Регулярные выражения: начало работы с RegExp
Авторизуйтесь
Регулярные выражения: начало работы с RegExp
Что такое регулярные выражения?
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
13–15 декабря, Онлайн, Беcплатно
Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто Хаха нам не подойдёт — ведь под него не попадут «Хехе», «Хохо» и «Хихи». Да и проблему с регистром первой буквы нужно как-то решить.
Здесь нам на помощь придут наборы — вместо указания конкретного символа, мы можем записать целый список, и если в исследуемой строке на указанном месте будет стоять любой из перечисленных символов, строка будет считаться подходящей. Наборы записываются в квадратных скобках — паттерну [abcd] будет соответствовать любой из символов «a», «b», «c» или «d».
Внутри набора большая часть спецсимволов не нуждается в экранировании, однако использование \ перед ними не будет считаться ошибкой. По прежнему необходимо экранировать символы «\» и «^», и, желательно, «]» (так, [][] обозначает любой из символов «]» или «[», тогда как [[]х] – исключительно последовательность «[х]»). Необычное на первый взгляд поведение регулярок с символом «]» на самом деле определяется известными правилами, но гораздо легче просто экранировать этот символ, чем их запоминать. Кроме этого, экранировать нужно символ «-», он используется для задания диапазонов (см. ниже).
Предопределённые классы символов

Комикс про регулярные выражения с xkcd.ru
Диапазоны
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
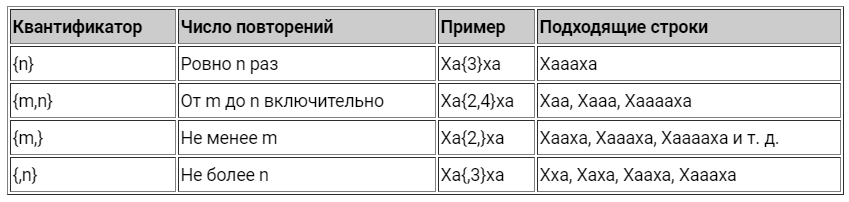
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:

Спецобозначения квантификаторов в регулярных выражениях.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
Очевидное решение здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строка
Ревнивая квантификация
Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Таким образом, наше выражение превращается в [Хх]([аиое]х?)+ — сначала идёт заглавная или строчная «х», а потом произвольное ненулевое количество гласных, которые (возможно, но не обязательно) перемежаются одиночными строчными «х». Однако это выражение решает проблему лишь частично — под это выражение попадут и такие строки, как, например, «хихахех» — кто-то может быть так и смеётся, но допущение весьма сомнительное. Очевидно, мы можем использовать набор из всех гласных лишь единожды, а потом должны как-то опираться на результат первого поиска. Но как?…
Запоминание результата поиска по группе
Результат поиска по всему регексу: «
».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».

Перечисление
С помощью этого оператора мы сможем добавить к нашему регулярному выражению для поиска междометий возможность распознавать смех вида «Ахахаах» — единственной усмешке, которая начинается с гласной: [Хх]([аоие])х?(?:\1х?)*|[Аа]х?(?:ах?)+
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: «Завтрак в 09:00». Учтите, что «37:98» – некорректное время.
Регулярные выражения
Создание регулярного выражения
Регулярное выражение можно создать двумя способами:
Литералы регулярных выражений вызывают предварительную компиляцию регулярного выражения при анализе скрипта. Если ваше регулярное выражение постоянно, то пользуйтесь им, чтобы увеличить производительность.
Использование конструктора влечёт за собой компиляцию регулярного выражения во время исполнения скрипта. Используйте данный способ, если знаете, что выражение будет изменяться или не знаете шаблон заранее. Например вы получаете его из стороннего источника, при пользовательском вводе.
Написание шаблона регулярного выражения
Использование простых шаблонов
Простые шаблоны используются для нахождения прямого соответствия в тексте. Например, шаблон /abc/ соответствует комбинации символов в строке только когда символы ‘abc’ встречаются вместе и в том же порядке. Такое сопоставление произойдёт в строке «Hi, do you know your abc’s?» и «The latest airplane designs evolved from slabcraft.» В обоих случаях сопоставление произойдёт с подстрокой ‘abc’. Сопоставление не произойдёт в строке «Grab crab», потому что она не содержит подстроку ‘abc’.
Использование специальных символов
В случае когда поиск соответствия требует чего-то большего, чем прямое сопоставление, например нахождение последовательности символов ‘b’ или нахождение пробела, шаблон включает в себя специальные символы. Например, шаблон /ab*c/ соответствует любой комбинации символов, в которой за ‘a’ следует ноль или более символов ‘b’ ( * означает ноль или более вхождений предыдущего символа), за которыми сразу же следует символ ‘c’. В строке «cbbabbbbcdebc,» этому шаблону сопоставляется подстрока ‘abbbbc’.
В следующей таблице приводится полный список специальных символов регулярных выражений с их описаниями.
Соответствует началу ввода. Если установлен флаг многострочности, также производит сопоставление непосредственно после переноса строки.
Например, /^A/ не соответствует ‘A’ в «an A», но соответствует ‘A’ в «An E».
Этот символ имеет другое значение при появлении в начале шаблона набора символов.
Например, /[^a-z\s]/ соответствует ‘I’ в «I have 3 sisters».
Соответствует концу ввода. Если установлен битовый флаг многострочности, также сопоставляется содержимому до переноса строки.
Например, /t$/ не соответствует ‘t’ в строке «eater», но соответствует строке «eat».
Соответствует предыдущему символу повторенному 0 или более раз. Эквивалентно <0,>.
Например, /bo*/ соответствует ‘boooo’ в «A ghost booooed» и ‘b’ в «A bird warbled», но не в «A goat grunted».
Соответствует предыдущему символу повторенному 1 или более раз. Эквивалентно <1,>.
Например, /a+/ соответствует ‘a’ в «candy» и всем символам ‘a’ в «caaaaaaandy».
0 или 1 раз. Эквивалентно <0,1>.
Например, /e?le?/ соответствует ‘el’ в «angel» и ‘le’ в «angle» а также ‘l’ в «oslo».
Также используется в упреждающих утверждениях (assertions), описанных в строках x(?=y) и x(?!y) данной таблицы.
(десятичная точка) соответствует любому символу кроме переноса строки.
Например, /.n/ соответствует ‘an’ и ‘on’ в «nay, an apple is on the tree», но не ‘nay’.
Соответствует ‘x’ и запоминает это соответствие. Это называется захватывающие скобки.
Соответствует ‘x’ только если за ‘x’ следует ‘y’. Это называется упреждение.
Например, /Jack(?=Sprat)/ соответствует ‘Jack’ только если за ним следует ‘Sprat’. /Jack(?=Sprat|Frost)/ соответствует ‘Jack’ только если за ним следует ‘Sprat’ или ‘Frost’. Тем не менее, ни ‘Sprat’ ни ‘Frost’ не являются частью сопоставленного результата.
Соответствует ‘x’ только если за ‘x’ не следует ‘y’. Это называется отрицательное упреждение.
Например, /\d+(?!\.)/ соответствует числу только если за ним не следует десятичная точка. Регулярное выражение /\d+(?!\.)/.exec(«3.141») сопоставит ‘141’ но не ‘3.141’.
Соответствует либо ‘x’ либо ‘y’.
Например, /green|red/ соответствует ‘green’ в «green apple» и ‘red’ в «red apple.»
Например, /a<2>/ не соответствует ‘a’ в «candy,» но соответствует всем а в «caandy,» первым двум а в «caaandy.»
Например, /a<1,3>/ ничему не соответствует в строке «cndy», символу ‘a’ в «candy,» двум а в «caandy,» и трём первым а в «caaaaaaandy». Отметим, что при сопоставлении «caaaaaaandy», совпадает «aaa», хотя изначальная строка содержит больше а.
Инвертированный или дополняющий набор символов. Это означает соответствие всему, что не в скобках. Можно указать диапазон символов с помощью тире. Все, что действует в обычном наборе символов, действует и здесь.
Note: JavaScript’s regular expression engine defines a specific set of charactersto be «word» characters. Any character not in that set is considered a word break. This set of characters is fairly limited: it consists solely of the Roman alphabet in both upper- and lower-case, decimal digits, and the underscore character. Accented characters, such as «é» or «ü» are, unfortunately, treated as word breaks.
Соответствует несловообразующей границе. Несловообразующая граница соответствует позиции, в которой предыдущий и следующий символы являются символами одного типа: либо оба должны быть словообразующими символами, либо несловообразующими. Начало и конец строки считаются несловообразующими символами.
Например, /\B../ соответствует ‘oo’ в слове «noonday» (, а /y\B./ соответствует ‘ye’ в «possibly yesterday.»
Где X является символом случайного выбора из последовательности от А до Я. Соответствует управляющему символу в строке.
Например, /\cM/ соответствует control-M (U+000D) в строке.
Например, /\d/ or /7/ соответствует ‘2’ в «B2 is the suite number.»
Например, /\D/ or /[^0-9]/ соответствует ‘B’ в предложении «B2 is the suite number.»
Соответствует символу прогона страницы (U+000C). Особый символ управления печатью.
Например, /\s\w*/ совпадает с ‘ bar’ в «foo bar.»
Например, /\S\w*/ совпадает с ‘foo’ в «foo bar.»
Например, /\w/ совпадает с ‘a’ в «apple,» ‘5’ в «$5.28,» и ‘3’ в «3D.»
Например, /\W/ or /[^A-Za-z0-9_]/ совпадает с ‘%’ в «50%.»
Например, /apple(,)\sorange\1/ соответствует ‘apple, orange,’ в «apple, orange, cherry, peach.»
Экранирование пользовательского ввода, соответствующего буквенной строке внутри регулярного выражения, может быть достигнуто простой заменой:
Использование скобок
Скобки вокруг любой части регулярного выражения означают что эта часть совпадаемой подстроки будет запомнена. Раз запомнена, подстрока может выбрана для использования как это описано в Using Parenthesized Substring Matches.
Например, паттерн /Chapter (\d+)\.\d*/ включает в себя дополнительные экранирующие и специальные символы и указывает на то, что часть шаблона должна быть запомнена. Он точно соответствует символам слова ‘Chapter ‘, за которыми следует один или более цифровых символов ( \d означает любой цифровой символ, а ‘ +’ означает 1 или более раз), за которым следует десятичная точка (сама по себе являющаяся специальным символом; предшествующий десятичной точке слеш ‘ \’ означает, что паттерн должен искать литеральный символ ‘.’), после которой следует любой цифровой символ 0 или более раз (‘ \d’ обозначает цифровой символ, ‘ *’ обозначает 0 или более раз). Кроме того, круглые скобки используются для запоминания первых же совпавших цифровых символов.
Этот шаблон будет найден во фразе «Open Chapter 4.3, paragraph 6» и цифра ‘4’ будет запомнена. Но он не будет найден во фразе «Chapter 3 and 4», поскольку эта строка не имеет точки после цифры ‘3’.
Работа с Регулярными Выражениями
Чтобы просто узнать есть ли в строке что либо соответствующее шаблону, воспользуйтесь методами test или search ; а чтобы получить больше информации пользуйтесь методами exec или match (хотя эти метода работают медленнее). Если вы пользуетесь exec или match и если совпадения есть, эти методы вернут массив и обновлённые свойства объекта ассоциированного регулярного выражения а также предопределённого объекта RegExp регулярного выражения. Если совпадений нет, метод exec вернёт null (который сконвертируется в false ).
В след. примере, скрипт использует метод exec чтобы найти совпадения в строке.
Если вам не нужен доступ к свойствам регулярного выражения, то альтернативный способ получить myArray можно так:
Если вы хотите сконструировать регулярное выражение из строки, другой способ сделать это приведён ниже:
С помощью этих скриптов, поиск совпадения завершается и возвращает массив и обновлённые свойства показанные в след. таблице.
| Объект | Свойство или индекс | Описание | В этом примере. |
|---|---|---|---|
| myArray | Совпавшая строка и все запомненные подстроки. | [«dbbd», «bb»] | |
| index | Индекс совпавшей подстроки (индекс начинается с нуля). | 1 | |
| input | Исходная строка. | «cdbbdbsbz» | |
| [0] | Последние совпавшие символы. | «dbbd» | |
| myRe | lastIndex | Индекс с которого начнётся след. поиск совпадения. (Это свойство определяется только если регулярное выражение использует параметр g, описанный в Advanced Searching With Flags.) | 5 |
| source | Текст шаблона. Обновляется в момент создания регулярного выражения, а не во время выполнения. | «d(b+)d» |
Как показано во втором варианте этого примера, вы можете использовать регулярное выражение, созданное при помощи инициализатора объекта, без присваивания его переменной. Таким образом, если вы используете данную форму записи без присваивания переменной, то в процессе дальнейшего использования вы не можете получить доступ к свойствам данного регулярного выражения. Например, у вас есть следующий скрипт:
Этот скрипт выведет:
Однако, если у вас есть следующий скрипт:
Использование скобочных выражений для нахождения подстрок
Число возможных скобочных подстрок неограничено. Возвращаемый массив содержит все полученные совпадения, удовлетворяющие выражению в скобках. Следующий пример показывает как использовать скобочные выражения для нахождения подстрок.
Выведет «Smith, John».
Расширенный поиск с флагами
Регулярные выражения имеют четыре опциональных флага, которые делают возможным глобальный и регистронезависимый поиск. Флаги могут использоваться самостоятельно или вместе в любом порядке, а также могут являться частью регулярного выражения.
| Flag | Description |
|---|---|
| g | Глобальный поиск. |
| i | Регистронезависимый поиск. |
| m | Многострочный поиск. |
| y | Выполняет поиск начиная с символа, который находится на позиции свойства lastindex текущего регулярного выражения. |
Чтобы использовать флаги в шаблоне регулярного выражения используйте следующий синтаксис:
Обратите внимание, что флаги являются неотъемлемой частью регулярного выражения. Флаги не могут быть добавлены или удалены позднее.
Для примера, re = /\w+\s/g создаёт регулярное выражение, которое ищет один или более символов, после которых следует пробел и ищет данное совпадение на протяжении всей строки.
Выведет [«fee «, «fi «, «fo «]. В этом примере вы бы могли заменить строку:
и получить тот же результат.
Примеры
След. примеры показывают использование регулярных выражений.
Изменение порядка в Исходной Строке
Использование спецсимволов для проверки входных данных
В след. примере, ожидается что пользователь введёт телефонный номер и требуется проверить правильность символов набранных пользователем. Когда пользователь нажмёт кнопку «Check», скрипт проверит правильность введённого номера. Если номер правильный (совпадает с символами определёнными в регулярном выражении), то скрипт покажет сообщение благодарности для пользователя и подтвердит номер. Если нет, то скрипт проинформирует пользователя, что телефонный номер неправильный.
Событие «Изменить» активируется, когда пользователь подтвердит ввод значения регулярного выражения, нажав клавишу «Enter».
Регулярные выражения. Всё проще, чем кажется
Всем доброго времени суток. Сегодня хочу рассказать максимум о регулярных выражениях: что они из себя представляют, как их писать, для чего нужны и т.д.
Информации о регулярках много, они разбросаны по разным сайтам и я решил собрать всё, касательно регулярок, в одну статью. Ну что-ж, приступим поскорее к делу 🙂
Содержание
Что такое регулярка и с чем ее едят?
Где писать регулярки?
Самые простые регулярки
Специальные символы квантификаторов
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Регулярные выражения в разных языках программирования
Что такое регулярка и с чем ее едят?
Если по простому, регулярка- это некий шаблон, по которому фильтруется текст. Мы можем написать нужный нам шаблон (регулярку) и таким образом искать в тексте необходимые нам символы, слова и т.д. Также их используют, например, при заполнении поля E-mail на различных сайтах, т.е. создают шаблон по типу: someEmail@gmail.com. Это я взял как пример, не более. Теперь, разобравшись, что это, приступим к изучению. Обещаю, скучно не будет)
Где писать регулярки?
Регулярки мы можем писать как на специальных сайтах, так и используя какой-либо язык программирования. Синтаксис (правила написания регулярок) не привязан к какому-то отдельному языку программирования. Поэтому, изучив регулярные выражения, вы сможете пользоваться ими где захотите. Сначала, в рамках изучения, воспользуемся отличным сайтом, а как писать регулярные выражения в различных языках программирования, рассмотрим чуточку позже.
Сразу дам ссылку на сайт, чтобы вы могли уже писать вместе со мной https://www.regextester.com/
Коротко о том, как пользоваться сайтом. Сверху, в графе Regular Expression вы пишете само регулярное выражение, а под ним, в графе Test String вы пишете строку, которую вы хотите фильтровать. Если были найдены соответствия между регулярным выражением и текстом, в тексте эти соответствия будут помечены синим цветом, вы их сразу увидите, даже не сомневайтесь.
Самые простые регулярки
Перед тем, как писать регулярку, возьмем некоторый текст, чтобы мы не фильтровали пустоту. Допустим, у нас будет строка some text. И допустим мы хотим найти слово text. Для этого в саму регулярку мы должны написать просто слово text и он найдет его.
 Пример регулярки
Пример регулярки
Вот и всё, надеюсь вы поняли регулярные выражения, спасибо за внимание.
Шутка конечно, это далеко не всё. Например, мы можем написать одну букву t, и он найдет все буквы t в тексте.
Таким образом вы можете просто указывать какие-то символы, но нам не всегда даются конкретные символы, а нужно написать какой-то шаблон. Сейчас этим и займемся.
Квантификаторы
Понимаю, звучит страшно, но на деле все просто. Сейчас разберемся.
С помощью квантификаторов мы можем указывать сколько раз должен повторяться тот или иной символ (ну или группа символов). Ниже приведу список квантификаторов с пояснением, а дальше попрактикуемся с ними.
— символ повторяется ровно n раз
— символ повторяется в диапазоне от m до n раз
— символ повторяется минимум m раз (от m и более)
Почему же он взял еще ssss? Он взял не совсем его, а лишь его часть, так как в нем тоже есть 3 буквы s подряд. Дело в том, что регулярка не будет учитывать, отдельное это слово или нет. Пробелы тоже идут как символы! Поэтому будет выбран любой фрагмент, которому соответствует 3 идущие подряд буквы s
Интересный момент получается, он выбрал все. Почему же? Ответ: та же ситуация, что и в прошлый раз. Он увидел ssss, взял 3 идущие подряд s вместе и еще одну s, которая рядом, ведь она тоже соответствует регулярку (а ведь мы помним, что мы указали диапазон от одного до трех раз)
Ну и напоследок, давайте напишем шаблон, где символ s будет повторяться минимум три раза. Для этого напишем следующее: s ( <3,>обозначает, что символ s будет повторяться от трех раз и до бесконечности).
Специальные символы квантификаторов
Есть уже готовые квантификаторы, которые обозначаются спец. символами. Вот они:
Давайте разбираться. Начнем со знака вопроса. Допустим у нас есть строка colour color и мы хотим найти либо colour, либо color. Мы можем написать так: colou?r.
Давайте изменим строку и напишем что-то по типу colouuuuur color. И допустим мы хотим указать, что u должен либо не быть, либо быть сколько угодно раз. Для этого мы можем написать colou*r.
То есть либо u у нас нет, либо повторяется много раз.
Символ + работает почти также, за исключением того, что символ должен повторяться минимум 1 раз. То есть в данном случае слово color не будет соответствовать, так как там u не присутствует (то есть повторяется 0 раз, а у нас символ должен повторяться минимум 1 раз)
Специальные символы
Теперь поговорим о специальных символах, которые используются в регулярках. Тут все очень просто, так что можете сильно не переживать. Скрины прикреплять буду здесь не везде (тогда статья разрастется до безумных размеров). Так что заранее прошу меня понять и простить и попробовать сами.
Поговорим об одиночном символе. Это значит, что будет выбираться любой символ, который повторяется только один раз. Например, вернемся к нашей строке Some text и выберем букву t, после которой идет любой символ. Для этого напишем t.
Выберется te, так как после t идет один любой символ (в данном случае е)
Теперь давайте возьмем слово test и выделим в нем первую букву t. Для этого мы можем написать ^t. То есть мы написали символ t и указали, что он должен находиться в самом начале строки. Важно поставить символ ^ перед нужным нам символом.
Теперь давайте сделаем наоборот и возьмем последнюю букву t. Для этого напишем t$. Важно, чтобы символ $ стоял после нужного нам символа.
Перейдем к экранированию. Звучит страшно, но на деле все проще простого. Например, в тексте some text. мы хотим выделить точку. Но ведь точка у нас уже зарезервирована как специальный символ (напоминаю, точка обозначает любой одиночный символ). И чтобы сделать так, чтобы точка на считалась как спец. символ мы можем написать \. и тем самым говоря, что точка у нас будет как обычный символ.
Теперь идут, простые вещи. \d у нас обозначает любую цифру. Например в тексте some text123, если написать \d у нас будут выделяться только цифры.
\D делает все наоборот: берутся все символы, кроме цифр. То есть, если написать \D будет браться все, кроме цифр (и пробелы, кстати, тоже).
\w берет буквы, а \W берет, все, кроме букв (в том числе и пробелы).
Теперь расскажу про еще одно применение символа ^. Его можно использовать как отрицание, тем самым исключая символ или группу символов. Например, в слове test мы хотим выбрать все, кроме буквы t и для этого мы можем написать так: [^t]
Именно в такой последовательности символ ^ будет обозначать отрицание.
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Давайте разберемся, что это такое. Lookahead или же опережающая проверка позволяет выбрать символ или группу символов, если после него идет идет какой-либо символ или группа символов. Lookbehind или же ретроспективная проверка позволяет выбрать символ или группу символов, если до них идет какой-то символ или группа символов.
Также мы можем сделать наоборот и выбрать символ s, если после него НЕ идет символ d. Для этого вместо знака равно мы должны поставить восклицательный знак (!), т.е. написать вот так: s(?!d)
Теперь поговорим о lookbehind. Допустим, у нас есть строка s ws ds ts es и мы хотим выбрать символ s, до которого будет символ d. Для этого мы можем написать так: (?
Почему же lookbehind подчеркивается красной линией? Дело в том, что lookbehind не всегда поддерживается и не везде такая регулярка будет работать. Нужно искать способ заменить этот lookbehind, но это зависит от поставленной задачи, поэтому нельзя сказать, как именно ее заменять. Будем надеяться, что в скором временем будет полная поддержка этой возможности.
Чтобы сделать наоборот, то есть выбрать все символы s, до которых НЕ будет идти символ d, нужно опять же поменять знак равно на восклицательный знак: (?
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования. Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку. В результате все сопоставления будут добавляться в коллекцию matches.
Java
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Заключение
Итак, мы разобрали, что такое регулярные выражения, где они используются, как их писать и использовать в контексте языков программирования. Скажу сразу, написание регулярок приходит с опытом. Практикуйтесь, и я уверен: все у вас получится! А на этом я с вами прощаюсь. Спасибо за внимание и приятного всем дня)



