4 Сложные структуры данных в R
4.1 Матрица
Если вдруг вас пугает это слово, то совершенно зря. Матрица (matrix) — это всего лишь “двумерный” вектор: вектор, у которого есть не только длина, но и ширина. Создать матрицу можно с помощью функции matrix() из вектора, указав при этом количество строк и столбцов.
Заметьте, значения вектора заполняются следующим образом: сначала заполняется первый столбик сверху вниз, потом второй сверху вниз и так до конца, т.е. заполнение значений матрицы идет в первую очередь по вертикали. Это довольно стандартный способ создания матриц, характерный не только для R.
Если мы знаем сколько значений в матрице и сколько мы хотим строк, то количество столбцов указывать необязательно:
Все остальное так же как и с векторами: внутри находится данные только одного типа. Поскольку матрица — это уже двумерный массив, то у него имеется два индекса. Эти два индекса разделяются запятыми.
Первый индекс — выбор строк, второй индекс — выбор колонок. Если же мы оставляем пустое поле вместо числа, то мы выбираем все строки/колонки в зависимости от того, оставили мы поле пустым до или после запятой:
Так же как и в случае с обычными векторами, часть матрицы можно переписать:
В принципе, это все, что нам нужно знать о матрицах. Матрицы используются в R довольно редко, особенно по сравнению, например, с MATLAB. Но вот индексировать матрицы хорошо бы уметь: это понадобится в работе с датафреймами.
4.2 Массив
Два измерения — это не предел! Структура с одним типом данных внутри, но с тремя измерениями или больше, называется массивом (array). Создание массива очень похоже на создание матрицы: задаем вектор, из которого будет собран массив, и размерность массива.
4.3 Список
Теперь представим себе вектор без ограничения на одинаковые данные внутри. И получим список (list)!
А это значит, что там могут содержаться самые разные данные, в том числе и другие списки и векторы!
Если у нас сложный список, то есть очень классная функция, чтобы посмотреть, как он устроен, под названием str() :
Как и в случае с векторами мы можем давать имена элементам списка:
К списку можно обращаться как с помощью индексов, так и по именам. Начнем с последнего:
А вот с индексами сложнее, и в этом очень легко запутаться. Давайте попробуем сделать так, как мы делали это раньше:
Мы, по сути, получили элемент списка — просто как часть списка, т.е. как список длиной один:
А вот чтобы добраться до самого элемента списка (и сделать с ним что-то хорошее), нам нужна не одна, а две квадратных скобочки:
Как и в случае с вектором, к элементу списка можно обращаться по имени.
Списки довольно часто используются в R, но реже, чем в Python. Со многими объектами в R, такими как результаты статистических тестов, удобно работать именно как со списками — к ним все вышеописанное применимо. Кроме того, некоторые данные мы изначально получаем в виде древообразной структуры — хочешь не хочешь, а придется работать с этим как со списком. Но обычно после этого стоит как можно скорее превратить список в датафрейм.
4.4 Датафрейм
Итак, мы перешли к самому главному. Самому-самому. Датафреймы (data.frames). Более того, сейчас станет понятно, зачем нам нужно было разбираться со всеми предыдущими темами.
Без векторов мы не смогли бы разобраться с матрицами и списками. А без последних мы не сможем понять, что такое датафрейм.
Ну а можно просто обращаться с помощью двух индексов через запятую, как мы это делали с матрицей:
Как и с матрицами, первый индекс означает строчки, а второй — столбцы.
А еще можно использовать названия колонок внутри квадратных скобок:
И здесь перед нами открываются невообразимые возможности! Узнаем, любят ли R те, кто моложе среднего возраста в группе:
Эту же задачу можно выполнить другими способами:
В большинстве случаев подходят сразу несколько способов — тем не менее, стоит овладеть ими всеми.
Датафреймы удобно просматривать в RStudio. Для это нужно написать команду View(df) или же просто нажать на названии нужной переменной из списка вверху справа (там где Environment). Тогда увидите табличку, очень похожую на Excel и тому подобные программы для работы с таблицами. Там же есть и всякие возможности для фильтрации, сортировки и поиска. 9

Но, конечно, интереснее все эти вещи делать руками, т.е. с помощью написания кода.
Все, что вы нажмете в этом окошке, никак не повлияет на исходную переменную. Так что можете смело использовать эти функции для исследования содержимого датафрейма.↩︎

Предыдущую часть мы закончили темой векторов, а в этой — переходим к матрицам.
9. Что такое матрица?
Матрица, как структура данных, тоже часто встречается в R.
Её можно рассматривать как расширение понятия вектора. У матрицы может быть множество строчек и столбцов. Все элементы матрицы должны иметь один тип данных.
Чтобы создать матрицу, пользуйтесь конструктором matrix(), а функции nrow и ncol пригодятся вам, чтобы определить количество строк и столбцов соответственно:
Так получается матричная переменная под названием x с 4-мя строками и 4-мя столбцами. Вектор можно трансформировать в матрицу, используя для этого конструктор matrix. Результирующая матрица будет заполняться по столбцам:
Так получится матрица с одним столбцом и тремя строками (по одной для каждого элемента):
Если нам нужно заполнить матрицу по строкам или столбцам, тогда мы можем явно передать их количество при помощи параметра byrow:
Этот код создаёт матрицу с 2-мя столбцами и строчками. Заполняется матрица построчно.
10. Что такое списки и факторы?
Если мы хотим создать множество, в котором будут элементы разных типов, то нам стоит сделать список.
Списки
Списки — это очень важная структура данных в R. Чтобы создать список, пользуйтесь конструктором list():
Эта строчка кода иллюстрирует то, как создаётся список из трёх элементов с разными типами данных.
Мы можем получить доступ к любому элементу при помощи указателя. Например, так:
Этот код в результате напишет “hello”.
Ещё мы можем назвать каждый элемент. К примеру, так:
Факторы
Факторы — это категориальные данные. Например: “да”, “нет” или “мужской”, “женский”, или “красный”, “синий”, “зелёный” и т.д.
Тип данных “фактор” можно использовать для представления факторного множества данных:
Факторы также можно упорядочить (отсортировать):
А ещё можем вывести факторы в формате таблицы:
Это даст следующий результат:
А сейчас давайте разберёмся с вопросами, связанными со статистикой.
11. Что такое датафреймы?
Многим, даже практически всем, научным проектам по работе с данными нужно на вход подавать таблицы. Датафрейм — это структура, которая нужна для представления табличных данных в R. В каждом столбце — список элементов. В разных столбцах могут быть разные типы (данных).
Чтобы создать датафрейм из 2-х столбцов и 5-ти строк, напишите следующее:
12. Различные логические операции в R
В этом разделе рассмотрим общепринятые операторы.
OR (или): первое | второе
Этот оператор проверяет, верно ли первое, или второе. Это дизъюнкция.
AND (и): первое & второе
Этот оператор проверяет, верно ли первое и второе. Это называется конъюнкция.
Этот оператор возвращает true, если было введено false. И наоборот. Операцию ещё называют инверсией.
Также можем пользоваться операторами:
больше или равно;
> больше, чем;
isTRUE(input) верно для вводимого;и другие.
13. Функции и область действия переменных в R
Иногда нам нужно, чтобы код решал не одну, а сразу комплекс задач. Эти задачи можно группировать в формате функций. А функции — это очень важные объекты в R.
В функцию можно передавать аргументы, а она может возвращать объект.
В установленном пакете R есть определенное количество встроенных функций, в том числе: length(), mean() и т.д.
Каждый раз, когда мы объявляем функцию (или переменную) и вызываем её, она ищется в текущем окружении, а также рекурсивно ищется в родительских окружениях до тех пор, пока значение не будет найдено.
У функции есть имя. Оно хранится в окружении R. В теле функции находятся её операторы.
Функция может возвращать значение и может принимать ряд аргументов (второе опционально).
Чтобы создать функцию, нам нужно написать следующее:
К примеру, мы можем создать функцию, которая берёт два целых числа и возвращает их сумму:
Чтобы вызвать функцию, нам нужно передать ей аргументы:
Так на выходе получим 3.
Ещё мы можем установить значения по умолчанию для аргумента таким образом, чтобы оно было использовано в случае, когда значение аргументу не присвоено:
Значение по умолчанию y — 2. Так что мы можем вызвать функцию без присвоения значения y.
Запомните ключевое: используйте фигурные скобки <…>.
Давайте посмотрим на сложный случай, в котором мы будем использовать логический оператор.
Предположим, что нужно создать функцию, которая принимает следующие аргументы: Mode (режим), x и y.
Чтобы вызвать функцию сложения x и y, можем сделать так:
Разберём код ниже. В частности, посмотрим, где наше print(z):
Ключевой момент в том, что z выводится после закрытия скобок.
Будет ли переменная z доступна здесь? Это подводит нас к теме области действия в функциях.
Функция может быть объявлена внутри другой функции:
В примере выше some_func и another_func — это две функции. another_func объявляется внутри функции some_func. В результате another_func() является частной по отношению к some_func(). Следовательно она недоступна внешнему миру.
Если я выполню функцию another_func() снаружи функции some_func, как это показано ниже:
Error in another_func() : could not find function “another_func”
Ошибка в функции another_func() : невозможно найти функцию “another_func”.
С другой же стороны, мы можем выполнить another_func() внутри some_func() и она сработает именно так, как и ожидалось.
Теперь рассмотрим этот код, чтобы понять, как работает область действия в R.
Выполнение этого кода приведёт к возникновению исключения в R-Studio:
Это значит примерно следующее: ошибка при выводе, объект ‘another_func_variable’ не обнаружен.
Как говорится в сообщении об ошибке, another_func_variable не обнаружена. Мы можем увидеть, что было выведено DEF, а это было значение, которое присвоили переменной some_func_variable.
Если мы хотим получить доступ и присвоить значения глобальной переменной, то будем пользоваться оператором 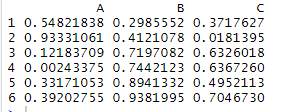 Сниппет показывает содержимое Excel-файла
Сниппет показывает содержимое Excel-файла
Запись в Excel-файл
Создаётся новый файл Excel с таблицей под названием NewSheet:
Чтение таблицы SQL
Мы может читать данные из SQL-таблицы.
Запись в таблицу SQL
Можем записывать данные в SQL-таблицы.
16. Статистические вычисления в R
R известен как один из самых популярных языков программирования для статистической обработки данных. Встроенные статистические функции очень важно понимать. В этом разделе я расскажу о самых популярных статистических вычислениях, которые производят исследователи данных.
Заполнение недостающих значений
Одна из самых частых задач в проекте исследования данных — это заполнение пропущенных значений. Мы можем пользоваться is.na(), чтобы найти элементы, которые имеют нулевое значение (NA (Not Available — «не доступно») или NAN (Not a Number — «не число»)):
В результате выведется FALSE TRUE FALSE (ложно, истинно, ложно), указывая на второй элемент в NA.
Чтобы вы лучше разобрались, скажу, что is.na() возвращает все те элементы NA. А функция is.nan() вернёт все объекты NaN. Важно помнить, что NaN это NA, но не наоборот. NA не является NaN.
Заметка: многие статистические функции, например mean, median, и так далее, принимают аргумент na.rm — он указывает, хотим ли мы удалить (переместить) na (недостающие значения).
Некоторые вычисления далее будут производиться на следующих двух векторах:
Оба вектора A и B содержат числовые значения 20-ти элементов.
Среднее арифметическое значение
Среднее арифметическое значение вычисляется путем сложения значения в множестве и затем делением на общее количество значений:
Медиана
Медиана — среднее значение в отсортированном множестве. Если количество значений четное, то медиана будет средним значением двух значений в середине:
Она показывает самое часто повторяющееся значение. В R нет стандартной встроенной функции для вычисления моды. Но при этом мы можем создать функцию для такого расчёта, смотрите на пример:
Вот, что происходит при выполнении этого кода:
Среднеквадратичное отклонение
Среднеквадратичное отклонение — это отклонение от значений среднего арифметического.
Дисперсия
Дисперсия — это среднеквадратичное отклонение в квадрате:
Корреляция
При помощи корреляции мы можем понять, связаны ли множества друг с другом и взаимодействуют ли они, если между ними значительная связь:
Мы можем пользоваться определенным методом корреляции, например, коэффициентом ранговой корреляции Кендалла или Спирмена. По умолчанию используется коэффициент корреляции Пирсона.
Помещайте метод корреляции в аргумент метода.
Работа с табличными данными в R. Часть 1
Data Frame
Data Frame используются для хранения табличных данных. Они представляют собой особый тип списков (lists), матрицу данных. Это – именованный список векторов одной и той же длины, в которых элементы отвечают за переменные. В отличие от матриц, таблица данных содержит элементы разных классов, т.е. допускаются столбцы с числовыми, текстовыми и логическими значениями.
Создать Data Frame
Для создания таблицы данных применяется функция data.frame()
Определение таблицы данных на основе векторов
Определим сначала два вектора, а после введем величину d, которая является таблицей данных, включающей эти два вектора:
Еще один пример по созданию таблицы данных
Пусть требуется изменить названия столбцов. Тогда
Кроме того, вывод значений 1-го столбца (переменной) осуществляется следующим образом
Изложенная процедура создания таблицы данных с изменением названий столбцов имеет аналог
Выбор числа, строк и столбцов
[1] 5260 5470 5640 6180 6390 6515 6805 7515 7515 8230 8770
Если нужно взять определенные элементы из вектора, пользуемся записью вида
Здесь с(…) запись, которая определяет вектор, состоящий из чисел под указанными порядковыми номерами.
Это же можно делать следующим образом
Кроме того, применяются логические условия для выбора чисел из вектора
intake.post[intake.pre > 7000 & intake.pre
Индексирование с data frame происходит так
В квадратных скобках первый параметр указывает на номер строки, а второй – столбца. То же самое получаем, если вместо номера указывается наименование переменной
Если нужна конкретная строка целиком, например, 5-я, то записываем
Следует подчеркнуть, что запятая нужна.
По аналогии получаем все значения по конкретному столбцу
[1] 3910 4220 3885 5160 5645 4680 5265 5975 6790 6900 7335
Пусть необходимо вывести значения по заданным строкам и столбцам. Для этого следует выполнить
Выбор по условию
Если нужна выборка записей (строк), которые соответствуют выполнению условия по одной переменной, то команда имеет такой вид
Данную выборку можно получить несколько другим способом
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
Шапка – head ()
Работая над большим массивом данных, часто есть потребность посмотреть несколько первых строк. В таком случае можно выбрать один из двух способов.
Конец – tail()
Сведения о таблице: количество строк и столбцов, их названия
Чтобы узнать, сколько строк и столбцов насчитывается в таблице, воспользуемся функцией dim()
Благодаря dimnames() можно увидеть названия строк и столбцов
Как видим, Data Frame имеет особый атрибут raw.names
Чтобы узнать и применять в дальнейших расчетах количество строк, вводим функцию nrow(). А количество столбцов определяется через ncol().
Полезной функцией для получения информации о таблице данных является str()
При создании таблицы можно указать, что переменная типа “Factor” является “Character”
‘data.frame’: 5 obs. of 3 variables:
Знакомство с R (молниеносное и поверхностное).
Онлайн IDE для R — на тот случай, если у вас не установлен R:
Комментарии
Комментарии в текстах программ обозначаются символом #
Полезные клавиатурные сокращения в RStudio
Как получить помощь
R как калькулятор, математические операции
Переменные
Как выбрать название переменной?
Данные в R можно хранить в виде разных объектов.
Некоторые способы создания векторов:
Функция c принимает несколько (произвольное количество) аргументов, разделенных запятыми. Она собирает из них вектор.
Векторы можно хранить в переменных для последующего использования
Адресация внутри векторов
Если вам нужно несколько элементов, то их нужно передать квадратным скобкам в виде вектора. Например, нам нужны элементы с 3 по 5. Вот вектор, который содержит значения 3, 4 и 5.
Если мы его напишем в квадратных скобках, то добудем элементы с такими порядковыми номерами
Аналогично, если вам нужны элементы не подряд, то передайте вектор с номерами элементов, который вы создали при помощи функции c() c(2, 4, 6) # это вектор содержащий 2, 4 и 6, поэтому
Но R выдаст ошибку, если при обращении к вектору, вы не создавали вектор, а просто перечислили номера элементов через запятую.
При помощи функции c() можно объединять несколько векторов в один вектор
Добываем 1, 3, 5 и с 22 по 24 элементы
Типы данных в R
Числовые данные
Уже видели в прошлом разделе.
Текстовые данные
Текстовые значения можно объединять в вектора.
Это текстовый вектор
Добываем первый и последний элементы
В данном случае я точно знаю, что их 6, мне нужны 1 и 6.
Добываем элементы с 3 по 6
Если у вас вдруг слишком короткий вектор в этом задании, то можно склеить новый из двух
Логические данные
Еще логический вектор
Создаем длинный логический вектор.
Чтобы создавать длинные вектора из повторяющихся элементов, можно использовать функцию rep()
В R названия аргументов функций можно не указывать, если вы используете аргументы в том же порядке, что прописан в help к этой функции.
Создаем логический вектор, где TRUE повторяется 3 раза, FALSE 3 раза и TRUE 4 раза. Результат сохраняем в переменной vect_log
Применение логических векторов для фильтрации данных
Вспомните, у нас был вот такой текстовый вектор
Задача 1. Допустим, мы хотим из этого вектора извлечь только желтый цвет.
Мы можем создать логический вектор, в котором TRUE будет только для 3-го и 9-го элементов
Этот логический вектор-фильтр мы можем использовать для извлечения данных из double_rainbow
Задача 2. Допустим, мы хотим извлечь из double_rainbow желтый и синий Желтый фильтр у нас уже есть, поэтому мы создадим фильтр для синего.
Выражение “желтый или синий” можно записать при помощи логического “или” ( | )
Задача решена, мы извлекли желтый и синий цвета.
То же самое можно было бы записать короче.
В одну строку — совершенно нечитабельно:
Фильтр отдельно — читается лучше:
У нас был числовой вектор
Задача 3. Давайте извлечем из числового вектора vect_num только значения больше 0
Факторы
уровни этого фактора
По умолчанию, R назначает порядок уровней по алфавиту. Можно изменить порядок (см. help(«factor») ). Нам это пригодится позже
Создаем фактор из текстового вектора и складываем его в переменную
Как узнать, что за данные хранятся в переменной?
Чтобы узнать, что за данные хранятся в переменной, используйте функцию class()
Встроенные константы в R
Встроенные константы в R: NA, NULL, NAN, Inf
Вот текстовый вектор с пропущенным значением
Кстати, если попросили добыть из вектора номер элемента, которого там точно нет, то R выдаст NA, потому, что такого элемента нет
Поэкспериментируем с векторами. Проверим, как работают арифметические операции
Теперь посмотрим на встроенные константы в действии.
Создаем новый вектор для экспериментов
Вот так он выглядит
Что произойдет с NA?
Но в последнем случае вы увидите
NaN получится, если взять корень из отрицательного числа
Функции в R
Вы уже видели массу функций, их легко узнать по скобкам после ключевого слова. Познакомимся еще с несколькими и научимся писать пользовательские функции. Пользовательские функции позволяют автоматизировать повторяющиеся действия и делают код легко читаемым.
Длину вектора можно вычислить при помощи функции length()
Сумму элементов вектора при помощи функции sum()
Упс! Почему-то получилось NA
Та же история с функцией mean
Проверим нашу функцию при помощи встроенной функции
Для этого, для начала, создадим векторы с данными для переменных.
Теперь сложим эти векторы в датафрейм
Можно проверить, действительно мы создали объект класса data.frame
Содержимое датафрейма можно просмотреть несколькими способами
Адресация внутри датафреймов
У каждой ячейки в датафрейме есть координаты вида [строка, столбец]
Визуализация данных
Базовые графики
Скаттерплот (точечный график) — по оси х и y непрерывные числовые величины
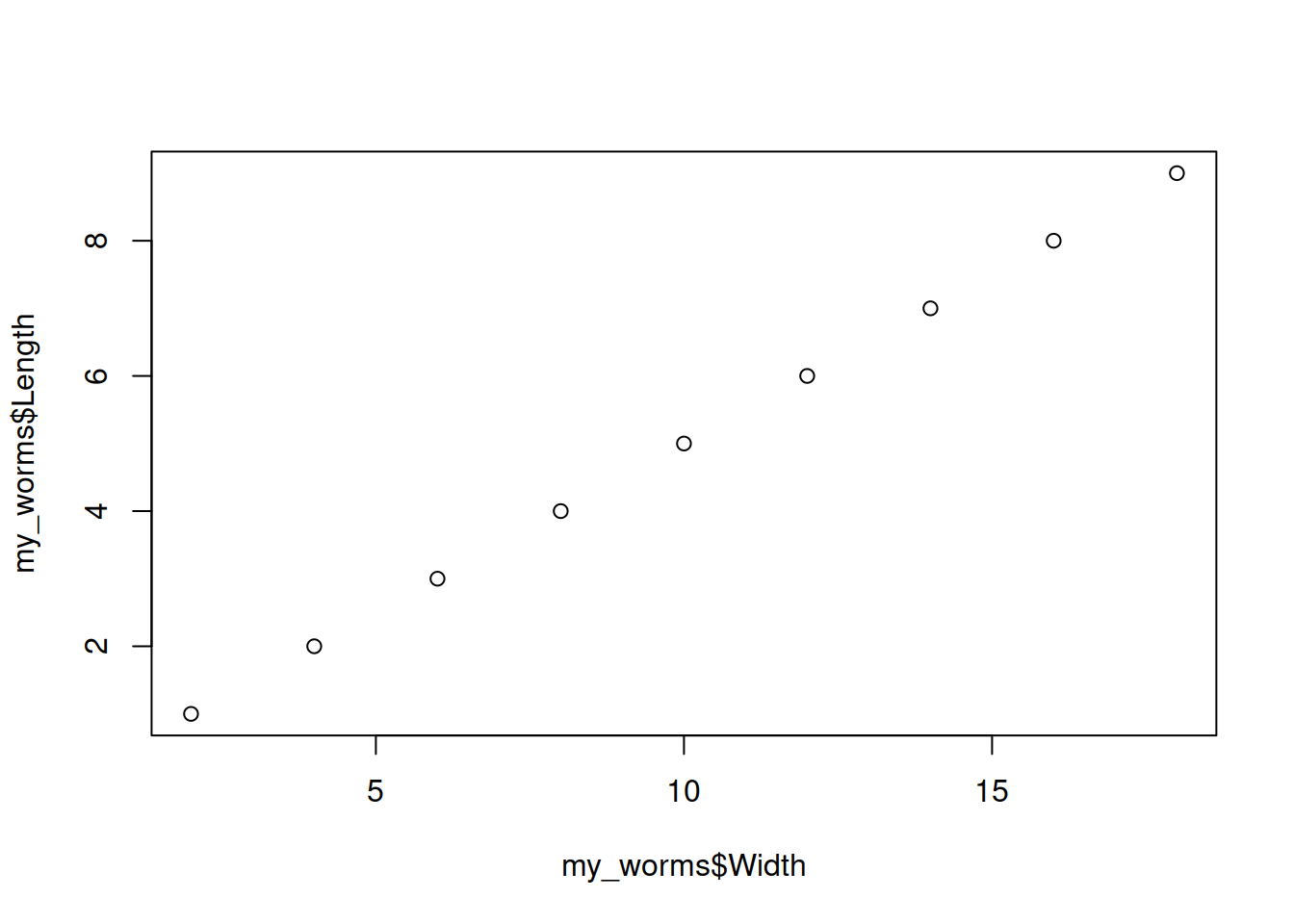
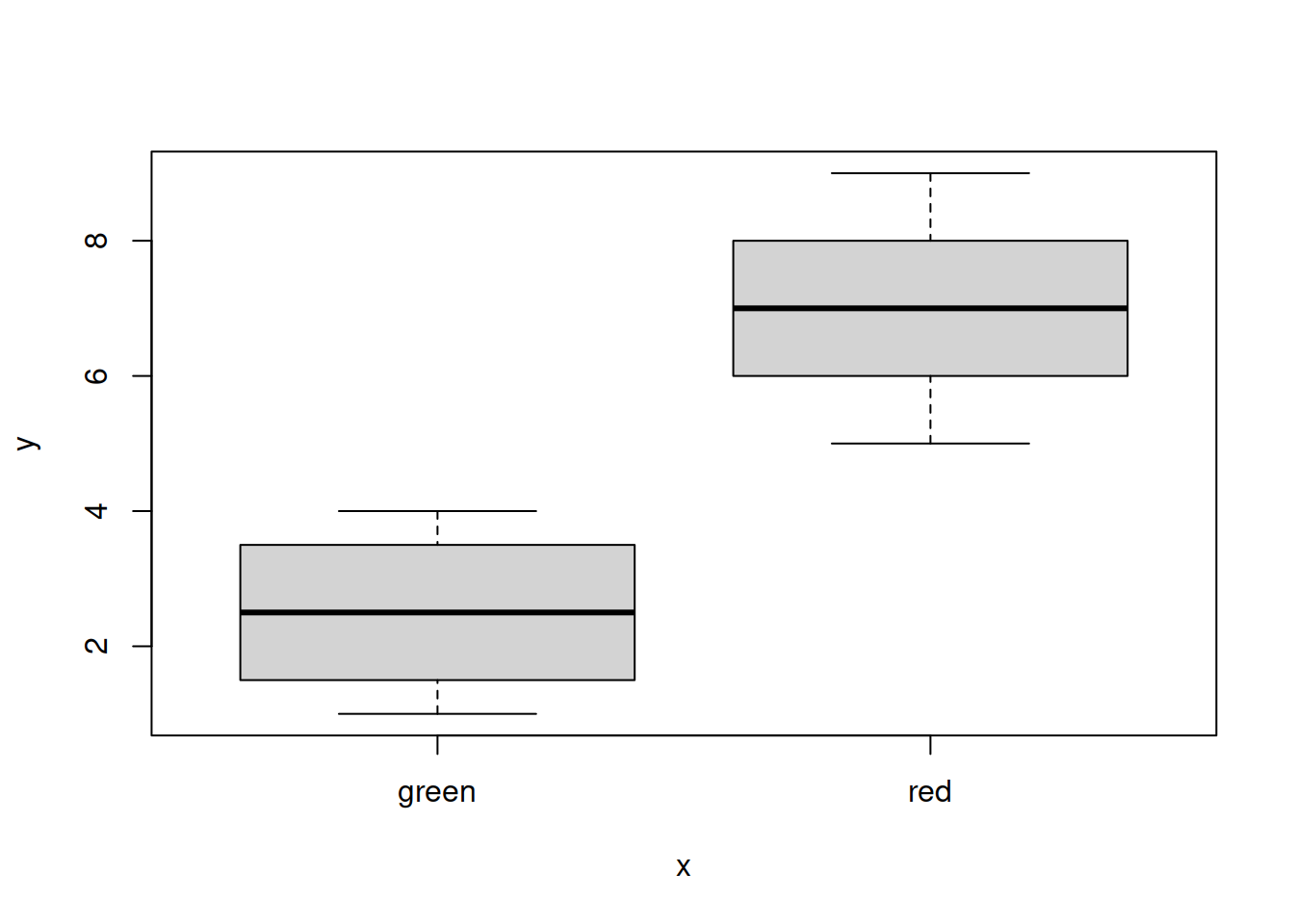
Для настройки внешнего вида см graphical parameters в help
На самом деле, мы не будем пользоваться этой системой графики, но об этом в следующих сериях
Графики из пакета ggplot2
В R есть более удобный (но, может быть, более многословный) пакет для рисования графиков — ggplot2. Чтобы использовать функции из пакета ggplot2, нужно его сначала установить.
Установка пакета в локальную библиотеку делается один раз. Поэтому строку с install.packages() не нужно включать в финальную версию кода.
В текущей сессии работы в R пакет нужно активировать перед использованием. Когда вы в следующий раз начнете работать с R, нужные пакеты придется снова активировать. Поэтому строки с загрузкой пакетов при помощи library() обязательно должны остаться в финальной версии кода.
Нарисуем те же самые графики при помощи пакета ggplot2.
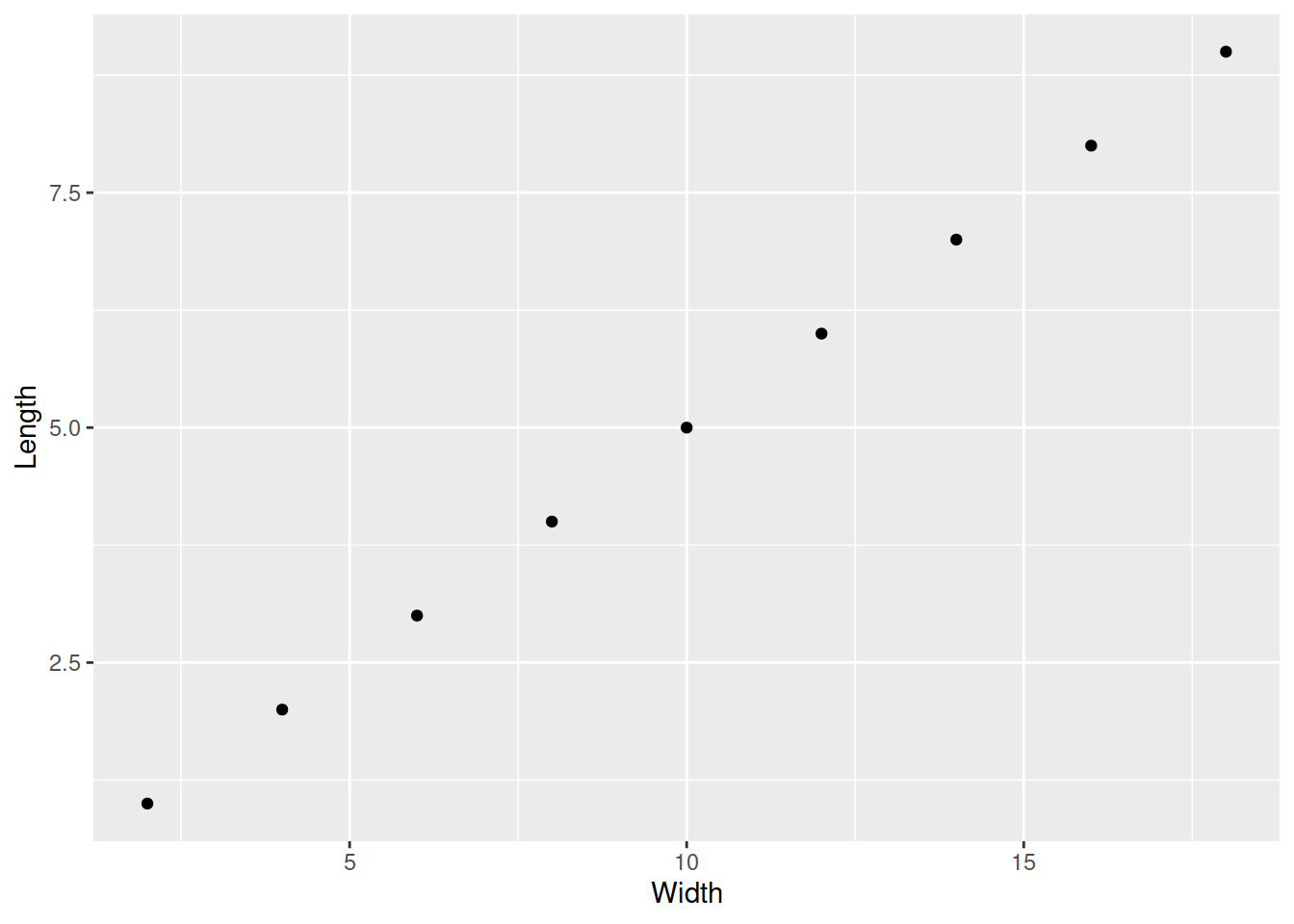
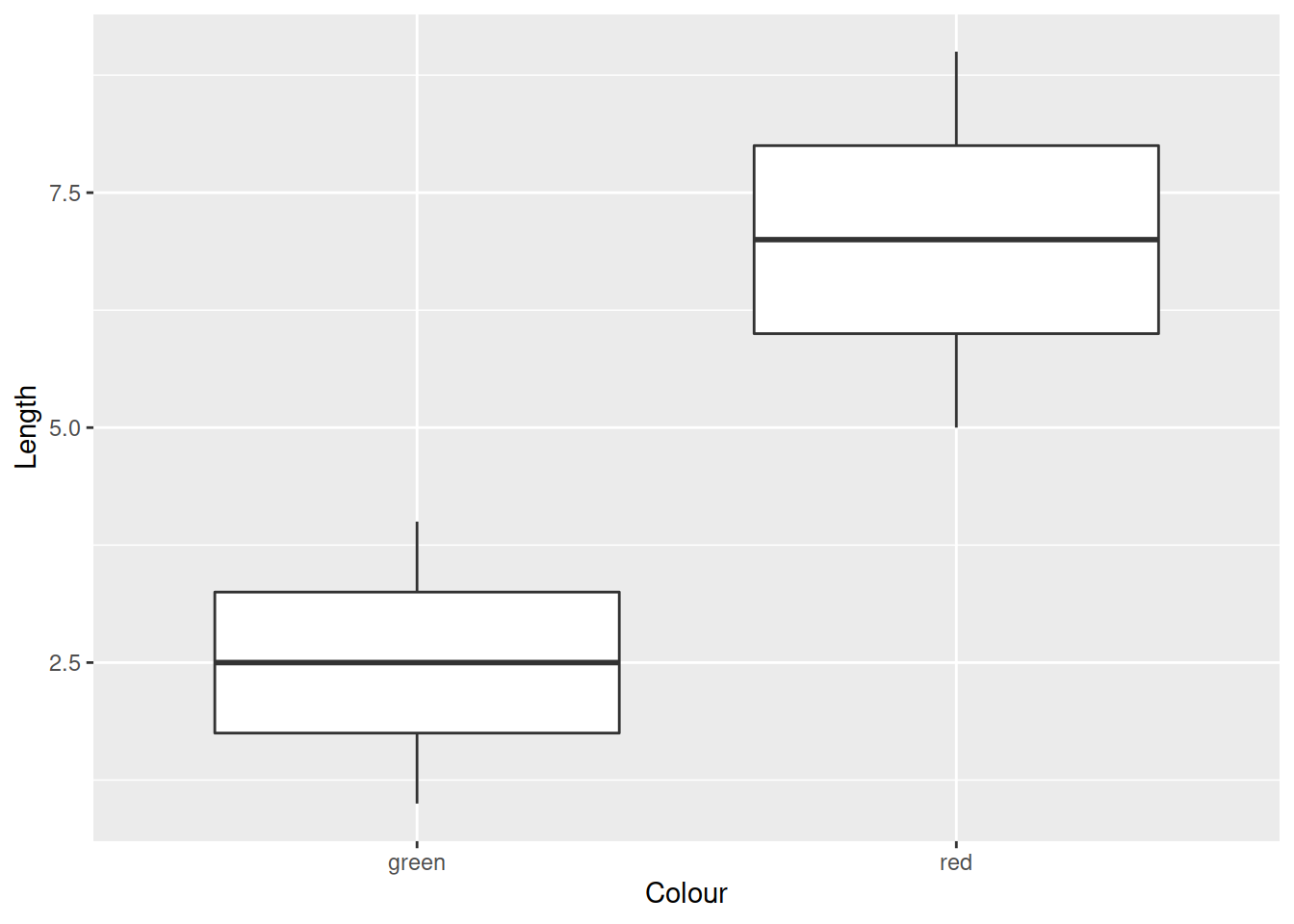
Добавляем для точек эстетику цвет (colour) из переменной Colour
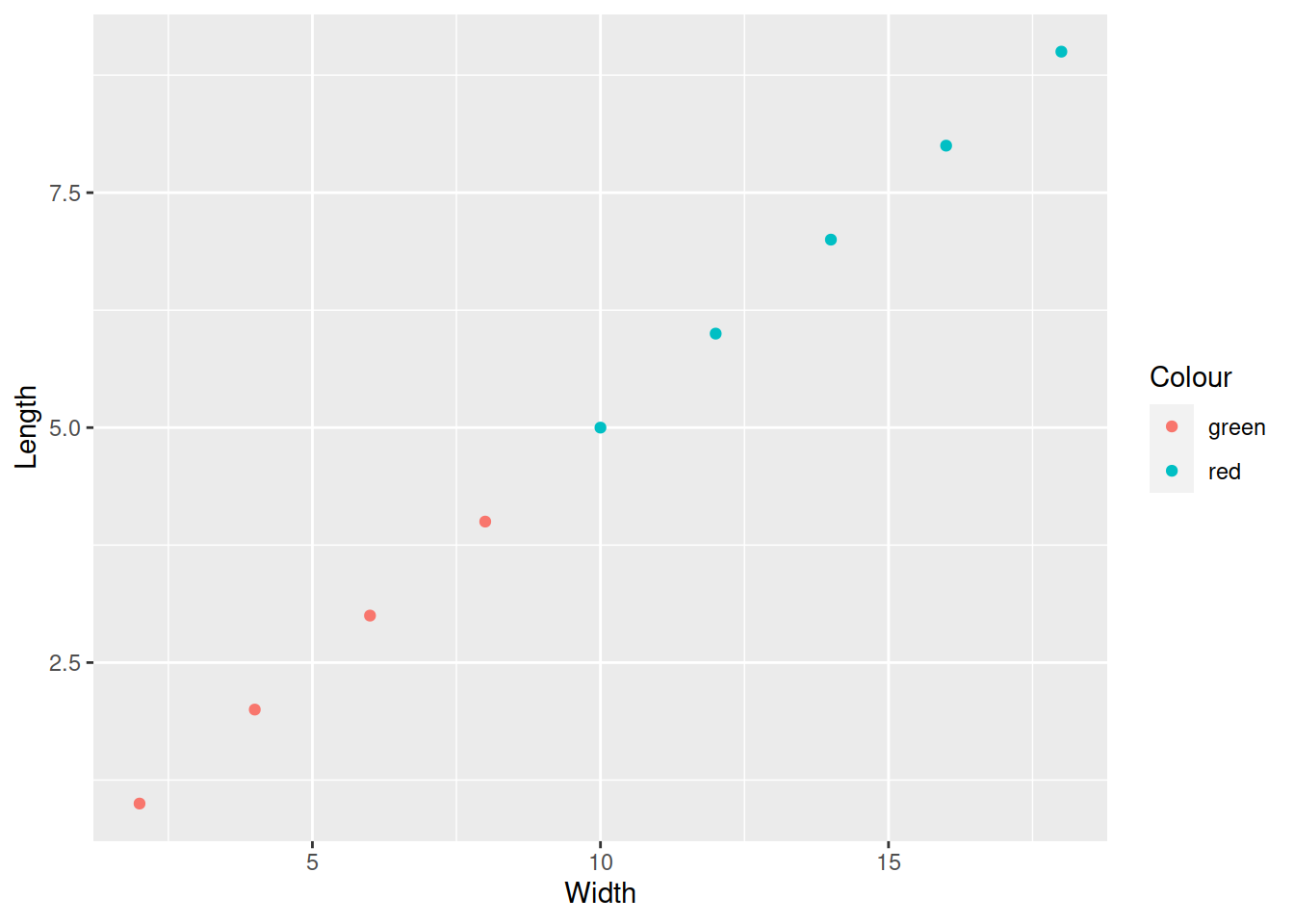
Графики можно сохранять в переменных, и использовать потом
Чтобы вывести график, нужно напечатать название переменной.
Можно менять темы оформления графика. Если тема нужна только один раз, то прибавляем ее к графику
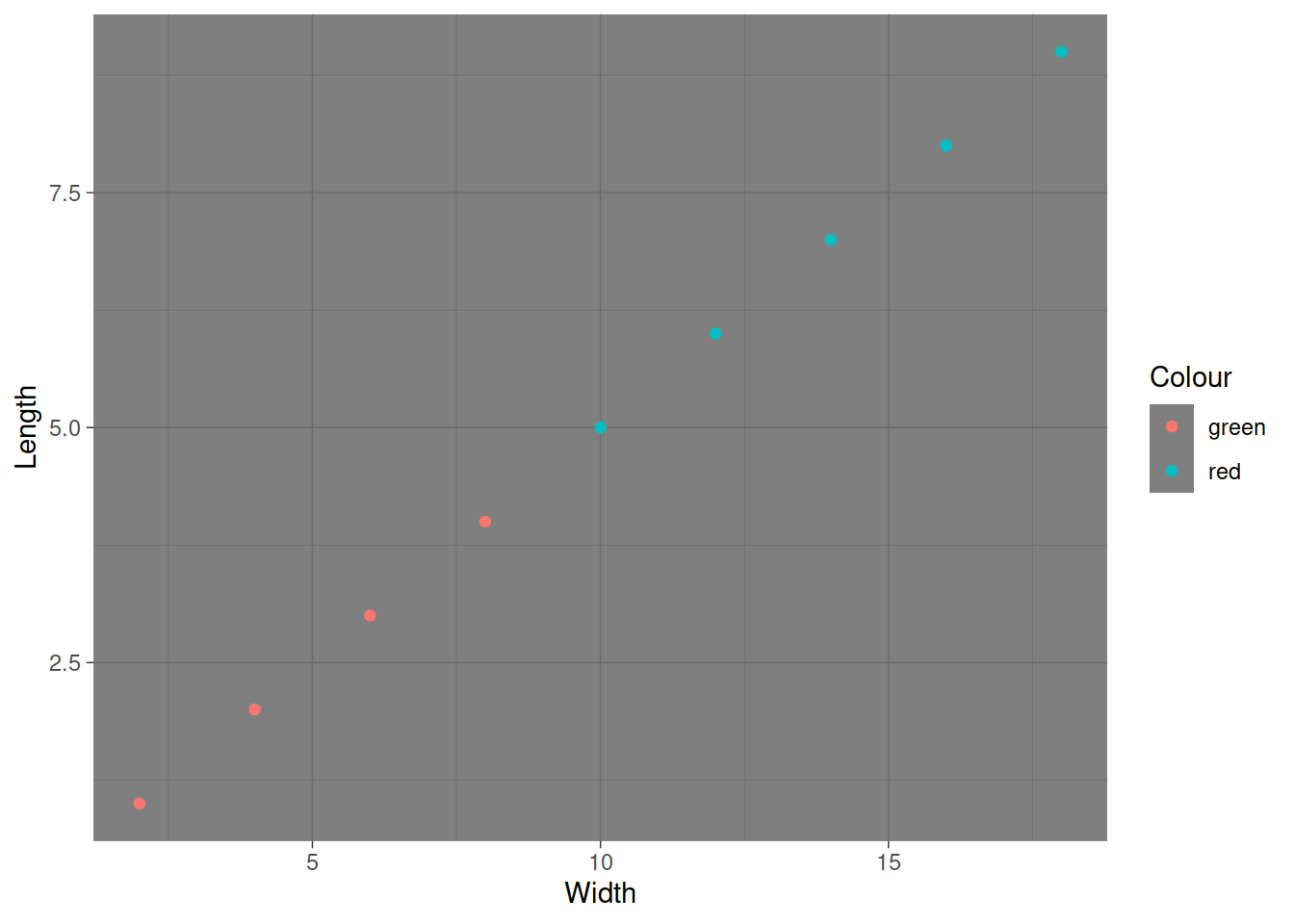
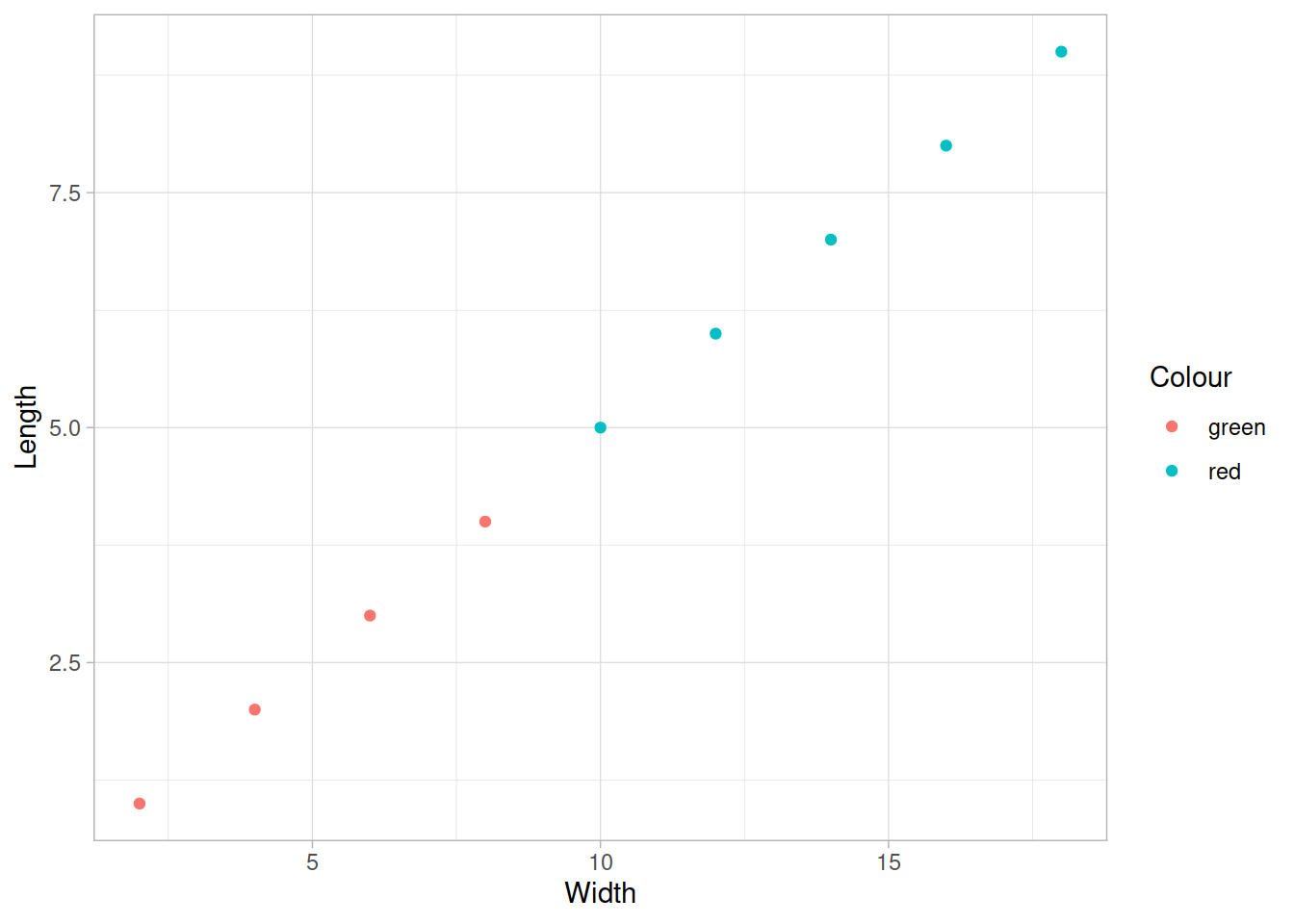
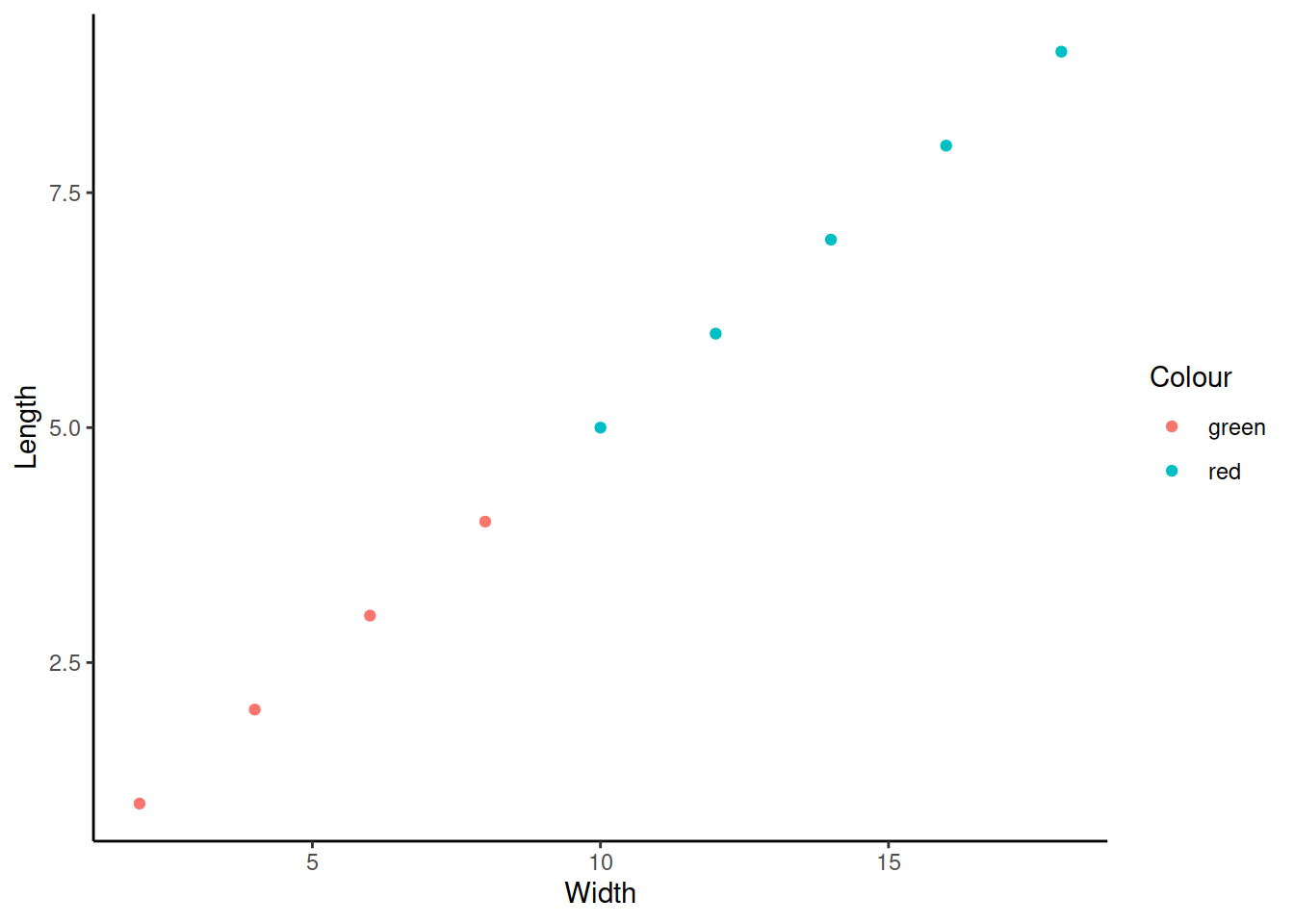
Можно установить нужную тему до конца сессии.
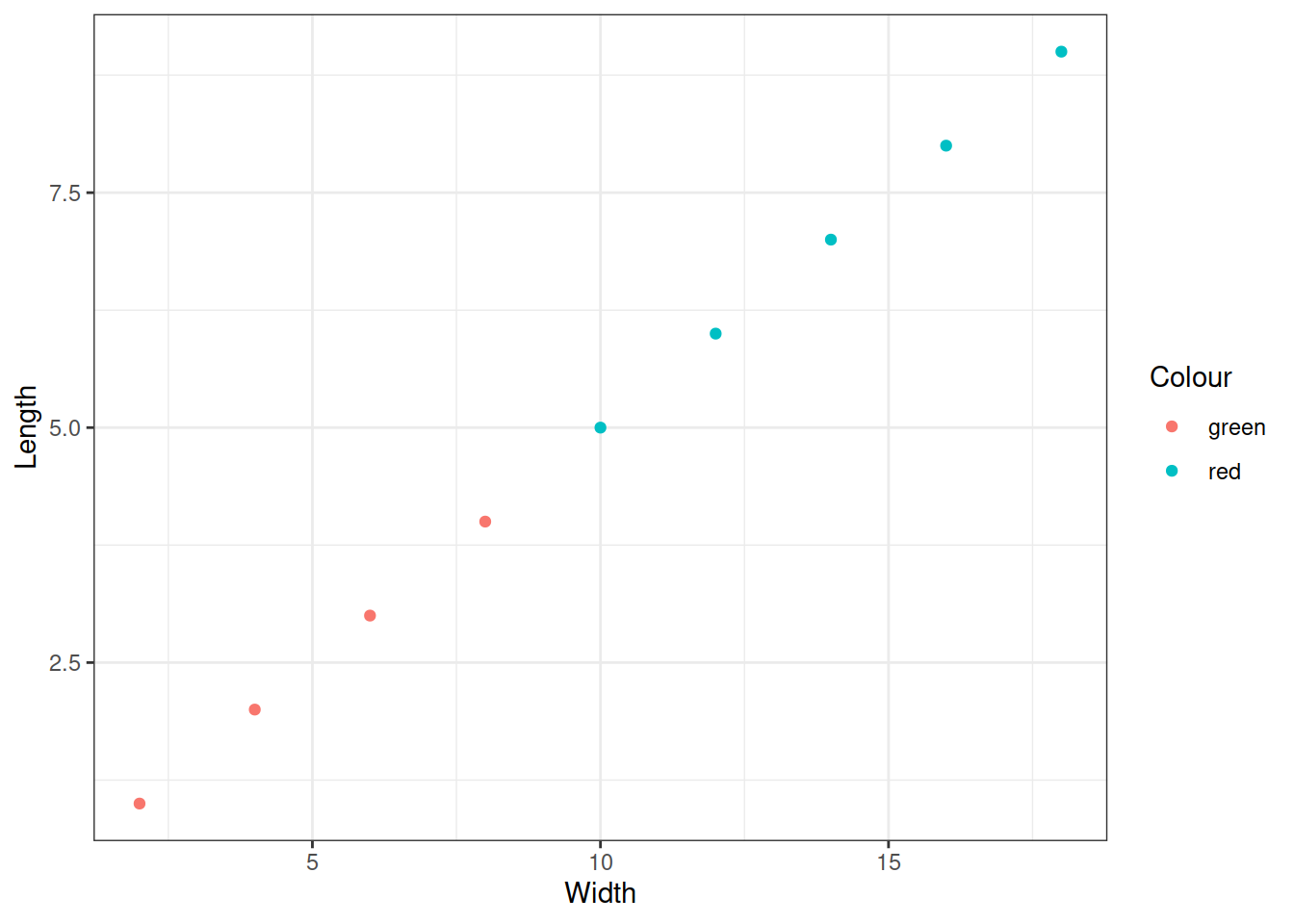
Подписи осей и легенд задает функция labs()
Графики можно делить на фасетки при помощи facet_wrap или facet_grid
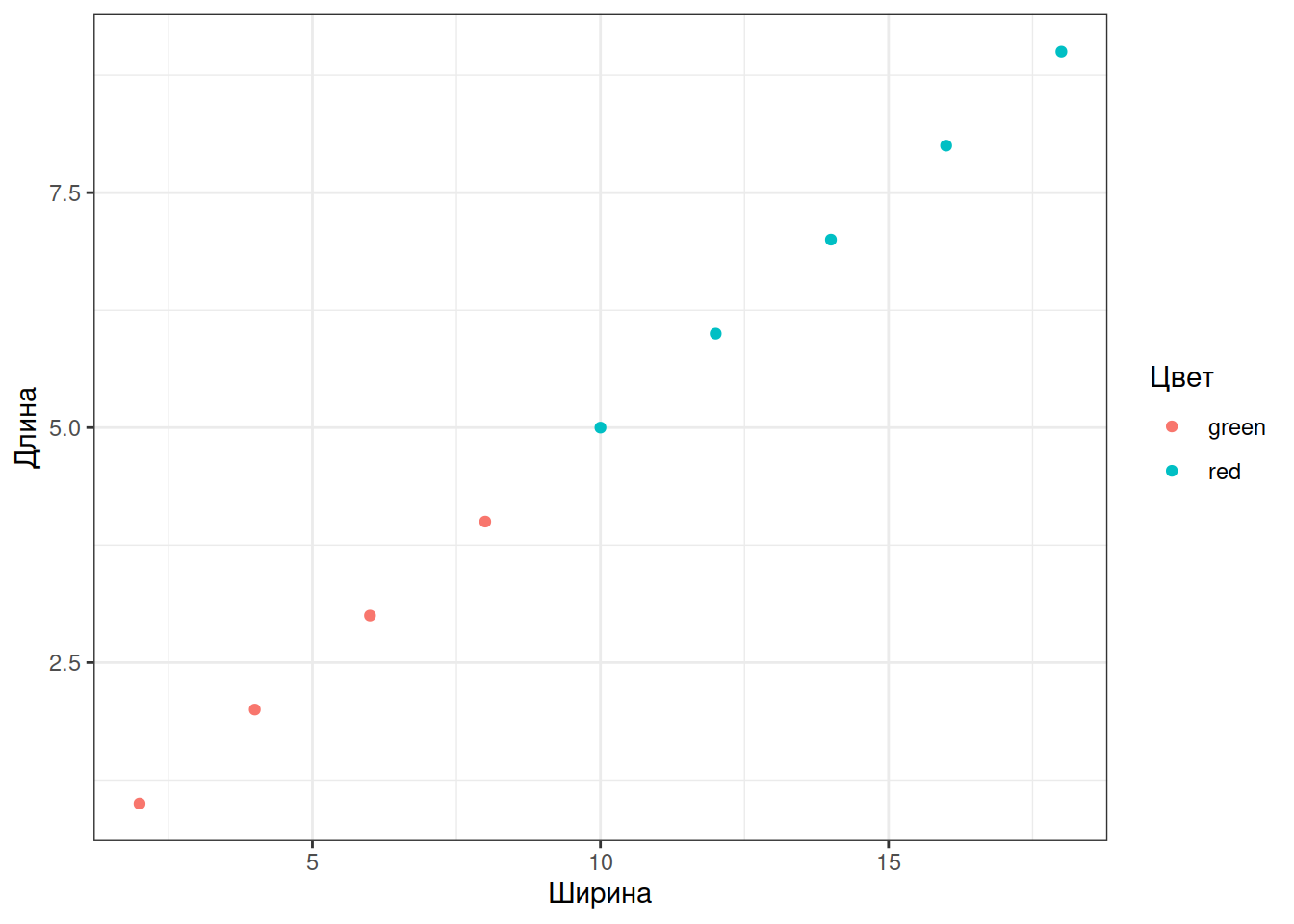
Чтобы изменить подписи цветов, нужно изменить уровни соотв. фактора.



