Что такое представления VIEWS в базах данных? И зачем они нужны?
Многие начинающие администраторы и программисты баз данных, да и просто системные администраторы, которые обслуживают некую базу данных, не знают что такое представление или VIEWS, и зачем вообще они нужны. Сейчас мы попробуем разобраться, что же это такое.
Начнем с небольшой теории.
Что такое VIEWS?
VIEWS – представление, или, например, в PostgreSQL они называются «Видами» (т.е. Вид), русские админы часто называют их вьюхами, т.е. одно представление это вьюшка. Она представляет собой хранимый запрос к базе данных, также ее можно назвать виртуальная таблица, но в этой таблице данные не хранятся, а хранится только сам запрос. Но, тем не менее, к вьюшке можно обращаться как к обычной таблице и извлекать данные из нее.
Мы с Вами говорим о базах данных, в которых используется язык SQL, исходя из этого, можно сделать вывод, что VIEWS можно создать на данном языке. Это очень распространенный объект в базе данных, поэтому во всех СУБД есть возможность создавать представления в графическом интерфейсе путем нажатия кнопки «Создать представление» или «Создать новый вид», а также, конечно же, с использованием инструкции «CREATE VIEW».
Но перед тем как учиться создавать вьюшки, давайте поговорим о том, зачем они нужны и какие преимущества они нам дадут.
Зачем нужны представления?
Одним из главных достоинством представлений является то, что они сильно упрощают взаимодействие с данными в базе данных. Допустим, Вам необходимо каждый раз делать сложную по своей структуре выборку, а как Вы знаете, запрос на выборку может быть, ну просто очень сложный и этому нет предела. И если не было бы вьюшек, то Вам приходилось бы каждый раз запускать этот запрос, или даже его модифицировать, например, для вставки условий. А так как у нас есть такие объекты как представления, нам этого делать не придется. Мы просто на всего создадим одну вьюшку, и потом уже к ней будем обращаться с помощью уже простых запросов, которые также можно делать сложными, если это необходимо. Например, вьюшки также можно объединять с другими таблицами или другими представлениями.
К представлениям можно обращаться и из приложений, например, Вам нужно вывести какой-нибудь отчет, формирование которого требует каких-то расчетов, это легко можно реализовать путем написания необходимого запроса (в котором и будут рассчитываться данные, например из разных таблиц) и вставке этого запроса во вьюшку. А потом уже обращаться к этой вьюшке, например с помощью такого простого запроса как:
Как создать представление VIEWS?
Теперь давайте поговорим о том, как создавать эти самые вьюшки. Во-первых, сразу скажу, что для этого необходимы знания SQL (для построения сложных запросов). Во-вторых, Вы за ранее должны определиться, что Вам необходимо вывести в результате того или иного запроса. Рассматривать процесс создания представления путем нажатия кнопок мы не будем, так это достаточно просто. Мы рассмотрим создание VIEWS с использованием языка SQL (хотя и это тоже просто).
Например, в PostgreSQL запрос создания представления будет выглядеть так:
Здесь мы использовали простой запрос на выборку, Вы в свою очередь можете писать любой запрос, даже с объединением нескольких таблиц и условий к ним.
Полный синтаксис команды CREATE VIEW (в PostgreSQL) выглядит следующим образом:
После того, как Вы создали представление, Вы можете к нему обращаться. А данные, которые будет выводить вьюшка, будут изменяться в зависимости от изменений данных в исходных таблицах, так как данные во вьюшке формируются при обращении к этому представлению. Исходя из этого, можно сделать вывод, что данные, которые выводит вьюшка, будут всегда актуальные.
У меня все, надеюсь, теперь у Вас есть представление о том, что такое VIEWS, пока!
Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
Тема 14: VIEW в SQL на примере базы данных SQLite: CREATE, DROP, UPDATE
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. В этой записи мы с вами разберемся с представлениями и их использованием в реляционных базах данных. Вообще VIEW в SQL довольно полезная штука, которая позволяет упростить SQL запросы SELECT, а также скрыть логику базы данных от пользователей и программного кода, тем самым создав дополнительный уровень абстракции, который защищает наши базы данных от вредоносного вмешательства. Многие считают VIEW виртуальными таблицами, что не совсем правильно, так как представление — это запрос хранимый в базе данных и доступный по его имени (VIEW это такой же объект базы данных, как скажем, триггер или таблица). Делать выборку данных из VIEW во многих СУБД намного быстрее, например, MySQL сервер любит кэшировать результаты запросов, а VIEW, как вы поняли, есть ни что иное, как запрос.

VIEW в SQL на примере базы данных SQLite: CREATE, DROP, UPDATE.
В этой записи мы с вами будем разбираться с использованием VIEW в SQL и реляционных базах данных на пример библиотеки SQLite. Сначала мы поговорим о том, что собой представляют VIEW в базах данных и разберемся с тем, как мы можем использовать представления. Затем поговорим про особенности работы представлений в SQLite3 и разберем SQL синтаксис VIEW, реализованный в данной СУБД. И затем попробуем поработать с VIEW в базах данных под управлением SQLite.
Что такое VIEW в контексте языка SQL и баз данных?
Прежде чем ответить на вопрос зачем нужны VIEW в SQL и реляционных базах данных давайте ответим на вопрос: «что такое VIEW в языке запросов SQL?». В Википедии, на мой взгляд, формулировка определения VIEW в SQL написана неправильно. Так как представление не является виртуальной таблицей (как минимум, для создания виртуальных таблиц в SQLite предусмотрен отдельный синтаксис).
Документация MySQL говорит нам о том, что представление можно рассматривать, как виртуальную таблицу, но не утверждает, что VIEW – это VIRTUAL TABLE. В разделе VIEW документации Oracle упоминаний про виртуальную таблицу при беглом чтении я не встретил. Конечно, кто-то со мной может не согласиться, но я считаю, что VIEW – это не виртуальная таблица. Итак, мы разобрались с тем, чем не является VIEW в SQL и реляционных базах данных.
Теперь давайте дадим правильное определение термину VIEW в контексте языка SQL. VIEW – это хранимый запрос в базе данных. Возможно, представление называют виртуальной таблицей (virtual table) по той причине, что структура VIEW полностью повторяет структуру результирующей таблицы запроса SELECT, но опять же, это не повод называть VIEW виртуальной таблицей.
Сервер MySQL довольно быстро работает с представлениями за счет того, что MySQL очень любит кэшировать результаты запросов, в принципе, многие современные системы управления базами данных любят и хорошо кэшируют запросы, поэтому вы не всегда сможете заметить разницу работы между VIEW и таблицей базы данных, особенно, если ваши таблицы небольшие.
Вместо термина VIEW в различных источниках вы можете встретит термины представления или просмотры. Мне удобнее использовать термин представление. Давайте вернемся к определению термина представления в базах данных. Итак, представление – это хранимый в базе данных запрос, которому нужно дать имя. Когда мы создали представление, мы можем обращаться к нему, как к обычной таблице базы данных, используя то имя, которое мы написали после команды CREATE VIEW.
Единственная команда языка SQL, возвращающая в результате своей работы таблицу – это команда SELECT, с помощь которой мы не только делаем выборку данных, но и создаем VIEW в базе данных. Практически в любой СУБД для работы с представлениями доступны все команды манипуляции данными, но в библиотеки SQLite3 это утверждение не верно, об этом мы поговорим чуть ниже.
Напомним себе, что команды: UPDATE, SELECT, INSERT, DELETE, относятся к командам манипуляции данными. VIEW создается на основе запроса SELECT. Но, например, в базах данных MySQL, вы не сможете использовать команды UPDATE, INSERT, DELETE, если SQL запрос создающий VIEW содержит:
Поэтому рекомендую вам сперва ознакомиться с документацией той или иной СУБД, прежде чем начать создавать представления в базе данных. Например, документация MySQL так и говорит, что команды манипуляции данными (за исключением SELECT, который можно применять к любому представлению) можно применять к VIEW в том случае, когда строки VIEW совпадают со строками таблицы в базе данных (это несколько вольный и не совсем точный перевод).
Мы разобрались с тем, что VIEW – это именованный запрос SELECT, который хранится в базе данных. Каждый раз, когда мы обращаемся к VIEW, СУБД выполняет этот запрос SELECT, а следом за ним, она выполняет наш запрос. Думаю, ничего сложно в понимание того, что такое VIEW нет, давайте теперь разберемся для чего мы можем использовать VIEW.
Использование представлений в SQL и реляционных базах данных
Первое и очевидное применение VIEW в базах данных заключается в том, чтобы упростить запросы на выборку данных. Ведь нам же не хочется писать полотно SELECT, которое объединяет три-четыре таблицы каждый раз, а потом еще задавать какие-нибудь условия выборки данных клаузулой WHERE? Итак, первое, для чего мы можем использовать представление – это для упрощения запросов выборки данных.
Второй пункт можно назвать безопасность. Во-первых, при помощи VIEW можно скрыть бизнес-логику и архитектуру базы данных от прикладных приложений, сделав так, что программа будет обращаться не к таблицам базы данных, а к представлениям. Во-вторых, так вы избавитесь от некоторых видов SQL-инъекций, плюсом к этому, особо талантливые программисты лишаться «чудесной возможности» конкатенировать SQL запросы (как только вы увидите, что программист конкатенирует SQL запрос, можете зарядить ему в щи с вертушки и прокричать: я угорел по базам данных, а ты не знаешь даже таких простых вещей), тем самым вы еще уменьшите вариативность атак на вашу базу данных.
Третий вариант применения VIEW сводится к обновлениям. Вы редко можете встретить базу данных без прикладного приложения. Мир не стоит на месте, всё летит, всё развивается, компании растут и объединяются, у клиентов появляются всё новые потребности и рано или поздно старые приложения становятся неудобными и возникает потребность в их модификации. Мы уже говорили, что VIEW позволяют скрывать бизнес-логику базы данных, но не всегда, создавая базу данных, вы создаете представления. Поэтому если у вас возникла потребность в обновлении программного кода, работающего с базой данных, вы можете создать новую структуру базы данных в виде представлений, с которой будет работать новый программный код, тем самым вы разделите схему хранения данных и схему представления данных. Если потребности в разделении схем нет, то в дальнейшем вы можете отказаться от использования VIEW и вернуться к таблицам, после того, как код приложения будет обновлен.
Пожалуй, это три самых важных аспекта работы с базами данных, для которых можно и даже нужно использовать представления.
Особенности работы с VIEW в базах данных SQLite
Теперь поговорим про особенности VIEW в базах данных SQLite, мы уже говорили о том, что представления в SQLite нельзя редактировать, их можно только создавать, удалять и делать выборку из VIEW, в то время, как другие СУБД позволяют выполнять другие команды манипуляции данными представлений.
Но это не совсем так, все дело в том, что SQLite не дает возможность редактировать представления при помощи обычных SQL запросов. Но в базах данных есть триггеры, которые успешно эмитируют работу команд UPDATE, INSERT и DELETE. Соответственно, если мы можем:
То ничто нам не помешает выполнить те же самые операции с VIEW в SQLite, правда они будут немного сложнее из-за того, что нам придется использовать триггеры.
SQL синтаксис VIEW в базах данных SQLite
Давайте разберемся с синтаксисом SQL, реализованным в SQLite, который позволяет нам создавать и удалять представления из базы данных. Начнем мы с синтаксиса создания представлений в SQLite, он показан на рисунке ниже.
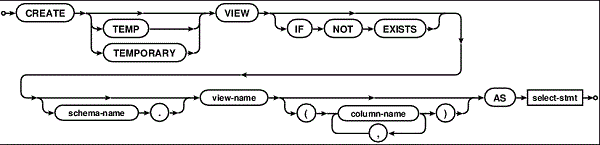
SQL синтаксис создания VIEW в базах данных SQLite
Отметим, что создание VIEW начинается с той же команды, что и создание таблицы в базе данных: с команды CREATE. Это обусловлено тем, что VIEW – это такой же объект базы данных, как и таблица. Далее мы указываем, что хотим создать представление при помощи ключевого слова VIEW. Представление может быть временным, поэтому после ключевого слова CREATE вы можете использовать слово TEMP или TEMPORARY. Если вы не уверены, что создаете представление с уникальным именем и не хотите возникновения ошибок при создании VIEW в базе данных, то можете использовать ключевую фразу IF NOT EXIST (кстати, оператор EXISTS может быть использован для создания подзапроса SELECT). Далее вам необходимо указать имя представления, которое должно быть уникальным, в качестве имени можно использовать квалификатор, в том случае, если вы работаете с несколькими базами данных и хотите быть уверенным в том, что создаете VIEW для нужной базы данных.
После имени представления идет ключевое слово AS и запрос SELECT, который как раз-таки и будет храниться в файле базы данных SQLite и к которому SQLite будет обращаться по тому имени, которое вы указали при создании VIEW.
Теперь рассмотрим SQL синтаксис удаления VIEW из базы данных под управлением SQLite3. Он показан на рисунке ниже.
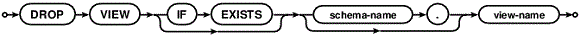
SQL синтаксис удаления VIEW из базы данных под управлением SQLite3
Хоть обычное представление, хоть временное, удаляются из базы данных под управлением SQLite одинаково: ключевое слово DROP, за которым следует VIEW, говорит SQLite о том, что вы хотите удалить из базы данных не просто объект, а представление. Далее следует конструкция IF EXISTS, которая осуществляет проверку наличия представления в базе данных, чтобы SQLite не возвращала ошибки в том случае, если представление, которое вы хотите удалить, уже удалено. После чего идет имя представления или квалификатор.
Отметим, что для представлений в SQLite команда ALTER не реализована. Если вам нужно изменить структуру VIEW, то вам нужно удалить старое представление, а затем создать новой и с новой структурой.
Итак, мы разобрались с SQL синтаксисом VIEW в базах данных SQLite и можем начинать работать с представлениями.
Материализованные представления, как средство контроля целостности данных
Контроль целостности данных — одна из важнейших функций СУБД. Чем тщательнее этот контроль организован, тем проще реализовывать прикладную логику, ведь чем больше ограничений контролируется базой данных, тем меньше вариаций «а что, если» следует предусмотреть при реализации логики. В то же самое время контроль целостности оказывается достаточно удобно использовать и для проверки корректности работы прикладного слоя. Что-то вроде юнит-тестов. «Лишняя» проверка, порой может сослужить очень добрую службу.
Традиционный набор ограничений — ограничение первичного, внешнего ключей, уникальности при использовании нормализации позволяет удовлетворить подавляющее большинство случаев потребности контроля. Однако в случае, когда ограничение оказывается зависимым от значений в нескольких таблицах и строках, этих средств оказывается недостаточно. Такие ограничения приходится реализовывать триггерной логикой. И реализация далеко не всегда оказывается проста. Разработчику приходится держать в уме то, что модификация данных может проводиться в конкурентной среде, потому необходимо самостоятельно заботиться о блокировании ресурсов, при этом, еще и пытаясь избегать взаимных блокировок. Реализация ограничения строки может потребовать доступа к другим строкам этой же таблицы, что, в свою очередь является ограничением платформы — Oracle не позволяет обращаться к изменяемому в настоящее время(мутирующему) набору данных.
Но есть и другой путь. В некоторых случаях оказывается возможным использование ограничений, наложенных на материализованные представления, обновляемые по факту фиксации транзакций (fast refresh on commit). Такие ограничения будут работать как отложенные (deferred) и не будут позволять зафиксировать транзакцию, если вдруг целостность данных оказалась нарушенной. В рамках же модифицирующей транзакции ограничения могут нарушаться. С одной стороны это упрощает модификацию данных, с другой, мешает идентифицировать источник ошибки. В этой статье я хотел бы привести пару простых примеров реализации таких ограничений.
Постановка задачи
Реализацию подхода я хотел бы показать на вымышленном упрощенном примере. Оказалось достаточно сложно подобрать такой пример, чтобы он был достаточно прост для восприятия, но при этом, чтобы применение подхода было оправданным, не обессудьте если что вдруг получилось не так.
Пусть мы имеем необходимость учета товара в разрезе зоны размещения. Размещением в данном случае выступает магазин(S) или склад(W).
Зона — территория физическая или логическая каждого конкретного размещения. К примеру — торговый зал, или же даже полки торгового зала, материальная комната, холодильник, зона утерянного товара. Каждое размещение может иметь более одной зоны каждого типа, но одна зона каждого типа обязательно должна быть помечена как основная. Она будет использоваться по умолчанию, если зона операции явно не определена. Основная зона должна быть одна и только одна для каждого типа зоны. Это будет первый вид ограничения, который мы попытаемся реализовать.
Реализация
таблицы
Ограничение количества основных зон
Для реализации этого ограничения создадим материализованное представление, которое будет производить подсчет основных зон для каждого типа зоны размещения, и сверху на него наложим ограничение, контролирующее строгое равенство единице рассчитанного значения. Для запросов, на основе которых строятся материализованные представления определен целый ряд ограничений, который, к тому еще сильно ужесточается наложением требований к обновлению методом fast. В нашем случае мы имеем аггрегирующее материализованное представление, а потому должны создать materialized view log для таблицы zone, включающий rowid и новые значения, список полей которого должен включить все значения, которые могут повлиять на результат запроса
Так же мы обязаны включить в результат, возвращаемый запросом значение «count(*)»
Здесь следует отметить: для того чтобы оценить, может ли материализованное представление построенное по запросу использовать для обновления метод fast, существует процедура dbms_mivew.explain_mview. Крайне желательно использовать ее для контроля доступен ли для представления метод обновления fast. К примеру, если бы мы забыли указать в запросе count(*), материализованное представление с успехом бы создалось и корректно работало при выполнении операции вставки. Однако при модификации, удалении значение primary_count — не пересчитывалось бы, что нарушило бы логику нашего ограничения. Однако если мы используем explain_mview, оракл услужливо подскажет нам наш просчет.
Итак, материализованное представление создано, осталось только добавить ограничение
Прошу обратить внимание на то, что ограничение создается отложенным(deferred). Дело в том, что в процессе обновления представления ораклом, на каком-то промежуточном этапе, может оказаться что ограничение будет временно нарушено. Чтобы избежать таких ложных срабатываний, лучше устанавливать такие ограничения заведомо отложенными.
Проверим работу этого ограничения
Попытаемся создать зону с типом, не имеющем отметки «основной».
Попытаемся определить две основные зоны для размещения с одинаковым типом.
Ограничение состава зон размещения
Это ограничение от предыдущего отличается тем, что опирается на значения не одной таблицы, а двух. Т.е. одновременно необходимо удовлетворить требования метода обновления fast для представлений с соединениями и аггрегирующих представлений. Но это не возможно. Мы не можем одновременно вывести в результат и rowid присоединенной строки и count(*). По этой причине придется строить каскад материализованных представлений. В одном будет производится соединение наборов данных, в другом — аггрегация.
Для начала необходимо создать materialized veiw log для таблицы размещений. Для таблицы зон будет использован ранее созданный лог.
Следом создаем join mivew. К сожалению ANSI синтаксис здесь оракл не воспринимает, испльзуем old-style join.
Создаем materialized veiw log для join представления
Создаем аггрегирующеее материализованное представление
ну и сами ограничения
Проверим работу ограничений:
Размещение успешно создано в статусе «Черновик». Попробуем активировать его:
Нет. Нельзя активировать размещение, если для него не определены необходимые для его типа зоны
Заключение
Когда это использовать
В первую очередь тогда, когда связь на столько сложна, что высок риск что разработчик приложения сможет не все учесть, а рассогласование критично. Я впервые такой подход использовал, когда проектировал структуру, закольцованную на себя же внешними ключами через семь таблиц. Причем эти таблицы ведутся разными бизнес-подразделениями. Это ограничение стоит и по сей день. И по сей день пользователи находят лазейки, шлют скришноты когда это ограничение срабатывает, а воспроизвести, чтоб закрыть лазейку в прикладном модуле — не удается, требуется стечение обстоятельств от нескольких пользователей.
Очень удобно иметь такие ограничения на этапе тестирования, старта, стабилизации проектов, когда не достает доверия к корректности работы логики, а данные могут модифицироваться и мимо прикладного звена.
Когда это не использовать
Очевидно, что не стоит использовать такой подход в случаях, когда он дает заметную просадку по производительности.
В случае модификации, уточнения схемы данных, содержимое представлений может оказаться не достоверным и потребует полного обновления. Если время полного обновления материализованного представления может поставить под угрозу выполнение регламента технических работ, наверное, тоже не стоит использовать такой подход.
Получение сведений о представлении
Получить сведения об определении или свойствах представления в SQL Server можно с помощью SQL Server Management Studio или Transact-SQL. Возможность просмотреть определение представления может понадобиться, чтобы понять, как его данные извлекаются из исходных таблиц, или чтобы увидеть данные, определенные представлением.
Если имя объекта, на который ссылается представление, было изменено, необходимо изменить представление так, чтобы в его тексте использовалось новое имя. Следовательно, прежде чем переименовывать объект, следует отобразить зависимости объекта, чтобы определить, повлияет ли предполагаемое изменение на какие-либо представления.
В этом разделе
Перед началом работы
Получение сведений о представлении с помощью следующих средств:
Перед началом
безопасность
Permissions
Использование среды SQL Server Management Studio
Получение свойств представления с помощью обозревателя объектов
В обозревателе объектов нажмите на значок плюса рядом с базой данных, содержащей представление, свойства которого необходимо просмотреть, а затем нажмите значок плюса, чтобы развернуть папку Представления.
Щелкните правой кнопкой представление, свойства которого необходимо просмотреть, и выберите пункт Свойства.
В диалоговом окне Свойства представления отображаются следующие свойства:
База данных
Имя базы данных, содержащей это представление.
Server
Имя текущего экземпляра сервера.
Пользователь
Имя пользователя этого соединения.
Дата создания
Отображает дату создания представления.
имя;
Имя текущего представления.
Схема
Схема, которой принадлежит представление.
Системный объект
Указывает, является ли представление системным объектом. Возможные значения: True и False.
Значения NULL по стандарту ANSI
Указывает, был ли объект создан с параметром ANSI NULL.
Зашифрована
Указывает, зашифровано ли представление. Возможные значения: True и False.
Заключенный в кавычки идентификатор
Показывает, был ли объект создан с параметром «заключенный в кавычки идентификатор».
Привязка к схеме
Указывает, является ли представление привязанным к схеме. Возможные значения: True и False. Сведения о представлениях, привязанных к схеме, см. в подразделе SCHEMABINDING раздела CREATE VIEW (Transact-SQL).
Получение свойств представления с помощью конструктора представлений
Щелкните правой кнопкой мыши представление, свойства которого необходимо просмотреть, и выберите пункт Конструктор.
Правой кнопкой мыши щелкните пустое пространство в области диаграмм и выберите Свойства.
На панели Свойства отображаются следующие свойства.
(Имя)
Имя текущего представления.
Имя базы данных
Имя базы данных, содержащей это представление.
Описание
Краткое описание текущего представления.
Схема
Схема, которой принадлежит представление.
Имя сервера
Имя текущего экземпляра сервера.
Привязка к схеме
Предотвращает такие изменения пользователями базовых объектов, задействованных в представлении, в результате которых определение представления становится недействительным.
Детерминированное
Указывает, может ли тип данных для выбранного столбца быть точно определен
Различные значения
Указывает, что запрос будет отфильтровывать повторения в представлении. Этот параметр полезен при использовании только некоторых столбцов из таблицы, притом что эти столбцы могут содержать повторяющиеся значения, или если обработка соединения двух или более таблиц приводит к появлению повторяющихся строк в результирующем наборе. Выбор этого параметра эквивалентен вставке ключевого слова DISTINCT в инструкцию на панели SQL.
Расширение GROUP BY
Указывает, что для представлений доступны дополнительные параметры, основанные на агрегатных запросах.
Выводить все столбцы
Указывает, возвращаются ли в выбранном представлении все столбцы. Этот параметр задается во время создания представления.
Комментарий SQL
Показывает описание инструкций SQL. Чтобы просмотреть описание целиком или изменить его, выберите описание, а затем нажмите на меню с многоточием (…) справа от свойства. Комментарии могут содержать, например, сведения о том, кто использует это представление и когда оно используется.
(Верх)
Указывает, что представление будет иметь предложение TOP, возвращающее только первые n строк или первые n процентов строк из результирующего набора. По умолчанию представление возвращает первые 10 строк из результирующего набора. Это поле позволяет изменить число возвращаемых строк или указать другой процент.
Выражение
Указывает, какой процент (если для параметра Процент выбрано значение Да) или какое количество записей (если для параметра Процент выбрано значение Нет) возвращает представление.
(Обновление с использованием правил представления.)
Указывает, что все обновления и вставки в представлении будут преобразованы с помощью Microsoft Data Access Components (MDAC) в инструкции SQL, которые ссылаются на представление, а не в инструкции SQL, которые ссылаются непосредственно на базовые таблицы представления.
В некоторых случаях компоненты MDAC представляют операции обновления и вставки представления в виде операций обновления и вставки в базовых таблицах представления. Выбор Обновление с использованием правил представления позволяет гарантировать создание MDAC операций обновления и вставки для самого представления.
Параметр проверки
Указывает, что при открытии этого представления и изменении панели Результаты источник данных проверяет соответствие добавленных или измененных данных предложению WHERE определения представления. Если изменение не соответствует предложению WHERE, отобразится сообщение об ошибке с дополнительными сведениями.
Получение зависимостей представления
Щелкните правой кнопкой мыши представление, свойства которого необходимо просмотреть, и выберите пункт Просмотреть зависимости.
Выберите Объекты, зависящие от [имя_представления] для отображения объектов, которые ссылаются на представление.
Использование Transact-SQL
Получение определения и свойств представления
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте один из следующих примеров и вставьте его в окне запроса, а затем нажмите Выполнить.
Получение зависимостей представления
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте приведенный ниже пример в окно запроса и нажмите кнопку Выполнить.



