Опережающее чтение
Опережающее чтение, или интервал копирования — приём набора, при котором выполняется чтение букв (слогов, слов, словосочетаний) наперёд. Этот приём повсеместно применяется наборщиками при перепечатке текста с оригинала. Согласно проведённым экспериментам, только в тех случаях, когда наборщику для предварительного просмотра доступно более 7 символов, он может показать увеличение средней скорости. С увеличением средней скорости эта зависимость увеличивается.
Интервал копирования — это число символов, которые могут быть напечатаны в точности после однократного просмотра текста [Солтхаус, 1986a]. Не давая наборщикам указания запоминать предлагаемый текст до его печати, а также используя случайный порядок слов, Солтхаус [1985] измерил интервал копирования как число символов, напечатанных правильно после непредвиденного скрытия оригинала и выяснил, что интервал копирования в обычной ситуации перепечатки у опытного наборщика составил в среднем 14,6 символов.
Phenomenon 13. Copying span is 2-8 words or 7-40 characters for all typists. Copying span is the amount of characters that can be typed accurately after a single inspection of the copy [Salthouse 1986a]. Without requiring the typists to commit the material to be typed to memory before typing or by randomizing the order of the words, Salthouse [1985] measured the copying span as the number of characters typed correctly after an unexpected disappearance of the copy and found that the copying span in normal transcription typing situation was 14.6 characters on average for the skilled typist
Эта статья не завершена. Вы можете помочь проекту, исправив и дополнив её.
Опережающее чтение




![]()
![]()
В том случае, если обработка данных ведется последовательным образом (от начала файла к концу), кэширование не дает значительного эффекта. После того, как обработаны данные из одного блока, дальнейшее пребывание этого блока в кэш-буфере бесполезно. Значительно более полезной в этом случае может оказаться другая специальная форма буферизации, известная как опережающее чтение. Она заключается в том, что при обращении к некоторому блоку диска система, выполнив чтение требуемого блока, считывает затем еще несколько следующих за ним блоков. Если аппаратура позволяет выполнять операцию чтения одновременно с обработкой ранее прочитанных данных, то велика вероятность, что к моменту, когда следующий блок данных будет запрошен для обработки, этот блок уже окажется прочитанным.
Как правило, системе неизвестно, будет ли обработка файла вестись в режиме последовательного или произвольного доступа, поэтому часто используется та или иная комбинация кэширования с опережающим чтением. В Windows программа, открывающая файл, может указать системе, для какого способа доступа желательно оптимизировать механизм буферизации.
Идея опережающего чтения получила интересное развитие в Windows XP. В этой системе введен механизм опережающей загрузки данных (prefetch), который основан на автоматическом сборе и хранении статистики о том, какие файлы и каталоги используются в ходе загрузки ОС и при запуске конкретных приложений, а также какие данные читаются из этих файлов в первые минуты работы. При последующих загрузках ОС и запусках приложений система выполняет ожидаемые операции чтения еще до того, как они будут в действительности запрошены загружаемыми компонентами ОС или приложением. При этом система планирует порядок операций таким образом, чтобы сократить перемещения читающих головок и тем самым ускорить загрузку данных.
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Что такое опережающее чтение?
Что такое опережающие чтения, и как они влияют на производительность SQL Server? Опережающие чтения позволяют SQL Server заглянуть вперед, чтобы извлечь страницы в буферный кэш прежде, чем они фактически будут затребованы для запроса. До 64 последовательных страниц могут быть прочитаны из файла, а возможность опережающего чтения может применяться как для страниц данных, так и для индексных страниц. Когда страницы оказываются в буферном кэше, то отпадает необходимость извлекать их с диска для будущих запросов, пока они не будут сброшены другими задачами SQL Server.
Опережающее чтение в действии
Для начала нам нужно проверить, чтобы была включена статистика ввода-вывода. Тогда мы сможем узнать число сканирований, логических чтений и т.д., но, что нам более важно, мы сможем посмотреть число опережающих чтений:
Мы можем также для нашего примера выполнить следующий оператор, чтобы почистить буферы буферного пула, прежде чем выполнять какие-либо операторы SELECT. Это гарантирует, что мы увидим опережающие чтения, когда выполним наш первый запрос.
Например, мы хотим сделать запрос к базе данных StackOverFlow2013 для получения top 10000 пользователей c id, меньшими 10000. Выполнив запрос SELECT, увидим следующие результаты:
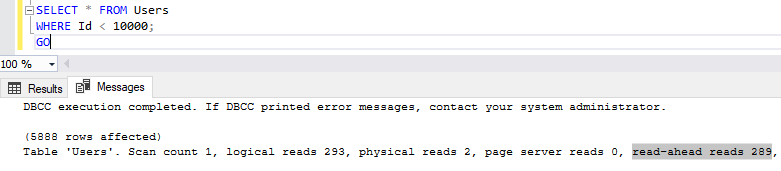
Я получил 5888 строк. Если мы перейдем на вкладку Messages и посмотрим на статистику, то увидим 289 опережающих чтений, означающее, что SQL Server извлек 289 страниц.
Что случится, если мы выполним тот же запрос еще раз? Увидим ли мы теперь опережающие чтения?
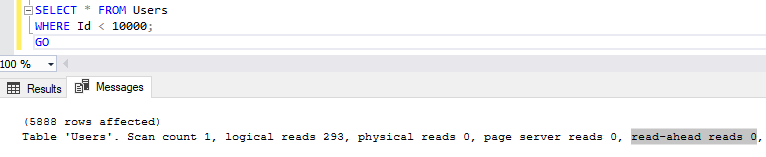
Никаких опережающих чтений на этот раз, поскольку данные уже загружены в буферный кэш.
Запрет опережающих чтений
Если вы по каким-либо причинам не хотите, чтобы выполнялись опережающие чтения, то можете включить флаг трассировки 652, чтобы запретить их:
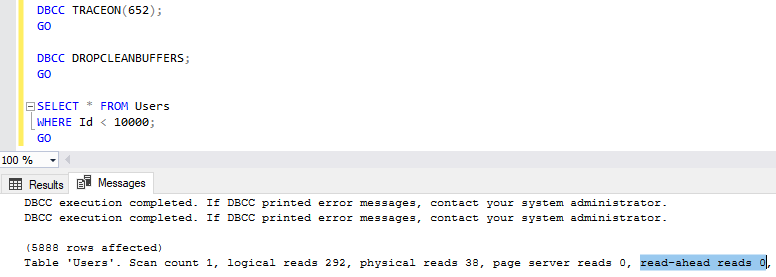
Как видно выше, что даже при предварительной очистке буферов (DBCC DROPCLEANBUFFERS), выполнение нашего оператора SELECT показало 0 в числе опережающих чтений, поскольку был включен флаг трассировки 652.
Вы разрешаете опережающие чтения?
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Опережающее чтение.
В том случае, если обработка данных ведется последовательным образом (от начала файла к концу), кэширование не дает значительного эффекта. После того, как обработаны данные из одного блока, дальнейшее пребывание этого блока в кэш-буфере бесполезно. Значительно более полезной в этом случае может оказаться другая специальная форма буферизации, известная как опережающее чтение. Она заключается в том, что при обращении к некоторому блоку диска система, выполнив чтение требуемого блока, считывает затем еще несколько следующих за ним блоков. Если аппаратура позволяет выполнять операцию чтения одновременно с обработкой ранее прочитанных данных, то велика вероятность, что к моменту, когда следующий блок данных будет запрошен для обработки, этот блок уже окажется прочитанным.
Как правило, системе неизвестно, будет ли обработка файла вестись в режиме последовательного или произвольного доступа, поэтому часто используется та или иная комбинация кэширования с опережающим чтением. В Windows программа, открывающая файл, может указать системе, для какого способа доступа желательно оптимизировать механизм буферизации.
Идея опережающего чтения получила интересное развитие в Windows XP. В этой системе введен механизм опережающей загрузки данных (prefetch), который основан на автоматическом сборе и хранении статистики о том, какие файлы и каталоги используются в ходе загрузки ОС и при запуске конкретных приложений, а также какие данные читаются из этих файлов в первые минуты работы. При последующих загрузках ОС и запусках приложений система выполняет ожидаемые операции чтения еще до того, как они будут в действительности запрошены загружаемыми компонентами ОС или приложением. При этом система планирует порядок операций таким образом, чтобы сократить перемещения читающих головок и тем самым ускорить загрузку данных.
Дата добавления: 2015-09-07 ; просмотров: 950 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Оптимизация скорости бэкапов средствами файловой системы (read ahead, опережающее чтение)
Данная статья адресована инженерам и консультантам работающим с производительностью операций, связанных с последовательным чтением файлов. В основном, это конечно бэкапы. Cюда же можно включить чтение больших файлов с файловых хранилищ, некоторые операции баз данных, например полное сканирование таблиц (зависит от размещения данных).
Примеры приведены для файловой системы VxFS (Symantec). Данная файловая система достаточно широко используется в серверных системах и поддерживается на HP-UX, AIX,Linux, Solaris.
Зачем это нужно?
Вопрос состоит в том, как получить максимальную скорость при последовательном чтении данных в один поток (!) из большого файла (бэкап большого числа мелких файлов за рамками данной статьи). Последовательным чтением считаем такое, когда блоки данных с физических дисков запрашиваются один за другим, по порядку. Считаем, что фрагментация файловых систем отсутствует. Это обоснованно, так как если на файловой системе расположено немного файлов большого размера, и они редко пересоздаются, то практически не фрагментированы. Это обычная ситуация для баз данных, типа Oracle. Чтение из файла в таком случае мало отличается от чтения с сырого устройства.
Чем ограничена скорость однопоточного чтения?
Самые быстрые из современных дисков (15K rpm) имеют время доступа (service time) около 5.5 мс (для почитателей queuing theory, считаем время ожидания равным 0).
Определим количество операций ввода-вывода, которое может выполнить процесс(бэкапа):
1/0.0055 = 182 IO per second (iops).
Если процесс последовательно выполняет операции, каждая из которых длится 5.5 мс, за секунду он выполнит 182 штуки. Предположим, что размер блока составляет 256KB. Таким образом, максимальная пропускная способность данного процесса составит: 182* 256= 46545 KB/s. (46 MB/s). Скромно, правда? Особенно скромно это выглядит для систем с сотнями физических шпинделей, когда мы расчитываем на гораздо большую скорость чтения. Возникает вопрос, как это оптимизировать. Уменьшить время доступа к диску нельзя, так как это технологические ограничения. Распараллелить бэкап тоже не всегда удается. Для снятия данного ограничения на файловых системах реализуется механизм опережающего чтения (read ahead).
Как работает опережающее чтение
В cовременных *nix системах существует два типа запросов ввода-вывода: синхронные и асинхронные. При синхронном запросе, процесс блокируется до получения ответа от дисковой подсистемы. При асинхронном, не блокируется и может делать что-либо еще. При последовательном чтении, мы читаем данные синхронно. Когда включается механизм опережающего чтения, код файловой системы, сразу после синхронного запроса, делает еще несколько асинхронных. Предположим, процесс запросил блок номер 1000. При включенном read ahead, кроме блока 1000 будут запрошены еще и 1001,1002,1003,1004. Таким образом, при запросе блока 1001 нам нет необходимости ждать 5.5 мс. C помощью настройки read ahead можно значительно (в разы) увеличить скорость последовательного чтения.
Как настраивается?
Ключевой настройкой опережающего чтения является его размер. Забегая вперед скажу, что с read ahead есть две основные проблемы: недостаточный read ahead и чрезмерный. Итак, на VxFS read ahead настраивается с помощью параметров “read_pref_io” и “read_nstream” команды vxtunefs. Когда на VxFS включается опережающее чтение, изначально запрашивается 4 блока размером “read_pref_io”. Если процесс продолжает читать последовательно, то прочитывается 4*read_pref_io*read_nstream.
Пример
Пусть read_pref_io=256k и read_nstream=4
Таким образом начальный read ahead составит: 4*256KB =1024KB.
Если последовательное чтение продолжается, то: 4*4*256KB=4096KB
Необходимо заметить, что в последнем случае, в дисковую подсистему отправятся практически одновременно 16 запросов с блоком 256KB. Это не мало и на короткое время может хорошенько подгрузить массив. В общем случае, в настройке read_pref_io и read_nstream сложно давать какие-то общие советы. Конкретные решения всегда зависят от числа дисков в массиве и характера нагрузки. Для некоторых нагрузок отлично работает read_pref_io=256k и read_nstream=32 (очень много). Иногда, read_ahead лучше отключить совсем. Так как настройка простая и ставится она на на лету, проще всего подбирать оптимальное значение. Единственное, что можно посоветовать, всегда ставить read_pref_io по степеням 2. Или как минимум, чтобы они были кратными размеру блока данных в кеше ОС. Иначе, последствия могут быть непредсказуемыми.
Влияние буферного кеша ОС
Когда read ahead асинхронно прочитывает данные, их надо хранить где-то в памяти. Для этого используется файловый кеш операционной системы. В ряде случаев, файловую систему можно смонтировать с отключенным файловым кешем (direct IO). Соответственно, функциональность read ahead в этом случае отключается.
Основные проблемы с опережающим чтением:
1) Недостаточный read ahead. Размер блока, который запросило приложение, больше блока считанного через read ahead. Например, команда ‘cp’ может читать блоком 1024 KB, а опережающее чтение настроено на чтение 256KB. То есть данных просто не хватит чтобы удовлетворить приложение и необходим еще один синхронный запрос ввода-вывода. В данном случае, включение read ahead не принесет увеличения скорости.
2) Чрезмерный read ahead
— слишком агрессивный read ahead может попросту перегрузить дисковую подсистему. Особенно, если в бэкенде установлено мало шпинделей. Большое число практически параллельных запросов свалившихся с хоста могут зафлудить дисковый массив. В этом случае, вместо ускорения вы увидите замедления в работе.
— другой проблемой с read ahead могут быть промахи, когда файловая система ошибочно определяет последовательное чтение прочитывает ненужные данные в кеш. Это приводит к паразитным операциям ввода-вывода, и создает дополнительную нагрузку на диски.
— так как данные read ahead хранятся в кеше файловой системы, большой объем read ahead может приводить к вымыванию из кеша более ценных блоков. Эти блоки потом придется прочитывать с диска снова.
3) Конфликт между read ahead файловой системы и read ahead дискового массива
К счастью, это крайне редкий случай. В большинстве современных дисковых массивов, оснащенных кеш-памятью и логикой, на аппаратном уровне реализован собственный механизм read ahead. Логика массива cама определяет последовательное чтение и контроллер оптом считывает данные с физических дисков в кеш массива. Это позволяет значительно сократить время отклика от дисковой подсистемы и увеличить скорость последовательного чтения. Опережающее чтение файловой системы несколько отличается от обычного синхронного чтения и может сбивать с толку контроллер дискового массива. Он может не распознать характер нагрузки и не включить аппаратный read ahead. Например, если дисковый массив подключен по SAN (Storage Area Networking) и до него есть несколько путей. Из-за балансировки нагрузки асинхронные запросы могут приходить на разные порты дискового массива практически одновременно. В таком случае, запросы могут быть обработаны контроллером не в том порядке, как они отправлены с сервера. Как следствие, массив не распознает последовательное чтение. Решение подобных проблем может быть наиболее долгим и трудоемким. Иногда решение лежит в области настройки, иногда помогает отключение одного из read ahead (если это возможно), иногда необходимо изменение кода одного из компонент.
Пример влияния опережающего чтения
Заказчик был неудовлетворен временем резервного копирования базы данных. В качестве теста, выполнялся бэкап одного файла размером 50 GB. Дальше приведены результаты трех тестов с различными настройками файловой системы.
Directories… 0
Regular files… 1
— Objects Total… 1
Total Size… 50.51 GB
1. Опережающее чтение выключено (Direct IO)
Run Time… 0:17:10
Backup Speed… 71.99 MB/s
2. Стандартные настройки опережающего чтения (read_pref_io = 65536, read_nstream = 1)
Run Time… 0:05:17
Backup Speed… 163.16 MB/s
3. Увеличенный (сильно) размер опережающего чтения (read_pref_io = 262144, read_nstream = 64)
Run Time… 0:02:27
Backup Speed… 222.91 MB/s
Как видно из примера, read ahead позволил значительно сократить время бэкапа. Дальнейшая эксплуатация показала, что все остальные задачи на системе нормально работали с таким большим размером read ahead (тест 3). Каких-либо проблем из-за чрезмерного read ahead не было замечено. В результате, эти настройки и оставили.



