Что такое парсер простыми словами

Еще не зарегистрированы?
Для наполнения интернет-магазина или торговой онлайн-площадки нужно анализировать тысячи страниц сайтов производителей. Делать это вручную очень затратно и долго, поэтому рекомендуется использовать специальные программы сбора и анализа данных — парсеры. Такие же утилиты подходят для сбора и систематизации информации с веб-страниц конкурентов — для изучения контента и многих других задач.

Что такое парсинг и парсер сайтов
Парсингом называется процесс и способ индексирования цифровой информации и дальнейшей конвертации в другой формат. Парсер — это специальная программа, онлайн-сервис или скрипт, собирающие данные с нужных сайтов, аккаунтов социальных сетей и других интернет-площадок, а затем преобразующие их в нужный вид. Есть разные виды парсеров, конвертирующие информацию в простейший язык, необходимый для отображения или использования для различных целей.
Сбор открытых данных разрешен Конституцией. Но если собираются персональные данные пользователей, которые используются для таргетированной рекламы, спам-рассылок, то это уже считается незаконными действиями (нарушение закона о персональных данных).
Назначение парсеров сайтов
Какие данные можно собирать с помощью программ-парсеров («белый» парсинг»):
Есть также «серый» парсинг, к которому относятся скачивание контента на конкурентных онлайн-ресурсах, сбор контактной информации с агрегаторов и бизнес-порталов, применяющийся для рассылок и обзвона «холодных» баз.

Виды парсеров веб-сайтов
Есть разные виды парсеров, которые подбираются в зависимости от поставленных целей и задач, вида контента, который нужно собирать, анализировать и конвертировать. Они приведены в Табл. 1.
Табл. 1. Типы парсеров и их особенности
| Параметр классификации | Тип парсера | Особенности и применение |
| Тип устройства | Облачный | Облачные сервисы работают с помощью скриптов и программ, которые не нужно скачивать на компьютер. Скачать нужно только полученные результаты. Такие инструменты рекомендованы тем, кто регулярно парсит данные, автоматизируя процессы. В сети можно найти англоязычные и русскоязычные программы для парсинга |
| Декстопный (на компьютере) | Парсеры для сбора информации о товарах и ценах, которые нужно скачать на компьютер либо запускать с флешки, внешнего накопителя. Такие сервисы разрабатываются под Windows — на macOS | |
| Технологии | Браузерные расширения | Браузерные расширения подходят для сбора небольшого количества информации и преобразуют ее в удобный формат (XML или XLSX). Есть различные парсеры для Google Chrome и других браузеров |
| Надстройки для Excel | Программные продукты, разработанные в виде надстроек для Microsoft Excel (такие, как ParserOK и пр.). В таких парсерах для сайтов используются простые макросы, которые дают возможность выгрузки результатов в файлы XLS или CSV | |
| Google Таблицы | Программный продукт поисковой системы Гугл, который предлагает применение простых формул IMPORTXML и IMPORTHTML для сбора данных с веб-ресурсов. Функция IMPORTXML работает с помощью языка запросов XPath, парсит данные XML-фидов, HTML-страниц и прочих источников для анализа заголовков, метаданных, ценовых показателей и пр. Функция IMPORTXML дает меньше возможностей — она позволяет собирать информацию с таблиц и списков на веб-страницах | |
| Сфера применения | Совместные покупки | Специальные программы-парсеры устанавливают на своих интернет-магазинах или торговых онлайн-платформах производители или сетевики, продающие тысячи разных товаров. Потенциальные покупатели, заходя на такой ресурс, могут выгрузить себе весь ассортимент с помощью парсера. Можно загрузить себе на устройство весь ассортимент, а также отдельные товарные группы или категории. Предлагаются также разные форматы выгрузки — стандартные XLSX, CSV, адаптированный прайс-лист для Tiu.ru, выгрузка продукции для Яндекс.Маркета и т. д. |
| Анализ ценовых предложений конкурентов | Есть специальные сервисы, которые позволяют парсить цены на товары конкурентов при указании нужных ссылок | |
| Наполнение товарных сайтов, интернет-магазинов | При наполнении онлайн-магазина товарами с сайтов производителей нужно копировать названия и характеристики продукции, цены и фото. Это можно сделать вручную (если таких позиций немного) или же воспользоваться парсером. Такой сервис дает возможность добавлять стандартную наценку на все собранные единицы продукции, а также настроить автоматическое обновление всех данных с определенной периодичностью |

Есть также парсеры для SEO-специалистов, применяемые для оптимизации сайтов, интернет-магазинов, порталов. Программы по сбору SEO-данных можно также использовать для анализа конкурентных веб-ресурсов.
Такие программы нужны для:

Как найти парсер под определенные задачи
Для сбора данных можно:

Плюсы и минусы парсинга
У применения сервисов для парсинга сайтов в коммерческих и других целях есть свои преимущества и недостатки (Табл. 2).
Табл.2. Плюсы и минусы применения парсеров
| Преимущества | Недостатки |
| Автоматизация сбора, анализа и другой обработки собранных данных. Сервис работает быстро, без перерывов и выходных, в рамках настроек под нужные задачи | Некоторые сайты, с которых требуется собирать информацию, могут быть защищены от копирования или обработки парсинговыми программами |
| Возможность собирать именно те данные, которые нужны для выполнения определенных задач. Можно отсечь нецелевые данные путем гибких настроек сервиса или инструмента | Конкуренты также могут парсить ваш сайт (если не защищать его с помощью капчи или настроек — блокирования популярных ключевых запросов и слов в файле robots.txt) |
| Распределение нагрузки на обрабатываемые веб-ресурсы. Равномерная нагрузка при сборе данных позволяет скрыть планомерный парсинг контента. Если нагрузки превышать, то сайт может «упасть» и вас могут обвинить в незаконной DDoS-атаке |
Как работает парсер
Программное обеспечение анализирует данные определенного веб-ресурса с учетом заданных настроек, извлекает контент, систематизирует и преображает тексты и другие элементы наполнения.

Упрощенный алгоритм работы с парсинговым сервисом, который может различаться в зависимости от разных типов утилиты:
Как использовать парсер для различных целей
Применение программы для сбора данных осуществляется с учетом поставленных задач. От этого зависит подбор типа и перечня функций сервиса.
Парсинг интернет-магазина
Одним из самых частых применений парсинговых программ является сбор данных с онлайн-площадок или электронных каталогов для наполнения собственного интернет-магазина товарами, ценами и описаниями продукции.
Какие задачи можно решить, применяя автоматизированные сервисы для сбора, анализа и конвертации данных:

Парсинг контента
Для поиска и анализа текстов и другого контента используется специальная утилита для парсинга. Настройка осуществляется с учетом поставленных задач — анализ опубликованных статей, описание характеристик или комментариев в каталоге продукции.
Как парсить интернет-магазин
Для корректного сбора данных нужно грамотно настроить парсинговую программу или расширение. Настройка модуля позволяет обеспечить корректное распознавание разметки сайта — расположение и структуру категорий и подкатегорий, карточек товаров. После этого можно получить всю необходимую информацию с онлайн-ресурса.

Алгоритм действий при парсинге интернет-магазина:
Теги, которые используются для парсинга онлайн-магазина
При разработке интернет-магазинов разного масштаба и структуры используется язык HTML, типовые элементы блоков. Поэтому стандартные парсеры используют типовые теги HTML, которые имеются на страницах интернет-магазинов:
Используя стандартизированные настройки, можно выбрать именно те блоки информации, которые нужны для анализа или других целей.
Применение парсинговых утилит позволяет быстро собирать и систематизировать большие массивы данных. Это нужно для анализа цен и товаров конкурентов, а также для обновления данных о товарах и услугах. Если вы работаете с десятком производителей, то вам удобно использовать парсинговые сервисы для обновления и актуализации информации с этими товарами. Не нужно вносить изменения вручную, намного быстрее и проще применять данную программу.
Парсинг — что это такое простыми словами. Как работает парсинг и парсеры, и какие типы парсеров бывают (подробный обзор +видео)
Парсинг – что это такое простыми словами? Если коротко, то это сбор информации по разным критериям из интернета, в автоматическом режиме. В процессе работы парсера сравнивается заданный образец и найденная информация, которая в дальнейшем будет структурирована.
В качестве примера можно привести англо-русский словарь. У нас есть исходное слово «parsing». Мы открываем словарь, находим его. И в качестве результата получаем перевод слова «разбор» или «анализ». Ну, а теперь давайте разберем эту тему поподробнее
Содержание статьи:
Парсинг: что это такое простыми словами
Парсинг — это процесс автоматического сбора информации по заданным нами критериям. Для лучшего понимания давайте разберем пример:
Пример того, что такое парсинг:
Представьте, что у нас есть интернет-магазин поставщика, который позволяет работать по схеме дропшиппинга и мы хотим скопировать информацию о товарах из этого магазина, а потом разместить ее на нашем сайте/интернет магазине (под информацией я подразумеваю: название товара, ссылку на товар, цену товара, изображение товара). Как мы можем собрать эту информацию?
Первый вариант сбора — делать все вручную:
То есть, мы вручную проходим по всем страницам сайта с которого хотим собрать информацию и вручную копируем всю эту информацию в таблицу для дальнейшего размещения на нашем сайте. Думаю понятно, что этот способ сбора информации может быть удобен, когда нужно собрать 10-50 товаров. Ну, а что делать, когда информацию нужно собрать о 500-1000 товаров? В этом случае лучше подойдет второй вариант.
Второй вариант — спарсить всю информацию разом:
Мы используем специальную программу или сервис (о них я буду говорить ниже) и в автоматическом режиме скачиваем всю информацию в готовую Excel таблицу. Такой способ подразумевает огромную экономию времени и позволяет не заниматься рутинной работой.
Причем, сбор информации из интернет-магазина я взял лишь для примера. С помощью парсеров можно собирать любую информацию к которой у нас есть доступ.
Грубо говоря парсинг позволяет автоматизировать сбор любой информации по заданным нами критериям. Думаю понятно, что использовать ручной способ сбора информации малоэффективно (особенно в наше время, когда информации слишком много).
Для наглядности хочу сразу показать главные преимущества парсинга:
Если говорить о наличие минусов, то это, разумеется, отсутствие у полученных данных уникальности. Прежде всего, это относится к контенту, мы ведь собираем все из открытых источников и парсер не уникализирует собранную информацию.
Думаю, что с понятием парсинга мы разобрались, теперь давайте разберемся со специальными программами и сервисами для парсинга.
Что такое парсер и как он работает

Парсер – это некое программное обеспечение или алгоритм с определенной последовательностью действий, цель работы которого получить заданную информацию.
Сбор информации происходит в 3 этапа:
Чаще всего парсер — это платная или бесплатная программа или сервис, созданный под ваши требования или выбранный вами для определенных целей. Подобных программ и сервисов очень много. Чаще всего языком написания является Python или PHP.
Но также есть и отдельные программы, которые позволяют писать парсеры. Например я пользуюсь программой ZennoPoster и пишу парсеры в ней — она позволяет собирать парсер как конструктор, но работать он будет по тому же принципу, что и платные/бесплатные сервисы парсинга.
Для примера можете посмотреть это видео в котором я показываю, как я создавал парсер для сбора информации с сервиса spravker.ru.
Чтобы было понятнее, давайте разберем каких типов и видов бывают парсеры:
Не следует забывать о том, что парсинг имеет определенные минусы. Недостатком использования считаются технические сложности, которые парсер может создать. Так, подключения к сайту создают нагрузку на сервер. Каждое подключение программы фиксируется. Если подключаться часто, то сайт может вас заблокировать по IP (но это легко можно обойти с помощью прокси).
Не беспокойтесь!
Мы составили Руководство для начинающих по парсингу в интернете. Имея лишь некоторые, или вовсе не имея каких-либо технических знаний, вы можете начать использовать это руководство. Данное руководство позволит вам изучить парсинг и поможет вам получить конкурентное преимущество перед другими. Давайте начнем!
Зайдя на любой сайт вы можете только просматривать данные, но не можете их выгрузить. Да, вы можете вручную скопировать и сохранить некоторые из них, но это отнимает много времени и сил. Парсинг позволяет автоматизировать этот процесс и быстро извлечь точные данные, которые можно использовать для любого рода аналитики.
Вы можете собирать огромное количество данных, а также различные типы данных. Это могут быть текст, изображения, электронная почта, номера телефонов, видео и так далее. Для конкретных проектов вам могут потребоваться данные, относящиеся к конкретному ресурсу, такие как информация о товаре или услуге, обзоры, цены или данные о конкурентах. В конце процесса вы получите все это в формате таблицы XLS или CSV файла, который вы можете использовать по своему усмотрению далее.
Итак, позвольте нам показать вам, как на самом деле работает парсинг. Хотя есть много разных способов, мы расскажем самый простой и легкий из возможных способов сбора данных. Вот как это работает.
Проще говоря, парсер в основном принимает HTML-код и извлекает соответствующую информацию, такую как заголовок страницы, абзацы на странице, иные заголовки на странице, ссылки, текст и так далее. Все, что вам нужно, это задать регулярные выражения (Regex или Regexp, англ. Regular expressions), где группа регулярных выражений определяет регулярный язык и механизм регулярных выражений, автоматически генерирующий синтаксический анализатор для этого языка, позволяющий сопоставлять шаблоны и извлекать нужный текст.
3. Скачать данные
В заключительной части вы загружаете и сохраняете данные в CSV или XML, чтобы их можно было использовать в любой другой программе (например Excel).
В настоящее время автоматизация процесса парсинга используется для идентификации нужной информации на сайте путем визуального распознавания страниц, как это делает человек своими глазами.
Если показатель доверия слишком низок, система автоматически генерирует запрос, предназначенный для получения текстов, которые могут содержать данные, которые парсер пытается извлечь.
Затем парсер пытается извлечь соответствующие данные вначале из одного, а после по аналогии из новых текстов и сверяет результаты с результатами его первоначального извлечения. Если показатель достоверности остается достаточно низким, он переходит к следующему найденному тексту, и так далее.
Что такое парсинг сайта, программы и примеры их использования

В интернет маркетинге часто необходимо собрать большой объем информации с сайта, не только со своего, но и с сайтов конкурентов, после её проанализировать и применить для каких-либо целей.
В статье постараемся достаточно просто рассказать о термине «парсинг”, его основных нюансах и рассмотрим несколько примеров его полезного применения, как для маркетологов и владельцев бизнеса, так и для SEO специалистов.
Что такое парсинг сайта?
Простыми словами парсинг – это автоматизированный сбор информации с любого сайта, ее анализ, преобразование и выдача в структурированном виде, чаще всего в виде таблицы с набором данных.
Парсер сайта — это любая программа или сервис, которая осуществляет автоматический сбор информации с заданного ресурса.
В статье мы разберем самые популярные программы и сервисы для парсинга сайта.
Зачем парсинг нужен и когда его используют?
Вообще парсинг можно разделить на 2 типа:
На основе полученных данных специалист составляет технические задания для устранения выявленных проблем.
Выше перечислены основные примеры использования парсинга. На самом деле их куда больше и ограничивается только вашей фантазией и некоторыми техническими особенностями.
Как работает парсинг? Алгоритм работы парсера.
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов.
Если кратко, то парсер ходит по ссылкам указанного сайта и сканирует код каждой страницы, собирая информацию о ней в Excel-файл либо куда-то еще. Совокупность информации со всех страниц сайта и будет итогом парсинга сайта.
Парсинг работает на основе XPath-запросов, это язык, который обращается к определенному участку кода страницы и извлекает из него заданную критерием информацию.
Алгоритм стандартного парсинга сайта.
Чем парсинг лучше работы человека?
Парсинг сайта – это рутинная и трудоемкая работа. Если вручную извлекать информацию из сайта, в котором всего 10 страниц, не такая сложная задача, то анализ сайта, у которого 50 страниц и больше, уже не покажется такой легкой.
Кроме того нельзя исключать человеческий фактор. Человек может что-то не заметить или не придать значения. В случае с парсером это исключено, главное его правильно настроить.
Если кратко, то парсер позволяет быстро, качественно и структурировано получить необходимую информацию.
Какую информацию можно получить, используя парсер?
У разных парсеров могут быть свои ограничения на парсинг, но по своей сути вы можете спарсить и получить абсолютно любую информацию, которая есть в коде страниц сайта.
Законно ли парсить чужие сайты?
Парсинг данных с сайтов-конкурентов или с агрегаторов не противоречат закону, если:
Если вы сомневаетесь по одному из перечисленных пунктов, перед проведением анализа сайта лучше проконсультироваться с юристом.
Популярные программы для парсинга сайта
Мы выделяем 4 основных инструменты для парсинга сайтов:
Google таблицы (Google Spreadsheet)
Удобный способ для парсинга, если нет необходимости парсить большое количество данных, так как есть лимиты на количество xml запросов в день.
С помощью таблиц Google Spreadsheet можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим основные функции
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
=IMPORTHTML(“ссылка на страницу”; запрос “table” или “list”; порядковый номер таблицы/списка)
Пример использования
Необходимо выгрузить данные из таблицы со страницы сайта.

Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
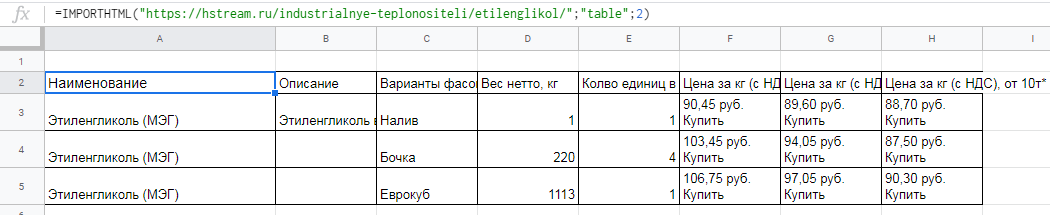
Вставляем формулу в таблицу и смотрим результат:

Для выгрузки второй таблицы в формуле заменяем 1 на 2.
Вставляем формулу в таблицу и смотрим результат:
Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
Формула:
=IMPORTXML(“ссылка”; “//XPath запрос”)
Пример использования
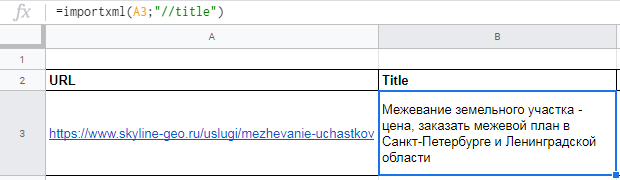
Вытягиваем title, description и заголовок h1.
В первом случае в формуле просто прописываем //title:
В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
Для заголовка h1 похожая формула
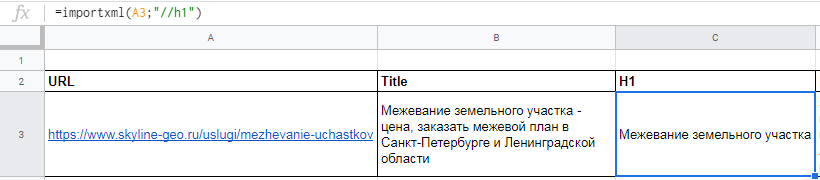
С парсингом description немного другая история, а именно прописать его XPath запросом. Он будет выглядеть так:

В случае с другими любыми данными XPath можно скопировать прямо из кода страницы. Делается это просто:
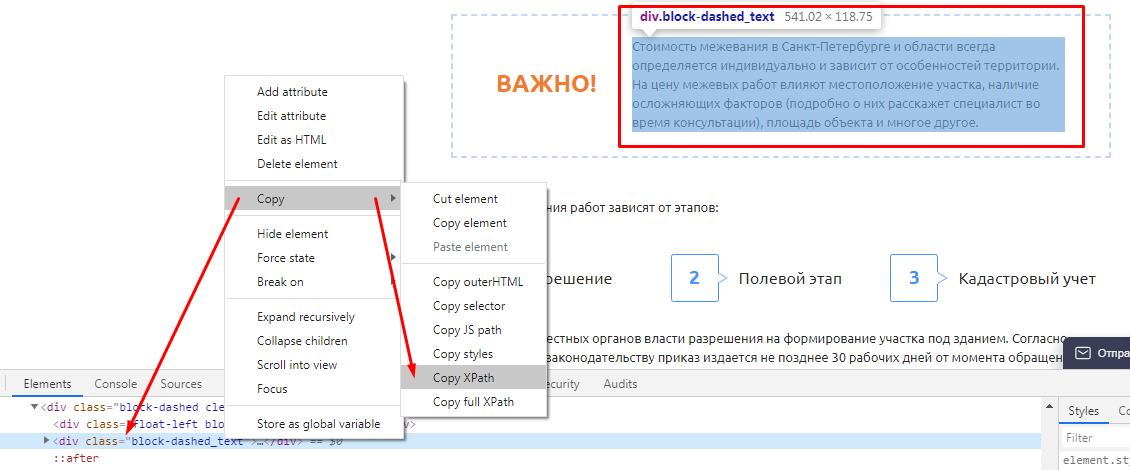
Вот как это будет выглядеть после всех манипуляций
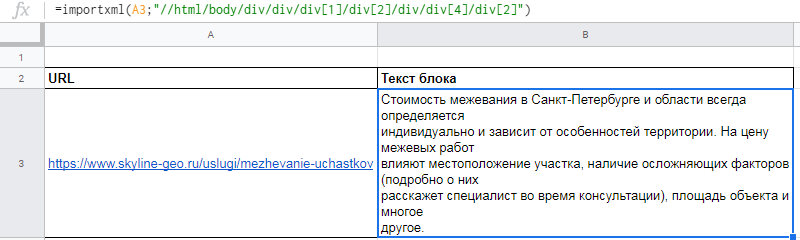
Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Конечно для использования данной функции необходимы знания построения регулярных выражений,
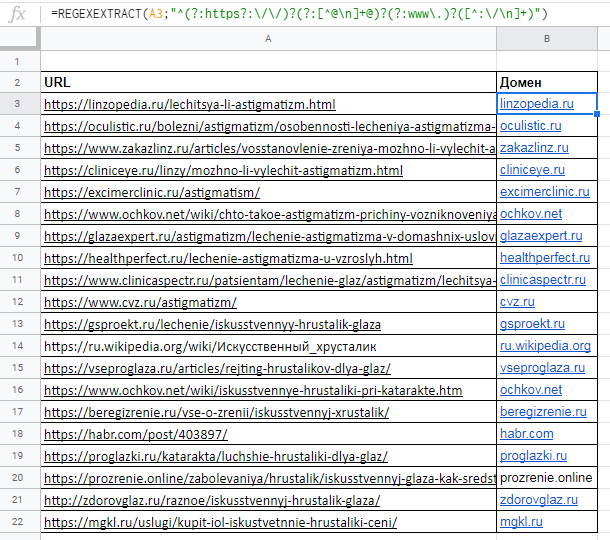
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:
Подробнее о функциях таблиц можно почитать в справке Google.
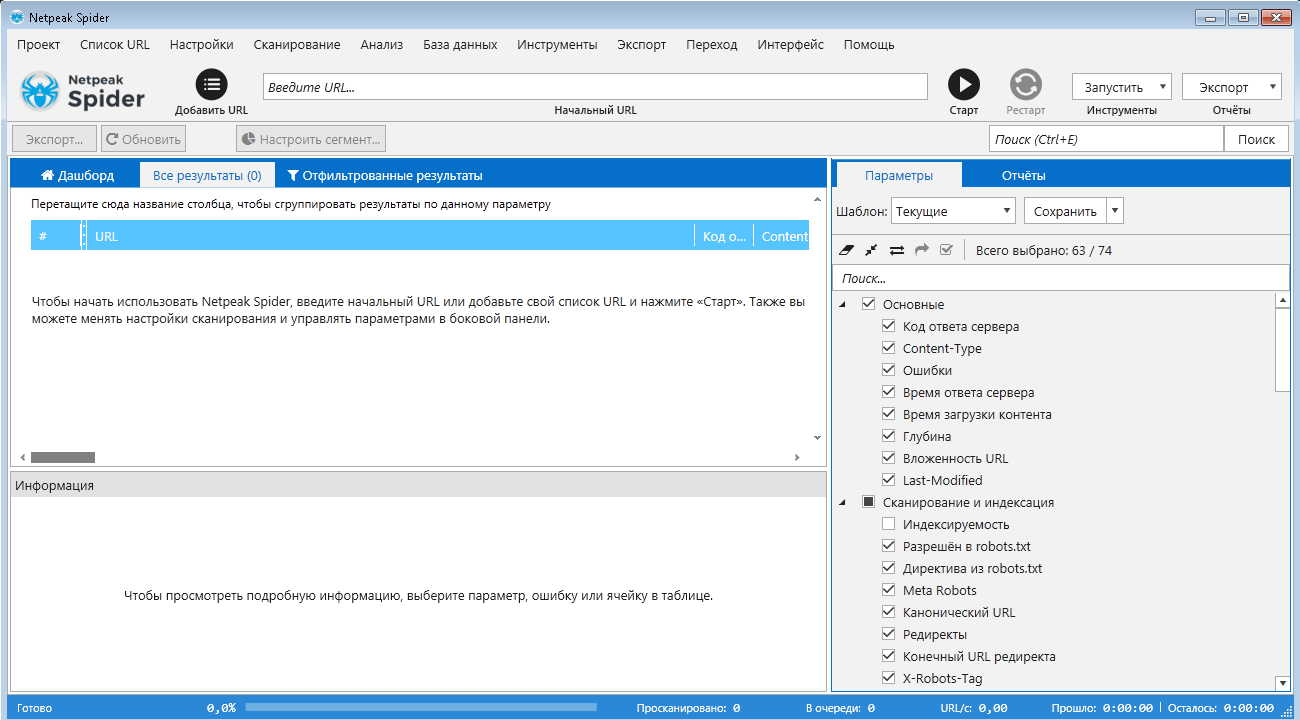
NetPeak Spider

Десктопный инструмент для регулярного SEO-аудита, быстрого поиска ошибок, системного анализа и парсинга сайтов.
Бесплатный период 14 дней, есть варианты платных лицензий на месяц и более.
Данная программа подойдет как новичкам, так и опытным SEO-специалистам. У неё интуитивно понятный интерфейс, она самостоятельно находит и кластеризует ошибки, найденные на сайте, помечает их разными цветами в зависимости от степени критичности.
Возможности Netpeak Spider:
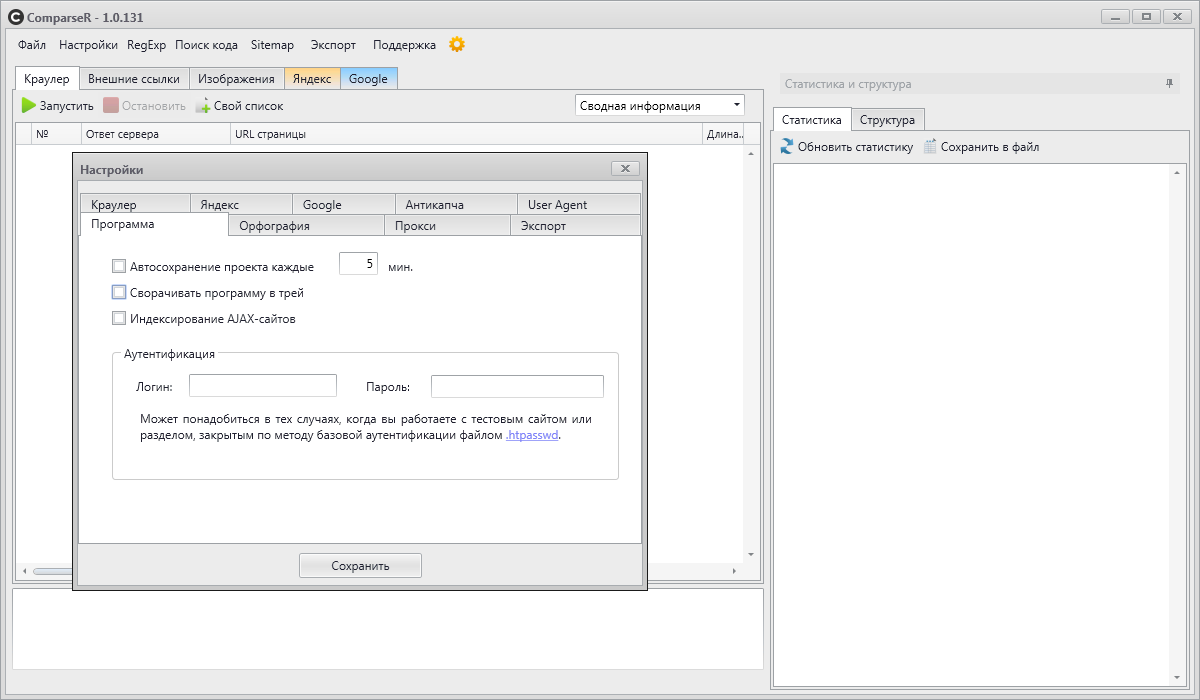
ComparseR

ComparseR – специализированная программа, предназначенная для глубокого изучения индексации сайта.
У демо-версии ComparseR есть 2 ограничения:
Данный парсер примечателен тем, что он заточен на сравнение того, что есть на вашем сайте и тем, что индексируется в поисковых системах.
То есть вы легко найдете страницы, которые не индексируются поисковыми системами, или наоборот, страницы-сироты (страницы, на которые нет ссылок на сайте), о которых вы даже не подозревали.
Стоит отметить, что данный парсер полностью на русском и не так требователен к мощностям компьютера, как другие аналоги.
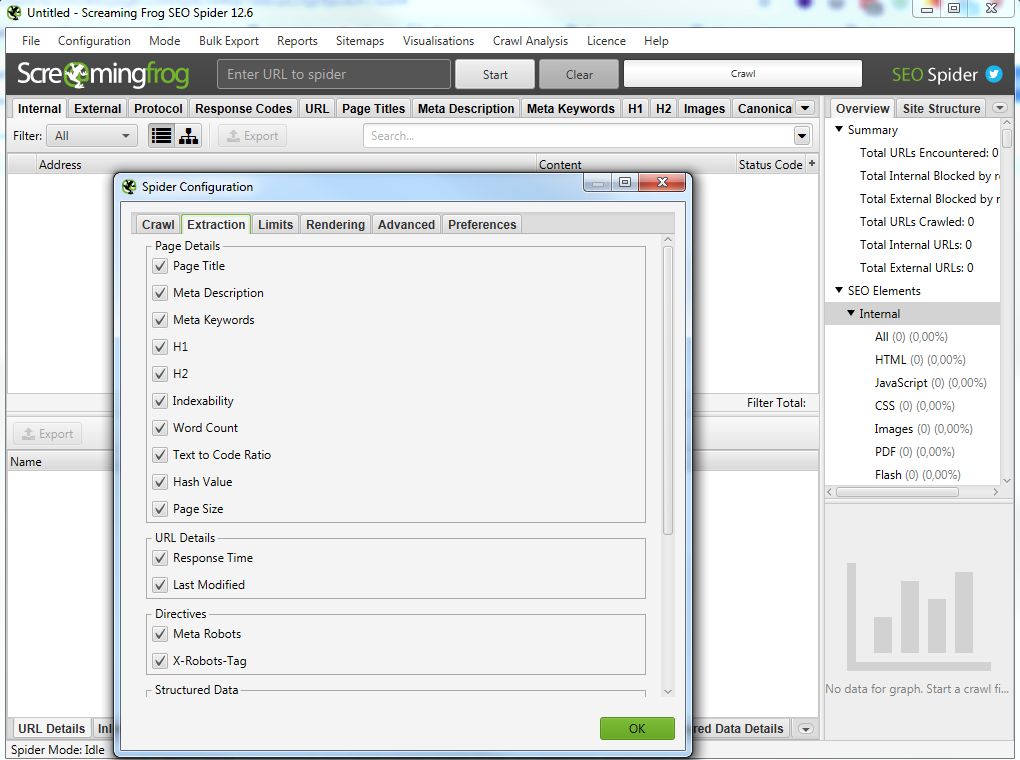
Screaming Frog SEO Spider

Особенности программы:
В бесплатной версии доступна обработка до 500 запросов.
На первый взгляд интерфейс данной программы для парсинга сайтов может показаться сложным и непонятным, особенно из-за отсутствия русского языка.
Не смотря на это, сама программа является великолепным инструментом с множеством возможностей.
Всю необходимую информацию можно узнать из подробного мануала по адресу https://www.screamingfrog.co.uk/seo-spider/user-guide/.
Примеры глубокого парсинга сайта — парсинг с конкретной целью
Пример 1 — Поиск страниц по наличию/отсутствию определенного элемента в коде страниц
Задача: — Спарсить страницы, где не выводится столбец с ценой квартиры.
Как быстро найти такие страницы на сайте с помощью Screaming Frog SEO Spider?
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, который есть на всех искомых страницах.
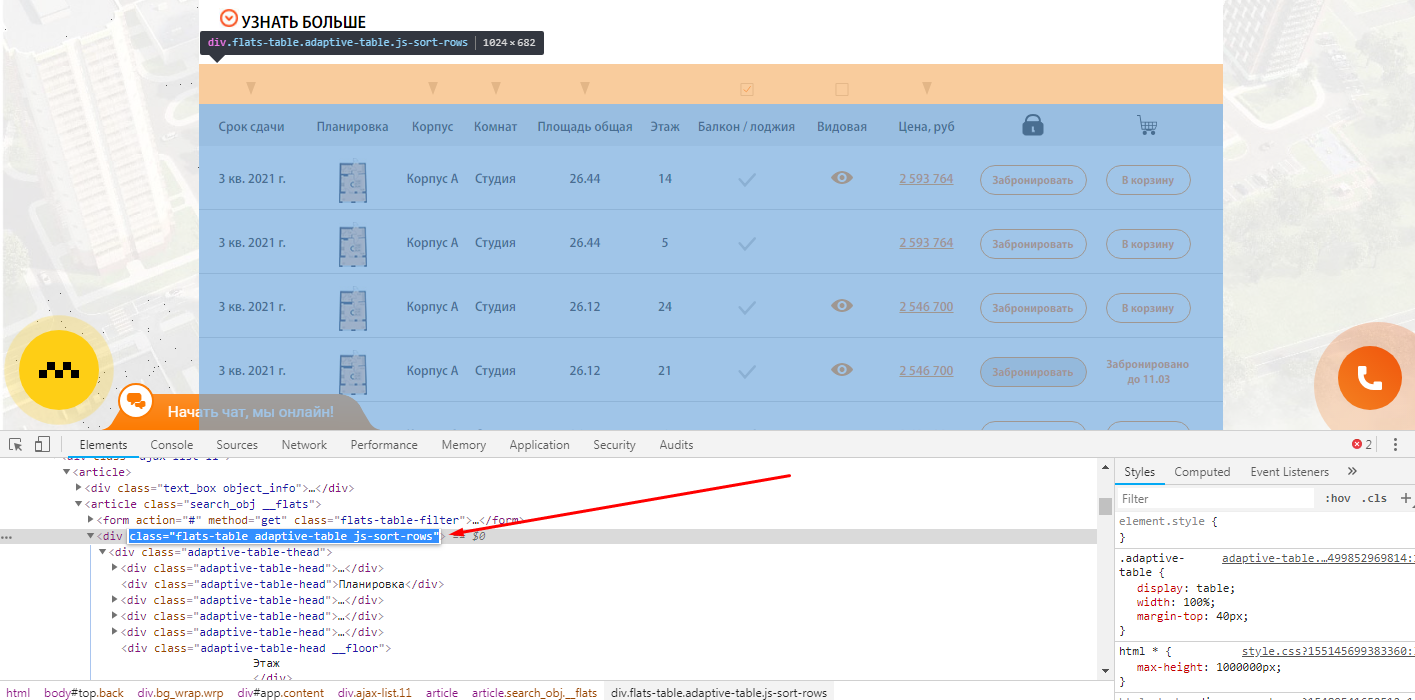
Чтобы было более понятна задача из примера, мы ищем страницы, блок которых выглядит вот так:
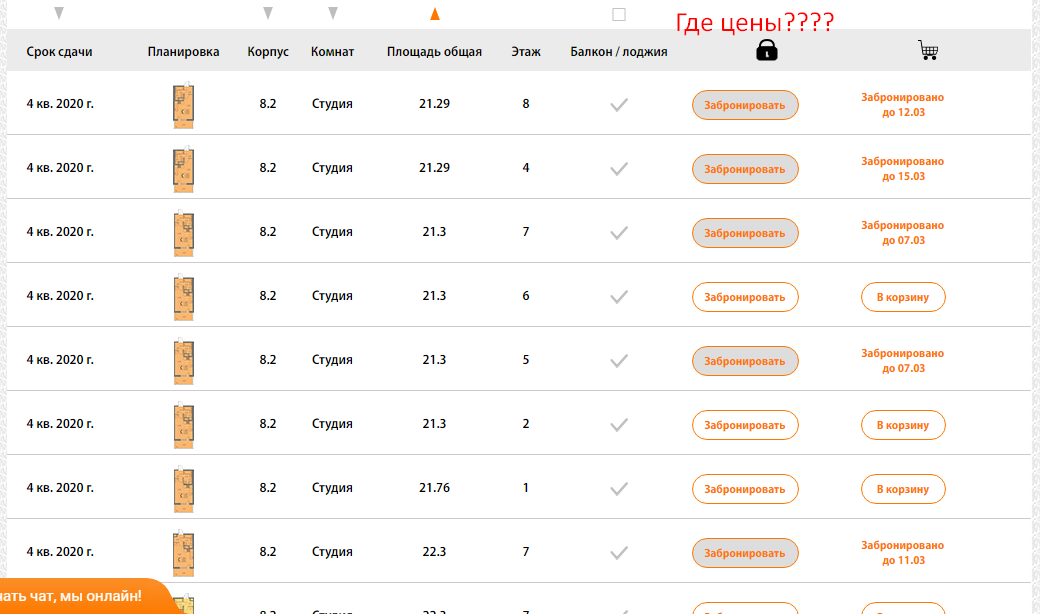
Тут же ищите элемент, который отсутствует на искомых страницах, но присутствует на нормальных страницах.
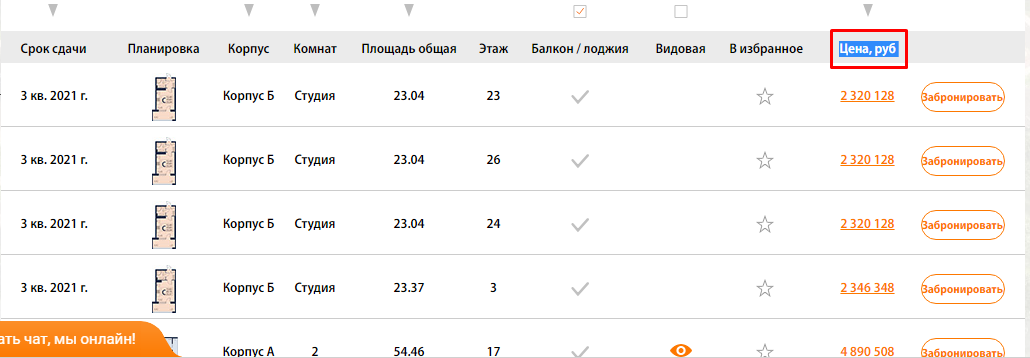
В нашем случае это столбец цен, и мы просто ищем страницы, где отсутствует столбец с таким названием (предварительно проверив, нет ли где в коде закомменченного подобного столбца)
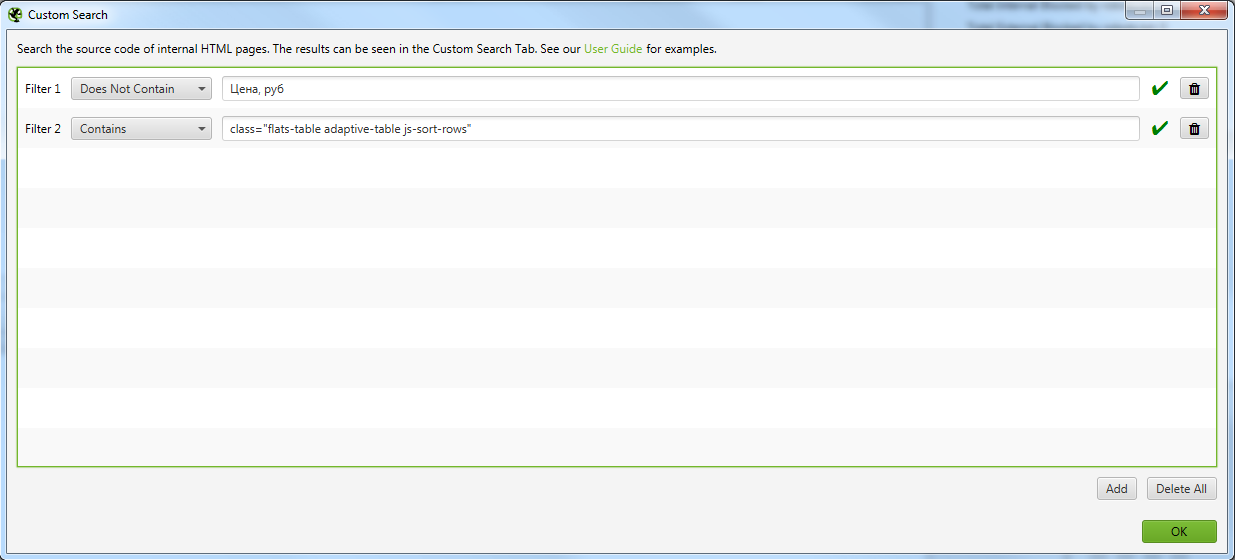
Выгружаем Custom 1 и Custom 2.
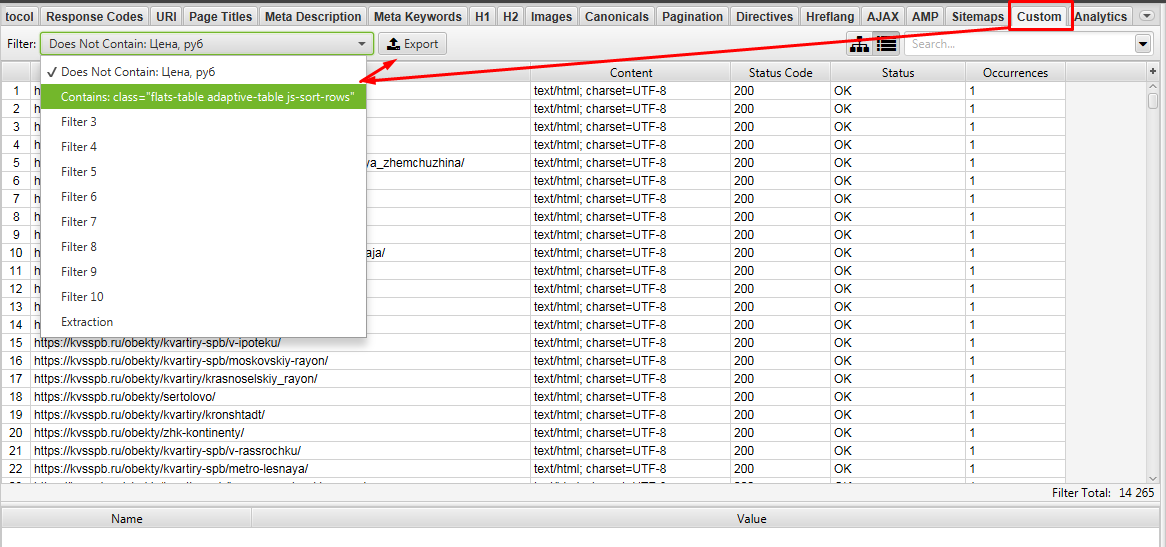
Далее в Excel ищем урлы которые совпадают между файлами Custom 1 и Custom 2. Для этого объединяем 2 файла в 1 таблицу Excel и с помощью «Повторяющихся значений» (предварительно нужно выделить проверяемый столбец).
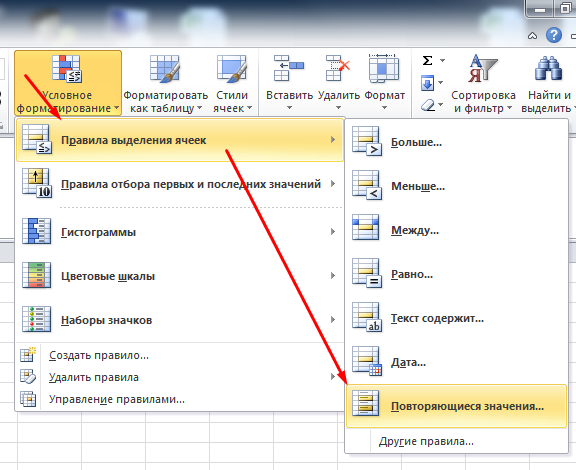
Фильтруем по красному цвету и получаем список урлов, где есть блок с выводом квартир, но нет столбца с ценами)!
Таким способом на сайте можно быстро найти и выгрузить выборку необходимых страниц для различных задач.
Пример 2 — Парсим содержимое заданного элемента на странице с помощью CSSPath
Давайте разбираться, как такое сделать
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, текст которого нам нужно выгружать.
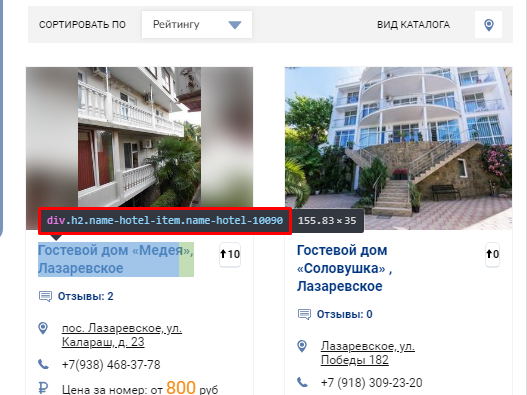
Выглядит это так
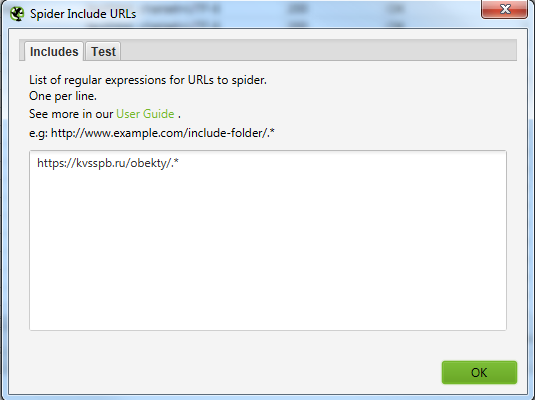
Для того, чтобы не парсить весь сайт целиком, вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить.
Указываем сюда разделы, в которых содержатся все нужные страницы.
Выглядит это вот так для обоих случаев.
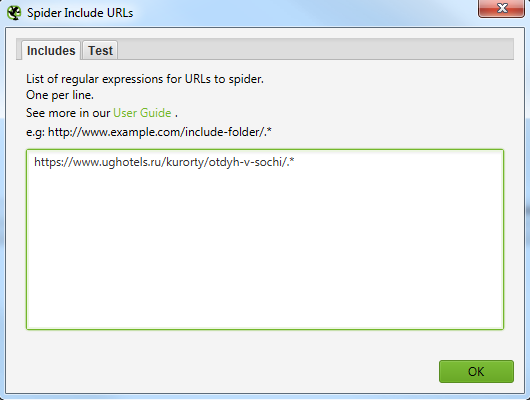
Далее парсим сайт, вбив в строку свой урл. В нашем случае это https://www.ughotels.ru/kurorty/otdyh-v-sochi.
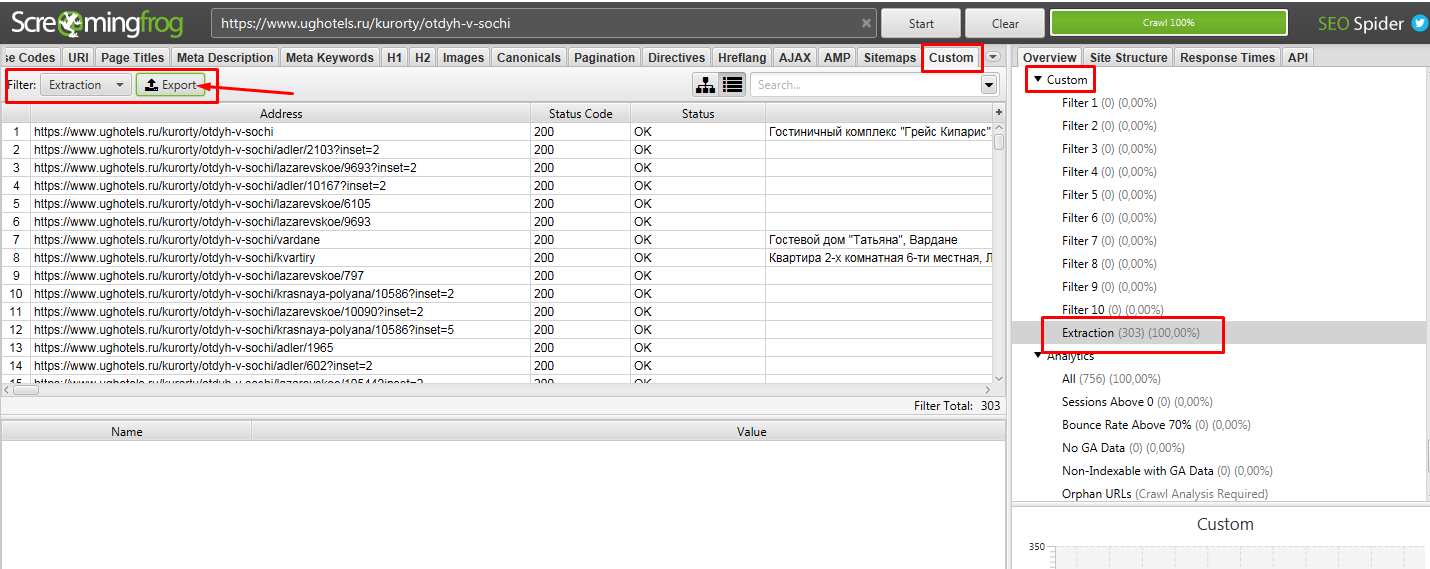
Теперь в Excel чистим файл от пустых данных, так как не на всех страницах есть подобные блоки, поэтому данных нет.
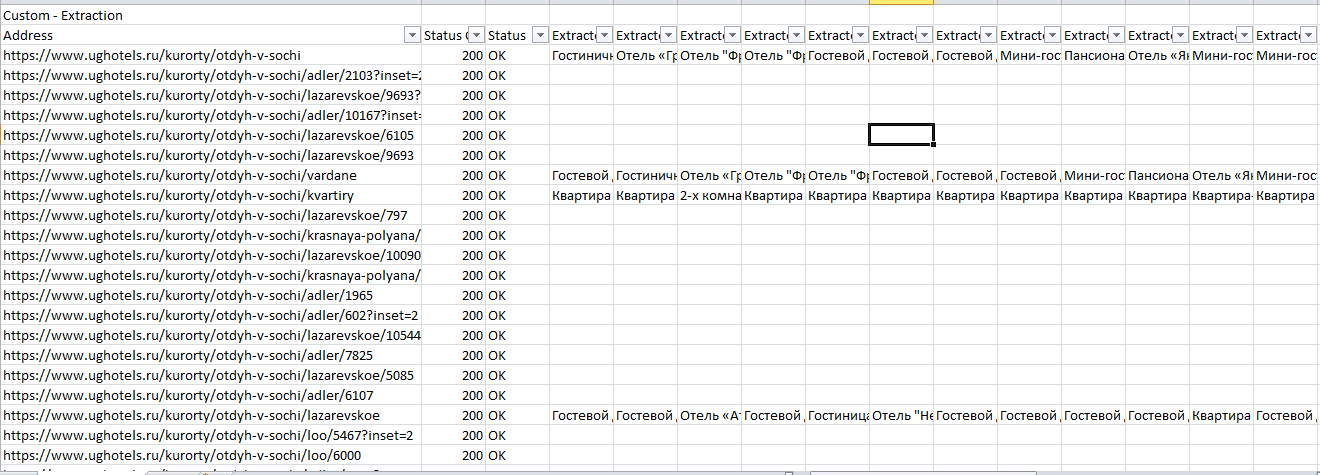
После фильтрации мы рекомендуем для удобства сделать транспонирование таблички на второй вкладке, так ее станет удобнее читать.
Для этого выделяем табличку, копируем и на новой вкладке нажимаем
Получаем итоговый файл: 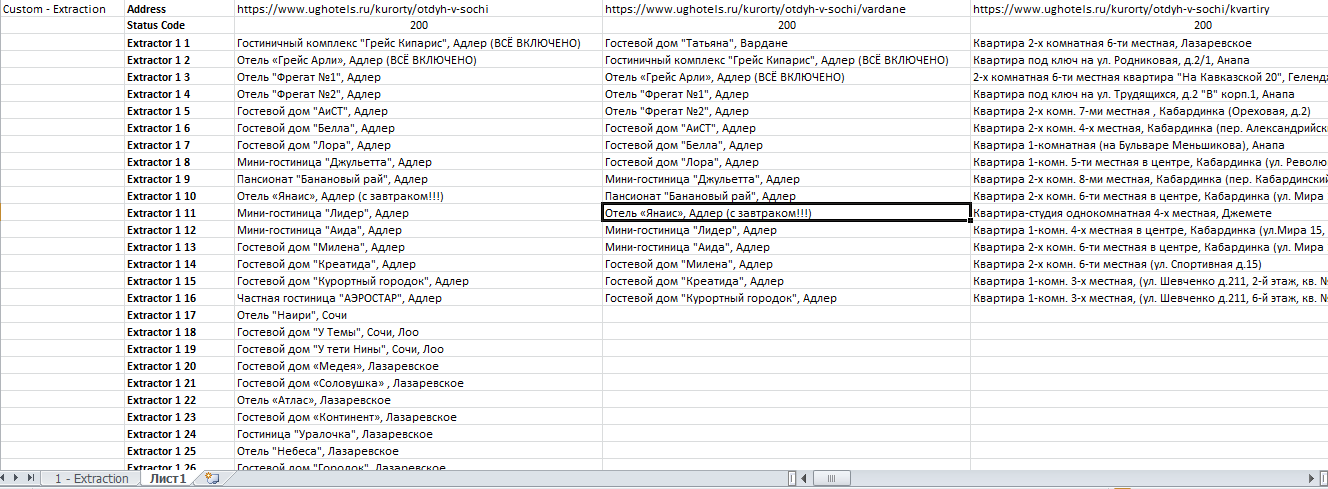
Пример 3 — Извлекаем содержимое нужных нам элементов сайта с помощью запросов XPath
Задача: Допустим, мы хотим спарсить нестандартные, необходимые только нам данные и получить на выходе таблицу с нужными нам столбцами — URL, Title, Description, h1, h2 и текст из конца страниц листингов товаров (например, https://www.funarena.ru/catalog/maty/). Таким образом, решаем сразу 2 задачи:
Сначала немного теории, знание которой позволит решить эту и многие другие задачи.
Технический парсинг сайта и сбор определенных данных со страницы с помощью запросов XPath
Как уже говорилось выше, SEO-специалисты используют технический парсинг сайта в основном для поиска “классических” тех. ошибок. У парсеров даже есть специальные алгоритмы, которые сразу помечают и классифицируют ошибки по типам, облегчая работу SEO специалиста.
Но бывают ситуации, когда с сайта необходимо извлечь содержимое конкретного класса или тега. Для этого на помощь приходит язык запросов XPath. С помощью него можно извлечь с сайта только нужную информацию, записать ее в удобный вид и затем работать с ней.
Ниже приведем примеры некоторых вариантов запросов XPath, которые могут быть вам полезны.
Данные взяты из официальной справки. Там вы сможете увидеть больше примеров.
По умолчанию парсер Screaming Frog SEO Spider собирает только h1 и h2, но если вы хотите собрать h3, то XPath запрос будет выглядеть так:
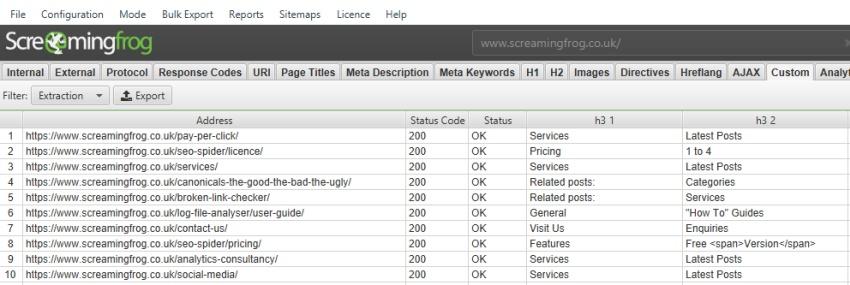
Если вы хотите спарсить только 1-й h3, то XPath запрос будет таким:
/descendant::h3[1]
Чтобы собрать первые 10 h3 на странице, XPath запрос будет:
/descendant::h3[position() >= 0 and position() Теперь вернемся к изначальной задаче
В предыдущем примере мы показали, как парсить с помощью CSSPath, принцип похож, но у него есть свои особенности.
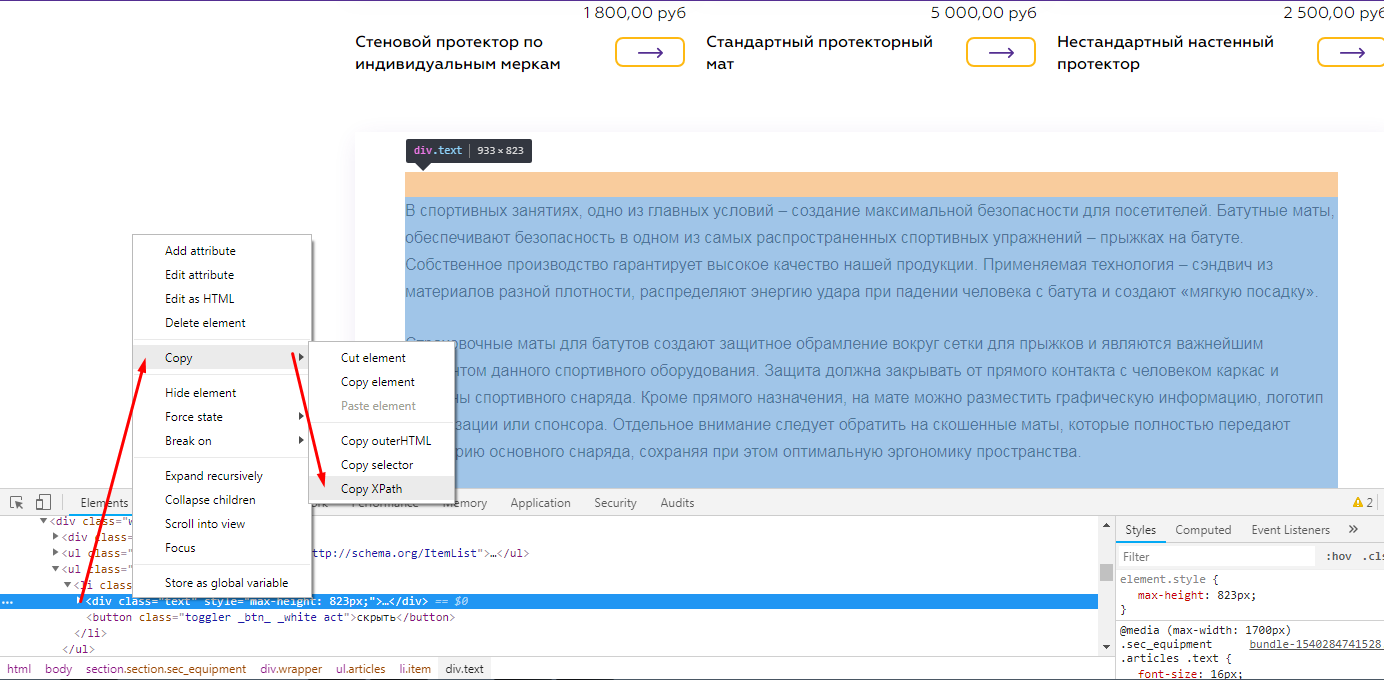
При таком копировании мы получили /html/body/section/div[2]/ul[2]/li/div
Для элементарного понимания, таким образом в коде зашифрована вложенность того места, где расположен текст. И мы получается будем проверять на страницах, есть ли текст по этой вложенности.
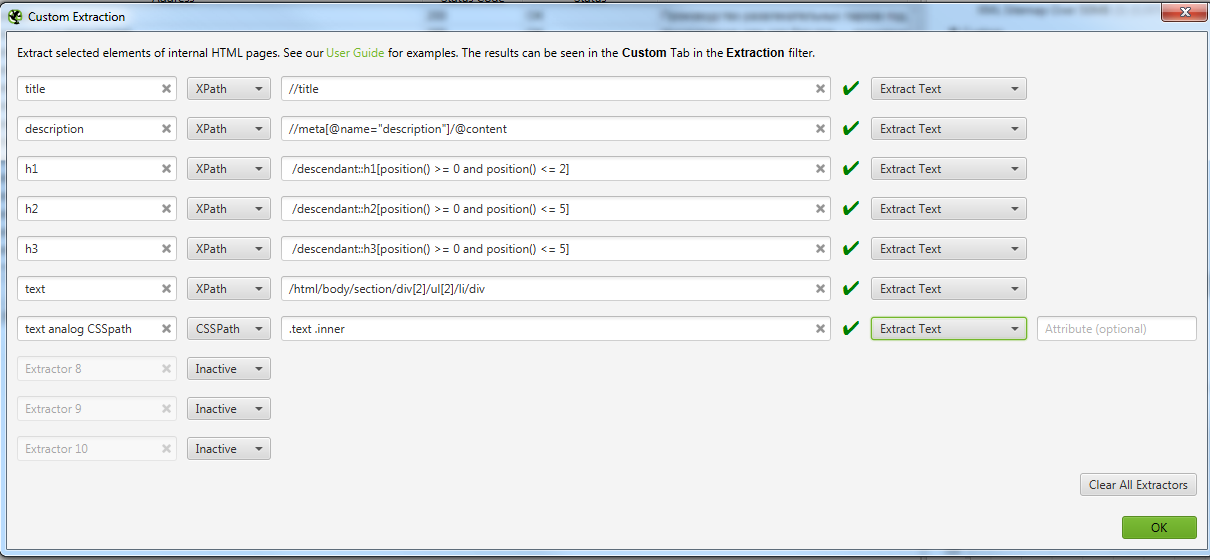
На скрине мы оставили вариант парсинга того же текста, но уже с помощью CSSPath, чтобы показать, что практически все можно спарсить 2-мя способами, но у Xpath все же больше возможностей.
Получаем Excel с нужными нам данными.
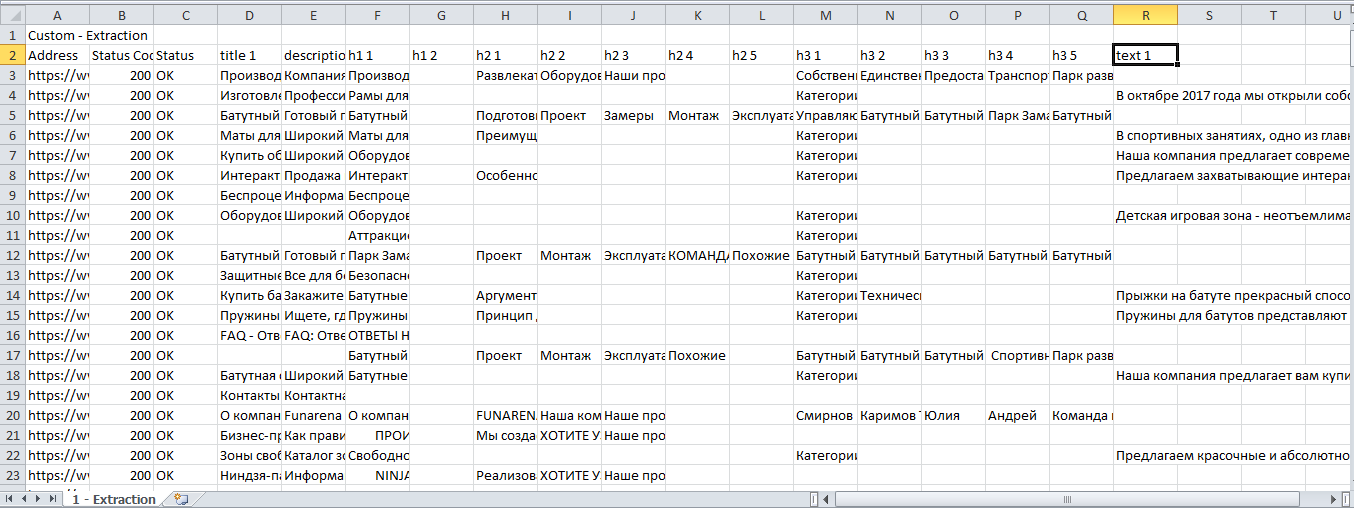
После фильтрации удобно сделать транспонирование полученных данных.

Пример 4 — Как спарсить цены и названия товаров с Интернет магазина конкурента
Задача: Спарсить товары и взять со страницы название товара и цену.

Начнем с того, что ограничим область парсинга до каталога, так как ссылки на все товары ресурса лежат в папке /catalog/. Но нас интересуют именно карточки товаров, а они лежат в папке /product/ и поэтому их тоже нужно парсить, так как информацию мы будем собирать именно с них.
https://okumashop.ru/catalog/.* ← Это страницы на которых расположены ссылки на товары.
https://okumashop.ru/product/.* ← Это страницы товаров, с которых мы будем получать информацию.
Для реализации задуманного мы воспользуемся уже известными нам методами извлечения данных с помощью CSSPath и XPath запросов.
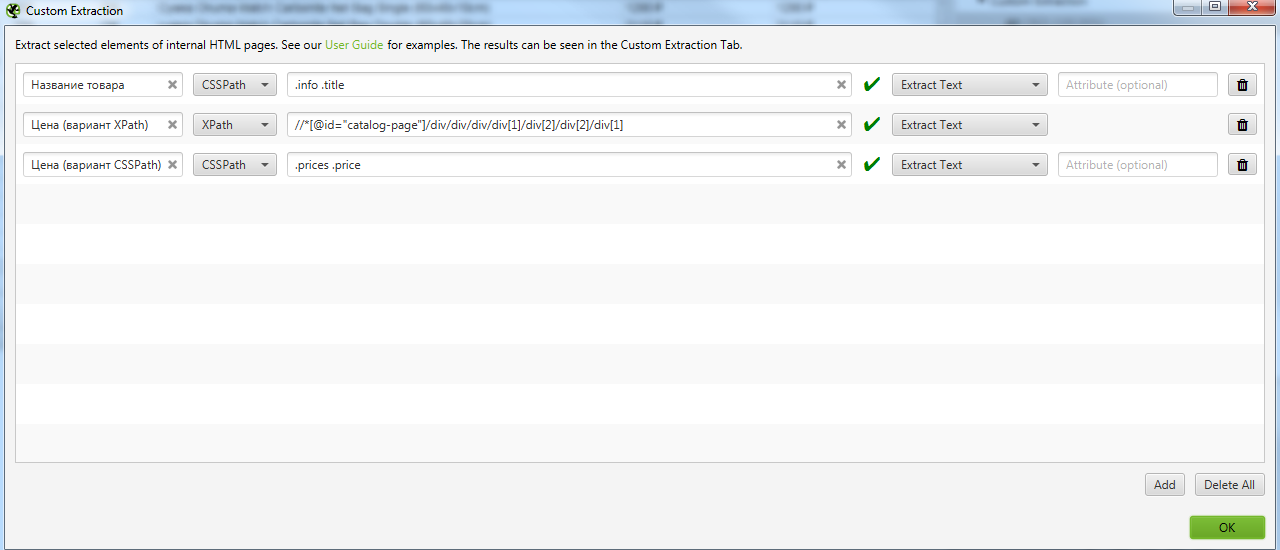
Заходим на любую страницу товара, нажимаем F12 и через кнопку исследования элемента смотрим какой класс у названия товара.
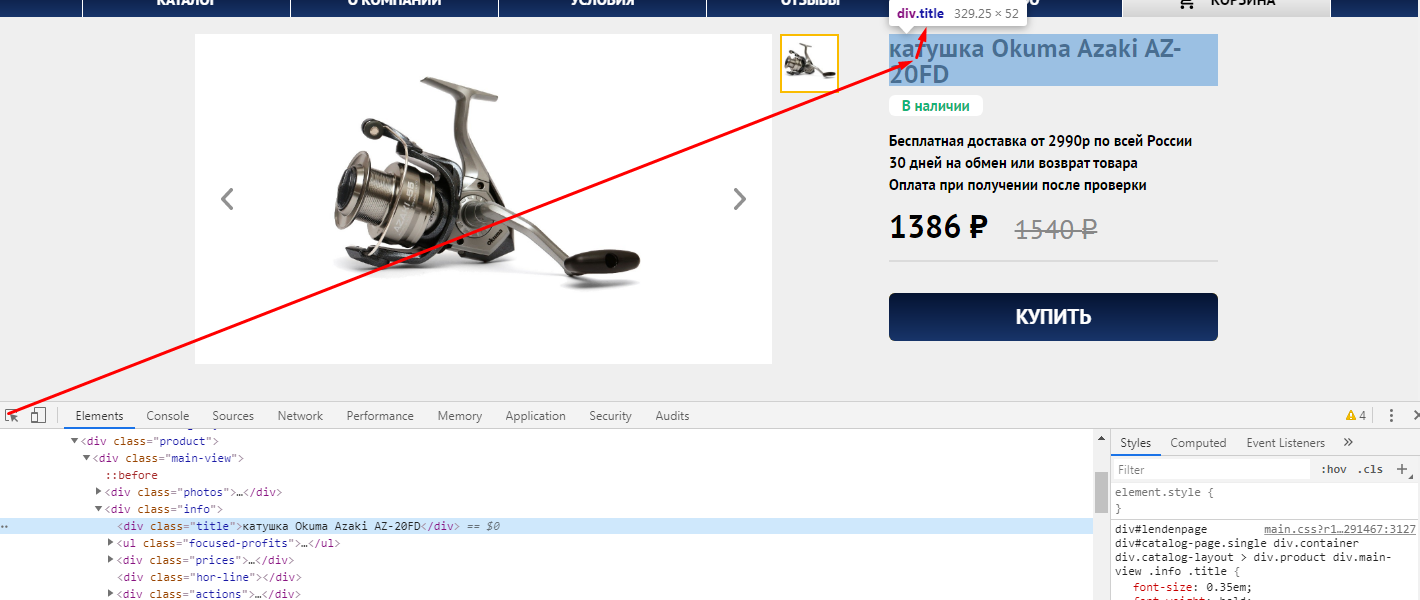
Иногда этого знания достаточно, чтобы получить нужные данные, но всегда стоит проверить, есть ли еще на сайте элементы, размеченные как
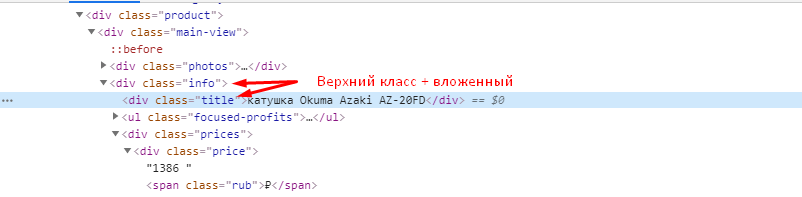
Цену можно получить, как с помощью CSSPath, так и с помощью Xpath.
Если хотим получить цену через XPath, то также через исследование элемента копируем путь XPath.
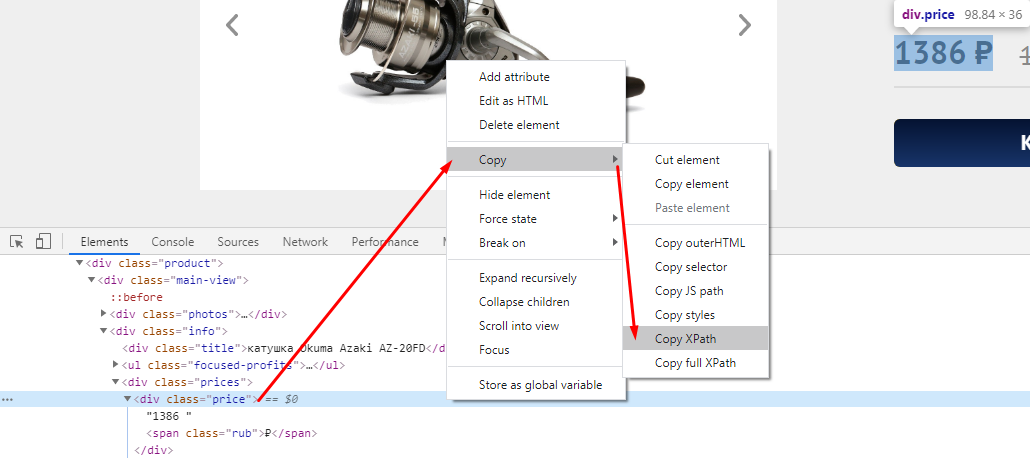
Получаем вот такой код //*[@id=»catalog-page»]/div/div/div/div[1]/div[2]/div[2]/div[1]
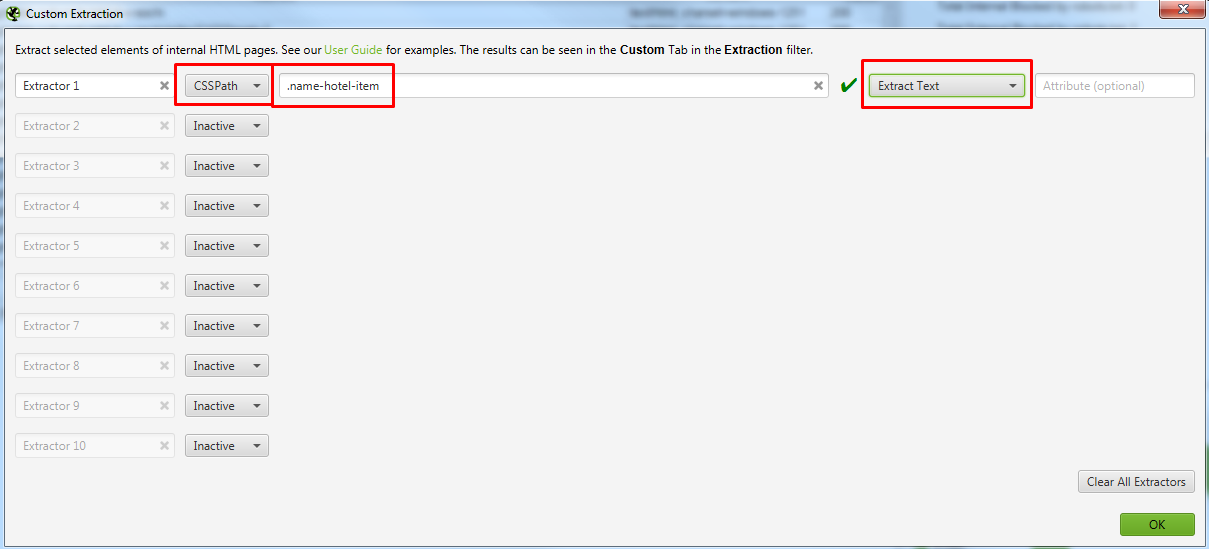
Идем в Configuration → Custom → Extraction и записываем все что мы выявили. Важно выбирать Extract Text, чтобы получать именно текст искомого элемента, а не сам код.
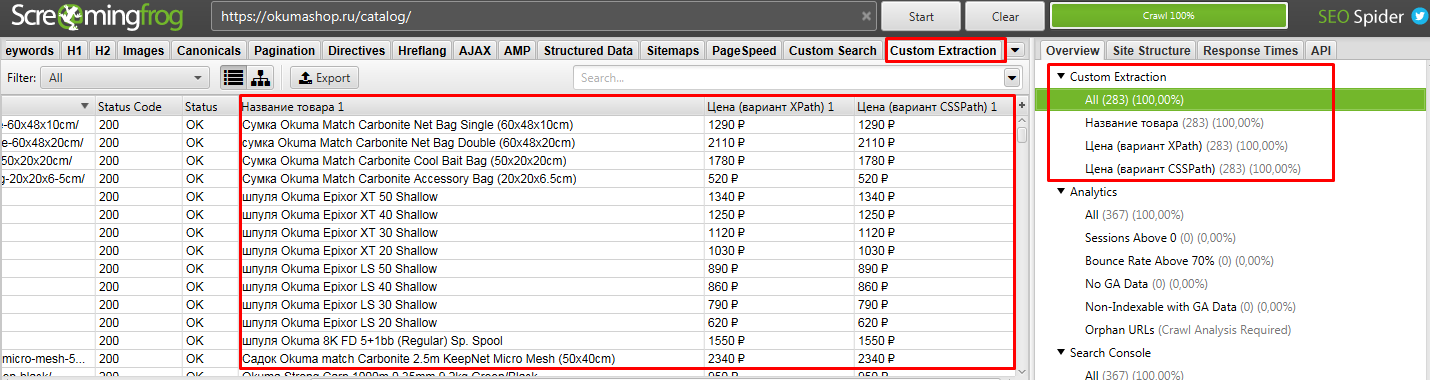
После парсим сайт. То, что мы хотели получить находится в разделе Custom Extraction. Подробнее на скрине.
Выгружаем полученные данные.
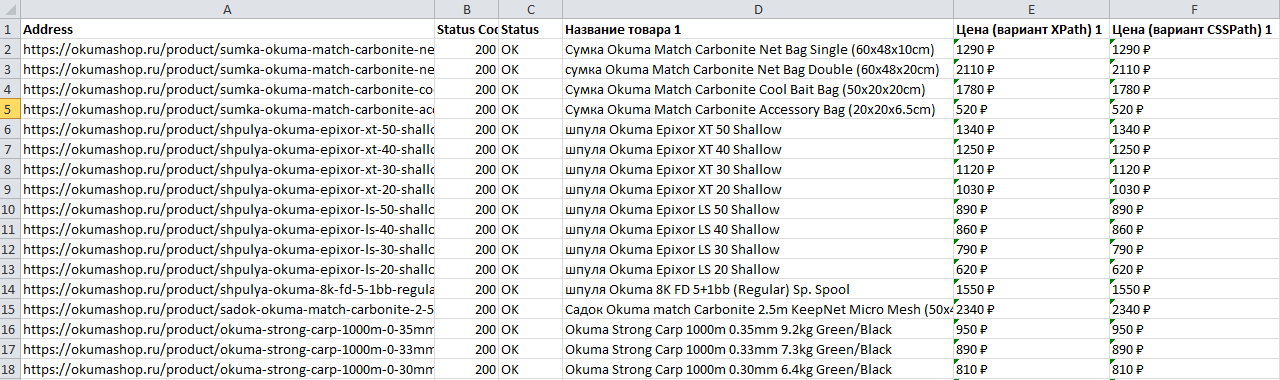
Получаем файл, где есть все необходимое, что мы искали — URL, Название и цена товара
Пример 5 — Поиск страниц-сирот на сайте (Orphan Pages)
Задача: — Поиск страниц, на которые нет ссылок на сайте, то есть им не передается внутренний вес.
Для решения задачи нам потребуется предварительно подключить к Screaming frog SEO spider Google Search Console. Для этого у вас должны быть подтверждены права на сайт через GSC.
Screaming frog SEO spider в итоге спарсит ваш сайт и сравнит найденные страницы с данными GSC. В отчете мы получим страницы, которые она не обнаружила на сайте, но нашла в Search Console.
Давайте разбираться, как такое сделать.
Подключаемся к Google Search Console. Просто нажимаете кнопку, откроется браузер, где нужно выбрать аккаунт и нажать кнопку “Разрешить”.
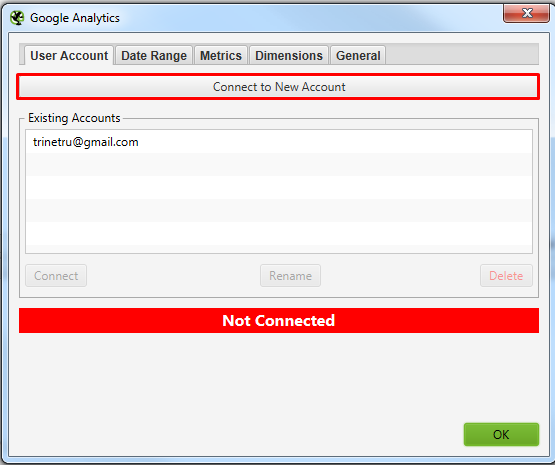
В окошках, указанных выше нужно найти свой сайт, который вы хотите спарсить. С GSC все просто там можно вбить домен. А вот с GA не всегда все просто, нужно знать название аккаунта клиента. Возможно потребуется вручную залезть в GA и посмотреть там, как он называется.
Выбрали, нажали ок. Все готово к чуду.
Теперь можно приступать к парсингу сайта.
Тут ничего нового. Если нужно спарсить конкретный поддомен, то в Include его добавляем и парсим как обычно.
Если по завершению парсинга у вас нет надписи “API 100%”

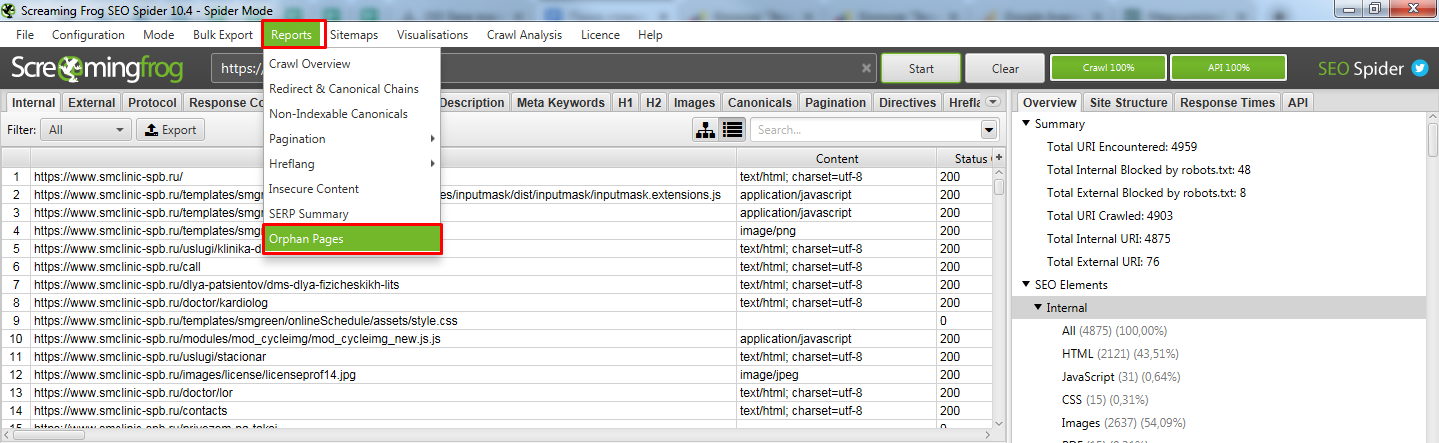
Открываем получившийся отчет. Получили список страниц, которые известны Гуглу, но Screaming frog SEO spider не обнаружил ссылок на них на самом сайте.
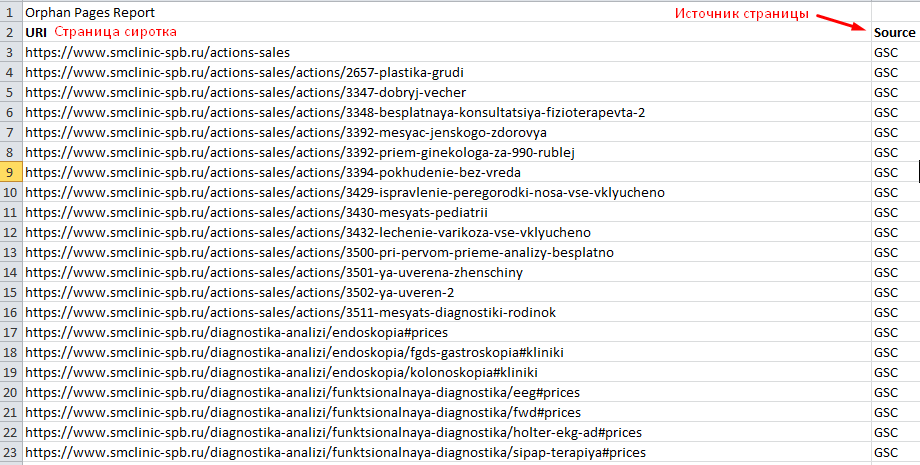
Возможно тут будет много лишних страниц (которые отдают 301 или 404 код ответа), поэтому рекомендуем прогнать весь этот список еще раз, используя метод List.
После парсинга всех найденных страниц, выгружаем список страниц, которые отдают 200 код. Таким образом вы получаете реальный список страниц-сирот с которыми нужно работать.
На такие страницы нужно разместить ссылки на сайте, если в них есть необходимость, либо удаляем страницы или настраиваем 301 редирект на существующие похожие страницы.
Вывод
Парсеры помогают очень быстро решить множество задач не только технического характера (поиска ошибок), но и массу бизнес задач, таких как, собрать структуру сайта конкурента, спарсить цены и названия товаров и и другие полезные данные.



