Вопрос 3 Распределение признака. Параметры распределения
Распределением признака называется закономерность встречаемости разных его значений (Плохинский Н.А., 1970, с. 12).
В психологических исследованиях чаще всего ссылаются на нормальное распределение.
В реальных психологических исследованиях мы оперируем не параметрами, а их приближенными значениями, так называемыми оценками параметров. Это объясняется ограниченностью обследованных выборок. Чем больше выборка, тем ближе может быть оценка параметра к его истинному значению. В дальнейшем, говоря о параметрах, мы будем иметь в виду юс оценки.
Среднее арифметическое (оценка математического ожидания) вычисляется по формуле:


∑— знак суммирования.
Оценка дисперсии определяется по формуле:
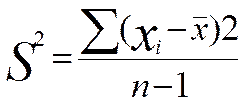

Показатель асимметрии (А)вычисляется по формуле:

Для симметричных распределений А=0.
 |
Рис. 1.5. Асимметрия распределений.
А) Левая, положительная
Б) правая, отрицательная
В тех случаях, когда какие-либо причины способствуют преимущественному появлению средних или близких к средним значений, образуется распределение с положительным эксцессом. Если же в распределении преобладают крайние значения, причем одновременно и более низкие, и более высокие, то такое распределение характеризуется отрицательным эксцессом и в центре распределения может образоваться впадина, превращающая его в двувершинное (см. Рис. 1.6).
Показатель эксцесса (Е) определяется по формуле:

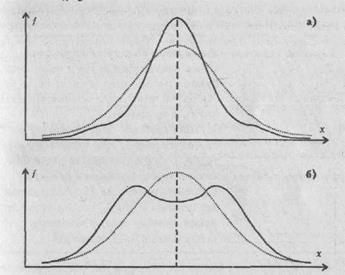
Рис. 1.6. Эксцесс: а) положительный; б) отрицательный
В распределениях с нормальной выпуклостью Е=0.
Параметры распределения оказывается возможным определить только по отношению к данным, представленным по крайней мере в интервальной шкале. Как мы убедились ранее, физические шкалы длин, времени, углов являются интервальными шкалами, и поэтому к ним применимы способы расчета оценок параметров, по крайней мере, с формальной точки зрения. Параметры распределения не учитывают
 истинной психологической неравномерности секунд, миллиметров и других физических единиц измерения.
истинной психологической неравномерности секунд, миллиметров и других физических единиц измерения.
На практике психолог-исследователь может рассчитывать параметры любого распределения, если единицы, которые он использовал при измерении, признаются разумными в научном сообществе.
Распределение признака. Параметры распределения
Распределением признака называется закономерность встречаемости разных его значений (Плохинский Н.А., 1970, с. 12).
В психологических исследованиях чаще всего ссылаются на нормальное распределение.
В реальных психологических исследованиях мы оперируем не параметрами, а их приближенными значениями, так называемыми оценками параметров. Это объясняется ограниченностью обследованных выборок. Чем больше выборка, тем ближе может быть оценка параметра к его истинному значению. В дальнейшем, говоря о параметрах, мы будем иметь в виду их оценки.
Среднее арифметическое (оценка математического ожидания) вычисляется по формуле:

Оценка дисперсии определяется по формуле:

 — среднее арифметическое значение признака;
— среднее арифметическое значение признака;

Показатель асимметрии (A)вычисляется по формуле:

В тех случаях, когда какие-либо причины способствуют преимущественному появлению средних или близких к средним значений, образуется распределение с положительным эксцессом. Если же в распределении преобладают крайние значения, причем одновременно и более низкие, и более высокие, то такое распределение характеризуется отрицательным эксцессом и в центре распределения может образоваться впадина, превращающая его в двувершинное (см. Рис. 1.6).
Показатель эксцесса (E) определяется по формуле:



Рис. 1.6. Эксцесс: а) положительный; 6) отрицательный
В распределениях с нормальной выпуклостью E=0.
Параметры распределения оказывается возможным определить только по отношению к данным, представленным по крайней мере в интервальной шкале. Как мы убедились ранее, физические шкалы длин, времени, углов являются интервальными шкалами, и поэтому к ним применимы способы расчета оценок параметров, по крайней мере, с формальной точки зрения. Параметры распределения не учитывают истинной психологической неравномерности секунд, миллиметров и других физических единиц измерения.
На практике психолог-исследователь может рассчитывать параметры любого распределения, если единицы, которые он использовал при измерении, признаются разумными в научном сообществе.
Статистические гипотезы
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Благодаря гипотезам исследователь не теряет путеводной нити в процессе расчетов и ему легко понять после их окончания, что, собственно, он обнаружил.
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные.
Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий, ибо они более информативны для нас в поиске нового. Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными.
Направленные гипотезы
Ненаправленные гипотезы
Если вы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной смелости, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы.
Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействий произошли более выраженные изменения, чем в группе Б, то нам тоже необходимо сформулировать направленные гипотезы.
Если же мы хотим доказать, что различаются формы распределения признака в группе А и Б, то формулируются ненаправленные гипотезы.
При описании каждого критерия в руководстве даны формулировки гипотез, которые он помогает нам проверить.

Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
Статистические критерии
Статистические критерии обозначают также метод расчета определенного числа и само это число.
По соотношению эмпирического и критического значений критерия мы можем судить о том, подтверждается ли или опровергается нулевая гипотеза. Например, если χ 2 эмп> χ 2 кр, H0 отвергается.
В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, хотя есть критерии (например, критерий Манна-Уитни или критерий знаков), в которых мы должны придерживаться противоположного правила.
Эти правила оговариваются в описании каждого из представленных в руководстве критериев.
В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как п. В этом случае эмпирическое значение критерия одновременно является тестом для проверки статистических гипотез. По специальной таблице мы определяем, какому уровню статистической значимости различий соответствует данная эмпирическая величина. Примером такого критерия является критерий φ*, вычисляемый на основе углового преобразования Шишера.
В большинстве случаев, однако, одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в исследуемой выборке (n) или от так называемого количества степеней свободы, которое обозначается как v или как df.
Число степеней свободы v равно числу классов вариационного ряда минус число условий, при которых он был сформирован (Ивантер Э.В., Коросов А.В., 1992, с. 56). К числу таких условий относятся объем выборки (n), средние и дисперсии.
Способы более сложного подсчета числа степеней свободы при двухмерных классификациях приведены в разделах, посвященных критерию χ 2 и дисперсионному анализу.
Критерии делятся на параметрические и непараметрические.
Параметрические критерии
Непараметрические критерии
Критерии, не включающие в формулу расчета параметров распределения и основанные на оперировании частотами или рангами (критерий Q Розенбаума, критерий Т Вилкоксона и др.)
И те, и другие критерии имеют свои преимущества и недостатки. На основании нескольких руководств можно составить таблицу, позволяющую оценить возможности и ограничения тех и других (Рунион Р., 1982; McCall R., 1970; J.Greene, M.D’Olivera, 1989).
Возможности и ограничения параметрических и непараметрических критериев
Из Табл. 1.1 мы видим, что параметрические критерии могут оказаться несколько более мощными[5], чем непараметрические, но только в том случае, если признак измерен по интервальной шкале и нормально распределен. С интервальной шкалой есть определенные проблемы (см. раздел «Шкалы измерения»). Лишь с некоторой натяжкой мы можем считать данные, представленные не в стандартизованных оценках, как интервальные. Кроме того, проверка распределения «на нормальность» требует достаточно сложных расчетов, результат которых заранее неизвестен (см. параграф 7.2). Может оказаться, что распределение признака отличается от нормального, и нам так или иначе все равно придется обратиться к непараметрическим критериям.
Учитывая это, в настоящее руководство включены в основном непараметрические статистические критерии. В сумме они охватывают большую часть возможных задач сопоставления данных.
Распределение признака. Параметры распределения
В психологических исследованиях при объяснении распределения результатов тестирования используется закон нормального распределения (Лапласа-Гаусса) в целях теоретического распределения случайных, но реальных (переменных) величин. График нормального распреде-ления представляет собой симметричную колоколообразную кривую.

Рис. 4. График нормального распределения признака

Рис. 5 (а, б). Различие распределения вероятностей случайных величин (дискретных
и непрерывных) зависимости от положения на числовой оси (а), рассеивания значений (б),

Рис. 5 (в, г). Различие распределения вероятностей случайных величин (дискретных
и непрерывных) в зависимости от асимметрии (косости, скошенности) рассеивания значений (в),
а также эксцесса (выпуклости, «кучности») рассеивания (г).
При обработке статистического материала необходимо установить форму полученного распределения в целях определения, подчиняется ли оно закону нормального распределения Лапласа-Гаусса.
Статистическая обработка результатов, произведенных в психологическом обследовании измерений, имеет свою логику и проводится по следующим этапам: а) упорядочивание, группировка и табулирование данных по их значениям; б) построение распреде¬ления их частот;
в) выявление центральных тенденций распределения (например, средней арифметической, среднеквадратичного отклонения и пр.); г) оценка типа распределения (разброса данных по отношению к найденной центральной тенденции, асимметрии и пр.).
Упорядочивание результатов измерений
Вслед за упорядочением вариант необходимо провести их группировку.
Группировка данных по их значениям заключается в расположении результатов (оценок), полученных на данной выборке групп испытуемых, в возрастающем или убывающем порядке. Упорядочив варианты, например, по степени их возрастания, получаем следующий статисти-ческий ряд (табл. 8).
Группировка результатов измерений
Табулирование результатов измерений
2-й этап. Построение распределения частот. При обработке статистического материала встает задача установления формы полученного распределения. Представим распределение полученных результатов с учетом встречаемости их частот и отобразим на гистограмме (от минимальной до максимальной оценки) (рис. 6,7).
Рис. 6. Гистограмма 1
Рис. 7. Гистограмма 2
Такая группировка необходима, прежде всего, для качественного анализа полученных результатов, разделяющих обследуемых по каким-либо свойствам, качествам. Единственной количественной оценкой здесь может служить лишь частота встречаемости обследуемых лиц с данными свойствами, качествами.
Выбор типа группировки с определенным интервалом между классами: интервал в 2 единицы необходим для выявления распределения результатов вокруг центрального «пика»; группировка с интервалами в 3 единицы дает более обобщенную и упрощенную картину распределения.
Статистическое распределение может быть представлено графически в виде полигона
частот – ломаной линии, соединяющей точки, соответствующие величинам частот, отклады-ваемым по оси ординат.
Для более наглядного представления общей конфигурации распределения строят полигоны распределения частот, соединив отрезками прямых центры вершин прямоугольников гисто-граммы вправо и влево до нулевых, т.е. крайних значений распределения (рис. 8).

Рис.8. Полигоны распределения частот
В итоге получилась кривая распределения – тот предел, к которому стремится полигон частот при увеличении числа обследуемых в выборке и повышении точности измерения. Форма распределения является некоторой обобщенной характеристикой выборки.
3-й этап. Определение центральной тенденции – осуществляется в целях определения того, насколько полученный в обследовании результат измерения переменных (признаков) является типичным, репрезентативным.

Рис. 9. Параметры распределения
В целях количественного выражения отмеченных тенденций на практике чаще всего пользуются такими параметрами распределения, как: средняя арифметическая  (математическое ожидание), дисперсия S, мода Мо, медиана Ме, показатели асимметрии А и эксцесса Е.
(математическое ожидание), дисперсия S, мода Мо, медиана Ме, показатели асимметрии А и эксцесса Е.

—  — сумма результатов всех измерений (табл. 10).
— сумма результатов всех измерений (табл. 10).
Вычисление среднего арифметического значения
Погрешность полученного среднего арифметического ( ) будет меньше погрешности отдельного измерения (Хn). Сравнение числовых величин средних значений различных обсле-дуемых мало что дает для понимания особенностей распределения. Основным, или опреде-ляющим, для каждого вида средней является качественное ее содержание, т.е. знание того, в каком смысле это средняя, а также в каких пределах идет усреднение.
1. В ряде случаев у распределения может не быть моды – это так называемое «унимодальное» распределение, когда все значения в изучаемой группе встречаются одинаково часто. Пример:
2. Когда два соседних значения имеют одинаковую частоту и они больше частоты любого другого значения, мода есть среднее этих двух значений. Пример: 1, 1, 2, 2, 2, 3, 3, 3, 4. Мо = 2,5.
3. Если два несмежных значения в группе имеют равные частоты и они больше частоты любого другого значения, то имеем две моды. Говорят: группа оценок является бимодальной: Пример: 10, 11, 11, 11, 12, 13, 14, 14, 14, 15. Мо = 11 и 14.
Среди распределений встречаются как «унимодальные», у которых мода отсутствует, так и полимодальные, у которых две и более мод. «Полимодальное» распределение свидетельствует о наличии относительно самостоятельных групп обследуемых, различных по измеряемым психологическим параметрам. Например, при следующих данных выборки наблюдается наличие двух групп чаще всего встречающихся частот в распределении (рис. 10).

Рис. 10. Бимодальное распределение
Данный пример показывает, что исследователь имеет дело с двумя разными выборками, резко отличающимися друг от друга по исследуемому параметру.
Для группы-2 в нашем примере мода равна 15, т.к. этот результат в распределении встре-чается 4 раза и находится примерно в центральной части распределения, что свидетельствует о распределении, близком к нормальному (рис. 11).

Рис.11. Распределение, близкое к нормальному
3. Медиана (Ме) — центральное значение переменной; результат, находящийся в середине последовательности показателей, если их расположить в порядке возрастания или убывания. Медиана делит выборку на две равные по количеству вариант части.
В случае, если число значений n в ряду нечетное, то медиана равна центральному наибольшему значению варианты.
Для группы-1 в нашем примере мы имеем следующий ряд:
Медиана (Ме) в этом случае соответствует 8-му значению варианты, т.е. 15. В случае, если число значений n в ряду четное, то нет истинно медианного значения и тогда за медиану берут среднее арифметическое между Хn/2 и Хn/2+1, например, для ряда
7 8 9 11 12 13 14 16
окажется, что медиана соответствует (11+12) /2 = 11,5
В случае симметричного распределения медиана и мода совпадают со средней арифме-тической. В унимодальных несимметричных выборках среднее арифметическое значение пере-менной, мода и медиана не совпадают (рис. 12).

Рис 12. Графическая иллюстрация меры центральной тенденции на симметричной
и асимметричной кривых распределения
4-й этап. Оценка типа распределения (или разброса) осуществляется в целях проверки предположения о том, что распределение изучаемого психологического явления или процесса подчинено закону нормального распределения и полученная эмпирическая кривая не требует нормализации.
При этом условии распределение можно рассматривать как репрезентативное по отношению к генеральной совокупности и на этой основе определять оценочные нормы. Если это условие не выполняется, то либо мала выборка для проведения обследования, либо методика не является надежной. Распределение считается нормальным, если кривая распределения имеет колоколо-образный вид, а все показатели центральной тенденции совпадают, что свидетельствует о сим-метричности распределения.

Рис. 13. Распределение, близкое к нормальному
В психологических исследованиях чаще всего осуществляется сравнение результатов обсле-дования с нормальным распределением.
— в первом случае – значения переменных сконцентрированы в двух местах, что свидетельствует о наличии двух разнородных выборок (рис. 14);

Рис. 14. Бимодальное распределение
При концентрации значений в правой части кривой наблюдалась бы тенденция к улучшению показателей у большинства обследуемых (рис. 15).

Рис. 15. Виды асимметрий
О наличии отклонений в распределении судят по величине диапазона размаха или разброса данных, т.е. по разнице между максимальным и минимальным значениями.
Так, если в обследуемой группе диапазон распределения до воздействия составлял
Обследуемая группа (до воздействия)
то после воздействия составил 25 – 8 = 17.
Обследуемая группа (после воздействия)
Это позволяет предположить, что воздействие по-разному сказалось на результатах: у одних обследуемых они улучшились, а у других ухудшились.
1. Сначала вычисляют среднее арифметическое значение ( ). Так, например, для следую-щего ряда 3 5 6 9 11 14 среднее арифметическое для данной выборки будет равно: 
2. Затем вычисляют отклонение каждого значения от средней, для чего сумму абсолютных значений делят на число членов ряда:

Каждое из отклонений (d) характеризуется степенью расхождения показателей переменной со средним арифметическим. Общая формула среднего отклонения выглядит следующим образом:
Среднее отклонение (d) = 
Однако среднее отклонение при достаточно большом разбросе значений переменной, при равномерном распределении оценок или при проведении оценок экспертами, стоящими на различных теоретических позициях, лишь приблизительно (усредненно) свидетельствует о разбросе полученных результатов измерений переменной.
В практике анализа полученных данных чаще всего пользуются наиболее информативным показателем разброса – стандартное (?) или среднее квадратическое отклонение (ошибка), которое вычисляется по следующим формулам:

t-критерий Стьюдента и др.), г) проведением корреляционного анализа.
Этими параметрами распределения психодиагност пользуется при статистической обработке результатов выявления и интерпретации результатов.



