Java RegEx: использование регулярных выражений на практике
Авторизуйтесь
Java RegEx: использование регулярных выражений на практике
Рассмотрим регулярные выражения в Java, затронув синтаксис и наиболее популярные конструкции, а также продемонстрируем работу RegEx на примерах.
Основы регулярных выражений
Мы подробно разобрали базис в статье Регулярные выражения для новичков, поэтому здесь пробежимся по основам лишь вскользь.
Определение
Вот самая простая регулярка для такой проверки:
В коде регулярные выражения обычно обозначается как regex, regexp или RE.
Синтаксис RegEx
Символы могут быть буквами, цифрами и метасимволами, которые задают шаблон:

Есть и другие конструкции, с помощью которых можно сокращать регулярки:
Квантификаторы
Это специальные ограничители, с помощью которых определяется частота появления элемента — символа, группы символов, etc:
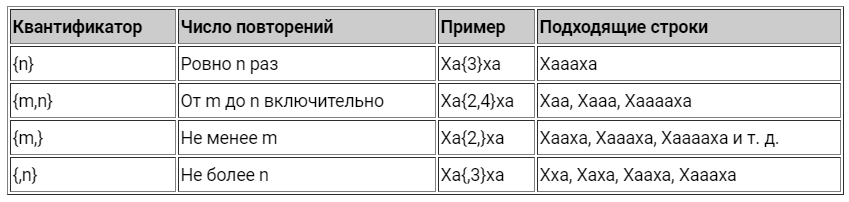
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Также квантификаторов есть три режима:
По умолчанию квантификатор всегда работает в жадном режиме. Подробнее о квантификаторах в Java вы можете почитать здесь.
Примеры их использования рассмотрим чуть дальше.
Регулярные выражения в Java
Поскольку мы говорим о регекспах в Java, то следует учитывать спецификации данного языка программирования.
Экранирование символов в регулярных выражениях Java
В коде Java нередко можно встретить обратную косую черту \ : этот символ означает, что следующий за ним символ является специальным, и что его нужно особым образом интерпретировать. Так, \n означает перенос строки. Посмотрим на примере:
Поэтому в регулярных выражениях для, например, метасимволов, используется двойная косая черта, чтобы указать компилятору Java, что это элемент регулярки. Пример записи поиска символов пробела:
Ключевые классы
Java RegExp обеспечиваются пакетом java.util.regex. Здесь ключевыми являются три класса:
Также есть интерфейс MatchResult, который представляет результат операции сопоставления.
Примеры использования регулярных выражений в Java
e-mail адрес
В качестве первого примера мы упомянули регулярку, которая проверяет e-mail адрес на валидность. И вот как эта проверка выглядит в Java-коде:
Телефонный номер
Регулярное выражение для валидации номера телефона:
Эта регулярка ориентирована на российские мобильные номера, а также на городские с кодом из трёх цифр. Попробуйте написать код самостоятельно по принципу проверки e-mail адреса.
IP адрес
А вот класс для определения валидности IP адреса, записанного в десятичном виде:
Правильное количество открытых и закрытых скобок в строке
На каждую открытую должна приходиться одна закрытая скобка:
Извлечение даты
Теперь давайте извлечём дату из строки:
А вот использование различных режимов квантификаторов, принцип работы которых мы рассмотрели чуть ранее.
Жадный режим
Сверхжадный режим
Принцип, как и в жадном режиме, только поиск заданного символа в обратном направлении не происходит. В приведённой строке всё аналогично: заданная стартовая позиция – это 0, а последняя – 2.
Ленивый режим
Здесь всё просто: самое короткое совпадение находится на первой, второй и третьей позиции заданной строки.
Выводы
Общий принцип использования регулярных выражений сохраняется от языка к языку, однако если мы всё-таки говорим о RegEx в конкретном языке программирования, следует учитывать его спецификации. В Java это экранирование символов, использование специальной библиотеки java.util.regex и её классов.
А какие примеры использования регулярных выражений в Java хотели бы видеть вы? Напишите в комментариях.
25 самых используемых регулярных выражений в Java
Список из 25 регулярных выражений в Java, без которых не обойтись ни новичку, ни профессиональному разработчику. С примерами.

Что такое Regex
Глупо спрашивать об очевидном, но вдруг вы новичок в сфере разработки? 😉
Регулярное выражение – это строка, последовательность символов. Данную строку также принято называть шаблоном, по которому происходит поиск соответствий в других последовательностях символов. Но не каждая строка компилируется в регулярное выражение, а только та, что соответствует их синтаксису.

Что за зверь «Pattern»?
Что за зверь «Matcher»?
Класс Java Matcher ( java.util.regex.Matcher ) создан для поиска некоторого множества вхождений регулярного выражения в одном тексте и поиска по одному шаблону в разных текстах. Класс Java Matcher имеет много полезных методов.
Другие методы Matcher можно найти в официальной документации.
25 самых используемых регулярных выражений
| . | Соответствие одиночному символу |
| ^regex | Поиск регулярного выражения с совпадением в начале строки |
| regex$ | Поиск регулярного выражения с совпадением в конце строки |
| [abc] | Поиск любого символа, заключенного в квадратные скобки |
| [abc][vz] | Находит значение символа a, b или c, за которыми следуют v или z |
| [^ xyz] | Когда символ располагается перед остальными символами в квадратных скобках, он «отрицает» шаблон. Данный шаблон соответствует любому символу, кроме x, y или z. |
| [a-d1-7] | Диапазоны: соответствует букве между a и d и цифрами от 1 до 7, но не d-1. |
| X|Z | Находит X или Z |
| $ | Конец строки |
| ^ | Начало строки |
| (re) | Создает группу из регулярных выражений, запоминая текст для сравнивания |
| (?: re) | Действует как (re), но не запоминает текст |
| Regex | Значение |
| \d | Любая цифра (эквивалентно 7) |
| \D | Любой символ, кроме цифер |
| \s | Символ пробела, сокращение от [\t \n \x0b \r \f] |
| \S | Любой символ, кроме пробела. |
| \w | Символы, соответствующие словам, сокращение от [a-zA-Z_0-9] |
| \W | Символы, не образующие слов, сокращение [\w] |
| \b | Соответствует границе слова, где символом слова является [a-zA-Z0-9_] |
| \B | Соответствует границам символов, не являющихся словами |
| \G | Точка предыдущего соответствия |
Квантификаторы
Квантификаторы имеют три режима, которые называют сверхжадным, жадным и ленивым.
Жадный режим
“A.+a”// Ищет максимальное по длине совпадение в строке.
Output:
Сверхжадный режим
«А.++а»?// Работает также как и жадный режим, но не производит реверсивный поиск при захвате строки.
Output:
Ленивый режим
“A.+?a”// Ищет самое короткое совпадение.
Output:
Профессиональные разработчики все время работают с регулярными выражениями. Перенимайте их практику: при частом использовании регулярки запомнятся быстро и существенно сэкономят время.
У вас случалось, что вы не можете вспомнить, что сами написали ранее? 🙂 Следите, чтобы регулярные выражения комментировались в коде. Особенно это касается новых для вас регулярок. А если всё-таки запутаетесь, помогут сервисы для тестирования и отладки.
Хотите расширить диапазон нашего must-have списка? Пишите в комментариях, что бы вы добавили в наш ТОП.
Регулярные выражения java примеры
Java предоставляет пакет java.util.regex для сопоставления с шаблоном с регулярными выражениями. Регулярные выражения Java очень похожи на язык программирования Perl и очень просты в освоении.
Регулярное выражение(regular expressions) – это специальная последовательность символов, которая помогает вам сопоставлять или находить другие строки или наборы строк, используя специальный синтаксис, содержащийся в шаблоне. Их можно использовать для поиска, редактирования или манипулирования текстом и данными.
Шаблон поиска может быть любым из простого символа, фиксированной строки или сложного выражения, содержащего специальные символы, описывающие шаблон. Шаблон, определенный выражением, может совпадать один или несколько раз или не совпадать для данной строки.
Шаблон применяется к тексту слева направо. Как только исходный символ был найден, его нельзя уже использовать повторно. Например, выражение aba будет соответствовать ababababa только два раза (aba_aba__)
Пакет java.util.regex в основном состоит из следующих трех классов:
Capturing groups
Группы захвата(Capturing groups) – это способ рассматривать несколько символов как единое целое. Они создаются путем помещения символов, которые будут сгруппированы, в набор скобок.
Например, (dog) создает одну группу, содержащую буквы «d», «o» и «g».
Группы захвата нумеруются путем подсчета открывающих скобок слева направо. В выражении ((A) (B (C))), например, есть четыре такие группы –
Чтобы узнать, сколько групп присутствует в выражении, вызовите метод groupCount для объекта соответствия. Метод groupCount возвращает int, показывающий количество групп захвата, присутствующих в шаблоне сопоставителя.
Существует также специальная группа, группа 0, которая всегда представляет все выражение. Эта группа не включена в общее количество, сообщенное groupCount.
В следующем примере показано, как найти строку цифр из заданной буквенно-цифровой строки:
Это даст следующий результат:
Found value: This order was placed for QT3000! OK?
Found value: This order was placed for QT300
Found value: 0
Синтаксис регулярных выражений в Java
Вот таблица со списком всех синтаксисов регулярных выражений, доступных в Java:
| Subexpression | Соответствия |
|---|---|
| ^ | Соответствует началу строки. |
| $ | Соответствует концу строки. |
| . | любому отдельному символу, кроме новой строки. Использование опции m позволяет ему соответствовать и новой строке. |
| […] | любому отдельному символу в скобках. |
| [^…] | любому отдельному символу не в скобках. |
| \A | Начало всей строки. |
| \z | Конец всей строки. |
| \Z | Конец всей строки, кроме допустимого конечного terminator. |
| re* | Соответствует 0 или более вхождений предыдущего выражения. |
| re+ | Соответствует 1 или более из предыдущего. |
| re? | Соответствует 0 или 1 вхождению предыдущего выражения. |
| re | Совпадает ровно с числом вхождений предыдущего выражения. |
| re | Соответствует n или более вхождений предыдущего выражения. |
| re | Соответствует не менее n и не более m вхождений предыдущего выражения. |
| a| b | Соответствует либо a, либо b. |
| (re) | Группирует регулярные выражения и запоминает сопоставленный текст. |
| (?: re) | Группирует без запоминания сопоставленного текста. |
| (?> re) | Соответствует независимому паттерну без возврата. |
| \w | Слову из символов. |
| \W | несловесным символам. |
| \s | Соответствует пробелу. Эквивалентно [\t\n\r\f]. |
| \S | без пробелов. |
| \d | Соответствует цифрам. Эквивалентно 7. |
| \D | Совпадает с “не цифрами”. |
| \A | началу строки. |
| \Z | концу строки. Если новая строка существует, она совпадает непосредственно перед новой строкой. |
| \z | концу строки. |
| \G | точке, где закончился последний. |
| \n | Обратная ссылка для захвата номера группы “n”. |
| \b | Соответствует границам слов вне скобок. Соответствует возврату (0x08) внутри скобок. |
| \B | границам без слов. |
| \n, \t, etc. | Сопоставляет переводы строк, возврат каретки, вкладки и т. д. |
| \Q | Escape (цитата) все символы до \E. |
| \E | Завершает цитирование, начинающееся с \ Q. |
Обратная косая черта имеет предопределенное значение в Java. Вы должны использовать двойную обратную косую черту \\, чтобы определить одну обратную косую черту. Если вы хотите определить \w, то вы должны использовать \\w.
Методы класса Matcher
Вот список полезных методов экземпляра – Index methods предоставляют полезные значения индекса, которые точно показывают, где совпадение было найдено во входной строке.
| № | Метод и описание |
|---|---|
| 1 | public int start() Возвращает начальный индекс предыдущего match. |
| 2 | public int start(int group) Возвращает начальный индекс подпоследовательности, захваченной данной группой во время предыдущей операции сопоставления. |
| 3 | public int end() Возвращает смещение после последнего совпадения символов. |
| 4 | public int end(int group) Возвращает смещение после последнего символа подпоследовательности, захваченной данной группой во время предыдущей операции сопоставления. |
Методы Study
Методы Study проверяют входную строку и возвращают логическое значение, указывающее, найден ли шаблон.
| № | Метод и описание |
|---|---|
| 1 | public boolean lookingAt() Пытается сопоставить входную последовательность, начиная с начала, с шаблоном. |
| 2 | public boolean find() Пытается найти следующую подпоследовательность входной последовательности, которая соответствует шаблону. |
| 3 | public boolean find(int start) Сбрасывает это сопоставление и затем пытается найти следующую подпоследовательность входной последовательности, которая соответствует шаблону, начиная с указанного индекса. |
| 4 | public boolean matches() Попытки сопоставить весь регион с паттерном. |
Методы замены
Методы замены являются полезными методами для замены текста во входной строке.
| № | метод и описание |
|---|---|
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) Реализует нетерминальный шаг добавления и замены. |
| 2 | public StringBuffer appendTail(StringBuffer sb) Реализует шаг добавления и замены терминала. |
| 3 | public String replaceAll(String replacement) Заменяет каждую подпоследовательность входной последовательности, которая соответствует шаблону с данной строкой замены. |
| 4 | public String replaceFirst(String replacement) Заменяет первую подпоследовательность входной последовательности, которая соответствует шаблону с данной строкой замены. |
| 5 | public static String quoteReplacement(String s) Возвращает буквенную замещающую строку для указанной строки. Этот метод создает строку, которая будет работать в качестве литеральной замены в методе appendReplacement класса Matcher. |
Методы начала и конца
Ниже приведен пример, который подсчитывает, сколько раз слово cat (кот) появляется во входной строке:
Получим результат:
Match number 1
start(): 0
end(): 3
Match number 2
start(): 4
end(): 7
Match number 3
start(): 8
end(): 11
Match number 4
start(): 19
end(): 22
Этот пример использует границы слов, чтобы гарантировать, что буквы “c” “a” “t” не являются просто подстрокой в более длинном слове. Это также дает некоторую полезную информацию о том, где во входной строке произошло совпадение.
Метод start возвращает начальный индекс подпоследовательности, захваченной данной группой во время предыдущей операции сопоставления, а end возвращает индекс последнего сопоставленного символа плюс один.
Методы поиска(lookingAt)
Методы match и LookingAt пытаются сопоставить входную последовательность с шаблоном. Разница, однако, заключается в том, что для matches требуется сопоставление всей входной последовательности, а для lookingAt – нет.
Оба метода всегда начинаются с начала строки ввода. Вот пример:
Получим следующий результат:
Current REGEX is: foo
Current INPUT is: fooooooooooooooooo
lookingAt(): true
matches(): false
Методы replaceFirst и replaceAll
Методы replaceFirst и replaceAll заменяют текст, соответствующий заданному регулярному выражению. replaceFirst заменяет первое вхождение, а replaceAll заменяет все вхождения.
Вот пример, объясняющий их работу:
И теперь вывод:
The cat says meow. All cats say meow.
Методы appendReplace и appendTail
Класс Matcher также предоставляет методы appendReplacement и appendTail для замены текста.
Методы класса PatternSyntaxException
PatternSyntaxException – это непроверенное исключение, которое указывает на синтаксическую ошибку в шаблоне. Класс PatternSyntaxException предоставляет следующие методы, чтобы помочь вам определить, что пошло не так:
| № | метод и описание |
|---|---|
| 1 | public String getDescription() Получает описание ошибки. |
| 2 | public int getIndex() Получает индекс ошибки. |
| 3 | public String getPattern() Извлекает ошибочный шаблон регулярного выражения. |
| 4 | public String getMessage() Возвращает многострочную строку, содержащую описание синтаксической ошибки и ее индекс, ошибочный шаблон регулярного выражения и визуальную индикацию индекса ошибки в шаблоне. |
Примеры
Напишите регулярное выражение, которое соответствует любому номеру телефона.
Телефонный номер в этом примере состоит либо из 7 номеров подряд, либо из 3 номеров, пробела или тире, а затем из 4 номеров.
В следующем примере проверяется, содержит ли текст число из 3 цифр.
В следующем примере показано как извлечь все действительные ссылки с веб-страницы. Не учитывает ссылки, начинающиеся с «javascript:» или «mailto:».
Поиск дублированных слов.
\b(\w+)\s+\1\b
\b является границей слова и \1 ссылается на совпадение первой группы, то есть первого слова. (?!-in)\b(\w+) \1\b находит повторяющиеся слова, если они не начинаются с “-in”. Добавьте (?S) для поиска по нескольким строкам.
Поиск элементов, которые начинаются с новой строки.
(\n\s*)title
Также можете посмотреть официальную документацию тут.
Средняя оценка / 5. Количество голосов:
Или поделись статьей
Видим, что вы не нашли ответ на свой вопрос.
Java Regex – регулярные выражения
Java Regex является официальным API регулярных выражений Java. Находится в пакете java.util.regex, который является частью стандартной JSE начиная с версии 1.4.
Регулярное выражение – это текстовый шаблон, используемый для поиска в тексте. Вы делаете это путем «сопоставления» его с текстом. Результат:
Например, вы можете использовать регулярное выражение для поиска в строке адресов электронной почты, URL-адресов, телефонных номеров, дат и т. д. Это можно сделать путем сопоставления различных выражений со строкой. Результатом сопоставления каждого из них будет набор совпадений – один набор совпадений для каждого выражения (может совпадать более одного раза).
Java Regex Core Classes
Состоит из двух основных классов:
Класс Pattern используется для создания шаблонов. Шаблон – это предварительно скомпилированное регулярное выражение в форме объекта (как экземпляр шаблона), способное сопоставляться с текстом.
Класс Matcher используется для сопоставления заданного экземпляра Pattern с текстом несколько раз. Другими словами, искать несколько вхождений в тексте. Matcher скажет вам, где в тексте (индекс символа) он нашел вхождения. Вы можете получить экземпляр Matcher из экземпляра Pattern.
Пример Pattern
Вот простой пример, чтобы проверить, содержит ли текст подстроку http: //:
Текстовая переменная содержит текст для проверки с помощью регулярного выражения.
Переменная pattern содержит выражение в виде String. Оно соответствует всем текстам, содержащим один или несколько символов (. *), за которыми следует текст http: //, а за ним следует один или несколько символов (. *).
В третьей строке используется статический метод Pattern.matches(), чтобы проверить, соответствует ли шаблон тексту. Если да, то Pattern.matches() возвращает true. Если нет, false.
Пример Matcher
Используем класс Matcher для поиска нескольких вхождений подстроки «is» внутри текста:
Из экземпляра Pattern получается экземпляр Matcher. С помощью него пример находит все вхождения регулярного выражения в тексте.
Синтаксис
Сопоставление символов
Первое, на что нужно обратить внимание – как написать регулярное выражение, которое сопоставляет символы с заданным текстом. Например, выражение, определенное здесь:
будет соответствовать всем строкам, которые точно соответствуют ему. Не может быть символов до или после http: // – или выражение не будет соответствовать тексту. Например, приведенный выше синтаксис будет соответствовать этому тексту:
Вторая строка содержит символы как до, так и после http: //, с которым сопоставляется.
Метасимволы
Метасимволы – это символы в выражении, которые интерпретируются как имеющие специальные значения. Эти метасимволы:
Если вы включите, например, “.” (Fullstop) в выражение, оно не будет соответствовать символу fullstop, но будет соответствовать чему-то еще, что определено этим метасимволом.
Экранирование метасимволов
Если вы действительно хотите сопоставить эти символы в их буквальной форме, а не в значении метасимвола, вы должны «экранировать» метасимвол, которому хотите соответствовать. Для этого вы используете escape-символ – символ обратной косой черты. Выход из символа означает предшествующий ему символ обратной косой черты. Например, вот так:
В этом примере. символу предшествует (экранированный) символ \. После экранирования символ полной остановки будет фактически соответствовать символу полной остановки во входном тексте. Особое значение метасимвола для экранированного метасимвола игнорируется – используется только его фактическое буквальное значение (например, точка полного останова).
Синтаксис использует символ обратной косой черты в качестве escape-символа, как это делают строки. Это немного затрудняет написание выражения в строке. Посмотрите на этот пример:
Причина в том, что сначала компилятор интерпретирует два \\ символа как экранированный символ Java String. После завершения компиляции остается только один \, поскольку \\ означает символ \. Таким образом, строка выглядит так:
Теперь включается интерпретатор выражений и интерпретирует оставшуюся обратную косую черту как escape-символ. Следующий персонаж. теперь интерпретируется как фактическая полная остановка, а не специальное регулярное выражение, означающее, что оно имеет иное значение. Таким образом, оставшееся выражение соответствует символу полной остановки и ничего более.
Несколько символов имеют особое значение в синтаксисе. Если вы хотите сопоставить этот явный символ и не использовать его с его специальным значением, вам нужно сначала экранировать его с помощью символа обратной косой черты. Например, чтобы соответствовать символу полной остановки, вам нужно написать:
Чтобы соответствовать самому символу обратной косой черты, вам нужно написать:
Получить экранирование символов в выражениях может быть сложно.
Соответствие любому символу
Вы можете просто сопоставить любой символ, независимо от того, какой он. Синтаксис позволяет делать это, используя. символ (точка / полная остановка). Вот пример:
Это выражение соответствует одному символу, независимо от того, какой это символ.
. символ может быть объединен с другими для создания более сложных выражений:
Это регулярное выражение будет соответствовать любой строке Java, которая содержит символы «H», за которыми следует любой символ, за которым следуют символы «llo». Таким образом, это регулярное выражение будет соответствовать всем строкам “Hello”, “Hallo”, “Hullo”, “Hxllo” и т. Д.
Соответствие любому из набора символов
Поддерживается сопоставление любого из указанного набора символов, используя так называемые классы символов. Вот пример класса символов:
Класс символов (набор символов для сопоставления) заключен в квадратные скобки – другими словами, часть выражения [ae]. Квадратные скобки не совпадают – только символы внутри них.
Класс символов будет соответствовать одному из вложенных символов независимо от того, какой, но не более одного. Таким образом, приведенное выше выражение будет соответствовать любой из двух строк «Hallo» или «Hello», но никаких других строк. Только «а» или «е» допускается между «Н» и «llo».
Вы можете сопоставить диапазон символов, указав первый и последний символ в диапазоне с тире между ними. Например, класс символов [az] будет соответствовать всем символам между строчными буквами a и строчными буквами z, включая a и z.
Вы можете иметь более одного диапазона символов в пределах класса символов. Например, класс символов [a-zA-Z] будет соответствовать всем буквам между a и z или между A и Z.
Вы также можете использовать диапазоны для цифр. Например, класс символов 2 будет соответствовать символам от 0 до 9, включая оба.
Если вы действительно хотите сопоставить одну из квадратных скобок в тексте, вам нужно будет их избежать. Вот как выглядят экранирующие квадратные скобки:
\\ [является левой квадратной скобкой Это выражение будет соответствовать строке “H [llo”.
Если вы хотите сопоставить квадратные скобки внутри класса символов, вот как это выглядит:
Класс символов – это часть: [\\ [\\]]. Он содержит две квадратных скобки(\\ [и \\]). Будет соответствовать строкам “H [llo” и “H] llo”.
Соответствие диапазону символов
Можно указать диапазон символов для сопоставления. Задать диапазон символов проще, чем явно указать каждый символ для сопоставления. Например, вы можете сопоставить символы от a до z следующим образом:
Это выражение будет соответствовать любому отдельному символу от a до z в алфавите.
Классы символов чувствительны к регистру. Чтобы сопоставить все символы от a до z независимо от регистра, вы должны включить как прописные, так и строчные диапазоны:
Соответствующие цифры
Вы можете сопоставить цифры номера с предопределенным классом символов с помощью кода \ d. Класс символов цифр соответствует классу символов 3.
Поскольку символ \ также является escape-символом, вам нужно две обратные косые черты в строке, чтобы получить \ d в выражении:
Это регулярное выражение будет соответствовать строкам, начинающимся с «Hi», за которым следует цифра (от 0 до 9). Таким образом, он будет соответствовать строке «Hi5», но не строке «Hip».
Соответствие не цифр
Совпадение не цифр может быть сделано с помощью предопределенного класса символов [\ D] (заглавная D):
Будет соответствовать любой строке, которая начинается с «Hi», за которым следует один символ, который не является цифрой.
Соответствующие слова
Вы можете сопоставить символы слова с предопределенным классом символов с кодом \ w. Слово символьный класс соответствует классу символов [a-zA-Z_0-9].
Будет соответствовать любой строке, которая начинается с «Hi», за которым следует символ одного слова.
Соответствующие несловесные символы
Вы можете сопоставить несловесные символы с предопределенным классом символов [\ W] (заглавными буквами W). Поскольку символ \ также является escape-символом, вам нужно две обратные косые черты в строке, чтобы получить \ w:
Границы
Java Regex API также может соответствовать границам в строке, а именно началом или концом строки, началом слова и т. д. API Java Regex поддерживает следующие границы:
| Символ | Описание |
|---|---|
| ^ | Начало строки |
| $ | Конец строки |
| \b | Граница слова (где слово начинается или заканчивается, например, пробел, табуляция и т. д.). |
| \B | Несловесная граница |
| \A | Начало ввода. |
| \G | Конец предыдущего совпадения |
| \Z | Конец ввода, кроме конечного объекта (если есть) |
| \z |
Начало строки
Соответствие границ ^ соответствует началу строки в соответствии со спецификацией API Java. Например, следующий пример получает только одно совпадение с индексом 0:
Даже если входная строка содержит несколько разрывов строк, символ ^ соответствует только началу входной строки, а не началу каждой строки (после каждого переноса строки).
Начало соответствия строки / строки часто используется в сочетании с другими символами, чтобы проверить, начинается ли строка с определенной подстроки. Например, этот пример проверяет, начинается ли строка ввода с подстроки http: //:
В этом примере найдено одно совпадение подстроки http: // из индекса 0 в индекс 7 во входном потоке. Даже если бы входная строка содержала больше экземпляров подстроки http: //, они не соответствовали бы этому регулярному выражению, так как оно начиналось с символа ^.
Конец строки
Соответствие начала строки часто используется в сочетании с другими символами, чаще всего для проверки, заканчивается ли строка определенной подстрокой:
В этом примере будет найдено одно совпадение в конце входной строки.
Границы слова
Сопоставитель границ \ b соответствует границе слова, что означает местоположение во входной строке, где слово либо начинается, либо заканчивается:
Этот пример соответствует всем границам слов, найденным во входной строке.
Обратите внимание, как сопоставитель границ слова записывается как \\ b – с двумя символами \\ (обратная косая черта). Причина этого объясняется в разделе об экранировании символов.
В выводе перечислены все места, где слово либо начинается, либо заканчивается во входной строке. Как видите, индексы начала слова указывают на первый символ слова, тогда как окончания слова указывают на первый символ после слова.
В этом примере будут найдены все места, где слово начинается с буквы l (строчные буквы). Фактически он также найдет концы этих совпадений, что означает последний символ шаблона, который является строчной буквой l.
Несловесные границы
Обратите внимание, что эти индексы соответствия соответствуют границам между символами в одном и том же слове.
Квантификаторы
Квантификаторы можно использовать для сопоставления символов более одного раза. Существует несколько типов, которые перечислены в синтаксисе Java Regex. Наиболее часто используемые:
Это регулярное выражение сопоставляет строки с текстом «Hell», за которым следует ноль или более символов. Таким образом, регулярное выражение будет соответствовать «Hell», «Hello», «Helloo» и т. д.
Если бы квантификатором был символ + вместо символа *, строка должна была бы заканчиваться 1 или более символами o.
Будет соответствовать строке «Hell+»;
Будет соответствовать строке «Helloo»(с двумя символами o в конце).
Будет соответствовать строкам “Helloo”, “Hellooo” и “Helloooo”. Другими словами, строка «Hell» с 2, 3 или 4 символами в конце.
Логические Операторы
Java Regex API поддерживает набор логических операторов, которые можно использовать для объединения нескольких подшаблонов в одном регулярном выражении, а именно оператор and и оператор or.
Обратите внимание на 3 подшаблона [Cc], [Ii] и. *
Поскольку в регулярном выражении между этими подшаблонами нет символов, между ними неявно существует оператор and. Это означает, что целевая строка должна соответствовать всем 3 подшаблонам в данном порядке, чтобы соответствовать регулярному выражению в целом. Как видно из строки, выражение соответствует строке. Строка должна начинаться с заглавной или строчной буквы C, за которой следует заглавная или строчная буква I, а затем ноль или более символов. Строка соответствует этим критериям.
Как вы можете видеть, шаблон будет соответствовать либо подчиненному шаблону Ariel, либо подчиненному шаблону Sleeping Beauty где-то в целевой строке. Поскольку целевая строка содержит текст «Sleeping Beauty», выражение соответствует целевой строке.
Методы выражений Java String
Класс Java String также имеет несколько методов регулярных выражений.
matches()
Метод принимает регулярное выражение в качестве параметра и возвращает true, если соответствует строке, и false, если нет.
split()
Метод разбивает строку на N подстрок и возвращает массив String с этими подстроками. Принимает регулярное выражение в качестве параметра и разбивает строку на все позиции в строке, где выражение соответствует части строки. Выражение не возвращается как часть возвращаемых подстрок.
Этот пример вернет три строки: «один», «три» и «один».
replaceFirst()
Метод возвращает новую строку с первым совпадением регулярного выражения, переданного в качестве первого параметра, со строковым значением второго параметра.
Этот пример вернет строку «один пять три два один».
replaceAll()
Метод возвращает новую строку со всеми совпадениями регулярного выражения, переданного в качестве первого параметра, со строковым значением второго параметра.



