Как устроены хранилища данных: обзор для новичков
Международный рынок гипермасштабируемых дата-центров растет с ежегодными темпами в 11%. Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.
Ключевой фактор, влияющий на оба критерия — системы хранения. Их классификация не ограничивается типами оборудования или брендами. В этой статье мы рассмотрим разновидности хранилищ — блочное, файловое и объектное — и определим, для каких целей подходит каждое из них.
Типы хранилищ и их различия
Хранение на уровне блоков лежит в основе работы традиционного жесткого диска или магнитной ленты. Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD пишет и считывает блоки по адресам на отформатированном диске. Такие СХД используются многими приложениями, например, большинством реляционных СУБД, в списке которых Oracle, DB2 и др. В сетях доступ к блочным хостам организуется за счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
Файловая система — это промежуточное звено между блочной системой хранения и вводом-выводом приложений. Наиболее распространенным примером хранилища файлового типа является NAS. Здесь, данные хранятся как файлы и папки, собранные в иерархическую структуру, и доступны через клиентские интерфейсы по имени, названию каталога и др.

При этом следует отметить, что разделение «SAN — это только сетевые диски, а NAS — сетевая файловая система» искусственно. Когда появился протокол iSCSI, граница между ними начала размываться. Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Что касается объектных хранилищ, то они отличаются от файловых и блочных отсутствием файловой системы. Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Марк Горос (Mark Goros), генеральный директор и соучредитель Carnigo, сравнивает такой способ организации со службой парковки, предполагающей выдачу автомобиля. Вы просто оставляете свою машину парковщику, который увозит её на стояночное место. Когда вы приходите забирать транспорт, то просто показываете талон — вам возвращают автомобиль. Вы не знаете, на каком парковочном месте он стоял.
Большинство объектных хранилищ позволяют прикреплять метаданные к объектам и агрегировать их в контейнеры. Таким образом, каждый объект в системе состоит из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, не ограничивает метаданные атрибутами файлов — здесь их можно настраивать.
/ 1cloud
Применимость систем хранения разных типов
Блочные хранилища
Блочные хранилища обладают набором инструментов, которые обеспечивают повышенную производительность: хост-адаптер шины разгружает процессор и освобождает его ресурсы для выполнения других задач. Поэтому блочные системы хранения часто используются для виртуализации. Также хорошо подходят для работы с базами данных.
Недостатками блочного хранилища являются высокая стоимость и сложность в управлении. Еще один минус блочных хранилищ (который относится и к файловым, о которых далее) — ограниченный объем метаданных. Любую дополнительную информацию приходится обрабатывать на уровне приложений и баз данных.
Файловые хранилища
Среди плюсов файловых хранилищ выделяют простоту. Файлу присваивается имя, он получает метаданные, а затем «находит» себе место в каталогах и подкаталогах. Файловые хранилища обычно дешевле по сравнению с блочными системами, а иерархическая топология удобна при обработке небольших объемов данных. Поэтому с их помощью организуются системы совместного использования файлов и системы локального архивирования.
Пожалуй, основной недостаток файлового хранилища — его «ограниченность». Трудности возникают по мере накопления большого количества данных — находить нужную информацию в куче папок и вложений становится трудно. По этой причине файловые системы не используются в дата-центрах, где важна скорость.
Объектные хранилища
Что касается объектных хранилищ, то они хорошо масштабируются, поэтому способны работать с петабайтами информации. По статистике, объем неструктурированных данных во всем мире достигнет 44 зеттабайт к 2020 году — это в 10 раз больше, чем было в 2013. Объектные хранилища, благодаря своей возможности работать с растущими объемами данных, стали стандартом для большинства из самых популярных сервисов в облаке: от Facebook до DropBox.
Такие хранилища, как Haystack Facebook, ежедневно пополняются 350 млн фотографий и хранят 240 млрд медиафайлов. Общий объем этих данных оценивается в 357 петабайт.
Хранение копий данных — это другая функция, с которой хорошо справляются объектные хранилища. По данным исследований, 70% информации лежит в архиве и редко изменяется. Например, такой информацией могут выступать резервные копии системы, необходимые для аварийного восстановления.
Но недостаточно просто хранить неструктурированные данные, иногда их нужно интерпретировать и организовывать. Файловые системы имеют ограничения в этом плане: управление метаданными, иерархией, резервным копированием — все это становится препятствием. Объектные хранилища оснащены внутренними механизмами для проверки корректности файлов и другими функциями, обеспечивающими доступность данных.
Плоское адресное пространство также выступает преимуществом объектных хранилищ — данные, расположенные на локальном или облачном сервере, извлекаются одинаково просто. Поэтому такие хранилища часто применяются для работы с Big Data и медиа. Например, их используют Netflix и Spotify. Кстати, возможности объектного хранилища сейчас доступны и в сервисе 1cloud.
Благодаря встроенным инструментам защиты данных с помощью объектного хранилища можно создать надежный географически распределенный резервный центр. Его API основан на HTTP, поэтому к нему можно получить доступ, например, через браузер или cURL. Чтобы отправить файл в хранилище объектов из браузера, можно прописать следующее:
После отправки к файлу добавляются необходимые метаданные. Для этого есть такой запрос:
Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него. Эти достоинства — масштабируемость, расширяемость метаданных, высокая скорость доступа к информации — делают объектные системы хранения оптимальным выбором для облачных приложений.
Однако важно помнить, что для некоторых операций, например, работы с транзакционными рабочими нагрузками, эффективность решения уступает блочным хранилищам. А его интеграция может потребовать изменения логики приложения и рабочих процессов.
Как используют объектное хранилище, чтобы обыграть конкурентов
Объектные хранилища — облачный сервис для дешёвого хранения и массовой раздачи информации в больших объёмах. Они нужны в первую очередь разработчикам и легко встраиваются в любое приложение, будь то мобильная игра, видеохостинг или корпоративная система документооборота.
Мы расскажем о том, как клиенты платформы Mail.ru Cloud Solutions (MCS) реально используют объектные хранилища и ставят эту технологию в основу своего конкурентного преимущества. Здесь собраны кейсы Mail.ru Group, а именно ICQ (мессенджер), «Смотри Mail.ru» (персонализированная видеоплатформа), а также других компаний: «Битрикс24» (SaaS для управления бизнесом), Max Group (услуги торгового маркетинга), «Биорг» (умная оцифровка изображений) и Prequel (приложение для смартфона).
В объектные хранилища можно поместить любые данные: аудио- и видеофайлы, документы, бэкапы, фрагменты кода. Хранилище решает две главные задачи: надёжное хранение любого объёма данных и быструю их раздачу любому количеству пользователей. Представьте видеохостинг, который должен «без тормозов» раздавать видео на десятки тысяч одновременных запросов: это идеальная задача для такого хранилища.
Объектное хранилище особенно полезно, когда заранее не знаешь, какой объём хранения понадобится: в него можно поместить сотни петабайт данных в любой момент.
Биллинг хранилищ опирается на реальный объём находящихся в них данных и интенсивность их скачивания, так что оплачиваемые облачные ресурсы утилизированы на 100%. Это делает объектное хранилище мощным инструментом оптимизации расходов и ускорения вывода новых продуктов на рынок.
Стоимость скачивания данных из объектного хранилища различается у разных провайдеров. Приложение Prequel до прихода в MCS хранило данные в хранилище зарубежного провайдера Amazon Web Services (AWS). Переход на MCS, который предлагает скачивание по более низкой стоимости, удешевил раздачу контента.
Сам переход на новое хранилище занял несколько дней. AWS оставили «в резерве»: MCS раздаёт основной трафик, а AWS хранит синхронизированный бэкап.
По закону «О персональных данных» (152-ФЗ) обрабатывать персональные данные следует на территории России. Обработкой данных считаются любые действия с ними, в том числе сбор и хранение. Размещение таких данных в объектном хранилище MCS позволяет компаниям соблюдать требования российского законодательства.
Когда этот закон появился, «Битрикс24» хранили данные у зарубежного провайдера. Для исполнения закона можно было самостоятельно построить инфраструктуру хранения данных. Но это было невыгодно, потому что сервис «Битрикс24» активно рос, пришлось бы постоянно покупать оборудование и самостоятельно его администрировать. Компания решила сосредоточиться на своих продуктах, а не на поддержке инфраструктуры, поэтому перенесла обслуживание российских проектов на платформу MCS.
Возможность быстро получить ИТ-ресурсы в облаке особенно важна для экспериментальных проектов с непредсказуемой нагрузкой — и для стартапов, которые тестируют рынок с помощью MVP, и для R&D-проектов крупных компаний.
Раньше для такого запуска приходилось закупать оборудование, до введения которого в эксплуатацию могли пройти месяцы. Ошибки в объёме закупленных ресурсов было нереально исправить, и внезапный рост базы пользователей и объёма данных мог «завалить» систему под нагрузкой. Теперь в облаке по запросу можно сразу получить нужное количество ресурсов без длительных закупок, а при необходимости менять объём использования.
Создатели видеоплатформы «Смотри Mail.ru» не стали вкладываться в построение собственной инфраструктуры — весь видеоконтент разместили в объектном S3-хранилище MCS. Веб-сайт и мобильные приложения платформы загружают контент для показа в плеере из объектного хранилища.
Характерно, что «Смотри» начали использовать объектное хранилище с самого начала тестирования проекта, но продолжают его использовать по тем же принципам и сейчас, когда аудитория проекта значительно выросла.
Изначальный выбор этого масштабируемого решения избавил проект от замедления работы системы в момент роста проекта и последующего болезненного переезда.
Когда объём хранения постоянно растёт или плохо предсказуем, поддержка собственного хранилища ложится тяжким бременем на IT-службу компании, перетягивает ресурсы и управленческий фокус на себя с основного бизнеса. Объектные хранилища и другие облачные сервисы снимают эту непрофильную рутину и развязывают руки экспертам компании для развития бизнеса и решения стратегических задач.
Max Group оказывает услуги торгового маркетинга для крупнейших FMCG-компаний, и её сотрудники и клиенты взаимодействуют через сервис Max Merch. В условиях роста потока данных и нагрузки на инфраструктуру компания отказалась от регулярной покупки собственного железа и перешла к размещению нагрузки и хранению данных в MCS. Это на 20% уменьшило совокупную стоимость инфраструктуры и обеспечило высокую скорость работы сервиса.
Переход к облачной инфраструктуре, её оптимизацию и в целом администрирование можно отдать на аутсорс в рамках управляемых услуг (managed services).
Снизить стоимость итоговых решений клиентам MCS помогают некоторые технические приёмы.
Данные сразу готовы к скачиванию и использованию. Видеоплеер «Смотри Mail.ru» показывает видео, которое таким способом «подтягивается» из S3-хранилища.
Благодаря этому в том месте, где происходит транскодирование, не нужно хранить большие временные файлы, а сеть не перегружается закачкой объёмных файлов. Всё это позволяет параллельно транскодировать много видеофайлов.
В итоге приёмы использования хранилища строятся вокруг его способности к неограниченному масштабированию и возможности одновременного доступа многих пользователей. В корпоративных системах и бэкенде приложений достаточно распространены и более традиционные средства хранения данных, но при сколь-нибудь значимом масштабировании владельцы этих систем сталкиваются с трудностями. Переход к объектному хранению потребует некоторого редизайна действующей системы, но когда объёмы хранения постоянно меняются, это оправдано.
Принципы организации объектных хранилищ

Наш коллега недавно написал об архитектуре объектного S3-хранилища Mail.ru Cloud Storage. Теперь мы переводим хорошую статью об общих особенностях и ограничениях объектных хранилищ.
Объектные хранилища более масштабируемые, отказоустойчивые и надежные, чем параллельные файловые системы, кроме того, у них ошеломляющая пропускная способность для некоторых рабочих нагрузок. Такие характеристики производительности достигаются за счет отказа от файлов и каталогов.
В отличие от файловых систем, объектные хранилища не поддерживают вызовы ввода-вывода POSIX: открытие, закрытие, чтение, запись и поиск файла. Вместо этого у них только две основные операции: PUT и GET.
Ключевые особенности объектных хранилищ
Поскольку у объектного хранилища всего несколько доступных операций, появляются важные ограничения:
Эта нарочитая простота приводит к ряду ценных последствий в контексте высокопроизводительных вычислений:
Обратите внимание, что во многих реализациях объектных хранилищ к неизменяемости объектов подходят с некоторой гибкостью. Например, режим доступа только с добавлением по-прежнему устраняет узкие места блокировки, улучшая при этом полезность хранилища.
Ограничения объектных хранилищ
Простота организации объектного хранилища делает его масштабируемым, но также ограничивает его функциональность:

Поскольку объектное хранилище не пытается сохранить совместимость с POSIX, реализации шлюзов — удобные места для хранения метаданных объектов, превосходящие те, что традиционно предоставлялись ACL POSIX и NFSv4.
Например, S3 API предоставляет средства для связывания произвольных пар ключ-значение с объектами в качестве определяемых пользователем метаданных. А WOS DDN — запрашивать базу метаданных объектов, чтобы выбрать все объекты, соответствующие критериям запроса.
На базе объектных хранилищ можно построить и гораздо более сложные интерфейсы. Большинство параллельных файловых систем, включая Lustre, Panasas и BeeGFS, построены на концепциях, вытекающих из объектного хранилища. Они идут на компромиссы во внешнем и внутреннем интерфейсе, чтобы сбалансировать масштабируемость с производительностью и удобством использования. Но такая гибкость обеспечивается за счет построения поверх объектно-ориентированных, а не блочных, представлений данных.
Хотя отделение пользовательского интерфейса от базового объектного представления данных обеспечивает гибкость, не все такие шлюзы — шлюзы с двойным доступом. Двойной (или, например, тройной) доступ позволяет получать доступ к одним и тем же данным через несколько интерфейсов. Например, записывать объект с помощью PUT, но читать его обратно, как если бы это был файл. Шлюзы с двойным доступом стараются делать согласованными, однако, возможна ситуация, когда после записи данных они не сразу видны через все интерфейсы.
Реализации объектных хранилищ
Хотя принципы организации объектного хранилища достаточно просты, конкретные продукты отличаются. В частности, для обеспечения устойчивости, масштабируемости и производительности могут использоваться различные способы перемещения данных при получении запроса PUT или GET.
ShellStore: простейший пример
В этом разделе я хочу проиллюстрировать простоту базового хранилища объектов с помощью ShellStore Яна Киркера. Оно представляет собой хотя и безумную, но удивительно лаконичную реализацию объектного хранилища. Прелесть в том, что он демонстрирует основные тонкости работы хранилища с помощью простого bash.
DDN WOS
DDN WOS создавали как высокопроизводительное масштабируемое объектное хранилище, ориентированное на рынок высокопроизводительных систем хранения. Поскольку DDN WOS создавали с нуля, его конструкция проста, разумна и учитывает недостатки дизайна более ранних продуктов.
Простота WOS делает его отличной моделью для иллюстрации того, как в целом работают объектные хранилища. WOS используют очень крупные компании (например, считается, что на нем работает Siri), оно имеет такие примечательные особенности:
Openstack Swift
OpenStack Swift — одна из первых крупных реализаций объектного хранилища корпоративного уровня с открытым исходным кодом. Это то, что сегодня стоит за многими частными облаками. Но поскольку хранилище писали давно, в его архитектуре много неоптимальных решений:
RedHat/Inktank Ceph
Ceph использует детерминированный хэш, называемый CRUSH, который позволяет клиентам напрямую связываться с серверами хранилища объектов. Искать местоположение объекта для каждой операции чтения или записи не нужно.
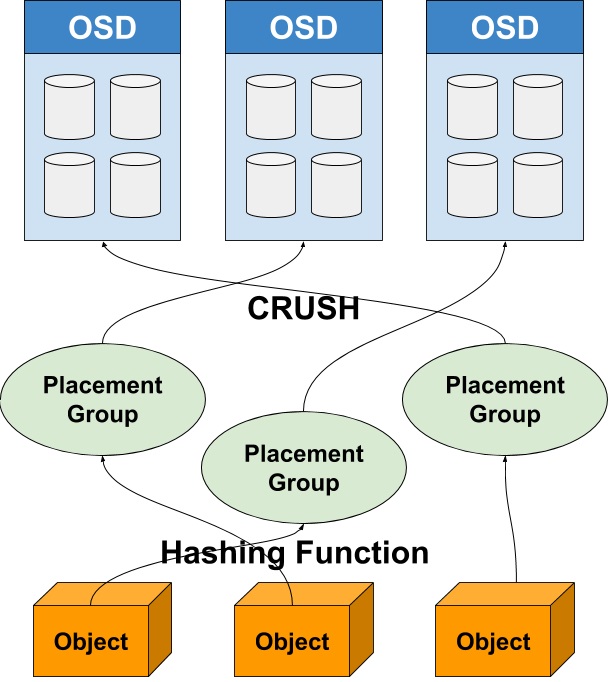
Общая схема потока данных
Объекты сопоставляются с группами размещения с помощью простой хеш-функции. Группы размещения (PG) — логические абстракции. Через хэш CRUSH они сопоставляются с демонами хранения объектов, которые владеют коллекциями физических дисков.
CRUSH уникален тем, что позволяет добавлять дополнительные OSD без перестройки всей структуры карты объект-PG-OSD. Переназначать на недавно добавленные OSD нужно только часть групп размещения, что обеспечивает гибкую масштабируемость и отказоустойчивость.
Группы размещения содержат собственные политики устойчивости объектов, а алгоритм CRUSH позволяет физически реплицировать объекты и географически распределять их по нескольким OSD.
Ceph реализует политику устойчивости на стороне сервера, так что клиент, выполняющий PUT или GET объекта, общается только с одним OSD. После помещения объекта в OSD этот OSD отвечает за его репликацию в другие OSD, выполнение сегментирования, кодирования стиранием и распределения закодированных сегментов. Хорошее описание (с диаграммами) путей данных репликации и кодирования стиранием Ceph опубликовали в Intel.
Ещё несколько ресурсов с информацией об архитектуре Ceph:
Scality RING
Я почти ничего не знаю о Scality RING. Но эта платформа быстро проникает в сферу High-Performance Computing и используется в Национальной лаборатории Лос-Аламоса, которая ведет разработки в области ядерного вооружения.
Scality RING — исключительно программный продукт (в отличие от DDN WOS), который работает на любом оборудовании. У него есть все стандартные шлюзовые интерфейсы (S3, NFS / CIFS и REST, называемые «коннекторами»), кодирование со стиранием и масштабируемый дизайн. Кажется, он основан на детерминированном хеш-коде, который отображает данные на определенный узел хранения в кластере. Все узлы хранения — одноранговые, и с помощью внутренней одноранговой передачи любой узел может отвечать на запросы данных, хранящихся на любом другом узле.
Некоторые архитектурные детали и ссылки на конкретные патенты — в презентации Scality RING.
Другие продукты
Хочу рассказать еще о нескольких платформах объектного хранения. Правда, они менее актуальны для индустрии высокопроизводительных вычислений из-за их направленности или особенностей проектирования.
NetApp StorageGRID
Платформа хранения объектов StorageGRID от NetApp появилась после покупки компании Bycast. StorageGRID в основном используют в бизнесе, связанном с хранением медицинских записей. NetApp особо не рассказывает о StorageGRID, и, насколько я могу судить, отметить нечего, кроме использования Cassandra в качестве прокси-базы данных для отслеживания индексов объектов.
Cleversafe
Cleversafe — платформа для хранения объектов, ориентированная на корпоративный рынок и обладающая исключительной надежностью. Они продают программный продукт, но по своеобразной модели.
Кластеры Cleversafe нельзя легко масштабировать, поскольку вы должны заранее купить все узлы хранения объектов (sliceStors). Всё, что вы можете — увеличивать емкость каждого узла хранения. Заполните до предела емкость каждого узла — придется покупать новый кластер. Такой подход нормален для организаций, которые масштабируются целыми стойками, но менее практичен за пределами высокопроизводительных центров HPC. Среди известных клиентов Cleversafe — Shutterfly.
Cleversafe не так функциональна, как другие платформы хранения объектов (если судить по последней инструкции, которую я читал). Она предоставляет несколько интерфейсов REST («устройств доступа»), включая S3, Swift и HDFS. Но доступ на основе NFS/CIFS осуществляется сторонними приложениями поверх S3/Swift. Впрочем, крупные компании часто пишут собственное ПО для работы с S3, так что это небольшое препятствие при масштабировании.
Периферийные технологии
Представленные ниже решения хоть и не являются строго платформами объектного хранения, дополняют или отражают дух объектных хранилищ.
iRODS: объектное хранилище без объектов или хранилища
iRODS обеспечивает уровень шлюза объектного хранилища без хранилища объектов под ним. Он способен превратить набор файловых систем во что-то, похожее на хранилище объектов, отказавшись от соответствия POSIX в пользу более гибкого и ориентированного на метаданные интерфейса. Однако iRODS предназначен для управления данными, а не для высокой производительности.
MarFS: POSIX-интерфейс к объектному хранилищу
MarFS — платформа, разработанная в Национальной лаборатории Лос-Аламоса. Предоставляет интерфейс для объектного хранилища, включающий знакомые операции POSIX. В отличие от шлюза, который находится перед хранилищем объектов, MarFS предоставляет интерфейс непосредственно на клиентских узлах и прозрачно транслирует операции POSIX в вызовы API, понятные хранилищу объектов.
Спроектированная как легкая, модульная и масштабируемая, MarFS во многом выполняет те же функции, что, например, клиент llite, сопоставляя вызовы POSIX на клиенте хранилища, с вызовами, понятными базовому представлению данных Lustre.
В текущей реализации, которую используют в LANL, — файловая система GPFS для хранения метаданных, которые обычная файловая система POSIX будет предоставлять своим пользователям. Вместо того чтобы хранить данные в GPFS, все файлы в этой индекс-системе являются заглушками — они не содержат данных, но имеют владельца, разрешения и другие атрибуты POSIX-объектов, которые они представляют.
Сами же данные находятся в хранилище объектов (предоставляемом Scality в реализации LANL), а демон MarFS FUSE на каждом клиенте хранилища использует файловую индекс-систему GPFS для связывания вызовов ввода-вывода POSIX с данными, находящимися в хранилище объектов.
Поскольку он подключает клиентов хранилища напрямую к хранилищу объектов, а не действует как шлюз, MarFS предоставляет только подмножество операций ввода-вывода POSIX. В частности, поскольку базовые данные хранятся как неизменяемые объекты, MarFS не позволяет пользователям перезаписывать данные, которые уже существуют.
Посмотрите презентацию MarFS на MSST 2016, чтобы узнать больше.
Зачем и как хранить объекты на примере MinIO
Наша биг дата проанализировала Telegram-чаты, форумы и разговоры в кулуарах IT-мероприятий и пометила объектные хранилища как инструмент, который ещё не все осмеливаются использовать в своих проектах. Хочу поделиться с вами своим опытом в формате статьи-воркшопа. Если вы пока не знакомы с этой технологией и паттернами её применения, надеюсь, эта статья поможет вам начать использовать её в своих проектах.
Зачем вообще говорить о хранении объектов?
С недавних пор я работаю Golang-разработчиком в Ozon. У нас в компании есть крутая команда админов и релиз-инженеров, которая построила инфраструктуру и CI вокруг неё. Благодаря этому я даже не задумываюсь о том, какие инструменты использовать для хранения файлов и как это всё поддерживать.
Но до прихода в Ozon я сталкивался с довольно интересными кейсами, когда хранение разных данных (документов, изображений) было организовано не самым изящным образом. Мне попадались SFTP, Google Drive и даже монтирование PVC в контейнер!
Использование всех этих решений сопряжено с проблемами, в основном связанными с масштабированием. Это и привело меня к знакомству с объектными хранилищами, ведь с их помощью можно красиво и удобно решать целый ряд задач.
Объектное хранилище – это дополнительный слой абстракции над файловой системой и хостом, который позволяет работать с файлами (получать доступ, хранить) через API.
Объектное хранилище может помочь вам в кейсах, когда необходимо хранить файлы пользователей в ваших приложениях, складывать статику и предоставлять доступ к ней через Ingress или хранить кеши вашего CI.
Все материалы к статье (исходники, конфиги, скрипты) лежат вот в этой репе.
Что такое объектное хранилище
Хранить данные нашего приложения можно различными способами, от хранения данных просто на диске до блоба в нашей БД (если она это поддерживает, конечно). Но будет такое решение оптимальным? Часто есть нефункциональные требования, которые нам хотелось бы реализовать: масштабируемость, простота поддержки, гибкость. Тут уже хранением файлов в БД или на диске не обойтись. В этих случаях, например, масштабирование программных систем, в которых хранение данных построено на работе с файловой системой хоста, оказывается довольно проблематичной историей.
И на помощь приходят те самые объектные хранилища, о которых сегодня и пойдёт речь. Объектное хранилище – это способ хранить данные и гибко получать к ним доступ как к объектам (файлам). В данном контексте объект – это файл и набор метаданных о нём.
Основное преимущество хранения данных в объектах – это возможность абстрагирования системы от технических деталей. Нас уже не интересует, какая файловая (или тем более операционная) система хранит наши данные. Мы не привязываемся к данным какими-то конкретными способами их представления, которые нам обеспечивает платформа.
В этой статье мы не будем сравнивать типы объектных хранилищ, а обратим наше внимание на класс S3-совместимых стораджей, на примере MinIO. Выбор обусловлен тем, что MinIO имеет низкий порог входа (привет, Ceph), а ещё оно Kubernetes Native, что бы это ни значило.
На мой взгляд, MinIO – это самый доступный способ начать использовать технологию объектного хранения данных прямо сейчас: его просто развернуть, легко управлять и его невозможно забыть. На протяжении долгого времени MinIO может удовлетворять таким требованиям, как доступность, масштабируемость и гибкость.
Вообще S3-совместимых решений на рынке много. Всегда есть, из чего выбрать, будь то облачные сервисы или self-hosted-решения. В общем случае мы всегда можем перенести наше приложение с одной платформы на другую (да, у некоторых провайдеров есть определённого рода vendor lock-in, но это уже детали конкретных реализаций).
Disclaimer: под S3 я буду иметь в виду технологию (S3-совместимые объектные хранилища), а не конкретный коммерческий продукт. Цель статьи – показать на примерах, как можно использовать такие решения в своих приложениях.
Кейс 1: прокат самокатов
В рамках формата статьи-воркшопа знакомиться с S3 в общем и с MinIO в частности мы будем на практике.
На практике часто возникает вопрос хранения и доступа к контенту, который генерируется или обрабатывается вашим приложением. Правильно выбранный подход может обеспечить спокойный сон и отсутствие головной боли, когда придёт время переносить или масштабировать наше приложение.
Давайте перейдём к кейсу. Представим, что мы пишем сервис для проката самокатов и у нас есть user story, когда клиент фотографирует самокат до и после аренды. Хранить медиаматериалы мы будем в объектном хранилище.
Для начала развернём наше хранилище.
Самый быстрый способ развернуть MinIO – это наш любимчик Docker, само собой.
С недавнего времени Docker – не такая уж и бесплатная штука, поэтому в репе на всякий случай есть альтернативные манифесты для Podman.
Запускать «голый» контейнер из терминала – нынче моветон, поэтому начнём сразу с манифеста для docker-compose.
Теперь мы можем управлять нашим хранилищем с помощью web-ui. Но это не самый удобный способ для автоматизации процессов (например, для создания пайплайнов в CI/CD), поэтому сверху ещё поставим CLI-утилиту:
$ go get github.com/minio/mc
И да, не забываем про export PATH=$PATH:$(go env GOPATH)/bin.
Cоздадим алиас в mc (залогинимся):
$ mc alias set minio http://localhost:9000 ozontech minio123
Теперь создадим bucket – раздел, в котором мы будем хранить данные нашего пользователя (не стоит ассоциировать его с папкой). Это скорее раздел, внутри которого мы будем хранить данные.
Назовем наш бакет “usersPhotos”:
$ mc mb minio/usersPhot
$ mc ls minio > [0B] usersPhotos
Теперь можно приступать к реализации на бэке. Писать будем на Golang. MinIO любезно нам предоставляет пакетик для работы со своим API.
Disclaimer: код ниже – лишь пример работы с объектным хранилищем; не стоит его рассматривать как набор best practices для использования в боевых проектах.
Начнём с подключения к хранилищу:
Теперь опишем ручку добавления медиа:
Нам надо как-то разделять фото до и после, поэтому мы добавим записи в базу данных:
Ну и сам метод обновления записи в БД:
Также мы могли бы напрямую через сервис вытаскивать и отдавать фото по запросу. Выглядело бы это примерно так:
Ну и само получение файла из хранилища:
Но мы можем и просто проксировать запрос напрямую в MinIO, так как у нас нет причин этого не делать (на практике такими причинами могут быть требования безопасности или препроцессинг файлов перед передачей пользователю). Делать это можно, обернув всё в nginx:
Получать ссылки на изображения мы будем через ручку rent_info:
И сам метод обогащения:
Упакуем всё в docker-compose.yaml:
Протестируем работу нашего приложения:
Изображение полученное при переходе по URL от ответа сервиса
Кейс 2: хранение и раздача фронта
Ещё одна довольно популярная задача, для решения которой можно использовать объектные хранилища, – хранение и раздача фронта. Объектные хранилища пригодятся нам тут, когда захотим повысить доступность нашего фронта или удобнее им управлять. Это актуально, например, если у нас несколько проектов и мы хотим упростить себе жизнь.
Небольшая предыстория. Однажды я встретил довольно интересную практику в компании, где в месяц релизили по несколько лендингов. В основном они были написаны на Vue.js, изредка прикручивался API на пару простеньких ручек. Но моё внимание больше привлекло то, как это всё деплоилось: там царствовали контейнеры с nginx, внутри которых лежала статика, а над всем этим стоял хостовый nginx, который выполнял роль маршрутизатора запросов. Как тебе такой cloud-native-подход, Илон? В качестве борьбы с этим монстром мной было предложено обмазаться кубами, статику держать внутри MinIO, создавая для каждого лендинга свой бакет, а с помощью Ingress уже всё это проксировать наружу. Но, как говорится, давайте не будем говорить о плохом, а лучше сделаем!
Представим, что перед нами стоит похожая задача и у нас уже есть Kubernetes. Давайте туда раскатаем MinIO Operator. Стоп, почему нельзя просто запустить MinIO в поде и пробросить туда порты? А потому, что MinIO-Operator любезно сделает это за нас, а заодно построит High Availability-хранилище. Для этого нам всего лишь надо три столовые ложки соды. воспользоваться официальной документацией.
Для простоты установки мы вооружимся смузи Krew, который всё сделает за нас:
$ kubectl krew update
$ kubectl krew install minio
$ kubectl minio init
После прокидывания портов до нашего оператора мы получим в вывод терминала JWT-токен, с которым и залогинимся в нашей панели управления:
Интерфейс управления тенантами
Далее нажимаем на кнопку «Добавить тенант» и задаём ему имя и неймспейс:
Интерфейс настройки тенанта
После нажатия на кнопку «Создать» мы получим креденшиалы, которые стоит записать в какой-нибудь Vault:
Теперь для доступа к панели нашего кластера хранилищ, поднимем прокси к сервису minio-svc и его панели управления:
Вот так у нас будет выглядеть джоба для CI/CD на примере GitLab CI (целиком конфиг лежит в репе):
Для того чтобы отдавать статику, добавим Ingress-манифест:
А если вдруг потребуется доступ из других неймспейсов, то мы можем создать ресурс ExternalName:
Вместо вывода
Объектные хранилища – это класс инструментов, которые позволяют наделить систему высокодоступным хранилищем данных. Во времена cloud-native это незаменимый помощник в решении многих задач. Да, на практике могут случаться кейсы, в которых использование объектного хранения данных будет избыточным, но вряд ли это можно считать поводом совсем игнорировать этот инструментарий в других своих проектах.
Отдельно я бы посоветовал обратить внимание на S3-совместимые решения, если вы занимаетесь машинным обучением или BigData и у вас есть потребность в хранении большого количества медиаданных для их последующей обработки.
Рассмотренное в статье MinIO – это не единственный достойный инструмент, который позволяет работать с данной технологией. Существуют решения на основе Ceph и Riak CS и даже S3 от Amazon. У всех инструментов свои плюсы и минусы.
Желаю вам успехов в создании и масштабировании ваших приложений и надеюсь, что объектные хранилища вам будут в этом помогать!
Делитесь в комментариях о вашем опыте работы с объектными хранилищами и задавайте вопроы!



