуре объединение процессора и основной памяти (то есть памяти, из которой процессор может читать и записывать в нее напрямую с помощью особых инструкций) составляет «мозг» компьютера, и с этой точки зрения, любой обмен информацией с этим объединением, например, с дисковым накопителем, подразумевает ввод-вывод. Процессор и его сопутствующие электронные цепи реализуют ввод-вывод с распределением памяти, используемый в низкоуровневом программировании при реализации драйверов устройств.
Высокоуровневая операционная система и программное обеспечение используют другие, более абстрактные концепции и примитивы ввода-вывода. Например, большинство операционных систем реализуют прикладные программы через концепцию файлов. Языки программирования Си и C++, а также операционные системы семейства Unix, традиционно абстрагируют файлы и устройства в виде потоков данных, из которых можно читать и в которые можно записывать, или и то и другое вместе. Стандартная библиотека языка Си реализует функции для работы с потоками для ввода и вывода данных.
Альтернативой специальным простейшим функциям служит монада ввода-вывода, которая позволяет программам просто описывать ввод-вывод, а действия выносятся за рамки программы. Это весьма примечательно, так как функции ввода-вывода имеют побочные эффекты в любом языке программирования, но сейчас получило распространение чисто функциональное программирование.
Содержание
Интерфейс ввода-вывода
Интерфейс ввода-вывода требует управления процессором каждого устройства. Интерфейс должен иметь соответствующую логику для интерпретации адреса устройства, генерируемого процессором.
Установление контакта должно быть реализовано интерфейсом при помощи соответствующих команд типа (ЗАНЯТ, ГОТОВ, ЖДУ), чтобы процессор мог взаимодействовать с устройством ввода-вывода через интерфейс.
Если существует необходимость передачи различающихся форматов данных, то интерфейс должен уметь конвертировать последовательные (упорядоченные) данные в параллельную форму и наоборот.
Должна быть возможность для генерации прерываний и соответствующих типов чисел для дальнейшей обработки процессором (при необходимости).
Компьютер, использующий ввод-вывод с распределением памяти, обращается к аппаратному обеспечению при помощи чтения и записи в определенные ячейки памяти, используя те же самые инструкции языка ассемблера, которые компьютер обычно использует при обращении к памяти.
Режимы адресации
Существует несколько способов, которыми данные могут быть прочитаны или помещены в память. Каждый метод представляет собой режим адресации и имеет собственные преимущества и ограничения.
Режимы адресации делятся на множество типов, как например, прямая адресация, косвенная (непрямая) адресация, непосредственная адресация, индексная адресация, базовая адресация, базово-индексная адресация, предполагаемая адресация и т. д.
Прямая адресация
В этом типе адрес данных сам является частью инструкции. Когда процессор декодирует инструкцию, он получает адрес ячейки памяти, откуда может быть считана (куда может быть записана) требуемая информация.
В данном случае операнд Addr указывает на область памяти, содержащее данные и копирует их в указанный регистр Reg.
Косвенная адресация
В этом случае адрес может храниться в регистре. Инструкции будут обращаться к регистру, содержащему адрес. То есть, для получения данных, инструкция должна декодировать данные соответствующего регистра. Содержимое регистра будет обработано как адрес, используя который, будет считана/записана информация из/в соответствующую область памяти.
Ввод-вывод с распределением (вводимой информации) по портам (памяти)
Ввод-вывод с распределением (вводимой информации) по портам (памяти) обычно требует применения инструкций, специально разработанных для выполнения операций ввода-вывода.
Что такое ввод и вывод в информатике
Рис.4.26.Фрагмент программы, обеспечивающей непрерывную индикацию строки символов
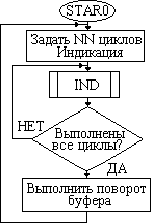
Рис.4.27.Блок-схема программы, обеспечивающий вывод в режиме «бегущей строки»

Рис.4.28.Структура буфера программы, обеспечивающий вывод в режиме бегущей строки
символы, семисегментные коды которых находятся в буфере. Числа около стрелок задают порядок пересылки кодов в процессе поворота. После поворота буфера вновь выполняется NN циклов индикации. Легко видеть, что при этом символы на дисплее будут последовательно смещаться влево и строка на нем «побежит». Скорость ее движения определяется числом циклов NN циклов индикации. Чем больше NN, тем медленнее бежит строка.
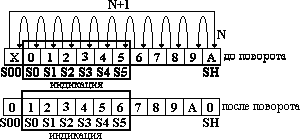
Для поворота буфера имеющего N ячеек можно воспользоваться фрагментом программы, представленным на рис.4.30.
; ЧИСЛО СИМВОЛОВ В СТРОКЕ
; ЗАНЕСТИ В ПАРУ HL НАЧ.
; АДРЕС ИСТОЧНИКА КОДА
; ЗАНЕСТИ В ПАРУ DE НАЧ.
; АДРЕС ПРИЕМНИКА КОДА
; ВЫПОЛНИТЬ N ЦИКЛОВ
; ИСТОЧНИКА В ПРИЕМНИК
; ИСТОЧНИКА И ПРИЕМНИКА
; НЕТ, ПОВТОРИТЬ, ИНАЧЕ
Рис.4.30.Фрагмент программы, обеспечиваюший поворот буфера
Вывод на семисегментный дисплей результатов расчета или кодов, набранных на клавиатуре, обычно сопряжен с переводом двоичных кодов шестнадцатеричных цифр в семисегментные. Такой перевод выполняется с помощью подпрограммы табличного преобразования. Существует несколько видов такого преобразования. Здесь целесообразно применить простейший вид, который использует исходный двоичный код в качестве указателя адреса своего семисегментного эквивалента в таблице семисегментных кодов.
Преобразование иллюстрирует подпрограмма BIS7 (рис.4.31), которая преобразует в семисегментный код младшую тетраду байта, находящегося в аккумуляторе.
; МАСКА МЛАДШЕЙ ТЕТРАДЫ
; ВЫДЕЛИТЬ МЛ. ТЕТРАДУ
; ОЧИСТИТЬ РЕГИСТР H
; ЗАГРУЗИТЬ МЛ. ТЕТРАДУ ВХ
; ЗАГРУЗИТЬ НАЧ. АДР.ТАБЛИЦЫ
; ВЫЧИСЛИТЬ АДРЕС ВЫХ. КОДА
; ЗАГРУЗИТЬ ВЫХ. КОД В РЕГ. А
; ВОЗВРАТИТЬСЯ В ОСНОВНУЮ
Рис.4.31. Текст подпрограммы BIS7
Начальный (базовый) адрес таблицы TAB7 складывается в подпрограмме с исходным кодом 0 F. При этом в регистровой паре HL получается адрес соответствующего семисегментного кода. Этот код извлекается из таблицы TAB7 командой MOV A, M и помещается в аккумулятор.
Ввод информации с кнопок и клавиатуры, подключенных к микро-ЭВМ обычно сопряжен с решением следующих специфических проблем:
защитой от дребезга контактов кнопок или клавиш;
идентификацией нажатой клавиши;
обеспечением нужного порядка срабатывания клавиш (при нажатии или при отпускании).
Защита от дребезга может быть обеспечена либо на аппаратном, либо на программном уровне.
Для идентификации клавиш обычно требуется комбинация определенных аппаратных и программных средств.
Нужный порядок срабатывания обычно обеспечивается соответствующим построением программы поддержки работы клавиатуры.
Проблема идентификации нажатой клавиши обычно решается в микро-ЭВМ в два этапа. На первом этапе обеспечивается генерация клавиатурой при нажатии каждой из клавиш уникального двоичного вода. Этот этап обеспечивается либо только аппаратными средствами, либо комбинацией аппаратных и программных средств. Второй этап всегда обеспечивается программными средствами. На этом этапе код нажатой клавиши вводится в микро-ЭВМ и сравнивается с заранее занесенной в память таблицей допустимых кодов. Результатом такого сравнения и является идентификация, опознание нажатой клавиши.
При малом количестве клавиш первый этап идентификации решается чисто аппаратно. Для приема сигнала с каждой из клавиш здесь выделяют отдельные разряды, биты в порте прямого ввода. Пример такого решения иллюстрирует схема клавиатуры, представленная на рис.4.32. Комбинация нажатых клавиш S0 S7 задает здесь уникальный код нажатой клавиши KNK1, который далее вводится в микро-ЭВМ через порт прямого ввода PIKNK1. Если количество клавиш больше числа разрядов порта ввода, можно включить между клавиатурой и портом шифратор с соответствующим количеством входов. При использовании шифратора, восьмиразрядный порт ввода может вводить информацию максимум от 255 клавиш.
Второй этап идентификации нажатой клавиши обеспечивается подпрограммой IDEN2, которая:
вводит в микро-ЭВМ код нажатой клавиши KNK1;
проверяет, содержится ли этот код в таблице допустимых кодов;
устанавливает признак недопустимого ввода Z = 1, если эта проверка не успешна. Некорректный ввод возможен, например, при одновременном нажатии нескольких клавиш;
Устанавливает признак управляющей клавиши С = 1, если нажата управляющая клавиша;
преобразует код нажатой клавиши KNK1 в другой KNK2, более удобный для последующего использования.

Рис.4.32.Подключение клавиатуры к микро-ЭВМ
Для цифровых клавиш, коды KNK2 должны соответствовать их маркировке. Для управляющих клавиш удобно использовать в качестве кодов KNK2 последовательность четных шестнадцатеричных чисел, начинающуюся с 00Н. Код KNK2 получается в подпрограмме из промежуточного кода CKNK2. Младшая тетрада кода CKNK2 есть код KNK2 нажатой клавиши. Старшая тетрада равна 0H для цифровых и 8H для управляющих клавиш. Такая структура кода CKNK2 позволяет одновременно использовать его как для формирования KNK2, так и признака управляющей клавиши.
В случае, если на рис.4.32 клавиши S0 S3 цифровые, а S4 S7 управляющие, подпрограмма IDEN2 может иметь вид, представленный на рис.4.33.
Основу подпрограммы составляет цикл, в котором последовательно устанавливаются адреса всех восьми строк таблиц ТАВ1 (KNK1) и ТАВ2 (CKNK2) и идет сравнение кода из таблицы ТАВ1 с кодом нажатой клавиши. Если введенного кода нет в таблице ТАВ1, то есть имел место некорректный ввод, происходит выход из подпрограммы с установленным некорректного ввода Z=1. Этот признак устанавливается командой DCR B при завершении цикла. Если же введенный код опознан в одном из кодов ТАВ1, следует выход из цикла к метке М1. Регистровая пара DE содержит в этом случае адрес кода CKNK2 в таблице ТАВ2. Далее этот код извлекается из ТАВ2 командой LDAX D.
; ДЛИНА ТАБЛИЦЫ КОДОВ
; МАСКА МЛАДШЕЙ ТЕТРАДЫ
; ЗАГРУЗИТЬ ДЛИНУ ТАБЛИЦЫ
; ЗАГРУЗ. НАЧ. АДРЕС ТАБЛИЦЫ
; КОДОВ KNK1 В ПАРУ HL
; ЗАГРУЗ. НАЧ. АДРЕС ТАБЛИЦЫ
; КОДОВ СKNK2 В ПАРУ DE
; KNK1 СОВПАДАЕТ СО СТРОКОЙ
; ДА, ПЕРЕЙТИ К М1, ИНАЧЕ
; КОДОВ В ТАВ1 И ТАВ2
; ПРОСМОТРЕНА ВСЯ ТАВ1?
; НЕТ, ПОВТОРИТЬ, ИНАЧЕ
; ВЫБРАТЬ CKNK2 ИЗ ТАВ2
; СОХРАНИТЬ В РЕГИСТРЕ В
; ВЫБРАТЬ CKNK2 ИЗ ТАВ2
; ПЕРЕНЕСТИ СТАРШИЙ БИТ CKNK2
; В БИТ С РЕГИСТРА F
; ВОССТАНОВИТЬ KNK2 В
; ВОЗВРАТ С Z=0 И С=1 / 0
0FEH, 0FDH, 0FBH, 0F7H
0EFH, 0DFH, 0BFH, 7FH
Рис.4.33.Текст подпрограммы IDEN2
В микро-ЭВМ часто используют так называемую матричную клавиатуру. Такая клавиатура представляет собой прямоугольную проводную матрицу, в узлах которой включены контакты клавиш. Принципиальная схема одного из реальных вариантов матричной клавиатуры приведена на рис.4.34
Работу клавиатуры поддерживают порт прямого ввода POKWR и порт прямого ввода PIKAR. Легко видеть, что к каждой из четырех активных линий порта ввода здесь подключено по 6 контактов клавиатуры. Понятно, что эти контакты не могут быть опрошены микро-ЭВМ одновременно. Поэтому в процессе идентификации нажатой клавиши используется процедура последовательного опроса вертикальных рядов клавиш. Эту процедуру, осуществляемую специальной подпрограммой, часто называют сканированием клавиатуры.
Порт POKWR предназначен для выбора ряда клавиш, опрашиваемых в данный момент времени. В этот порт выводится код выбора ряда KWR. Единичный бит этого кода обеспечивает активацию, выбор одного из вертикальных рядов клавиш, задавая на вертикальном проводнике матрицы уровень логического нуля. В невыбранных рядах вертикальные проводники имеют уровень логической единицы. Поэтому замыкание контактов клавиатуры в невыбранных рядах не меняет единичного состояния входов D6, D5, D4 и D2 порта PIKAR. Замыкание же контактов в выбранном ряду приводит к появлению уровня логического нуля на одном или нескольких входах этого порта. Таким образом, формируется код активного ряда KAR, который может ввести в микро-ЭВМ через порт PIKAR.
Последовательный выбор рядов клавиш меняющимся в цикле кодом KWR и ввод кода KAR соответствующего ряда осуществляет специальный блок подпрограммы идентификации IDEN. Байтовые коды KWR и KAR составляют вместе уникальный шестнадцатиразрядный код нажатой клавиши, который используется на втором этапе идентификации. Так, например, если этот код равен 0170H, то нажата клавиша «пробел».
Для рассматриваемого варианта клавиатуры коды KWR и KAR можно объединить в байтовый код нажатой клавиши KNK, используя соотношение
KNK = KWR / 2 + KAR х 2.
Это соотношение может быть реализовано фрагментом программы, приведенным на рис.4.35. Здесь предполагается, что код KWR содержится в регистре С.
Часто нужно определить, нажата ли какая-либо (неважно какая) из клавиш клавиатуры. В этом случае следует выбрать все шесть рядов клавиш одновременно, выдав в порт POKWR код KWR = 3FH. Порт PIKAR будет при этом принимать код KAR = 74H только в том случае, если не нажата ни одна из клавиш.
Процессы сканирования матричной клавиатуры и динамического управления семисегментным дисплеем имеют много общего. Поэтому их часто интегрируют, объединяют на аппаратном (клавиатура и дисплей обычно имеют общий порт выбора ряда POKWR) и (или) на программном уровне.
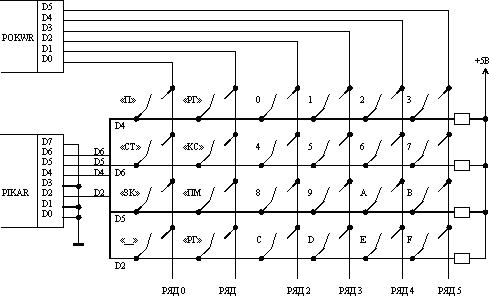
Рис.4.34.Принципиальная схема матричной клавиатуры
Ввод-Вывод
Одной из важнейших функций ОС является управление устройствами ввода-вывода компьютера. Операционная система дает этим устройствам команды, перехватывает прерывания и обрабатывает
ошибки. Она должна обеспечить простой и удобный интерфейс между устройствами и остальной частью системы. Интерфейс должен быть одинаковым для всех устройств с целью достижения независимости от применяемой аппаратуры. Программное обеспечение ввода-вывода составляет существенную часть операционной системы.
Другой тип устройств ввода-вывода — символьные устройства. Символьное устройство принимает или предоставляет поток неструктурированных символов. Оно не является адресуемым и не выполняет операцию поиска. Принтеры, сетевые адаптеры, мыши и большинство других устройств, не похожих на диски, можно считать символьными устройствами.
Такая классификация является условной. Некоторые устройства не попадают ни в одну из категорий. Например, часы не являются блок-адресуемыми. Они не формируют и не принимают символьных потоков. Вся их работа заключается в инициировании прерываний в строго определенные моменты времени. И все же модель блочных и символьных устройств является настолько общей, что может служить основой для достижения независимости программного обеспечения ОС от устройств ввода-вывода. Например, файловая система имеет дело с абстрактными блочными устройствами, а зависимую от устройств часть оставляет программному обеспечению низкого уровня.
Часто интерфейс между устройством и контроллером является интерфейсом низкого уровня. С диска в контроллер поступает последовательный поток битов, начинающийся с заголовка сектора
(преамбулы), за которым следует 4096 бит в секторе, и контрольная сумма, называемая кодом исправления ошибок ЕСС ( Error Correcting Code ). Заголовок сектора записывается на диск во время форматирования. Он содержит номера цилиндра и сектора, размер сектора, коды синхронизации и другую служебную информацию.
Работа контроллера заключается в конвертировании последовательного потока битов в блок байтов и коррекцию ошибок. Обычно байтовый блок накапливается в буфере контроллера. Затем проверя-
ется контрольная сумма блока, и если она совпадает с указанной в заголовке сектора, то блок считается принятым без ошибок. После этого блок копируется в оперативную память.
Контроллер монитора (видеоадаптер) работает на таком же низком уровне. Он считывает из памяти байты, содержащие символы, которые следует отобразить, и формирует сигналы, используемые для модуляции луча электронной трубки, заставляющие ее выводить изображение на экран. Видеоадаптер формирует сигналы, управляющие горизонтальным и вертикальным возвратом луча. Операционная система только инициализирует контроллер, задавая небольшое количество параметров, таких, как количество пикселов в строке и число строк на экране, а всю работу по управлению передвижениями луча по экрану выполняет контроллер.
Ключевая концепция разработки ПО ввода-вывода формулируется как независимость от устройств. Эта концепция означает возможность написания программ, способных получать доступ к любому устройству ввода-вывода без предварительного указания конкретного устройства. Например, программа, читающая данные из входного файла, должна одинаково успешно работать с файлом на дискете, жестком диске или компакт-диске. При этом не должны требоваться какие-либо изменения в программе. В качестве выходного устройства также может быть указан экран, файл на любом диске или принтер. Все проблемы, связанные с отличиями этих устройств, снимает операционная система.
Тесно связан с концепцией независимости от устройств принцип единообразного именования. Имя файла или устройства должно быть просто текстовой строкой или целым числом. Оно никак не
должно зависеть от физического устройства.
Другим важным аспектом ПО ввода-вывода является обработка ошибок. Ошибки должны обрабатываться как можно ближе к аппаратуре. Если контроллер обнаружил ошибку чтения, он должен по возможности исправить эту ошибку сам. Если он не может это сделать, то ошибку должен обработать драйвер устройства. Многие ошибки бывают временными, например ошибки чтения, вызванные пылинками на читающих головках. Такие ошибки исчезают при повторном чтении блока. Только если нижний уровень не может сам справиться с проблемой, о ней следует информировать верхний уровень. Во многих случаях восстановление может осуществляться на
нижнем уровне, так, что верхние уровни даже не будут знать о наличии ошибок.
Одним из ключевых вопросов является способ переноса данных — синхронный (блокирующий) или асинхронный (управляемый прерываниями). Большинство операций ввода-вывода на физическом
уровне являются асинхронными — ЦП запускает перенос данных и переключается на другой процесс, пока не придет прерывание.
Еще одним аспектом ПО ввода-вывода является буферизация. Часто данные, поступающие с устройства, не могут быть сохранены там, куда они направлены. Например, когда пакет приходит по сети, ОС не знает, куда его поместить, пока не будет проанализировано его содержимое. Буферизация предполагает копирование данных в больших количествах, что часто является основным фактором снижения производительности операций ввода-вывода.
И последним понятием, которое связано с вводом-выводом, является понятие выделенных устройств и устройств коллективного использования. С некоторыми устройствами, такими как диски, может одновременно работать большое количество пользователей. При этом не должно возникать проблем при одновременном открытии на одном и том же диске нескольких файлов. Другие устройства, такие как накопители на магнитной ленте, предоставляются в монопольное
пользование. Пока не завершит свою работу один пользователь накопитель не может быть предоставлен другому пользователю. ОС должна уметь управлять как устройствами общего доступа, так и выделенными устройствами.
Существуют три различных способа осуществления операций ввода-вывода. Простейший вид ввода-вывода состоит в том, что всю работу выполняет центральный процессор. Этот метод называется
программным вводом-выводом. ЦП вводит или выводит каждый байт или слово, находясь в цикле ожидания готовности устройства ввода-вывода. Второй способ представляет собой управляемый прерываниями ввод-вывод, при котором ЦП начинает передачу ввода-вывода для символа или слова, после чего переключается на другой процесс, пока прерывание от устройства не сообщит ему об окончании операции ввода-вывода. Третий способ заключается в использовании прямого доступа к памяти ( DMA — Direct Memory Access ), при котором отдельная микросхема управляет переносом целого блока данных и инициирует прерывание только после окончания операции переноса блока.



