Информатика. 7 класс
Конспект урока
Единицы измерения информации
Перечень вопросов, рассматриваемых в теме:
Каждый символ информационного сообщения несёт фиксированное количество информации.
Единицей измерения количества информации является бит – это наименьшаяединица.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Формулы, которые используются при решении типовых задач:
Информационный объём сообщения определяется по формуле:
I – объём информации в сообщении;
К – количество символов в сообщении;
i – информационный вес одного символа.
Теоретический материал для самостоятельного изучения.
Любое сообщение несёт некоторое количество информации. Как же его измерить?
Одним из способов измерения информации является алфавитный подход, который говорит о том, что каждый символ любого сообщения имеет определённый информационный вес, то есть несёт фиксированное количество информации.
Сегодня на уроке мы узнаем, чему равен информационный вес одного символа и научимся определять информационный объём сообщения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
Информационный вес одного символа этого алфавита составляет 4 бита.
Сообщение состоит из множества символов, каждый из которых имеет свой информационный вес. Поэтому, чтобы вычислить объём информации всего сообщения, нужно количество символов, имеющихся в сообщении, умножить на информационный вес одного символа.
Математически это произведение записывается так: I = К · i.
Например: сообщение, записанное буквами 32-символьного алфавита, содержит 180 символов. Какое количество информации оно несёт?
I = 180 · 5 = 900 бит.
Итак, информационный вес всего сообщения равен 900 бит.
В алфавитном подходе не учитывается содержание самого сообщения. Чтобы вычислить объём содержания в сообщении, нужно знать количество символов в сообщении, информационный вес одного символа и мощность алфавита. То есть, чтобы определить информационный вес сообщения: «сегодня хорошая погода», нужно сосчитать количество символов в этом сообщении и умножить это число на восемь.
I = 23 · 8 = 184 бита.
Значит, сообщение весит 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 Кб (килобайт) = 1024 байта= 2 10 байтов
1 Мб (мегабайт) = 1024 Кб = 2 10 Кб
1 Гб (гигабайт) = 1024 Мб = 2 10 Мб
1 Тб (терабайт) =1024 Гб = 2 10 Гб
Итак, сегодня мы узнали, что собой представляет алфавитный подход к измерению информации, выяснили, в каких единицах измеряется информация и научились определять информационный вес одного символа и информационный объём сообщения.
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Сейчас используют целых пять систем кодировок русского алфавита (КОИ8-Р, Windows, MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид. Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере.
Разбор решения заданий тренировочного модуля
№1. Определите информационный вес символа в сообщении, если мощность алфавита равна 32?
№2. Выразите в килобайтах 2 16 байтов.
2 6 = 64, а 2 10 байт – это 1 Кб. Значит, 64 · 1 = 64 Кб.
№3. Тип задания: выделение цветом
8 х = 32 Кб, найдите х.
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Что такое объем данных
Для информации существуют свои единицы измерения информации. Если рассматривать сообщения информации как последовательность знаков, то их можно представлять битами, а измерять в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах и петабайтах.
Давайте разберемся с этим, ведь нам придется измерять объем памяти и быстродействие компьютера.
Единицей измерения количества информации является бит – это наименьшая (элементарная) единица.
Байт – основная единица измерения количества информации.
Байт – довольно мелкая единица измерения информации. Например, 1 символ – это 1 байт.
Производные единицы измерения количества информации
1 килобайт (Кб)=1024 байта =2 10 байтов
1 мегабайт (Мб)=1024 килобайта =2 10 килобайтов=2 20 байтов
1 гигабайт (Гб)=1024 мегабайта =2 10 мегабайтов=2 30 байтов
1 терабайт (Гб)=1024 гигабайта =2 10 гигабайтов=2 40 байтов
Методы измерения количества информации
Итак, количество информации в 1 бит вдвое уменьшает неопределенность знаний. Связь же между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Алфавитный подход к измерению количества информации
При этом подходе отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка, т.е. его алфавит можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет в себе каждый символ:
Вероятностный подход к измерению количества информации
Этот подход применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
I – количество информации,
N – количество возможных событий,
Pi – вероятность i-го события.
Задача 1.
Шар находится в одной из четырех коробок. Сколько бит информации несет сообщение о том, в какой именно коробке находится шар.
Имеется 4 равновероятных события (N=4).
По формуле Хартли имеем: 4=2 i . Так как 2 2 =2 i , то i=2. Значит, это сообщение содержит 2 бита информации.
Задача 2.
Чему равен информационный объем одного символа русского языка?
В русском языке 32 буквы (буква ё обычно не используется), то есть количество событий будет равно 32. Найдем информационный объем одного символа. I=log2 N=log2 32=5 битов (2 5 =32).
Примечание. Если невозможно найти целую степень числа, то округление производится в большую сторону.
Задача 3.
Чему равен информационный объем одного символа английского языка?
Задача 4.
Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний (“включено” или “выключено”). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
С помощью N лампочек, каждая из которых может находиться в одном из двух состояний, можно закодировать 2 N сигналов.
2 5 6 , поэтому пяти лампочек недостаточно, а шести хватит. Значит, нужно 6 лампочек.
Задача 5.
Метеостанция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
В данном случае алфавитом является множество чисел от 0 до 100, всего 101 значение. Поэтому информационный объем результатов одного измерения I=log2101. Но это значение не будет целочисленным, поэтому заменим число 101 ближайшей к нему степенью двойки, большей, чем 101. это число 128=2 7 . Принимаем для одного измерения I=log2128=7 битов. Для 80 измерений общий информационный объем равен 80*7 = 560 битов = 70 байтов.
Задача 6.
Определите количество информации, которое будет получено после подбрасывания несимметричной 4-гранной пирамидки, если делают один бросок.
Пусть при бросании 4-гранной несимметричной пирамидки вероятности отдельных событий будут равны: p1=1/2, p2=1/4, p3=1/8, p4=1/8.
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
Задача 7.
Задача 8.
Оцените информационный объем следующего предложения:
Тяжело в ученье – легко в бою!
Так как каждый символ кодируется одним байтом, нам только нужно подсчитать количество символов, но при этом не забываем считать знаки препинания и пробелы. Всего получаем 30 символов. А это означает, что информационный объем данного сообщения составляет 30 байтов или 30 * 8 = 240 битов.
Методы измерения количества информации
Теория к заданию 10 из ЕГЭ по информатике
Информация и ее кодирование
Различные подходы к определению понятия «информация». Виды информационных процессов. Информационный аспект в деятельности человека
Информация (лат. informatio — разъяснение, изложение, набор сведений) — базовое понятие в информатике, которому нельзя дать строгого определения, а можно только пояснить:
Понятие «информация» является общенаучным, т. е. используется в различных науках: физике, биологии, кибернетике, информатике и др. При этом в каждой науке данное понятие связано с различными системами понятий. Так, в физике информация рассматривается как антиэнтропия (мера упорядоченности и сложности системы). В биологии понятие «информация» связывается с целесообразным поведением живых организмов, а также с исследованиями механизмов наследственности. В кибернетике понятие «информация» связано с процессами управления в сложных системах.
Основными социально значимыми свойствами информации являются:
В человеческом обществе непрерывно протекают информационные процессы: люди воспринимают информацию из окружающего мира с помощью органов чувств, осмысливают ее и принимают определенные решения, которые, воплощаясь в реальные действия, воздействуют на окружающий мир.
Информационный процесс — это процесс сбора (приема), передачи (обмена), хранения, обработки (преобразования) информации.
Сбор информации — это процесс поиска и отбора необходимых сообщений из разных источников (работа со специальной литературой, справочниками; проведение экспериментов; наблюдения; опрос, анкетирование; поиск в информационно-справочных сетях и системах и т. д.).
Передача информации — это процесс перемещения сообщений от источника к приемнику по каналу передачи. Информация передается в форме сигналов — звуковых, световых, ультразвуковых, электрических, текстовых, графических и др. Каналами передачи могут быть воздушное пространство, электрические и оптоволоконные кабели, отдельные люди, нервные клетки человека и т. д.
Хранение информации — это процесс фиксирования сообщений на материальном носителе. Сейчас для хранения информации используются бумага, деревянные, тканевые, металлические и другие поверхности, кино- и фотопленки, магнитные ленты, магнитные и лазерные диски, флэш-карты и др.
Обработка информации — это процесс получения новых сообщений из имеющихся. Обработка информации является одним из основных способов увеличения ее количества. В результате обработки из сообщения одного вида можно получить сообщения других видов.
Защита информации — это процесс создания условий, которые не допускают случайной потери, повреждения, изменения информации или несанкционированного доступа к ней. Способами защиты информации являются создание ее резервных копий, хранение в защищенном помещении, предоставление пользователям соответствующих прав доступа к информации, шифрование сообщений и др.
Язык как способ представления и передачи информации
Для того чтобы сохранить информацию и передать ее, с давних времен использовались знаки.
В зависимости от способа восприятия знаки делятся на:
Для долговременного хранения знаки записывают на носители информации.
Для передачи информации используются знаки в виде сигналов (световые сигналы светофора, звуковой сигнал школьного звонка и т. д.).
По способу связи между формой и значением знаки делятся на:
Для представления информации используются знаковые системы, которые называются языками. Основу любого языка составляет алфавит — набор символов, из которых формируется сообщение, и набор правил выполнения операций над символами.
Системы счисления также можно рассматривать как формальные языки. Так, десятичная система счисления — это язык, алфавит которого состоит из десяти цифр 0..9, двоичная система счисления — язык, алфавит которого состоит из двух цифр — 0 и 1.
Методы измерения количества информации: вероятностный и алфавитный
Единицей измерения количества информации является бит. 1 бит — это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Связь между количеством возможных событий N и количеством информации I определяется формулой Хартли:
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка (алфавит) можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет каждый символ:
Например, в русском языке 32 буквы (буква ё обычно не используется), т. е. количество событий будет равно 32. Тогда информационный объем одного символа будет равен:
I = log2 32 = 5 битов.
Если N не является целой степенью 2, то число log2N не является целым числом, и для I надо выполнять округление в большую сторону. При решении задач в таком случае I можно найти как log2N’, где N′ — ближайшая к N степень двойки — такая, что N′ > N.
Например, в английском языке 26 букв. Информационный объем одного символа можно найти так:
N = 26; N’ = 32; I = log2N’ = log2(2 5 ) = 5 битов.
Если количество символов алфавита равно N, а количество символов в записи сообщения равно М, то информационный объем данного сообщения вычисляется по формуле:
Примеры решения задач
Пример 1. Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний («включено» или «выключено»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
Пример 2. Метеорологическая станция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
Решение. В данном случае алфавитом является множество целых чисел от 0 до 100. Всего таких значений 101. Поэтому информационный объем результатов одного измерения I = log2101. Это значение не будет целочисленным. Заменим число 101 ближайшей к нему степенью двойки, большей 101. Это число 128 = 27. Принимаем для одного измерения I = log2128 = 7 битов. Для 80 измерений общий информационный объем равен:
80 · 7 = 560 битов = 70 байтов.
Вероятностный подход к измерению количества информации применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
$N$ — количество возможных событий;
Например, пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
Единицы измерения количества информации
Наименьшей единицей информации является бит (англ. binary digit (bit) — двоичная единица информации).
Бит — это количество информации, необходимое для однозначного определения одного из двух равновероятных событий. Например, один бит информации получает человек, когда он узнает, опаздывает с прибытием нужный ему поезд или нет, был ночью мороз или нет, присутствует на лекции студент Иванов или нет и т. д.
В информатике принято рассматривать последовательности длиной 8 битов. Такая последовательность называется байтом.
Производные единицы измерения количества информации:
1 килобайт (Кб) = 1024 байта = 2 10 байтов
1 мегабайт (Мб) = 1024 килобайта = 2 20 байтов
1 гигабайт (Гб) = 1024 мегабайта = 2 30 байтов
1 терабайт (Тб) = 1024 гигабайта = 2 40 байтов
Процесс передачи информации. Виды и свойства источников и приемников информации. Сигнал, кодирование и декодирование, причины искажения информации при передаче
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними.
В качестве источника информации может выступать живое существо или техническое устройство. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал.
Сигнал — это материально-энергетическая форма представления информации. Другими словами, сигнал — это переносчик информации, один или несколько параметров которого, изменяясь, отображают сообщение. Сигналы могут быть аналоговыми (непрерывными) или дискретными (импульсными).
Сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Примеры решения задач
Пример 1. Для кодирования букв А, З, Р, О используются двухразрядные двоичные числа 00, 01, 10, 11 соответственно. Этим способом закодировали слово РОЗА и результат записали шестнадцатеричным кодом. Указать полученное число.
Решение. Запишем последовательность кодов для каждого символа слова РОЗА: 10 11 01 00. Если рассматривать полученную последовательность как двоичное число, то в шестнадцатеричном коде оно будет равно: 1011 01002 = В416.
Скорость передачи информации и пропускная способность канала связи
Прием/передача информации может происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации, или скорость информационного потока.
Скорость выражается в битах в секунду (бит/с) и кратных им Кбит/с и Мбит/с, а также в байтах в секунду (байт/с) и кратных им Кбайт/с и Мбайт/с.
Максимальная скорость передачи информации по каналу связи называется пропускной способностью канала.
Примеры решения задач
Пример 1. Скорость передачи данных через ADSL-соединение равна 256000 бит/с. Передача файла через данное соединение заняла 3 мин. Определите размер файла в килобайтах.
Решение. Размер файла можно вычислить, если умножить скорость передачи информации на время передачи. Выразим время в секундах: 3 мин = 3 ⋅ 60 = 180 с. Выразим скорость в килобайтах в секунду: 256000 бит/с = 256000 : 8 : 1024 Кбайт/с. При вычислении размера файла для упрощения расчетов выделим степени двойки:
Размер файла = (256000 : 8 : 1024) ⋅ (3 ⋅ 60) = (2 8 ⋅ 10 3 : 2 3 : 2 10 ) ⋅ (3 ⋅ 15 ⋅ 2 2 ) = (2 8 ⋅ 125 ⋅ 2 3 : 2 3 : 2 10 ) ⋅ (3 ⋅ 15 ⋅ 2 2 ) = 125 ⋅ 45 = 5625 Кбайт.
Представление числовой информации. Сложение и умножение в разных системах счисления
Представление числовой информации с помощью систем счисления
Для представления информации в компьютере используется двоичный код, алфавит которого состоит из двух цифр — 0 и 1. Каждая цифра машинного двоичного кода несет количество информации, равное одному биту.
Система счисления — это система записи чисел с помощью определенного набора цифр.
Система счисления называется позиционной, если одна и та же цифра имеет различное значение, которое определяется ее местом в числе.
Позиционной является десятичная система счисления. Например, в числе 999 цифра «9» в зависимости от позиции означает 9, 90, 900.
Римская система счисления является непозиционной. Например, значение цифры Х в числе ХХІ остается неизменным при вариации ее положения в числе.
Позиция цифры в числе называется разрядом. Разряд числа возрастает справа налево, от младших разрядов к старшим.
Количество различных цифр, употребляемых в позиционной системе счисления, называется ее основанием.
Развернутая форма числа — это запись, которая представляет собой сумму произведений цифр числа на значение позиций.
Развернутая форма записи чисел произвольной системы счисления имеет вид
$a$ — цифры численной записи, соответствующие разрядам;
$m$ — количество разрядов числа дробной части;
$n$ — количество разрядов числа целой части;
$q$ — основание системы счисления.
Если основание используемой системы счисления больше десяти, то для цифр вводят условное обозначение со скобкой вверху или буквенное обозначение: В — двоичная система, О — восмеричная, Н — шестнадцатиричная.
Например, если в двенадцатеричной системе счисления 10 = А, а 11 = В, то число 7А,5В12 можно расписать так:
В шестнадцатеричной системе счисления 16 цифр, обозначаемых 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, что соответствует следующим числам десятеричной системы счисления: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. Примеры чисел: 17D,ECH; F12AH.
Перевод чисел в позиционных системах счисления
Перевод чисел из произвольной системы счисления в десятичную
Для перевода числа из любой позиционной системы счисления в десятичную необходимо использовать развернутую форму числа, заменяя, если это необходимо, буквенные обозначения соответствующими цифрами. Например:
11012 = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 1310;
17D,ECH = 12 ⋅ 16 –2 + 14 ⋅ 16 –1 + 13 ⋅ 160 + 7 ⋅ 16 1 + 1 ⋅ 16 2 = 381,921875.
Перевод чисел из десятичной системы счисления в заданную
Для преобразования целого числа десятичной системы счисления в число любой другой системы счисления последовательно выполняют деление нацело на основание системы счисления, пока не получат нуль. Числа, которые возникают как остаток от деления на основание системы, представляют собой последовательную запись разрядов числа в выбранной системе счисления от младшего разряда к старшему. Поэтому для записи самого числа остатки от деления записывают в обратном порядке.
Например, переведем десятичное число 475 в двоичную систему счисления. Для этого будем последовательно выполнять деление нацело на основание новой системы счисления, т. е. на 2:
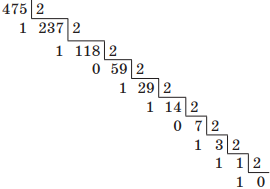
Читая остатки от деления снизу вверх, получим 111011011.
1 ⋅ 2 8 + 1 ⋅ 2 7 + 1 ⋅ 2 6 + 0 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 47510.
Для преобразования десятичных дробей в число любой системы счисления последовательно выполняют умножение на основание системы счисления, пока дробная часть произведения не будет равна нулю. Полученные целые части являются разрядами числа в новой системе, и их необходимо представлять цифрами этой новой системы счисления. Целые части в дальнейшем отбрасываются.
Например, переведем десятичную дробь 0,37510 в двоичную систему счисления:

Полученный результат — 0,0112.
Не каждое число может быть точно выражено в новой системе счисления, поэтому иногда вычисляют только требуемое количество разрядов дробной части.
Перевод чисел из двоичной системы счисления в восьмеричную и шестнадцатеричную и обратно
Для записи восьмеричных чисел используются восемь цифр, т. е. в каждом разряде числа возможны 8 вариантов записи. Каждый разряд восьмеричного числа содержит 3 бита информации (8 = 2 І ; І = 3).
Таким образом, чтобы из восьмеричной системы счисления перевести число в двоичный код, необходимо каждую цифру этого числа представить триадой двоичных символов. Лишние нули в старших разрядах отбрасываются.
1234,7778 = 001 010 011 100,111 111 1112 = 1 010 011 100,111 111 1112;
12345678 = 001 010 011 100 101 110 1112 = 1 010 011 100 101 110 1112.
При переводе двоичного числа в восьмеричную систему счисления нужно каждую триаду двоичных цифр заменить восьмеричной цифрой. При этом, если необходимо, число выравнивается путем дописывания нулей перед целой частью или после дробной.
Для записи шестнадцатеричных чисел используются шестнадцать цифр, т. е. для каждого разряда числа возможны 16 вариантов записи. Каждый разряд шестнадцатеричного числа содержит 4 бита информации (16 = 2 І ; І = 4).
Таким образом, для перевода двоичного числа в шестнадцатеричное его нужно разбить на группы по четыре цифры и преобразовать каждую группу в шестнадцатеричную цифру.
Для перевода шестнадцатеричного числа в двоичный код необходимо каждую цифру этого числа представить четверкой двоичных цифр.
1234,AB7716 = 0001 0010 0011 0100,1010 1011 0111 01112 = 1 0010 0011 0100,1010 1011 0111 01112;
CE456716 = 1100 1110 0100 0101 0110 01112.
При переводе числа из одной произвольной системы счисления в другую нужно выполнить промежуточное преобразование в десятичное число. При переходе из восьмеричного счисления в шестнадцатеричное и обратно используется вспомогательный двоичный код числа.
Например, переведем троичное число 2113 в семеричную систему счисления. Для этого сначала преобразуем число 2113 в десятичное, записав его развернутую форму:
2113 = 2 ⋅ 3 2 + 1 ⋅ 3 1 + 1 ⋅ 3 0 = 18 + 3 + 1 = 2210.
Затем переведем десятичное число 2210 в семеричную систему счисления делением нацело на основание новой системы счисления, т. е. на 7:
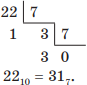
Примеры решения задач
Пример 1. В системе счисления с некоторым основанием число 12 записывается в виде 110. Указать это основание.
Пример 2. Указать через запятую в порядке возрастания все основания систем счисления, в которых запись числа 22 оканчивается на 4.
Пример 3. Указать через запятую в порядке возрастания все числа, не превосходящие 25, запись которых в двоичной системе счисления оканчивается на 101. Ответ записать в десятичной системе счисления.
a1 = 0; x = 5 + 0 · 8 = 5;.
a1=1; x = 5 + 1 · 8 = 13;.
a1 = 2; x = 5 + 2 · 8 = 21;.
Арифметические операции в позиционных системах счисления
Правила выполнения арифметических действий над двоичными числами задаются таблицами сложения, вычитания и умножения.
| Сложение | Вычитание | Умножение |
| 0 + 0 = 0 | 0 – 0 = 0 | 0 ⋅ 0 = 0 |
| 0 + 1 = 1 | 1 – 0 = 1 | 0 ⋅ 1 = 0 |
| 1 + 0 = 1 | 1 – 1 = 0 | 1 ⋅ 0 = 0 |
| 1 + 1 = 10 | 10 – 1 = 1 | 1 ⋅ 1 = 1 |
Правило выполнения операции сложения одинаково для всех систем счисления: если сумма складываемых цифр больше или равна основанию системы счисления, то единица переносится в следующий слева разряд. При вычитании, если необходимо, делают заем.
Пример выполнения сложения: сложим двоичные числа 111 и 101, 10101 и 1111:

Пример выполнения вычитания: вычтем двоичные числа 10001 – 101 и 11011 – 1101:

Пример выполнения умножения: умножим двоичные числа 110 и 11, 111 и 101:
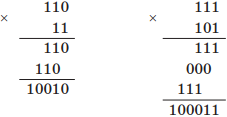
Аналогично выполняются арифметические действия в восьмеричной, шестнадцатеричной и других системах счисления. При этом необходимо учитывать, что величина переноса в следующий разряд при сложении и заем из старшего разряда при вычитании определяется величиной основания системы счисления.
Например, выполним сложение восьмеричных чисел 368 и 158, а также вычитание шестнадцатеричных чисел 9С16 и 6716:

При выполнении арифметических операций над числами, представленными в разных системах счисления, нужно предварительно перевести их в одну и ту же систему.
Представление чисел в компьютере
Формат с фиксированной запятой
В памяти компьютера целые числа хранятся в формате с фиксированной запятой: каждому разряду ячейки памяти соответствует один и тот же разряд числа, «запятая» находится вне разрядной сетки.
Для хранения целых неотрицательных чисел отводится 8 битов памяти. Минимальное число соответствует восьми нулям, хранящимся в восьми битах ячейки памяти, и равно 0. Максимальное число соответствует восьми единицам и равно
1 ⋅ 2 7 + 1 ⋅ 2 6 + 1 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 25510.
Таким образом, диапазон изменения целых неотрицательных чисел — от 0 до 255.
Для п-разрядного представления диапазон будет составлять от 0 до 2 n – 1.
Для хранения целых чисел со знаком отводится 2 байта памяти (16 битов). Старший разряд отводится под знак числа: если число положительное, то в знаковый разряд записывается 0, если число отрицательное — 1. Такое представление чисел в компьютере называется прямым кодом.
Для представления отрицательных чисел используется дополнительный код. Он позволяет заменить арифметическую операцию вычитания операцией сложения, что существенно упрощает работу процессора и увеличивает его быстродействие. Дополнительный код отрицательного числа А, хранящегося в п ячейках, равен 2 n − |А|.
Алгоритм получения дополнительного кода отрицательного числа:
1. Записать прямой код числа в п двоичных разрядах.
2. Получить обратный код числа. (Обратный код образуется из прямого кода заменой нулей единицами, а единиц — нулями, кроме цифр знакового разряда. Для положительных чисел обратный код совпадает с прямым. Используется как промежуточное звено для получения дополнительного кода.)
3. Прибавить единицу к полученному обратному коду.
Например, получим дополнительный код числа –201410 для шестнадцатиразрядного представления:
| Прямой код | Двоичный код числа 201410 со знаковым разрядом | 1000011111011110 |
| Обратный код | Инвертирование (исключая знаковый разряд) | 1111100000100001 |
| Прибавление единицы | 1111100000100001 + 0000000000000001 | |
| Дополнительный код | 1111100000100010 |
При алгебраическом сложении двоичных чисел с использованием дополнительного кода положительные слагаемые представляют в прямом коде, а отрицательные — в дополнительном коде. Затем суммируют эти коды, включая знаковые разряды, которые при этом рассматриваются как старшие разряды. При переносе из знакового разряда единицу переноса отбрасывают. В результате получают алгебраическую сумму в прямом коде, если эта сумма положительная, и в дополнительном — если сумма отрицательная.
1) Найдем разность 1310 – 1210 для восьмибитного представления. Представим заданные числа в двоичной системе счисления:
Запишем прямой, обратный и дополнительный коды для числа –1210 и прямой код для числа 1310 в восьми битах:
| 1310 | –1210 | |
| Прямой код | 00001101 | 10001100 |
| Обратный код | — | 11110011 |
| Дополнительный код | — | 11110100 |
Вычитание заменим сложением (для удобства контроля за знаковым разрядом условно отделим его знаком «_»):

Так как произошел перенос из знакового разряда, первую единицу отбрасываем, и в результате получаем 00000001.
2) Найдем разность 810 – 1310 для восьмибитного представления.
Запишем прямой, обратный и дополнительный коды для числа –1310 и прямой код для числа 810 в восьми битах:
| 810 | –1310 | |
| Прямой код | 00001000 | 10001101 |
| Обратный код | — | 11110010 |
| Дополнительный код | — | 11110011 |
Вычитание заменим сложением:

В знаковом разряде стоит единица, а значит, результат получен в дополнительном коде. Перейдем от дополнительного кода к обратному, вычтя единицу:
11111011 – 00000001 = 11111010.
Перейдем от обратного кода к прямому, инвертируя все цифры, за исключением знакового (старшего) разряда: 10000101. Это десятичное число –510.
Определим диапазон чисел, которые могут храниться в оперативной памяти в формате длинных целых чисел со знаком (для хранения таких чисел отводится 32 бита памяти). Минимальное отрицательное число равно
А = –2 31 = –214748364810.
Максимальное положительное число равно
А = 2 31 – 1 = 214748364710.
Достоинствами формата с фиксированной запятой являются простота и наглядность представления чисел, простота алгоритмов реализации арифметических операций. Недостатком является небольшой диапазон представимых чисел, недостаточный для решения большинства прикладных задач.
Формат с плавающей запятой
Вещественные числа хранятся и обрабатываются в компьютере в формате с плавающей запятой, использующем экспоненциальную форму записи чисел.
Число в экспоненциальном формате представляется в таком виде:
$q$ — основание системы счисления;
Например, десятичное число 2674,381 в экспоненциальной форме запишется так:
Число в формате с плавающей запятой может занимать в памяти 4 байта (обычная точность) или 8 байтов (двойная точность). При записи числа выделяются разряды для хранения знака мантиссы, знака порядка, порядка и мантиссы. Две последние величины определяют диапазон изменения чисел и их точность.
Определим диапазон (порядок) и точность (мантиссу) для формата чисел обычной точности, т. е. четырехбайтных. Из 32 битов 8 выделяется для хранения порядка и его знака и 24 — для хранения мантиссы и ее знака.
Найдем максимальное значение порядка числа. Из 8 разрядов старший разряд используется для хранения знака порядка, остальные 7 — для записи величины порядка. Значит, максимальное значение равно 11111112 = 12710. Так как числа представляются в двоичной системе счисления, то
Аналогично, максимальное значение мантиссы равно
Кодирование текстовой информации. Кодировка ASCII. Основные используемые кодировки кириллицы
Соответствие между набором символов и набором числовых значений называется кодировкой символа. При вводе в компьютер текстовой информации происходит ее двоичное кодирование. Код символа хранится в оперативной памяти компьютера. В процессе вывода символа на экран производится обратная операция — декодирование, т. е. преобразование кода символа в его изображение.
Присвоенный каждому символу конкретный числовой код фиксируется в кодовых таблицах. Одному и тому же символу в разных кодовых таблицах могут соответствовать разные числовые коды. Необходимые перекодировки текста обычно выполняют специальные программы-конверторы, встроенные в большинство приложений.
Как правило, для хранения кода символа используется один байт (восемь битов), поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными. Они позволяют использовать 256 символов ( N = 2 I = 2 8 = 256 ). Таблица однобайтных кодов символов называется ASCII (American Standard Code for Information Interchange — Американский стандартный код для обмена информацией). Первая часть таблицы ASCII-кодов (от 0 до 127) одинакова для всех IBM-PC совместимых компьютеров и содержит:
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит коды букв национального алфавита, коды некоторых математических символов, коды символов псевдографики. Для русских букв в настоящее время используется пять различных кодовых таблиц: КОИ-8, СР1251, СР866, Мас, ISO.
В последнее время широкое распространение получил новый международный стандарт Unicode. В нем отводится по два байта (16 битов) для кодирования каждого символа, поэтому с его помощью можно закодировать 65536 различных символов ( N = 2 16 = 65536 ). Коды символов могут принимать значение от 0 до 65535.
Примеры решения задач
Пример. С помощью кодировки Unicode закодирована следующая фраза:
Я хочу поступить в университет!
Оценить информационный объем этой фразы.
Решение. В данной фразе содержится 31 символ (включая пробелы и знак препинания). Поскольку в кодировке Unicode каждому символу отводится 2 байта памяти, для всей фразы понадобится 31 ⋅ 2 = 62 байта или 31 ⋅ 2 ⋅ 8 = 496 битов.



