Race condition и D ata Race

Продолжаем серию статей о проблемах многопоточности, параллелизме, concurrency и других интересных штуках.
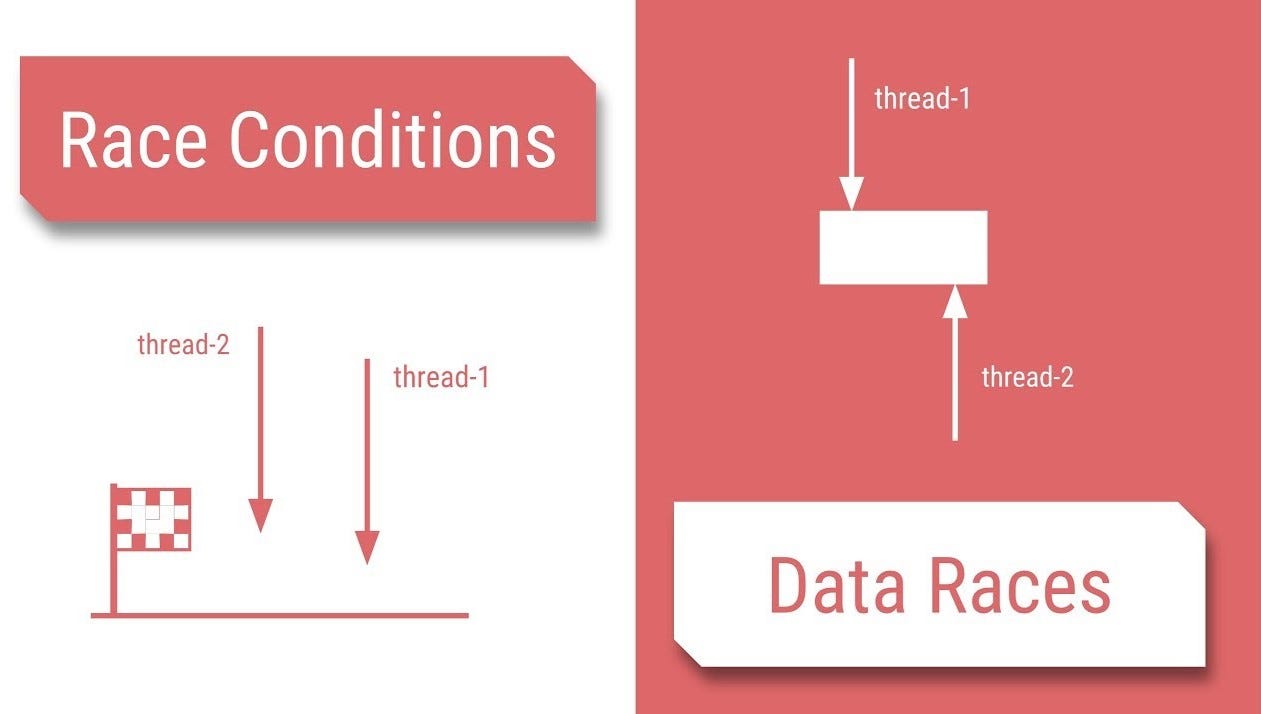
Race condition и data race — две разные проблемы многопоточности, которые часто путают. Попробуем разобраться.
Race condition
Существует много формулировок определения:
Race condition представляет собой класс проблем, в которых корректное поведение системы зависит от двух независимых событий, происходящих в правильном порядке, однако отсутствует механизм, для того чтобы гарантировать фактическое возникновение этих событий.
Race condition — ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода.
Race condition — это нежелательная ситуация, которая возникает, когда устройство или система пытается выполнить две или более операций одновременно, но из-за природы устройства или системы, операции должны выполняться в правильной последовательности, чтобы быть выполненными правильно.
Race condition — это недостаток, связанный с синхронизацией или упорядочением событий, что приводит к ошибочному поведению программы.
Но мне нравиться наиболее короткое и простое:
Race condition — это недостаток, возникающий, когда время или порядок событий влияют на правильность программы.
Важно, что Race condition — это семантическая ошибка.
В проектирование электронных схем есть похожая проблема:
Состязание сигналов — явление в цифровых устройствах несоответствия работы данного устройства с заданным алгоритмом работы по причине возникновения переходных процессов в реальной аппаратуре.
Рассмотрим пример, где результат не определен:
Если запустить такой код много раз, то можно увидеть примерно такое:
Результат выполнения кода зависит от порядка выполнения горутин. Это типичная ошибка race condition. Ситуации могут быть гораздо сложней и не очевидней.
Учитывая, что race condition семантическая ошибка, нет общего способа который может отличить правильное и неправильное поведение программы в общем случае.
Помочь могут хорошие практики и проверенные паттерны.
В результате на консоле получим четные и нечетные числа, а расчитывали увидеть только четные.
Проблемы с доступом к общим ресурсам проще обнаружить автоматически и решаются они обычно с помощью синхронизации:
или локальной копией:
Data Race
Data race это состояние когда разные потоки обращаются к одной ячейке памяти без какой-либо синхронизации и как минимум один из потоков осуществляет запись.
Пример с балансом на счету:
Запускаем в разных горутинах:
Изначально баланс равен 0, депозитим 1000 раз по 1. Ожидаем баланс равный 1000, но результат другой:
Потеряли много денег.
Причина в том, что операция acc.balance += amount не атомарная. Она может разложиться на 3:
Пока мы меняем временную переменную в одном потоке, в других уже изменен основной balance. Таким образом теряется часть изменений.
Например, у нас 2 параллельных потока выполнения, каждый должен прибавить к балансу по 1:
Ожидали получить баланс=102, а получили = 101.
У Data Race есть точное определение, которое не обязательно связано с корректностью, и поэтому их можно обнаружить. Существует множество разновидностей детекторов гонки данных (статическое/динамическое обнаружение, обнаружение на основе блокировок, обнаружение основанное на предшествующих событий, обнаружение гибридного data race).
У Go есть хороший Data Race Detector с помощью которого такие ошибки можно обнаружить.
Решается проблема с помощью синхронизации:
Race Condition и Data Race

Функция для перевода средств с одного счета на другой:
На одном счету у нас будет 1000, а на другом 0. Переводим по 1 в 1000 горутинах и ожидаем, что все деньги из одного счета перетекут в другой:
Но результат может быть таким:
Если запустить цикл на большее кол-во операций, то можно получить еще интересней:
При вызове из нескольких потоков без внешней синхронизации эта функция допускает как dara race (несколько потоков могут одновременно пытаться обновить баланс счета), так и race condition (в параллельном контексте это приведет к потере денег).
Для решения можно применить синхронизацию и локальную копию. Общая логика может быть не такой линейной и в итоге код может выглядит например так:
У нас синхронизированы все участки с записью и чтением, у нас есть локальная копия, Race Detector больше не ругается на код. Запускаем 1000 операций и получаем верный результат:
Но что если горутин будет 10к:
Мы решили проблему data race, но race condition остался. В данном случае можно сделать блокировку на всю логику перевода средств, но это не всегда возможно.
Решив Data Race через синхронизацию доступа к памяти (блокировки) не всегда решается race condition и logical correctness.
Термин « состояние гонки» уже использовался к 1954 году, например, в докторской диссертации Дэвида А. Хаффмана «Синтез схем последовательного переключения».
СОДЕРЖАНИЕ
В электронике
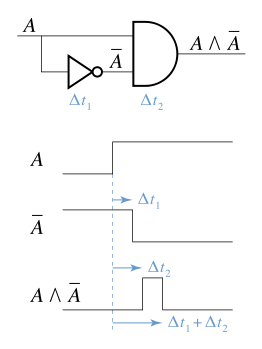
Типичный пример состояния гонки может возникнуть, когда логический вентиль объединяет сигналы, которые прошли по разным путям от одного и того же источника. Входы в вентиль могут изменяться в несколько разное время в ответ на изменение исходного сигнала. Выход может на короткое время перейти в нежелательное состояние, прежде чем вернуться в расчетное состояние. Некоторые системы могут допускать такие сбои, но если этот выходной сигнал функционирует как тактовый сигнал для других систем, которые, например, содержат память, система может быстро отклониться от запланированного поведения (фактически, временный сбой становится постоянным сбоем).
Рассмотрим, например, двухвходовой логический элемент И, работающий по следующей логике:
о ты т п ты т знак равно А ∧ А ¯ <\ displaystyle output = A \ wedge <\ overline >>

Критические и некритические формы
Статические, динамические и существенные формы
Состояние статической гонки возникает при объединении сигнала и его дополнения.
Состояние динамической гонки возникает, когда оно приводит к нескольким переходам, когда предназначен только один. Они связаны с взаимодействием ворот. Устранить ее можно, используя не более двух уровней стробирования.
Обходные пути
В программном обеспечении
Состояние гонки может быть трудно воспроизвести и отладить, потому что конечный результат недетерминирован и зависит от относительного времени между мешающими потоками. Поэтому проблемы такого характера могут исчезнуть при работе в режиме отладки, добавлении дополнительных журналов или подключении отладчика. Ошибка, которая исчезает таким образом во время попыток отладки, часто называется « Heisenbug ». Поэтому лучше избегать условий гонки за счет тщательного проектирования программного обеспечения.
Пример
Предположим, что каждый из двух потоков увеличивает значение глобальной целочисленной переменной на 1. В идеале должна выполняться следующая последовательность операций:
| Поток 1 | Поток 2 | Целочисленное значение |
|---|---|---|
| 0 | ||
| прочитать значение | ← | 0 |
| увеличить стоимость | 0 | |
| написать ответ | → | 1 |
| прочитать значение | ← | 1 |
| увеличить стоимость | 1 | |
| написать ответ | → | 2 |
В случае, показанном выше, окончательное значение равно 2, как и ожидалось. Однако, если два потока выполняются одновременно без блокировки или синхронизации, результат операции может быть неверным. Альтернативная последовательность операций ниже демонстрирует этот сценарий:
| Поток 1 | Поток 2 | Целочисленное значение |
|---|---|---|
| 0 | ||
| прочитать значение | ← | 0 |
| прочитать значение | ← | 0 |
| увеличить стоимость | 0 | |
| увеличить стоимость | 0 | |
| написать ответ | → | 1 |
| написать ответ | → | 1 |
Гонка данных
Это может быть опасно, потому что на многих платформах, если два потока записывают в ячейку памяти одновременно, это может оказаться возможным для этой ячейки памяти в конечном итоге содержать значение, которое представляет собой произвольную и бессмысленную комбинацию битов, представляющих значения, которые каждый поток пытался писать; это может привести к повреждению памяти, если результирующее значение будет таким, которое ни один поток не пытался записать (иногда это называется « разорванной записью »). Точно так же, если один поток читает из местоположения, в то время как другой поток записывает в него, для чтения может быть возможно вернуть значение, которое представляет собой некоторую произвольную и бессмысленную комбинацию битов, представляющих значение, которое ячейка памяти хранила до записи, и битов, представляющих записываемое значение.
Примеры определений гонок данных в конкретных моделях параллелизма
Точное определение гонки данных различается в разных формальных моделях параллелизма. Это важно, потому что параллельное поведение часто не интуитивно понятно, и поэтому иногда применяется формальное рассуждение.
Стандарт C ++ в проекте N4296 (2014-11-19) определяет гонку данных следующим образом в разделе 1.10.23 (стр. 14).
Два действия потенциально могут быть одновременными, если
Выполнение программы содержит гонку данных, если она содержит два потенциально одновременных конфликтующих действия, по крайней мере одно из которых не является атомарным, и ни одно из них не происходит раньше другого, за исключением особого случая для обработчиков сигналов, описанного ниже [опущено]. Любая такая гонка данных приводит к неопределенному поведению.
В статье « Обнаружение гонки данных в системах со слабой памятью» дается другое определение:
Отношение hb1 определено в другом месте статьи и является примером типичного отношения «произошло до »; интуитивно, если мы можем доказать, что мы находимся в ситуации, когда одна операция памяти X гарантированно будет выполнена до завершения до начала другой операции памяти Y, тогда мы скажем, что «X происходит до Y». Если ни «X происходит до Y», ни «Y происходит до X», то мы говорим, что X и Y «не упорядочены отношением hb1». Таким образом, предложение «. и они не упорядочены отношением исполнения hb1» можно интуитивно перевести как «. и X и Y потенциально параллельны».
В статье опасными считаются только те ситуации, в которых хотя бы одна из операций с памятью является «операцией с данными»; в других частях этого документа также определяется класс « операций синхронизации », которые безопасны для потенциально одновременного использования, в отличие от «операций с данными».
Спецификация языка Java обеспечивает другое определение:
SC для DRF
Важным аспектом гонок данных является то, что в некоторых контекстах программа, свободная от гонок данных, гарантированно выполняется последовательно согласованным образом, что значительно упрощает рассуждения о параллельном поведении программы. Говорят, что формальные модели памяти, которые обеспечивают такую гарантию, демонстрируют свойство «SC for DRF» (Последовательная согласованность для свободы от гонки данных). Утверждается, что этот подход недавно достиг консенсуса (по-видимому, по сравнению с подходами, которые гарантируют последовательную согласованность во всех случаях, или подходами, которые не гарантируют его вообще).
Например, в Java эта гарантия прямо указывается:
Программа правильно синхронизируется тогда и только тогда, когда все последовательно согласованные исполнения свободны от гонок данных.
Если программа правильно синхронизирована, то все выполнения программы будут выглядеть последовательно согласованными (§17.4.3).
Это очень сильная гарантия для программистов. Программистам не нужно рассуждать о переупорядочивании, чтобы определить, что их код содержит гонки данных. Поэтому им не нужно рассуждать о переупорядочивании, чтобы определить, правильно ли синхронизирован их код. Как только будет установлено, что код правильно синхронизирован, программисту не нужно беспокоиться о том, что изменение порядка повлияет на его или ее код.
Программа должна быть правильно синхронизирована, чтобы избежать противоречивого поведения, которое может наблюдаться при изменении порядка кода. Использование правильной синхронизации не гарантирует правильного поведения программы в целом. Однако его использование позволяет программисту просто рассуждать о возможном поведении программы; поведение правильно синхронизированной программы гораздо меньше зависит от возможных переупорядочений. Без правильной синхронизации возможно очень странное, сбивающее с толку и противоречащее интуиции поведение.
Напротив, черновик спецификации C ++ напрямую не требует SC для свойства DRF, а просто отмечает, что существует теорема, обеспечивающая его:
[Примечание: можно показать, что программы, которые правильно используют операции мьютексов и memory_order_seq_cst для предотвращения всех гонок данных и не используют никаких других операций синхронизации, ведут себя так, как если бы операции, выполняемые их составляющими потоками, просто чередовались, с вычислением каждого значения объекта. от последнего побочного эффекта этого объекта в этом чередовании. Обычно это называют «последовательной согласованностью». Однако это относится только к программам без гонки данных, а программы без гонки данных не могут наблюдать большинство программных преобразований, которые не изменяют семантику однопоточной программы. Фактически, большинство однопоточных программных преобразований по-прежнему разрешены, поскольку любая программа, которая в результате ведет себя иначе, должна выполнять неопределенную операцию.
Обратите внимание, что черновик спецификации C ++ допускает возможность программ, которые действительны, но используют операции синхронизации с memory_order, отличным от memory_order_seq_cst, и в этом случае результатом может быть программа, которая является правильной, но для которой не предоставляется гарантия последовательной согласованности. Другими словами, в C ++ некоторые правильные программы не являются последовательными. Считается, что этот подход дает программистам на C ++ свободу выбора более быстрого выполнения программы за счет отказа от простоты рассуждений о своей программе.
Существуют различные теоремы, часто предоставляемые в форме моделей памяти, которые обеспечивают SC для DRF-гарантий в различных контекстах. Предпосылки этих теорем обычно накладывают ограничения как на модель памяти (и, следовательно, на реализацию), так и на программиста; иными словами, как правило, это тот случай, когда есть программы, которые не соответствуют предпосылкам теоремы и которые не могут гарантировать последовательное последовательное выполнение.
Модель памяти DRF1 предоставляет SC для DRF и позволяет оптимизировать WO (слабый порядок), RCsc (согласованность выпуска с последовательно согласованными специальными операциями), модель памяти VAX и модели памяти без гонки данных-0. Модель памяти PLpc обеспечивает SC для DRF и позволяет оптимизировать модели TSO ( Total Store Order ), PSO, PC ( Processor Consistency ) и RCpc ( Release Consistency with processor consistency special operations). DRFrlx предоставляет набросок SC для теоремы DRF в присутствии релаксированной атомики.
Компьютерная безопасность
Файловые системы
Две или более программы могут столкнуться при попытках изменить или получить доступ к файловой системе, что может привести к повреждению данных или повышению привилегий. Блокировка файлов представляет собой широко используемое решение. Более громоздкое решение включает организацию системы таким образом, чтобы один уникальный процесс (запускающий демон и т.п.) имел монопольный доступ к файлу, а все другие процессы, которым необходим доступ к данным в этом файле, делали это только через межпроцессное взаимодействие. с этим одним процессом. Это требует синхронизации на уровне процесса.
Жизненно важные системы
Инструменты
Инструменты динамического анализа включают:
Существует несколько тестов, предназначенных для оценки эффективности инструментов обнаружения гонки данных.
В других сферах
Нейробиология демонстрирует, что расовые состояния могут возникать и в мозге млекопитающих (крыс).
Race conditon в веб-приложениях
Многие недооценивают такую уязвимость, как race condition. А также неправильно ее эксплуатируют. Автор расскажет как и с чем ее готовить.

При написании программ человек берет простейшие алгоритмы, которые он объединяет в единый сюжет, что и будет являться сценарием программы. Предположим, задача программиста — написать логику переводов денег (баллов, кредитов) от одного человека к другому в веб-приложении. Руководствуясь логикой можно составить алгоритм, состоящий из нескольких проверок.
Вася хочет перевести 100 долларов, которые есть у него на счету, Пете. Он переходит на вкладку переводов, вбивает Петин ник и в поле с количеством средств, которые необходимо перевести — цифру 100. Далее, нажимает на кнопку перевода. Данные кому и сколько отправляются на веб-приложение. Что может происходить внутри? Что необходимо сделать программисту, чтобы все работало корректно?
● Убедиться, что у Васи достаточно денег на счету
Нужно убедиться, что сумма доступна Васе для перевода. Необходимо получить значение текущего баланса пользователя, если оно меньше чем сумма, которую он хочет перевести — сказать ему об этом. С учетом того, что на нашем сайте не предусмотрены кредиты и в минус баланс уйти не должен.
● Вычесть сумму, которую необходимо перевести из баланса пользователя
Необходимо записать в значение баланса текущего пользователя его баланс с вычетом переводимой суммы. Было 100, стало 100-100=0.
● Добавить к балансу пользователя Петя сумму которую перевели.
Пете наоборот, было 0, стало 0+100=100.
● Вывести сообщение пользователю, что он молодец!
У нас получается примерно такой псевдокод:
Если (Вася.баланс >= сумма_перевода) То
Но всё бы ничего, если бы все происходило в одном потоке. Тогда бы все запросы выполнялись друг за другом. Но так как сайт может обслуживать одновременно множество пользователей, это все происходит не в одном потоке, потому что современные веб-приложения используют многопроцессорность и многопоточность для параллельной обработки данных. С появлением многопоточности у программ появилась забавная архитектурная уязвимость — состояние гонки (или race condition). А теперь представим, что наш алгоритм срабатывает одновременно 3 раза.
У Васи все так же 100 баксов на балансе, только вот каким-то образом он обратился к веб-приложению тремя потоками одновременно (с минимальным количеством времени между запросами). Все три потока проверяют, существует ли пользователь Петя, и проверяют, достаточно ли баланса у Васи для перевода. В тот момент времени, когда алгоритм проверяет баланс, он всё еще равен 100. Как только проверка пройдена, из текущего баланса 3 раза вычитается 100, и добавляется Пете.

Также race condition применяется, например, для повышения привилегий в операционных системах.
Типичная гонка
Что там на сервере
Каждый поток устанавливает TCP соединение, отправляет данные, ждет ответа, закрывает соединение, открывает снова, отправляет данные и так далее. На первый взгляд, все данные отправляются одновременно, но сами HTTP-запросы могут приходить не синхронно и в разнобой из-за особенностей транспортного уровня, необходимости устанавливать защищенное соединение (HTTPS) и резолвить DNS (не в случае с burp’ом) и множества слоёв абстракций, которые проходят данные до отправки в сетевое устройство. Когда речь идет о миллисекундах, это может сыграть ключевую роль.
Конвейерная обработка HTTP
На самом деле использовать linux необходимо по многим причинам, ведь там более современный стек TCP/IP, который поддерживается ядрами операционной системы. Сервер скорее всего тоже на нем.
Например, выполни команду nc google.com 80 и вставь туда строки
Таким образом, в рамках одного соединения будет отправлено три HTTP-запроса, и ты получишь три HTTP ответа. Эту особенность можно использовать для минимизации времени между запросами.
Что там на сервере
Веб-сервер получит запросы последовательно (ключевое слово), и обработает ответы в порядке очереди. Эту особенность можно использовать для атаки в несколько шагов (когда необходимо последовательно выполнить два действия в минимальное количество времени) или, например, для замедления работы сервера в первом запросе, чтобы увеличить успешность атаки*.
Разбиение HTTP-запроса на две части
Для начала вспомни как формируется HTTP-запрос.
Ну как ты знаешь, первая строка это метод, путь и версия протокола:
Второй и последующий это заголовки и их содержимое
Но как веб-сервер узнает, что HTTP-запрос закончился?
Давай рассмотрим на примере, введи nc google.com 80, а там
после того, как нажмешь ENTER, ничего не произойдет. Нажмешь еще раз — увидишь ответ.
GET / HTTP/1.1\r\nHost: google.com\r\n\r\n
Если бы это был метод POST (не забываем про Content-Length), то корректный HTTP-запрос был бы таким:
Или POST / HTTP/1.1\r\nHost: google.com\r\nContent-Length: 3\r\na=1\r\n\r\n
Попробуй отправить подобный запрос из командной строки:
В итоге ты получишь ответ, так как наш HTTP-запрос полноценный. Но если ты уберешь последний символ \n, то ответа не получишь.
На самом деле многим веб-серверам достаточно использовать в качестве переноса \n, поэтому важно не менять местами \r и \n, иначе дальнейшие трюки могут не получиться.
Что это дает? Ты можешь одновременно открыть множество соединений на ресурс, отправить 99% своего HTTP-запроса и оставив неотправленным последний байт. Сервер будет ждать пока ты не дошлёшь последний символ перевода строки. После того, как будет ясно, что основная часть данных отправлена — дослать последний байт (или несколько).
Это особенно важно, если речь идет о большом POST-запросе, например, когда необходима заливка файла. Но и даже в небольшом запросе это имеет смысл, так как доставить несколько байт намного быстрее, чем одновременно килобайты информации.
Задержка перед отправкой второй части запроса
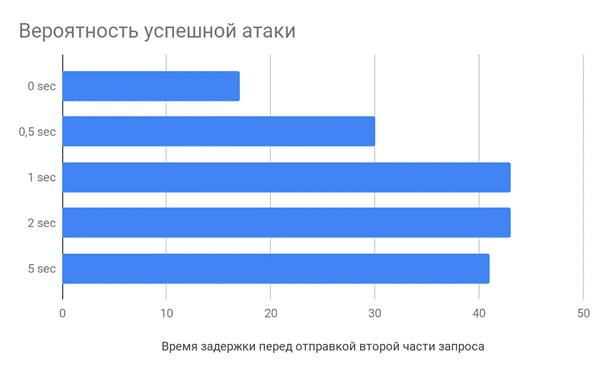
Что там на сервере
Например nginx при получении заголовков HTTP-запроса начнет их парсить, складывая неполноценный запрос в кэш. Когда придет последний байт — веб-сервер возьмет частично обработанный запрос и отправит его уже непосредственно приложению, тем самым сокращается время обработки запросов, что повышает вероятность атаки.
Кстати, как с этим бороться
В первую очередь это конечно же архитектурная проблема, если правильно спроектировать веб-приложение, можно избежать подобных гонок.
Обычно, применяют следующие методы борьбы с атакой:
Операция блокирует в СУБД обращения к заблокированному объекту, пока его не разблокируют. Другие стоят и ждут в сторонке. Необходимо правильно работать с блокировками, не блокировать ничего лишнего.
Берут какую-нибудь штуку (например etcd). В момент вызова функций создают запись с ключем, если не получилось создать запись, значит она уже есть и тогда запрос прерывается. По окончании обработки запроса запись удаляется.
И вообще мне понравилось видео выступления Ивана Работяги про блокировки и транзакции, очень познавательно.
Особенности сессий в race condition
Одна из особенностей сессий может быть то, что она сама по-себе мешает эксплуатировать гонку. Например, в языке PHP после session_start() происходит блокировка сессионного файла, и его разблокировка наступит только по окончанию работы сценария (если не было вызова session_write_close ). Если в этот момент вызван другой сценарий который использует сессию, он будет ждать.
Для обхода этой особенности можно использовать простой трюк — выполнить аутентификацию нужное количество раз. Если веб-приложение разрешает создавать множество сессий для одного пользователя, просто собираем все PHPSESSID и делаем каждому запросу свой идентификатор.
Близость к серверу
Если сайт, на котором необходимо эксплуатировать race condition хостится в AWS — возьми тачку в AWS. Если в DigitalOcean — бери там.
Когда задача отправить запросы и минимизировать промежуток отправки между ними, непосредственная близость к веб-серверу несомненно будет плюсом.
Ведь есть разница, когда ping к серверу 200 и 10 мс. А если повезет, вы вообще можете оказаться на одном физическом сервере, тогда зарейсить будет немного проще 🙂
Для успешного race condition можно применять различные трюки для увеличения вероятности успеха. Отправлять несколько запросов (keep-alive) в одном, замедляя веб-сервер. Разбивать запрос на несколько частей и создавать задержку перед отправкой. Уменьшать расстояние до сервера и количество абстракций до сетевого интерфейса.
В результате этого анализа мы вместе с Michail Badin разработали инструмент RacePWN
Он состоит из двух компонентов:
Библиотеки librace на языке C, которая за минимальное время и используя большинство фишек из статьи отправляет множество HTTP-запросов на сервер
Утилиты racepwn, которая принимает на вход json-конфигурацию и вообще рулит этой библиотекой
RacePWN можно интегрировать в другие утилиты (например в Burp Suite), или создать веб-интерфейс для управления рейсами (все никак руки не доходят). Enjoy!
Но на самом деле ещё есть куда расти и можно вспомнить о HTTP/2 и его перспективы для атаки. Но в данный момент HTTP/2 у большинство ресурсов лишь фронт, проксирующий запросы в старый-добрый HTTP/1.1.



