Обзор нативных библиотек API
В большей части этого курса мы сосредоточились на REST API. В этом разделе мы рассмотрим API-интерфейсы нативных библиотек, которые более распространены при создании нативных приложений, которые устанавливаются на устройства (например, устройства Android или iOS). Понимание API-интерфейсов нативных библиотек также поможет выяснить, чем же отличаются API-интерфейсы REST.
Характеристики нативных библиотек API
Нативные библиотеки API-интерфейсы (также называемые API на основе классов или просто API) заметно отличаются следующим:
В этом модуле сосредоточимся на Java API, потому что они, являются одними из самых распространенных. Однако многие из упомянутых здесь концепций и соглашений о коде могут применяться и к другим языкам с небольшими отличиями.
Нужно ли быть программистом для документирования нативных библиотек API
Тем не менее, техническому писателю не нужно быть программистом. Просто нужно минимальное понимание языка. Технические писатели могут внести здесь большой вклад в отношении стиля, последовательности, ясности, маркировки и общего профессионализма.
Подход автора к преподаванию нативной библиотеки API
Существует множество книг и онлайн-ресурсов, с которыми вы можете ознакомиться, чтобы выучить определенный язык программирования. В этом модуле курса не будет попыток всестороннего изучения Java. Однако, чтобы немного понять документацию по API Java (которая использует генератор документов под названием Javadoc ), понадобится некоторое понимание Java.
Чтобы сосредоточиться на документации API, мы будем ориентироваться на документацию при изучении Java. Изучим различные части Java, просмотрев конкретный файл Javadoc и разобрав основные компоненты.
Что нужно установить
Java Development Kit (JDK)
Сначала проверим, не установлена ли уже JDK на компьютере:
Если JDK установлена, то увидим примерно такое сообщение:
Если JDK не установлен, можно скачать JDK здесь. Надо нажать кнопку Java и выбрать соответствующую загрузку для компьютера.
Eclipse IDE for Java Developers

Чтобы убедиться, что Eclipse настроен для использования версии 1.8, перейдите в Eclipse> Preferences, а затем Java> Installed JREs.
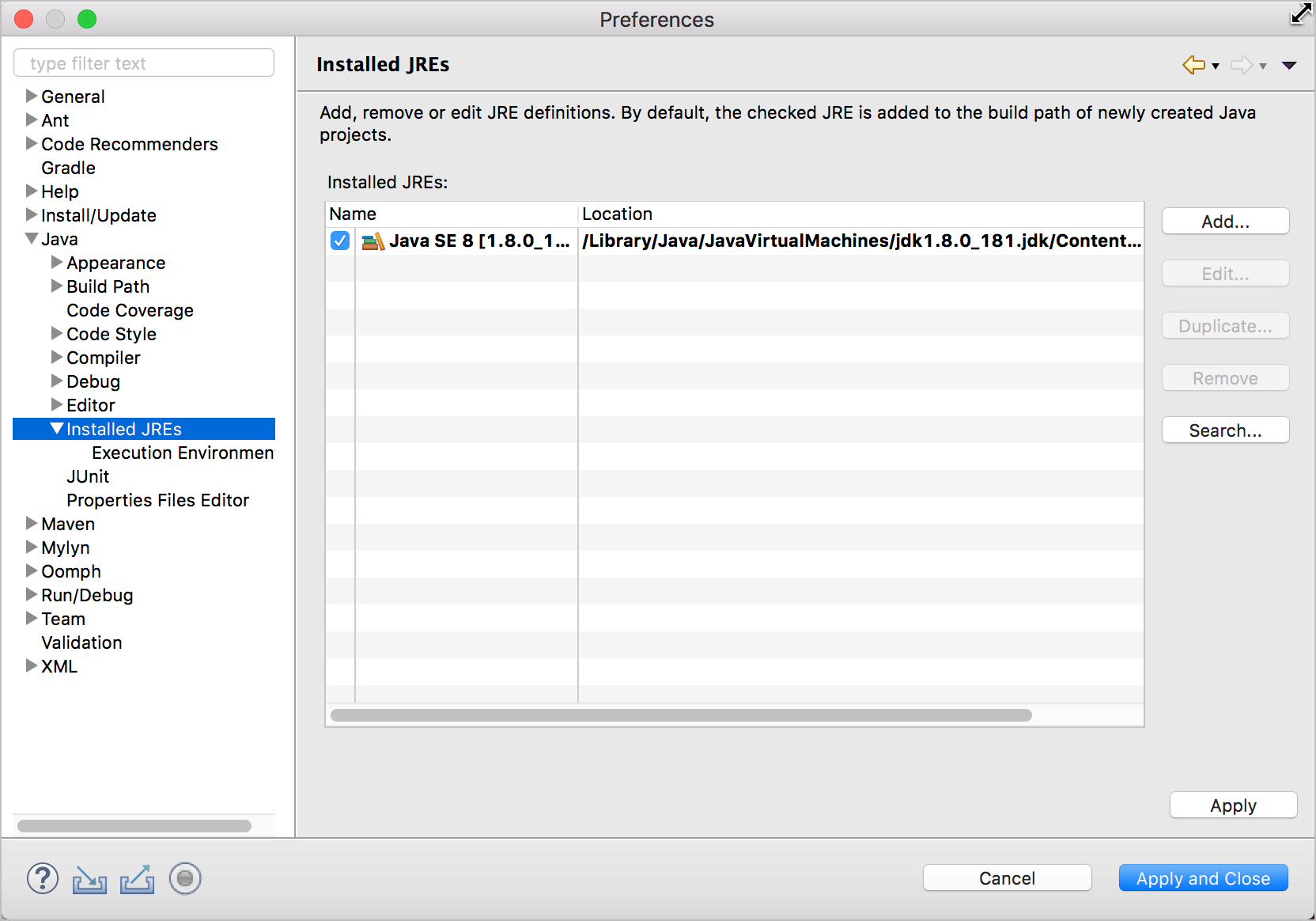
Если 1.8 не выбран, переходим в каталог установки (На MacOS это /Library/Java/JavaVirtualMachines/jdk1.8.0_171.jdk/Contents/Home ) и выбираем ее.
Поскольку мы будем использовать Java только в контексте Eclipse, пользователям Windows не нужно добавлять Java в их путь к классам. Но если нужно иметь возможность компилировать Java из командной строки, тогда это нужно сделать.
Мобильная разработка: Cross-platform или Native
Всем привет! Я Игорь Веденеев, руководитель мобильной разработки в AGIMA. Поговорим немного о нативной и кроссплатформенной разработке. Раньше я по большей части скептически относился ко второй: не устраивало качество конечных приложений в первую очередь. Однако за последний год темпы развития кроссплатформенных фреймворков уже не в первый раз заставляют пересмотреть свое мнение насчет такого подхода. Поэтому давайте еще раз сравним самые популярные кроссплатформенные решения и нативную разработку.

На всякий случай
Если вы не знаете, что такое нативная и кроссплатформенная разработка:
нативная разработка (2 независимых приложения на языках Swift и Kotlin);
кроссплатформенная разработка — общая кодовая база для iOS и Android (с применением фреймворков Flutter или React Native (далее RN)).
У каждого способа есть свои особенности, плюсы и минусы. Соответственно, под каждый конкретный проект и каждую конкретную цель подходит какой-то один из них. Сейчас объясню, как выбрать и на что обращать внимание.
Нативная разработка
Нативная разработка — это классический способ создания приложения для iOS и Android. Ведется она с использованием инструментов и языков программирования, предложенных вендорами — Apple и Google. Языки в данном случае — Swift (iOS) и Kotlin (Android), а инструментов для профилирования и отладки в нативной разработке очень много.
Однако мы должны понимать, что в данном случае мы делаем два независимых приложения. Разрабатываются они параллельно. Каждое приложение может реализовать фичу по-своему, и у каждого могут быть свои баги. И самое главное, нативная разработка никуда не денется: пока существуют iOS и Android, Apple и Google будут предоставлять инструментарий для создания приложений.
Нативная разработка позволяет создать самое качественное и функциональное приложение, но взамен придется разрабатывать и отлаживать всё 2 раза и следить, чтобы приложения соответствовали друг другу функционально.
Среди разработчиков это пока самый популярный способ создания приложений. Поэтому собрать команду, даже большую, в этом случае проще, чем для кроссплатформы. В первую очередь из-за количества предложений на рынке.
Плюсы и минусы нативной разработки
2 независимых приложения
Стоимость разработки и отладки
Меньше потребляемых ресурсов*
Богатый инструментарий для разработки
Широкий рынок разработчиков
Кроссплатформенная разработка
Кроссплатформенная разработка подразумевает, что мы используем один и тот же код и на iOS, и на Android. Вообще говоря, это всё такое же нативное приложение, но, запустив его, мы сразу проваливаемся в мир Flutter или RN, и всё происходит уже там. Стоит отметить, что разработка на Flutter/RN идет быстрее. Причем не только за счет того, что мы делаем 1 приложение вместо 2-х, а еще и за счет концепций создания приложений, в частности UI.
Но, увы, не всё так хорошо: кроссплатформа имеет ряд проблем, на которые стоит обратить внимание, прежде чем выбирать этот подход для своего приложения. React Native и Flutter всё же сторонние Open Source-решения. В них могут встречаться баги. Новые фишки iOS и Android там будут появляться не так быстро, как при нативных решениях. Может прекратиться поддержка, в конце концов.
Также, довольно часто придется полагаться на сторонние Open Source-библиотеки, что тоже несет в себе риски потенциальных проблем: например, совместимость версии Flutter/RN. Не исключен вариант, что нужной библиотеки не существует в природе, и тогда придется реализовывать всё с нуля самому. Также нельзя добавить расширения для iOS-приложений или, например, приложение на часы. Это касается и Flutter, и RN.
То есть для реализации определенных фич придется добавлять нативный код, что приведет к смешению технологий. Как минимум надо будет иметь в них компетенции. Как максимум — организовывать передачу данных из нативного кода в кроссплатформенный и наоборот.
Если в приложении много логики и есть необходимость сделать ее многопоточной, это тоже будет проблемой и во Flutter, и в RN. Это возможно, но, скажем, это не то, для чего были предназначены эти фреймворки. Также каждый из фреймворков имеет достаточно тяжелую исполнительную среду, что делает кроссплатформенные приложения более ресурсоемкими и требовательными к процессору/оперативке телефона.
Если приложение подразумевает обширное использование аппаратных возможностей телефона, взаимодействия с ОС, то я бы тоже не рекомендовал использовать кроссплатформу — есть риск, что в какой-то момент или код станет очень запутанным, или мы упремся в ограничения одной из платформ или самого фреймворка. Еще стоит учесть, что нам стоит использовать платформенно нейтральный UI, чтобы не создавать потенциальных проблем с различным поведением на платформах и в принципе не снижать на этом скорость разработки.
На картинке ниже представлены результаты теста с простым списком с изображениями: видим, что нативное приложение выигрывает вчистую. Да, на более новых моделях телефонов разница будет не такой значительной, но тенденцию можно видеть. Результаты остальных тестов тут.
Если проще, то кроссплатформа позволяет разработать приложение в кратчайшие сроки. Лучше всего подходит для приложений-витрин услуг или товаров среднего/малого объема без обширного использования платформенных возможностей. То есть снять фотку на аватар или отсканировать QR-код не составит больших проблем, но, если вы делаете приложение вокруг камеры, лучше рассмотреть нативную разработку.
Плюсы и минусы кроссплатформенной разработки
.NET-обёртки нативных библиотек на C++/CLI
Содержание
Создание обёрток для нативных библиотек
Прежде, чем начать
Отдельная DLL или интеграция в проект нативной библиотеки?
Проекты Visual C++ могут содержать файлы, компилируемые в управляемый код [подробнее можно прочитать в главе 7 книги]. Интеграция обёрток в нативную библиотеку может показаться хорошей затеей, потому что тогда у вас будет на одну библиотеку меньше. Кроме того, если вы интегрируется обёртки в DLL, то клиентском приложению не придётся загружать лишнюю динамическую библиотеку. Чем меньше загружается DLL, тем меньше время загрузки, требуется меньше виртуальной памяти, меньше вероятность, что библиотека будет перемещена в памяти из-за невозможности её загрузить по изначальному базовому адресу.
Тем не менее, включение обёрток в оборачиваемую библиотеку как правило не несёт пользы. Чтобы лучше понять почему, следует отдельно рассмотреть сборку статической библиотеки и DLL.
Как бы странно это не звучало, но управляемые типы можно включить в статическую библиотеку. Однако это легко может повлечь за собой проблемы идентичности типов. Сборка, в которой определён тип, является частью его идентификатора. Таким образом, CLR может различить два типа из разных сборок, даже если имена типов совпадают. Если два разных проекта использую один и тот же управляемый тип из статической библиотеки, то этот тип будет скомпонован в обе сборки. Так как сборка является частью идентификатора типа, то получится два типа с разными идентификаторами, хотя они и были определены в одной статической библиотеке.
Интеграция управляемых типов в нативную DLL также не рекомендуется, так как загрузка библиотеки потребует CLR 2.0 во времени загрузки. Даже если приложение, использующее библиотеку, обращается только к нативному коду, для загрузки библиотеки потребуется, чтобы на компьютере была установлена CLR 2.0, и чтобы приложение не загружало более раннюю версию CLR.
Какая часть нативной библиотеки должна быть доступна через обёртку?
Как это часто бывает, очень полезно чётко определить задачи разработчика, прежде чем начинать писать код. Знаю, это звучит как цитата из второсортной книженции о разработке программ из начала 90х, но для обёрток нативных библиотек постановка задачи особенно важна.
Когда вы приступаете к созданию обёртки для нативной библиотеки, задача кажется очевидной — у вас уже есть существующая библиотека и управляемое API должно принести её функциональность в мир управляемого кода.
Для большинства проектов такого общего описания совершенно недостаточно. Без более чёткого понимания проблемы вы, вероятно, напишете по обёртке для каждого нативного класса C++ библиотеки. Если библиотека содержит больше одной единственной центральной абстракции, то зачастую не стоит создавать обёртки один-к-одному с нативным кодом. Это заставит вас решать проблемы, не связанные с вашей конкретной задачей, а также породит много неиспользованного кода.
Чтобы лучше описать задачу, подумайте над проблемой в целом. Чтобы сформулировать задачу более чётко, вам надо ответить на два вопроса:
Это API даёт программисту следующие возможности:
Однако весьма вероятно, что обёртка нужна только для одного или двух алгоритмов. Если обёртка для этого API не будет поддерживать наследование, то её создание упрощается. С таким упрощением вам не придётся создавать обёртку для абстрактного класса CryptoAlgorithm. С виртуальными методами Encrypt и Decrypt можно будет работать так же, как и с любыми другими. Чтобы дать понять, что вы не хотите поддерживать наследование, достаточно объявить обёртки для SampleCipher и AnotherCipherAlgorithm как sealed классы.
Взаимодействие языков
Можно использовать атрибут CLSCompliantAttribute, чтобы обозначить тип или его член как соответствующий CLS. По умолчанию, не помеченные этим атрибутом типы считаются не соответствующими CLS. Если вы примените этот атрибут на уровне сборки, то по умолчанию все типы будут считаться соответствующими CLS. Следующий пример показывает, как применять этот атрибут к сборкам и типам:
Согласно правилу 11 CLS все типы, присутствующие в сигнатурах членов класса (методов, свойств, полей и событий), видимых снаружи сборки, должны соответствовать CLS. Чтобы правильно применять атрибут [CLSCompliant], вы должны знать, соответствуют ли типы параметров метода CLS. Чтобы определить соответствие CLS, надо проверить атрибуты сборки, в которой объявлен тип, а также атрибуты самого типа.
В Framework Class Library (FCL) также используется атрибут CLSCompliant. mscorlib и большинство других библиотек FCL применяют атрибут [CLSCompliant(true)] на уровне сборки и помечают типы, не соответствующие CLS, атрибутом [CLSCompliant(false)].
Учтите, что следующие примитивные типы в mscorlib помечены как несоответствующие CLS: System::SByte, System::UInt16, System::UInt32 и System::UInt64. Эти типы (или эквивалентные им имена типов char, unsigned short, unsigned int, unsigned long и unsigned long long в C++) нельзя использовать в сигнатурах членов типов, которые считаются соответствующими CLS.
Если тип считается соответствующим CLS, то все его члены также считаются таковыми, если явно не указано обратного. Пример:
К сожалению, компилятор C++/CLI не показывает предупреждений, когда тип, помеченный как соответствующий CLS, нарушает правила CLS. Чтобы понять, помечать тип как соответствующий CLS или нет, надо знать следующие важные правила CLS:
В отличие от C#, в C++/CLI допускается явное указание типа упакованного значения. Например:
Создание обёрток для классов C++
Объявить управляемый класс с полем типа NativeLib::SampleCipher нельзя [подробнее можно прочитать в главе 8 книги]. Так как поля управляемых классов могут быть только указателями на нативные типы, следует использовать поле типа NativeLib::SampleCipher*. Экземпляр нативного класса должен быть создан в конструкторе обёртки и уничтожен в деструкторе.
Кроме деструктора, также стоит реализовать финализатор [подробнее можно прочитать в главе 11 книги].
Отображение нативных типов на типы, соответствующие CLS
Если в нативную функцию передаётся ссылка C++ или указатель с семантикой передачи по ссылке, то в обёртке функции рекомендуется использовать отслеживаемую ссылку [см. примечание ниже]. Допустим, нативная функция имеет следующий вид:
Для вызова нативной функции требуется передать нативную ссылку на int. Для этого аргумента необходимо осуществить маршаллинг вручную, так как преобразования типов из отслеживающей ссылки в нативную ссылку не существует. Поскольку существует стандартное преобразование типов из int в int&, используется локальная переменная типа int, которая служит в качестве буфера для аргумента, передаваемого по ссылке. Перед вызовом нативной функции буфер инициализируется значением, переданным в качестве параметра i. После возврата из нативной функции в обёртку значение параметра i обновляется в соответствии с изменениями буфера j.
Как видно из этого примера, помимо затрат на переход между управляемым и нативным кодом, обёртки зачастую вынуждены тратить процессорное время на маршаллинг типов. Как будет показано позже, для более сложных типов эти затраты могут быть значительно выше.
По умолчанию считается, что отслеживающая ссылка означает передачу по ссылке. Если вы хотите, чтобы аргумент использовался только для возврата значения, следует применить атрибут OutAttribute из пространства имён System::Runtime::InteropServices, как показано в следующем примере:
Типы аргументов нативных функций часто содержат модификатор const, как в примере ниже:
Модификатор const транслируется в необязательный модификатор сигнатуры метода [подробнее можно прочитать в главе 8 книги]. Метод fWrapper всё равно можно вызвать из управляемого кода, даже если вызывающая сторона не воспринимает модификатор const:
Для передачи указателя на массив в качестве параметра нативной функции недостаточно просто использовать отслеживающую ссылку. Чтобы разобрать этот случай, предположим, что у нативного класса SampleCipher есть конструктор, который принимает ключ шифрования:
В данном случае недостаточно просто отобразить const unsigned char* в const unsigned char%, потому что ключ шифрования, передаваемый в конструктор нативного типа, содержит более одного байта. Лучшим использовать следующий подход:
В этом конструкторе оба аргумента нативного конструктора (pKey и nKeySizeInBytes) отображаются на единственный аргумент типа управляемый массив. Так можно сделать, потому что размер управляемого массива можно определить во время выполнения.
Как реализовывать этот конструктор, зависит от реализации нативного класса SampleCipher. Если конструктор создаёт внутреннюю копию ключа, переданного в качестве аргумента pKey, то можно передать закрепляющий указатель на ключ:
Этот конструктор требует, чтобы клиент не освобождал память, содержащую ключ, и указатель на ключ оставался корректным пока экземпляр класса SampleCipher не будет уничтожен. Конструктор обёртки не выполняет ни одно из этих требований. Так как обёртка не содержит дескриптора управляемого массива, сборщик мусора может собрать массив раньше, чем экземпляр нативного класса будет уничтожен. Даже если сохранить дескриптор объекта, чтобы память не освобождалась, массив может быть перемещён во время сборки мусора. В этом случае нативный указатель больше не будет указывать на управляемый массив. Чтобы память, содержащая ключ, не освобождалась и не перемещалась при сборке мусора, ключ надо скопировать в нативную кучу.
Для этого надо внести изменения как в конструктор, так и в деструктор управляемой обёртки. Следующий код показывает возможную реализацию конструктора и деструктора:
Если не брать в расчёт некоторые эзотерические проблемы [обсуждаются в главе 11 книги], приведённый здесь код обеспечивает корректное выделение и освобождение ресурсов даже при возникновении исключений. Если при создании экземпляра ManagedWrapper::SampleCipher возникнет ошибка, все выделенные ресурсы будут освобождены. Деструктор реализован таким образом, чтобы освободить нативный массив, содержащий ключ, даже если деструктор оборачиваемого объекта выбросит исключение.
Этот код также показывает характерные накладные расходы управляемых обёрток. Помимо накладных расходов на вызов оборачиваемых нативных функций из управляемого кода, зачастую добавляются накладные расходы на отображение между нативными и управляемыми типами.
Отображение исключений C++ на управляемые исключения
Помимо управления ресурсами, устойчивого к возникновению исключений, управляемая обёртка также должна позаботиться об отображении исключений C++, выбрасываемых нативной библиотекой, в управляемые исключения. Для примера предположим, что алгоритм SampleCipher поддерживает только 128 и 256-битные ключи. Конструктор NativeLib::SampleCipher мог бы выбрасывать исключение NativeLib::CipherException, если в него передан ключ неправильного размера. Исключения C++ отображаются в исключения типа System::Runtime::InteropServices::SEHException, что не очень удобно для потребителя библиотеки [обсуждается в главе 9 книги]. Следовательно, необходимо перехватывать нативные исключения и перебрасывать управляемые исключения, содержащие эквивалентные данные.
Для того, чтобы отобразить исключения конструктора, можно использовать блок try на уровне функции, как показано в следующем примере. Это позволит перехватить исключения, выброшенные как при инициализации членов класса, так и в теле конструктора.
Здесь используется блок try на уровне функции, хотя инициализация членов класса в этом примере и не должна приводить к выбросу исключений. Таким образом исключения будут перехвачены, даже если вы добавите новые члены класса или добавите наследование SampleCipher от другого класса.
Отображение управляемых массивов на нативные типы
Теперь, разобравшись с реализацией конструктора, разберём методы Encrypt и Decrypt. Ранее указание сигнатур этих методов было отложено, теперь приведём их полностью:
Данные, которые должны быть зашифрованы или расшифрованы, передаются при помощи параметров pData и nDataLength. Перед вызовом Encrypt или Decrypt следует выделить буфер памяти. Значение параметра pBuffer должно быть указателем на этот буфер, а его размер должен быть передан в качестве значения параметра nBufferLength. Размер данных на выходе возвращается при помощи параметра nNumEncryptedBytes.
Для отображения Encrypt и Decrypt можно добавить следующий метод в ManagedWrapper::SampleCipher:
Отображение других непримитивных типов
Ранее все типы параметров отображаемых функций были либо примитивными типами, либо указателями или ссылками на примитивные типы. Если вам надо отображать функции, принимающие в качестве параметров классы C++ либо указатели или ссылки на классы C++, то зачастую требуются дополнительные действия. В зависимости от конкретной ситуации, решения могут быть разными. Чтобы показать различные варианты решений на конкретном примере, рассмотрим другой нативный класс, для которого требуется обёртка:
Как можно догадаться о имени этого класса, его назначение — отправлять зашифрованные данные. В рамках дискуссии неважно куда отправляются данные и какой протокол при этом используется. Для шифрования можно использовать классы, наследованные от CryptoAlgorithm (например, SampleCipher). Алгоритм шифрования можно указать при помощи параметра конструктора типа CryptoAlgorithm&. Экземпляр класса CryptoAlgorithm, переданный в конструктор, используется в методе SendData при вызове виртуального метода Encrypt. Следующий пример показывает, как можно использовать EncryptingSender в нативном коде:
Чтобы создать обёртку над NativeLib::EncryptingSender, вы можете определить управляемый класс ManagedWrapper::EncryptingSender. Как и обёртка класса SampleCipher, он должен хранить указатель на обёрнутый объект в поле. Чтобы создать экземпляра оборачиваемого класса EncryptingSender требуется экземпляр класса NativeLib::CryptoAlgorithm. Допустим, единственный алгоритм шифрования, который вы хотите поддерживать, это SampleCipher. Тогда можно определить конструктор, принимающий значение типа array ^ в качестве ключа шифрования. Также, как и конструктор класса ManagedWrapper::SampleCipher, конструктор EncryptingSender может использовать этот массив для создания экземпляра нативного класса NativeLib::SampleCipher. Затем, ссылку на этот объект можно передать в конструктор NativeLib::EncryptingSender:
При таком подходе вам не придётся отображать параметр типа CryptoAlgorithm& на управляемый тип. Однако иногда этот подход слишком ограничен. Например, вы хотите дать возможность передать существующий экземпляр SampleCipher, а не создавать новый. Для этого у конструктора ManagedWrapper::EncryptingSender должен быть параметр типа SampleCipher^. Чтобы создать экземпляр класса NativeLib::EncryptingSender внутри конструктора, надо получить объект класса NativeLib::SampleCipher, который обёрнут в ManagedWrapper::SampleCipher. Для получения обёрнутого объекта требуется добавить новый метод:
Следующий код показывать возможную реализацию такого конструктора:
Пока что эта реализация позволяет передавать только экземпляры класса ManagedWrapper::SampleCipher. Чтобы использовать EncryptingSender с любой реализацией обёртки над CryptoAlgorithm, придётся изменить дизайн таким образом, чтобы реализация GetWrappedObject различными обёртками была полиморфной. Этого можно добиться при помощи управляемого интерфейса:
Для реализации этого интерфейса надо изменить обёртку SampleCipher следующим образом:
Этот метод реализован как internal, потому что код, использующий библиотеку-обёртку, не должен напрямую вызывать методы обёрнутого объекта. Если вы хотите предоставить клиенту доступ непосредственно к обёрнутому объекту, вам следует передавать указатель на него при помощи System::IntPtr, потому что тип System::IntPtr соответствует CLS.
Теперь конструктор класса ManagedWrapper::EncryptingSender принимает параметр типа INativeCryptoAlgorithm^. Чтобы получить объект класса NativeLib::CryptoAlgorithm, необходимый для создания оборачиваемого экземпляра EncryptingSender, можно вызвать метод GetWrappedObject у параметра типа INativeCryptoAlgorithm^:
Поддержка наследования и виртуальных методов
Если вы сделаете обёртки для других алгоритмов шифрования и добавите в них поддержку INativeCryptoAlgorithm, то их тоже можно будет передать в конструктор ManagedWrapper::EncryptingSender. Однако реализовать свой алгоритм шифрования в управляемом коде и передать его в EncryptingSender пока что нельзя. Для этого потребуется сделать доработки, потому что в управляемом классе нельзя просто переопределить виртуальный метод нативного класса. Для этого придётся снова изменить реализацию управляемых классов-обёрток.
На этот раз потребуется абстрактный управляемый класс, который обернёт NativeLib::CryptoAlgorithm. Помимо метода GetWrappedObject, этот класс-обёртка должен предоставлять два абстрактных метода:
Чтобы реализовать свой криптографический алгоритм, надо создать управляемый класс-наследник ManagedWrapper::CryptoAlgorithm и переопределить виртуальные методы Encrypt и Decrypt. Однако этих абстрактных методов недостаточно, чтобы переопределить виртуальные методы NativeLib::CryptoAlgorithm Encrypt и Decrypt. Виртуальные методы нативного класса, в нашем случае, NativeLib::CryptoAlgorithm, можно переопределить только в нативном классе-наследнике. Следовательно, надо создать нативный класс, который наследуется от NativeLib::CryptoAlgorithm и переопределяет требуемые виртуальные методы:
Этот класс назван CryptoAlgorithmProxy, потому что он служит посредником для управляемого класса, реализующего Encrypt и Decrypt. Его реализация виртуальных методов должна вызывать эквивалентные виртуальные методы класса ManagedWrapper::CryptoAlgorithm. Для этого CryptoAlgorithmProxy нужен дескриптор экземпляра класса ManagedWrapper::CryptoAlgorithm. Он может быть передан в качестве параметра конструктора. Чтобы сохранить дескриптор, нужен шаблон gcroot. (Так как CryptoAlgorithmProxy — это нативный класс, он не может содержать полей типа дескриптор.)
Вместо того, чтобы служить обёрткой нативного абстрактного класса CryptoAlgorithm, управляемый класс служит обёрткой для конкретного наследника CryptoAlgorithmProxy. Следующий код показывает, как это сделать:
Как говорилось ранее, класс CryptoAlgorithmProxy должен реализовать виртуальные методы таким образом, чтобы управление передавалось эквивалентным методам ManagedWrapper::CryptoAlgorithm. Следующий код показывает, как CryptoAlgorithmProxy::Encrypt вызывает ManagedWrapper::CryptoAlgorithm::Encrypt:
Общие рекомендации
Упростите обёртки с самого начала
Как видно из предыдущих разделов, создание обёрток для иерархий классов может быть очень трудозатратным. Иногда нужно создавать обёртки классов C++ таким образом, чтобы управляемые классы могли переопределять их виртуальные методы, но зачастую такая реализация не несёт практического смысла. Определение необходимой функциональности — вот ключ к упрощению задачи.
Не нужно заново изобретать колесо. Прежде чем создавать обёртку для некоторой библиотеки, убедитесь, что FCL не содержит готового класса с требуемыми методами. FCL может предложить больше, чем кажется на первый взгляд. Например, BCL уже содержит довольно много алгоритмов шифрования. Они находятся в пространстве имён System::Security::Cryptography. Если нужным вам алгоритм шифрования уже есть в FCL, вам не нужно заново создавать для него обёртку. Если FCL не содержит реализации алгоритма, для которого вы хотите создать обёртку, но приложение не завязано на алгоритм, реализованный в нативном API, то обычно предпочтительней использовать один из стандартных алгоритмов из FCL.
Адаптация к дизайну FCL как правило упрощает библиотеку обёрток с точки зрения потребителя библиотеки. Трудоёмкость этого подхода зависит от дизайна нативного API и дизайна типов FCL, поддержку которых вы хотите реализовать. Приемлемы ли эти дополнительные трудозатраты определяется отдельно в каждом конкретном случае. В этом примере можно предположить, что алгоритм безопасности используется только в одном конкретном случае и, следовательно, не стоит того, чтобы интегрировать его с FCL.
Если библиотека, для которой вы создаёте отображение, управляет табличными данными, следует рассмотреть классы System::Data::DataTable и System::Data::DataSet из части FCL, именуемой ADO.NET. Хотя рассмотрение этих типов и выходит за рамки данного текста, они заслуживают упоминания благодаря своей применимости в создании обёрток.
Заключение
Создание обёртки над нативной библиотекой также предполагает обёртывание нативных ресурсов (например, неуправляемой памяти, необходимой для создания оборачиваемых объектов). Надёжное освобождение ресурсов — это тема для отдельной статьи [рассматривается в главе 11 книги].



