
СОДЕРЖАНИЕ
В аппаратном обеспечении
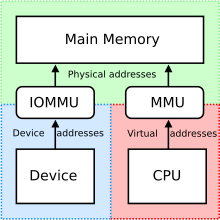
Системы с общей памятью могут использовать:
В программном обеспечении
В компьютерном программном обеспечении общая память либо
Динамические библиотеки обычно хранятся в памяти один раз и сопоставляются с несколькими процессами, и дублируются только страницы, которые должны были быть настроены для отдельного процесса (поскольку символ там разрешается по-разному), обычно с помощью механизма, известного как копирование при записи, которое прозрачно копирует страницу при попытке записи, а затем позволяет успешно выполнить запись в частной копии.
Поддержка Unix-подобных систем
POSIX также предоставляет mmap API для отображения файлов в память; отображение может быть общим, что позволяет использовать содержимое файла в качестве общей памяти.
Поддержка в Windows
В Windows можно использовать CreateFileMapping и MapViewOfFile функцию для отображения области файла в память в нескольких процессах.
Кросс-платформенная поддержка
Некоторые библиотеки C ++ предоставляют переносимый и объектно-ориентированный доступ к функциям общей памяти. Например, Boost содержит библиотеку Boost.Interprocess C ++, а Qt предоставляет класс QSharedMemory.
Поддержка языков программирования
STL, allocator, его разделяемая память и её особенности

Так и автор однажды задался мыслью, а что если … если произойдёт вырождение адресов сегментов разделяемой памяти в разных процессах. Вообще-то именно это происходит, когда процесс с разделяемой памятью делает fork, а как насчет разных процессов? Кроме того, не во всех системах есть fork.
Казалось бы, совпали адреса и что с того? Как минимум, можно пользоваться абсолютными указателями и это избавляет от кучи головной боли. Станет возможно работать со строками и контейнерами С++, сконструированными из разделяемой памяти.
Отличный, кстати, пример. Не то, чтобы автор сильно любил STL, но это возможность продемонстрировать компактный и всем понятный тест на работоспособность предлагаемой методики. Методики, позволяющей (как видится) существенно упростить и ускорить межпроцессное взаимодействие. Вот работает ли она и чем придётся заплатить, будем разбираться далее.
Введение
Идея разделяемой памяти проста и изящна — поскольку каждый процесс действует в своём виртуальном адресном пространстве, которое проецируется на общесистемное физическое, так почему бы не разрешить двум сегментам из разных процессов смотреть на одну физическую область памяти.
А с распространением 64-разрядных операционных систем и повсеместным использованием когерентного кэша, идея разделяемой памяти получила второе дыхание. Теперь это не просто циклический буфер — реализация “трубы” своими руками, а настоящий “трансфункционер континуума” — крайне загадочный и мощный прибор, причем, лишь его загадочность равна его мощи.
Рассмотрим несколько примеров использования.
Фиг.1 структура разделяемой памяти PostgreSQL (отсюда)
Из общих соображений, а какой бы мы хотели видеть идеальную разделяемую память? На это легко ответить — желаем, чтобы объекты в ней можно было использовать, как если бы это были объекты, разделяемые между потоками одного процесса. Да, нужна синхронизация (а она в любом случае нужна), но в остальном — просто берёшь и используешь! Пожалуй, … это можно устроить.
Для проверки концепции требуется минимально-осмысленная задача:
Аллокатор STL
Допустим, для работы с разделяемой памятью существуют функции xalloc/xfree как аналоги malloc/free. В этом случае аллокатор выглядит так:
Этого достаточно, чтобы подсадить на него std::map & std::string
Прежде чем заниматься заявленными функциями xalloc/xfree, которые работают с аллокатором поверх разделяемой памяти, стоит разобраться с самой разделяемой памятью.
Разделяемая память
Разные потоки одного процесса находятся в одном адресном пространстве, а значит каждый не thread_local указатель в любом потоке смотрит в одно и то же место. С разделяемой памятью, чтобы добиться такого эффекта приходится прилагать дополнительные усилия.
Windows
segment size 0 означает, что будет использован размер, с которым создано отображение с учетом сдвига.
Самое важно здесь — hint. Если он не задан (NULL), система подберет адрес на своё усмотрение. Но если значение ненулевое, будет сделана попытка создать сегмент нужного размера с нужным адресом. Именно определяя его значение одинаковым в разных процессах мы и добиваемся вырождения адресов разделяемой памяти. В 32-разрядном режиме найти большой незанятый непрерывный кусок адресного пространства непросто, в 64-разрядном же такой проблемы нет, всегда можно подобрать что-нибудь подходящее.
Linux
Здесь принципиально всё то же самое.
Здесь также важен hint.
Ограничения на подсказку
Что касается подсказки (hint), каковы ограничения на её значение? Вообще-то, есть разные виды ограничений.
Во-первых, архитектурные/аппаратные. Здесь следует сказать несколько слов о том, как виртуальный адрес превращается в физический. При промахе в кэше TLB, приходится обращаться в древовидную структуру под названием “таблица страниц” (page table). Например, в IA-32 это выглядит так:
Фиг.2 случай 4K страниц, взято здесь
Входом в дерево является содержимое регистра CR3, индексы в страницах разных уровней — фрагменты виртуального адреса. В данном случае 32 разряда превращаются в 32 разряда, всё честно.
В AMD64 картина выглядит немного по-другому.
Фиг.3 AMD64, 4K страницы, взято отсюда
В CR3 теперь 40 значимых разрядов вместо 20 ранее, в дереве 4 уровня страниц, физический адрес ограничен 52 разрядами при том, что виртуальный адрес ограничен 48 разрядами.
И лишь в(начиная с) микроархитектуре Ice Lake(Intel) дозволено использовать 57 разрядов виртуального адреса (и по-прежнему 52 физического) при работе с 5-уровневой таблицей страниц.
До сих пор мы говорили лишь об Intel/AMD. Просто для разнообразия, в архитектуре Aarch64 таблица страниц может быть 3 или 4 уровневой, разрешая использование 39 или 48 разрядов в виртуальном адресе соответственно (1).
Во вторых, программные ограничения. Microsoft, в частности, налагает (44 разряда до 8.1/Server12, 48 начиная с) таковые на разные варианты ОС исходя из, в том числе, маркетинговых соображений.
Между прочим, 48 разрядов, это 65 тысяч раз по 4Гб, пожалуй, на таких просторах всегда найдётся уголок, куда можно приткнуться со своим hint-ом.
Аллокатор разделяемой памяти
Во первых. Аллокатор должен жить на выделенной разделяемой памяти, размещая все свои внутренние данные там же.
Во вторых. Мы говорим о средстве межпроцессного общения, любые оптимизации, связанные с использованием TLS неуместны.
В третьих. Раз задействовано несколько процессов, сам аллокатор может жить очень долго, особую важность принимает уменьшение внешней фрагментации памяти.
В четвертых. Обращения к ОС за дополнительной памятью недопустимы. Так, dlmalloc, например, выделяет фрагменты относительно большого размера непосредственно через mmap. Да, его можно отучить, завысив порог, но тем не менее.
В пятых. Стандартные внутрипроцессные средства синхронизации не годятся, требуются либо глобальные с соответствующими издержками, либо что-то, расположенное непосредственно в разделяемой памяти, например, спинлоки. Скажем спасибо когерентному кэшу. В posix на этот случай есть еще безымянные разделяемые семафоры.
Итого, учитывая всё вышесказанное а так же потому, что под рукой оказался живой аллокатор методом близнецов (любезно предоставленный Александром Артюшиным, слегка переработанный), выбор оказался несложным.
Описание деталей реализации оставим до лучших времён, сейчас интересен публичный интерфейс:
Деструктор тривиальный т.к. никаких посторонних ресурсов BuddyAllocator не захватывает.
Последние приготовления
Раз всё размещено в разделяемой памяти, у этой памяти должен быть заголовок. Для нашего теста этот заголовок выглядит так:
Похоже, можно начинать.
Эксперимент
Сам тест очень прост:
Curid — это номер процесса/потока, процесс, создавший разделяемую память имеет нулевой curid, но для теста это неважно.
Qmap, LOCK/UNLOCK для разных тестов разные.
Проведем несколько тестов
qmap — glob_header_t::pglob_->q_map_
Результаты (тип теста vs. число процессов\потоков):
| 1 | 2 | 4 | 8 | 16 | |
|---|---|---|---|---|---|
| THR_MTX | 1’56’’ | 5’41’’ | 7’53’’ | 51’38’’ | 185’49 |
| THR_SPN | 1’26’’ | 7’38’’ | 25’30’’ | 103’29’’ | 347’04’’ |
| PRC_SPN | 1’24’’ | 7’27’’ | 24’02’’ | 92’34’’ | 322’41’’ |
| PRC_MTX | 4’55’’ | 13’01’’ | 78’14’’ | 133’25’’ | 357’21’’ |
Эксперимент проводился на двухпроцессорном (48 ядер) компьютере с Xeon® Gold 5118 2.3GHz, Windows Server 2016.
Итого
Вдогонку
Разделяемую память часто используют для передачи больших потоков данных в качестве своеобразной “трубы”, сделанной своими руками. Это отличная идея даже несмотря на необходимость устраивать дорогостоящую синхронизацию между процессами. То, что она не дешевая, мы видели на тесте PRC_MTX, когда работа даже без конкуренции, внутри одного процесса ухудшила производительность в разы.
Объяснение дороговизны простое, если std::(recursive_)mutex (критическая секция под windows) умеет работать как спинлок, то именованный мутекс — это системный вызов, вход в режим ядра с соответствующими издержками. Кроме того, потеря потоком/процессом контекста исполнения это всегда очень дорого.
Но раз синхронизация процессов неизбежна, как же нам уменьшить издержки? Ответ давно придуман — буферизация. Синхронизируется не каждый отдельный пакет, а некоторый объем данных — буфер, в который эти данные сериализуются. Если буфер заметно больше размера пакета, то и синхронизироваться приходится заметно реже.
Удобно смешивать две техники — данные в разделяемой памяти, а через межпроцессный канал данных (ex: петля через localhost) отправляют только относительные указатели (от начала разделяемой памяти). Т.к. указатель обычно меньше пакета данных, удаётся сэкономить на синхронизации.
А в случае, когда разным процессам доступна разделяемая память по одному виртуальному адресу, можно еще немного добавить производительности.
Напоследок
Чего нельзя делать с объектами, сконструированными в разделяемой памяти.
UPD: исходники BuddyAllocator выложены здесь под BSD лицензией.
Распределенная общая память (DSM — Distributed Shared Memory)
Виртуальная память для распределенных вычислительных систем
В настоящее время большинство высокопроизводительных вычислений мигрируют в сторону кластерных систем, а для них невозможно получить по настоящему высокую производительность без быстрого доступа к распределенным данным. Если раньше основным потребителем были отдельные пользователи, то сейчас все большая доля процессоров используется в различных дата-центрах. Данный сегмент рынка процессоров вырос до необходимости поддержки его потребностей непосредственно в аппаратуре процессора и основной из них является потребность в быстром обмене данными между процессорами дата-центра.
Производители процессоров не предлагают решений данной задачи, а идут путем увеличения числа ядер и интерфейсов памяти в серверных решениях. В настоящий момент задача доступа решается посредством эмуляции прямого доступа в память с использованием сетевых интерфейсов (RDMA).
Внимание:
Все идеи и алгоритмы, описываемые в данной статье, являются результатом моей независимой и полностью самостоятельной интеллектуальной деятельности. Как автор, разрешаю свободно использовать, изменять, дополнять все идеи и алгоритмы любому человеку или организации в любых типах проектов при обязательном указании моего авторства (Балыбердин Андрей Леонидович Rutel@Mail.ru).
Предлагаю механизм работы современной виртуальной памяти расширить в сторону виртуализации памяти для всего дата-центра целиком. В качестве линии передачи данных между процессорами предлагаем использовать оптическое волокно для линий связей больше метра и электрический интерфейс для меньших расстояний (100G на пару, для 12 пар 1.2Т). Современные трансиверы позволяют достигать скоростей передачи до 400G (ближайшей перспективе до 800G), при этом максимальная пропускная способность PCI-E 5.0 500G, а пропускная способность интерфейса памяти DDR4 200G. Получается, что полное задействование всех имеющихся интерфейсов не позволяет полностью использовать производительность даже одного оптического интерфейса, поэтому данный механизм необходимо интегрировать именно в процессор, а не сделать в виде устройства на шине PCI с доступом в основную память.
Расположение виртуальной памяти
Модуль виртуальной память должен быть непосредственно в процессоре и работать с кэш-памятью практически со скоростью процессорных ядер (архитектура COMA). Кроме того, необходимо учитывать, что далеко не все данные необходимо сохранять в локальной оперативной памяти, оптимальнее произвести обработку прямо в кэш-памяти, а результат отправить в кэш другого ядра для дальнейшей обработки, не отправляя их в «бутылочные горлышки» медленных интерфейсов. Такой подход позволит строить очень эффективные цепочки конвейерной обработки, собирать данные, считываемые с большого числа интерфейсов DDR памяти в кэш-память процессоров или контроллеров DSM, где находится начало конвейера, далее передавать через промежуточные обрабатывающие звенья, до конца и уже там производить обратное сохранение результата в DDR. Появится возможность отделить основную оперативную память от процессора, по примеру СХД.
Количество каналов
Если каждый процессор будет иметь только один, то это будет обязательно требовать внешнего коммутатора, что снизит привлекательность для систем низкого и среднего размера (до 1000 процессоров). Коммутатор большого размера автоматически потребует и более длинных линий связи, а это неустранимая задержка передачи данных. Если каналов в процессоре сделать много, то это сделает устройство слишком сложным, что неоправданно поднимет его стоимость. Оптимальным будет интеграция шести высокоскоростных интерфейсов, что позволит строить различные трехмерные структуры, а в системах больше, например 1000 процессоров, использовать внешние коммутаторы для создания дополнительных связей.
Минимальные требуемые характеристики
По производительности интерфейса этот минимум соответствует скорости доступа одного канала DDR4 памяти, иначе особого смысла нет. Время доставки, должно быть стабильным, предсказуемым и в основном определяться скоростью распространения сигнала в кабелях связи, данное требование является ключевым для систем с большим числом промежуточных коммутаторов (гиперкуб). Скорость распространения сигнала в кабеле уже не ускорить — скорость света предел для распространения информации и это выдвигает на первый план требование к компактности вычислительной системы. С другой стороны уменьшать вычислительную систему бесконечно нельзя, появятся ограничения по отводу выделяемого тепла. Оптимальной будет система где отдельные процессоры отделены друг от друга радиаторами с жидкостным охлаждением (воздушное делает радиаторы слишком большими).
Для системы с временем доступа к разделяемой памяти сопоставимой с локальной динамической памятью, максимум производительности соответствует квадрату или кубу со стороной 3 метра для задержки доступа к первому элементу не более 50нс, в этом случае время доступа в кэш любого процессора не будет больше времени доступа в локальную память. Современная динамическая память, хоть и имеет высокие скорости передачи данных, но доступ к новой строке медленный и особого прогресса в этом параметре нет (всего в 2 раза за 20 лет).
Устройство виртуальной памяти с точки зрения программиста
Общая распределенная память— это сегменты в адресном пространстве, общие для двух и более отдельных процессоров, составляющих грид-систему. Управлять общей распределенной памятью можно примерно теми же механизмами, что и обычную виртуальную память. В случае если сегмент не создан, то происходит прерывание по недоступности, также как и в обычной виртуальной памяти. Еще такое же прерывание должно вызываться если по каким-то причинам связь между вычислительными системами прервалась (для всех вариантов маршрутов соединяющих эти системы). Оптимальным вариантом работы кэш-памяти будет режим «сквозная запись», при записи происходит запись одновременно и в удаленные копии памяти и в свою, при чтении чтение производится только из своей копии. При этом останавливать процессор в моменты записи в удаленную память нет необходимости, первоначально запись производится в буфер с контроллера виртуальной памяти (он же обеспечивает строгую очередность записей).
Устройство распределенной памяти
Для понимания проблемы DSM желательно прочитать это.
Предлагаю такой вариант: Модель консистентности: Последовательная (Все процессы видят все записи разделяемых данных в одном и том же порядке).
Для достижения одинаковой последовательности записей, для каждого оригинала данных должен быть «главный» контроллер (сегмент, страница, да хоть одно слово) и все запросы на модификацию проходят только через него. Для различных сегментов распределенной памяти контроллеры могут быть различными, что позволит избежать излишней централизации ресурса. В момент перегрузки сегментного регистра, происходит создание соединения и копирование всего сегмента (страницы) данных удаленной памяти в кэш локального процессора.
Итог: Такая реализация виртуальной общей памяти позволяет сделать ее полностью прозрачной для программ и не требующей каких-либо дополнительных вызовов при ее использовании (кроме начального конфигурирования системы виртуальной памяти при запуске системы). Соответственно не потребуется написания какого-либо дополнительного софта (кроме ПО обслуживающего виртуальную память), с точки зрения программиста никаких отличий от системы с последовательной консистентностью, при использовании префикса LOCK и вообще обычного компьютера. Если грамотно использовать предоставленные возможности (совместное использование физической памяти и конвейерную обработку данных без промежуточной записи в локальную память), то можно существенно повысить производительность многопроцессорной системы, относительно обычной грид-системы.
Реализация виртуальной общей памяти с точки зрения аппаратуры
При заявленных требования к параметрам передачи и времени реакции. Построить такую систему на основе пакетной коммутации невозможно, пакетная коммутация асинхронна по своей природе. Существующие синхронные технологии передачи данных не обеспечивают гибкости в управлении скоростью создаваемого канала и не позволяют быстро создавать произвольный канал без предварительных и часто длительных действий.
Сетевой основой выбрана свободно распространяемая коммуникационная технология: «Синхронная символьная коммутация» (разработанная Балыбердиным А.Л. Rutel@Mail.ru).
Данная технология соответствует всем заявленным характеристикам и имеет относительно небольшие требования к размеру аппаратуры. Описание примененной коммуникационной парадигмы ( https://habr.com/ru/post/512652/ ).
Символьный коммутатор позволяет создавать строго последовательные каналы передачи данных с минимальной задержкой коммутации, неизменной скоростью передачи при отсутствии влияния виртуальных каналов друг на друга. Для пакетных коммутаторов достижение такого качества обслуживания если и возможно, то только при очень малой загрузке. Кроме этого, сеть на основе символьной коммутации позволяет быстро создавать и контролировать конкретные маршруты передачи данных, данная функция позволяет оперативно планировать и разводить по различным физическим соединениям высокоскоростные потоки данных, добиваясь более и равномерной загрузки сети с большим числом альтернативных маршрутов.
Возможность непосредственно задать маршрут и скорость передачи данных при контролируемой задержке передачи, позволяет оптимизировать потоки данных и решить давно востребованную, но не решенную задачу дезагрегации оперативной памяти (примерно как дисковые хранилища СХД). Можно создавать процессоры с малым размером оперативной памяти (на одном кристалле с процессором), построенной на основе статического ОЗУ (сейчас это кэш).
Повышения производительности за счет лучшей загрузки АЛУ
Сети символьной коммутации позволят производить оптимизацию потоков передачи данных и взаимного расположения задействованных задачей вычислительных ядер. Оперативность управления потоками данных в совокупности с высокой пропускной способностью современных трансиверов позволит загрузить исполнительные устройства процессоров до уровня пиковой производительности на постоянной основе, а не в отдельные моменты времени определяемые размером КЭШ памяти.
Распределенный по отдельным процессорам вычислительный конвейер может повысить производительность в несколько раз. Есть статистика, что на каждые пять исполняемых команд, требуется одно обращение в оперативную память за обрабатываемыми данными. Если считать, что одно 32х разрядное число считывается из памяти за 200 ps (25E9 команд в секунду), а одно 400G сетевое соединение позволяет его получить за 80 ps, то это позволит поддерживать в 2.5 раза больший темп исполнения команд (60E9 команд в секунду).
Если задействовать все 6 каналов, то это позволит загрузить в вычислитель практически в пиковой производительности на постоянной основе. Современная оперативная память является достаточно медленным устройством (относительно процессора), и символьная сеть позволит суммировать пропускные способности многих интерфейсов памяти для «запитывания» точек входа таких вычислительных конвейеров, что существенно увеличит производительность вычислительной системы целиком.
Хочу отдельно выделить интересный момент : Максимальная производительность на современных процессорах часто достигается только при правильном расположении данных в памяти, а сеть с синхронной символьной коммутацией может это делать без практически дополнительных затрат. Причем возможно сразу делать несколько различных раскладок, если данные используются в нескольких частях программы и не только для одного конкретного процессора. Есть возможность следить за «комплектностью» данных и формировать сигнал вызова нужного обработчика, иными словами выполнять аппаратную поддержку параллельной обработки.
Краткое описание работы распределенной виртуальной памяти
Если локальный процессор выполняет запись данных в разделяемую память, то сначала данные помещаются в буфер местного контроллера DSM, далее он формирует и передает запрос на изменение данных контроллеру владеющему оригиналом данных. Контроллер «хозяин», получив запрос, помещает его в общую очередь изменений (формирует одинаковую для всех последовательность изменений) и используя единый и очень быстрый канал рассылает уведомления всем владельцам копий. Получив уведомление, владелец копии обновляет данные в своем кэше (даже тот кто инициировал исходную запись). Для куба размером 3 метра, теоретическое полное время составляет 50нс. Если использовать префикс LOCK, то можно очень быстро (50нс) разрешать ситуации входа в критические секции для всей вычислительной системы целиком.
Влияние задержки передачи данных на производительность вычислительной системы
Есть еще важное соотношение, известное существенно меньше закона Амдала :
«Степень распараллеливания задачи равна корню из отношения времени исполнения на одном процессоре к суммарному времени затрачиваемому на передачу данных»
Иными словами, чем медленней сеть соединяющая отдельные процессоры тем крупнее должен быть параллелизм. Влияние этого закона резко возрастает при увеличении числа задействованных процессоров. (Лекции СибГУТИ)
Цели проекта
Создание прототипа универсальной сети на базе недорогой FPGA матрицы с достаточным число трансиверов ) в формате сетевой карты с интерфейсом PCI-E.
Подтвердить предположения о возможности новой сетевой технологии (ССИ) на реальной вычислительной системе.
Создание IP блока контроллера виртуальной общей памяти и применение его в выпускаемых процессорах (например, только для версии для дата-центров).
И еще впервые с 60х годов показать, что наша страна и наши ученые и инженеры что то стоят как самостоятельные игроки в области высокопроизводительных вычислений. (Шучу — в нашей стране нет такой науки).
Ожидаемые результаты
Для системы из 1000 процессоров и максимальном числе промежуточных коммутаторов 20.
Среднее ожидаемое время доставки:
(Размер посылки в символах) * (Время передачи символа) + (Длина кабеля связи) * (Скорость света в кабеле) + (Число промежуточных коммутаторов) * (Время передачи символа.)
Максимальное ожидаемое время доставки:
(Размер посылки в символах) * (Время передачи символа) + (Длина кабеля связи) * (Скорость света в кабеле) + (Число промежуточных коммутаторов) * (Время передачи символа) * 2.5
Чтение (запись) страницы размером 4кБ в монопольном режиме (пиковая производительность).
Чтение (запись) страницы размером 4кБ в режиме средней загрузки сети
Чтение (запись) от 8 до 32 бит в монопольном режиме
Чтение (запись) от 8 до 32 бит в режиме средней загрузке сети
Время задержки стремится к 40 нс, ко времени распространения света по оптическому волокну.
* Средняя загрузка сети, когда для передачи обновлений выделяется только 30% от максимальной производительности физического канала.



