Что такое семантическая модель
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе кратко рассмотренного нами механизма нормализации часто представляет собой очень сложный и неудобный для проектировщика процесс.
6.2.1. Семантические модели данных
Потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области вызвали к жизни направление семантических моделей данных. При том, что любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части, главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Прежде, чем мы коротко рассмотрим особенности одной из распространенных семантических моделей, остановимся на их возможных применениях.
Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования.
Менее часто реализуется автоматизированная компиляция концептуальной схемы в реляционную. При этом известны два подхода: на основе явного представления концептуальной схемы как исходной информации для компилятора и построения интегрированных систем проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области. И в том, и в другом случае в результате производится реляционная схема базы данных в третьей нормальной форме (более точно следовало бы сказать, что автору неизвестны системы, обеспечивающие более высокий уровень нормализации).
6.2.2. Основные понятия модели Entity-Relationship (Сущность-Связи)
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделей одна из наиболее развитых применяется в системе CASE фирмы ORACLE. Ее мы и рассмотрим. Более точно, мы сосредоточимся на структурной части этой модели.
Основными понятиями ER-модели являются сущность, связь и атрибут.
Ниже изображена сущность АЭРОПОРТ с примерными объектами Шереметьево и Хитроу:
Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
В изображенном ниже примере связь между сущностями БИЛЕТ и ПАССАЖИР связывает билеты и пассажиров. При том конец сущности с именем «для» позволяет связывать с одним пассажиром более одного билета, причем каждый билет должен быть связан с каким-либо пассажиром. Конец сущности с именем «имеет» означает, что каждый билет может принадлежать только одному пассажиру, причем пассажир не обязан иметь хотя бы один билет.
На следующем примере изображена рекурсивная связь, связывающая сущность ЧЕЛОВЕК с ней же самой. Конец связи с именем «сын» определяет тот факт, что у одного отца может быть более чем один сын. Конец связи с именем «отец» означает, что не у каждого человека могут быть сыновья.
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности. Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно, с примерами.
Уникальным идентификатором сущности является атрибут, комбинация атрибутов, комбинация связей или комбинация связей и атрибутов, уникально отличающая любой экземпляр сущности от других экземпляров сущности того же типа.
6.2.3. Нормальные формы ER-схем
Как и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу реляционных нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Мы приведем только очень краткие и неформальные определения трех первых нормальных форм.
В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, «замаскиро-ванных» под атрибуты.
Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность.
В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
6.2.4. Более сложные элементы ER-модели
Эти и другие более сложные элементы модели данных «Сущность-Связи» делают ее существенно более мощной, но одновременно несколько усложняют ее использование. Конечно, при реальном использовании ER-диаграмм для проектирования баз данных необходимо ознакомиться со всеми возможностями.
Сущность может быть расщеплена на два или более взаимно исключающих подтипа, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе подтипизация может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т.е. любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ.
Пример: Супертип ЛЕТАТЕЛЬНЫЙ АППАРАТ
Как полагается это читать? От супертипа: ЛЕТАТЕЛЬНЫЙ АППАРАТ, который должен быть АЭРОПЛАНОМ, ВЕРТОЛЕТОМ, ПТИЦЕЛЕТОМ или ДРУГИМ ЛЕТАТЕЛЬНЫМ АППАРАТОМ. От подтипа: ВЕРТОЛЕТ, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА. От подтипа, который является одновременно супертипа: АЭРОПЛАН, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА и должен быть ПЛАНЕРОМ или МОТОРНЫМ САМОЛЕТОМ.
6.2.5. Получение реляционной схемы из ER-схемы
Шаг 3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификатора, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
Шаг 5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
При применении способа (а) таблица создается для наиболее внешнего супертипа, а для подтипов могут создаваться представления. В таблицу добавляется по крайней мере один столбец, содержащий код ТИПА; он становится частью первичного ключа.
Если остающиеся внешние ключи все в одном домене, т.е. имеют общий формат (способ (а)), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Альтернативные модели сущностей:
Вариант 2 (существенно лучше, если подтипы действительно существуют)
Вариант 3 (годится при наличии осмысленного супертипа D).
Введение в семантическое моделирование
Linguistic vs. Semantic
Семантические и лингвистические модели определяют формальный способ кодирования понятий естественного языка. Упрощенно говоря, основное различие в подходах заключается в типе кодируемой информации. Лингвистическая модель оперирует лингвистическими категориями, такими как существительные, глаголы и так далее, а семантическая — смысловыми, такие как ПЕРСОНА или КОМПАНИЯ.
И лингвистический и семантический подходы к анализу текстов появились примерно в одно и тоже время, в семидесятых годах. Лингвистическое моделирование постоянно развивается и на протяжении многих лет является основополагающей базой для общего развития NLP.Семантическое моделирование, в свою очередь, вызвало первоначальный всплеск интереса, но быстро отступило на задний план из-за технических сложностей реализации. Тем не менее, в последние годы интерес к семантическому моделированию возрождается. На сегодняшний день данный подход является основой почти всех коммерческих NLP ассистентов, таких как Google assistant, Cortana, Siri, Alexa и так далее. Данный подход является базовым и для компании DataLingvo (компания, развивающая идею семантического моделирования, в которой работает автор статьи).Самый простой способ понять разницу между семантической и лингвистической грамматикой — рассмотреть следующую иллюстрацию:
Один и тот же текст здесь разбирается согласно разным критериям.
Нижняя часть анализируется с использованием традиционной лингвистической грамматики, и как результат мы видим набор POSтегов (Point of of Speech): NN для существительных, JJ для прилагательного и так далее.
Верхняя часть — результат использования семантической модели, и вместо отдельных слов, с POS тегами, слова и словосочетания образуют более высокоуровневые семантические категории, такие как DATE или GEO.
Эта способность группировать отдельные слова в высокоуровневые семантические сущности была введена для разрешения важной проблемы, характерной для ранних NLP система — лингвистической неопределенности.
Примечание — на картинке представлена лишь часть информации, извлекаемой из текста посредством лингвистического анализа, фактически приведена лишь часть работы морфологического анализатора — разметка слов POS тегами. Для упрощения в стороне оставлены прочие данные морфологического разбора, данные лексического и синтаксического анализаторов, анализ именованных сущностей, дат и так далее.
Лингвистическая неопределенность
Посмотрите на картинку внизу
Пусть наша задача найти в тесте строку по существующему шаблону.
На картинке представлены два предложения со схожей структурой на выходе лингвистического анализатора.
POS теги у них практически совпадают, но предложения совершенно не похожи друг на друга. Поиск/сопоставление предложений с совпадающими или схожими тегами ничего нам не даст.
Прийти на помощь могут синтаксические деревья и сложный контекстный анализ. Но даже если такой контекст и будет всегда доступен на этапе разбора предложения, процесс сопоставления предложений на основании подобного анализа все равно не удается сделать детерминированным.
С другой стороны, семантическое моделирование позволяет разрешить подобные неоднозначности простым и гарантированно надежным способом. Используя правильно построенную семантическую грамматику, слова “friday” и “Alexy” будут отнесены к разным элементам модели, как следствие в данных предложениях не будет найдено ничего общего.
Мы снова значительно упростили пример и оставили за его рамками то, что кроме схожих POS тегов эти предложения будут иметь разные обнаруженные поименованные сущности, а также проигнорировали распознанную на этапе лингвистического разбора дату в первом предложении. В принципе, для данного примера, этого было бы достаточно, чтобы сразу развести данные предложения в две разные категории. В более сложных примерах, даже дополнительный учет поименованных сущностей, дат и так далее уже мог бы не быть столь эффективным.Пример использования семантической грамматики
Рассмотрим максимально простой вариант семантического моделирования.Независимо от типа конфигурации, грамматика модели определяется как совокупность семантических сущностей, где каждый объект имеет (как минимум) имя и список синонимов, с помощью которых этот объект может быть обнаружен в тексте.Пример. Простейшее определение объектов WEBSITE и USER с их синонимами:
будут поняты и представлены как те же две семантические сущности:
Далее, последовательность семантических сущностей может быть привязана к определяемому пользователем intents. Поиск таких intentsявляется конечной целью NLP ассистентов.
Реальные системы, конечно же, поддерживают гораздо более сложное определение грамматики. Существует множество различных способов определения синонимов, семантические сущности могут иметь типы данных, они могут быть организованы в иерархические группы для обработки их диалоговой памятью и так далее — все это выходит за рамки этой заметки. Здесь вы можете найти примеры поддержки такой грамматики.
Предопределенность против вероятности
Задача NLP ассистента — разобрать предложение и обнаружить в нем сущности, определяющие intent.
Мы уже упоминали то, что семантическому моделированию свойственен детерминированный характер поиска сущностей. Хотя конкретные реализации приложений, использующих лингвистическое и семантическое моделирование могут быть как детерминированными, так и вероятностными, использование семантического подхода почти всегда подразумевает детерминированную обработку.
Причина кроется в самой природе семантической грамматики, основанной на простом сопоставлении синонимов. Правильно определенная семантическая модель позволяет осуществлять полностью детерминированный поиск семантической сущности. Семантическая сущность либо обнаружена, либо нет, система не старается угадывать.
Как результат, семантическая грамматика гарантирует качество системы.
Вероятностный подход может прекрасно работать для многих задач, таких как категоризация документов, разметка текстов по настроению, поддержка некоторых чатботов и так далее — но все это просто невозможно использовать например, для основанных на NLP / NLU систем построения отчетов и выдачи данных бизнес аналитики.
На самом деле зачастую не имеет большого значения, верно ли вы определили настроение текста — с точностью 85% или 86%, главное в данном случае правильно определенный вектор. Но отчет о продажах, должен на все 100% соответствовать данным системы учета. Даже результат с высокой степенью вероятности, такой как «ваши продажи за последний квартал составляли XXX долларов с вероятностью 97%», почти всегда бесполезен.
При всех преимуществах семантического моделирования есть одно явное ограничение, которое мешало его развитию (по крайней мере так было изначально), а именно тот факт, что оно может быть применено только к совершенно узкой области данных.
Универсальность или Данные узкого профиля
В отличии от лингвистической грамматики, универсальной для всех областей данных (поскольку она имеет дело с универсальными лингвистическими конструкциями, такими как глаголы и существительные), семантическая грамматика, сопоставляющая данные на основе синонимов, ограничивается определенной, зачастую очень узкой, предметной областью. Причиной этого является то, что для создания семантической модели нужно определить исчерпывающий набор всех ее сущностей и, самое сложное, множество всех их синонимов.Для конкретной области данных это сложная, но решаемая задача, особенно когда на помощь приходят современные компьютерные системы. Но для общего случая, когда вам нужно понять любого собеседника, поднимающего любые темы, семантическое моделирование просто не работает.Имеется ряд довольно успешных попыток продвижения идеи семантического моделирования в совокупности с курированием процесса обработки текста (контролем и разрешением коллизий со стороны человека), а также процессом контролируемого самообучения системы. Но несмотря на это, на сегодняшний день, факт остается фактом — семантическое моделирование может быть успешно применено только при работе с определенной, четко очерченной, узкой и хорошо описанной областью данных.
Стоит отметить, что популярный подход Deep Learning (DL) на сегодняшний день тоже недостаточно эффективно используется в NLP / NLU для работы даже с узкопрофильными данными. Это связано с отсутствием больших тренинговых наборов, необходимых для обучения модели DL, их просто неоткуда пока взять. Поэтому и по сегодняшний день семантическое моделирование чаще используется с более традиционными системами, использующими контроль коллизий и контролируемые самообучающиеся алгоритмы.
Курирование и контролируемое самообучение
Человеческий контроль (курирование) и контролируемые алгоритмы самообучения — два взаимосвязанных метода, помогающих решить проблему недостаточного для полноценной работы набора семантических сущностей и всех необходимых синонимов, при использовании новой семантической модели на начальном этапе ее разработки.
Как это работает:Вы начинаете с создания семантической модели с базовым набором синонимов для тех семантических сущностей, которые можно относительно легко сконфигурировать и описать. После того, как приложение NLP / NLU, использующее эту модель, начинает работу, пользовательские запросы, которые не могут быть автоматически обработаны моделью, перейдут к Куратору. Во время процесса курирования пользовательский запрос будет скорректирован так, чтобы он мог быть обработан системой автоматически на базе существующей модели, а алгоритм самообучения учтет эту “поправку“ и автоматически использует ее при следующем таком же или подобном запросе уже без участия человека.
Особенно важно то, что система развивается и становится ”умнее” с каждой такой итерацией. Каждая процедура курирования (помощь при разборе неотвеченного автоматически запроса) и последующее самообучение делают модель все более полной. Таким образом разработчик модели может начать с малого, далее модель будет развиваться и настраиваться с помощью пошагового взаимодействия с человеком — процесс непохожий на большинство AI приложений.
Выводы
За последние 50 лет семантическое моделирование прошло через целую серию подъемов и спадов. Благодаря техническому прогрессу последних лет, а также новым методам самообучения и технологиям разрешения коллизий и курирования результатов, семантический подход стал на сегодняшний день основной технологией для большинства современных NLP / NLU систем. Когда вы в следующий раз спросите что-либо у Siri или Alexa — знайте, что где-то на серверах Apple или Amazon уже идет обращение к семантическим моделям, помогающим подобрать ответ.
ISO 15926 vs Семантика: сравнительный анализ семантических моделей
Идея применения семантических моделей в корпоративных информационных системах существует давно, но устойчивая практика такого их использования еще не сформировалась. Семантические модели можно применять для интеграции данных, аналитики, управления знаниями; однако, пока нет общепринятого мнения о том, как подходить к оценке их полезности, по каким методикам должны строиться такие модели.
Задача статьи — на практическом примере сравнить аналитический потенциал моделей, построенных по правилам интеграционного стандарта ISO 15926, который предписывает использование OWL и SPARQL для выражения моделей и работы с ними, и «обычных» семантических моделей, построенных без использования этого стандарта. Решение этого вопроса позволит выбрать диапазон задач, для решения которого целесообразно применять такие высокоуровневые парадигмы семантического моделирования, как ISO 15926.
Постановка проблемы
Необходимо кратко осветить историю вопроса, и суть взаимоотношений между ISO 15926 и «обычной» семантикой. ISO 15926 – стандарт обмена информацией, предназначенный для использования в промышленности (прежде всего, нефтегазовой). Исторически, акцент при разработке стандарта делался на обмен данными между различными организациями, т.е. между различными информационными инфраструктурами. Основные его особенности – специфический подход к классификации объектов и их отношений, учет временнóй составляющей объектов (4D моделирование), возможность моделирования жизненного цикла систем (а не просто текущего состояния той или иной системы). Стандарт содержит онтологическое ядро, и подразумевает использование общих библиотек справочных данных для создания прикладных информационных моделей. Все это обеспечивает как его преимущества (возможность создания высококачественных и релевантных моделей жизненного цикла систем, отличный потенциал использования для передачи информации между различными организациями при помощи общего «онтологического словаря»), так и недостатки (возрастающую сложность получающихся моделей, высокий «порог входа» по уровню знаний, необходимых для овладения стандартом и его использования).
Разработка стандарта была начата еще в 1990-е годы. С появлением в середине 2000-х технологий Semantic Web, они были утверждены в качестве технологической основы для выражения данных в соответствии с ISO 15926. Таким образом, основные концепции стандарта были заложены до возникновения Semantic Web, но только появление этих технологий предоставило необходимый технологический базис для создания способа выражения данных в соответствии со стандартом, обладающего потенциалом действительно широкого распространения. Некоторая идеологическая близость, но не идентичность этих технологий заложила основу того «противоречия», которое мы хотим разрешить. Поскольку принципы, по которым выполняется моделирование в соответствии с ISO 15926, не вполне соответствуют принципам представления объектов и отношений между ними, например, в языке OWL, объединение этих двух технологий получилось несколько синтетическим. Данные, построенные в соответствии с ISO 15926, могут быть разложены на элементарные элементы — триплеты RDF, но анализ отношений между информационными объектами представленной в таком виде модели средствами SPARQL будет затруднен.
Итак, суть противоречия, на которое мы собираемся пролить свет, состоит в следующем: утверждается, что семантические модели, построенные в соответствии с ISO 15926, обладают качественными отличиями от семантических моделей, построенных без подобного высокоуровневого руководства, только средствами «обычных» технологий Semantic Web. Таким образом, эти модели имеют принципиально разную природу (по крайней мере, идеологическую). Утверждается, что может иметь место конкуренция между этими двумя видами семантических моделей, причем аргумент в пользу «обычных» моделей может быть только один – относительная простота; по всем остальным показателям модели ISO 15926 являются более правильными и полезными.
Ниже мы детально рассмотрим эти утверждения, опираясь на практический пример, призванный четко обозначить взаимосвязь, сходства и различия ISO 15926 и «обычных» семантических моделей. Пока же обратимся к идеологии создания и применения семантических моделей данных («обычной» семантикой мы будем называть модели, построенные не в соответствии с ISO 15926).
Семантические модели и их применения
Основной движущей идеей при создании семантических технологий явилась необходимость обеспечения «понимания» алгоритмами вычислительных машин смысла (семантики) данных. Таким образом, исходной задачей этих технологий была аналитика: обеспечение возможностей извлечения знаний из связанных наборов информации.
По мере развития этих технологий, экспериментов по их применению в различных сферах, выяснилось, что они исключительно удобны для объединения (связывания) данных из различных по структуре источников. Отсюда возникло второе направление развития инструментов, основанных на идеях семантических сетей – интеграция информационных систем.
Никакого противоречия между аналитическим и интеграционным применением семантики нет; напротив, они находятся в неразрывном единстве. Ведь целью интеграции, как правило, является извлечение каких-то новых знаний из объединенного набора – таких знаний, которые не могли быть получены из каждого источника в отдельности. Задача упрощения переноса информации из одной информационной системы в другую тоже может быть решена при помощи семантических технологий, но является, скорее, дополнительным бонусом от их развития.
В ряде сфер применения удалось добиться существенных прорывов с использованием семантических технологий анализа информации. Особенно убедительными являются эти успехи в сфере медицины и биотехнологий. Например, на семантических технологиях строятся базы, объединяющие сведения о медицинских препаратах и их действии, клинические истории, генетическую информацию. Анализ таких баз помогает исследователям создавать новые лекарства. Это отличный пример ситуации, когда реляционные базы данных не в состоянии адекватно отразить многообразие связей между информационными объектами, и предоставить инструменты для анализа этих связей – а семантические технологии могут. Также семантические базы данных используются в здравоохранении (для анализа распространения заболеваний), и во множестве других применений.
Средства анализа информации при помощи семантических технологий входят и в повседневную жизнь. Например, разработчики Facebook Graph Search придумали отличный пример, который позволяет на обыденном уровне продемонстрировать принципиальную новизну семантического поиска (анализа): очевидно, что ни одна из существующих поисковых машин, строящихся по принципу поиска в тексте, не сможет ответить на вопрос «Какие рестораны нравились моим друзьям?», или «В каких городах живут мои родственники?». Поиск по графу, используя формализованный набор информационных объектов (люди, рестораны, города) и отношений между ними (нравится, живет в), способен дать нужный ответ быстро и совершенно точно. При этом условия запроса можно варьировать в тех пределах, которые допускает онтология (набор тех самых типов информационных объектов и связей между ними): аналогичные вопросы можно задать не о ресторанах, а о фильмах, не о родственниках, а об одноклассниках. Понятно, что все содержимое социальной сети Facebook представляет собой огромный единый информационный граф, с миллиардами узлов и связей. Возможность анализа и использования этих связей и составляет всю его ценность, что прекрасно понимают владельцы ресурса.
Опираясь на сказанное выше, мы можем определить критерии, которые должны предъявляться к информационным моделям, строящимся по принципам семантических технологий. Часть этих критериев вытекает из общих требований к моделям, часть – из специфики технологий, связанных с условиями их практической полезности. Перечислим их.
1. Результат выполнения какого-либо действия в реальной системе и в модели должен совпадать (отношения подобия между моделью и системой в исходном и конечном состоянии описываются одними и теми же правилами). Это требование обеспечивает прогностический потенциал модели: если оно выполнено, мы можем моделировать развитие системы, и воплощать результаты моделирования.
2. Модель должна отражать свойства объектов и связи между ними таким образом, который делает возможным извлечение знаний из модели при помощи существующих технологий (таких, как SPARQL). Это сугубо практическое требование, обеспечивающее пригодность модели для анализа. Фактически, оно декларирует возможность выполнения расчетов на модели.
3. Модель должна обеспечивать возможности расширения и масштабирования (укрупнения и детализации), без пересмотра ее онтологического ядра. Это требование налагает ограничения на отбор способов классификации объектов, разграничение объектов и их свойств; это требование можно серьезно детализировать.
Пример: создание и анализ «обычной» семантической модели
Рассмотрим теперь два «конфликтующих» способа построения моделей, и оценим их практическую полезность, исходя из перечисленных критериев. Пример мы возьмем из области промышленности, «родной» для обсуждаемого стандарта.
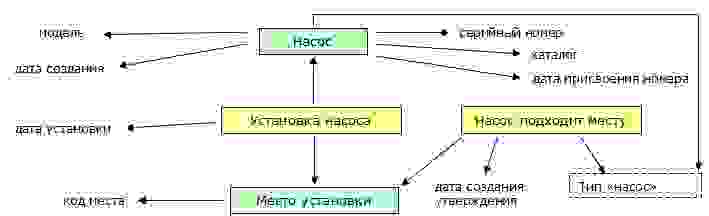
Желтым показаны объекты, соответствующие событиям, зеленым – материальные объекты, без рамки – литералы. В пунктирную рамку обведено определение класса, которое, в принципе, относится к справочным данным, а не к конкретной модели. Стрелками показаны связи объектов друг с другом, и объектов с литералами (свойствами) – ребра графа.
В результате импорта этой онтологии в SPARQL, получится набор из 16 триплетов (ребер графа). Они соответствуют показанным на схеме линиям, плюс по одному триплету для типа каждого объекта. Конечно, схема упрощена – например, «модель» должна быть не литералом, а ссылкой на соответствующий объект.
По этой ссылке можно скачать RDF-представление данной модели, а также набор триплетов, в которые она превращается после импорта в точку доступа SPARQL.
Рассмотрим возможности анализа этой модели. Например, пусть мы хотим узнать, в какое именно место был установлен насос с известным нам серийным номером. Для этого нам потребуется следующая последовательность простых запросов:
Этот запрос возвращает идентификатор объекта, содержащего информацию о насосе. Теперь найдем объект «установка насоса»:
Осталось узнать место установки:
Мы просмотрели три ребра графа; конечно, эти запросы можно объединить в один.
Пример: создание и анализ модели по стандарту ISO 15926
В соответствии со стандартом ISO 15926, наше событие – установка насоса – должно быть описано шаблоном InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace. В упрощенном виде структуру ролей этого шаблона, позволяющую выразить информацию, примерно эквивалентную той, что показана в примере выше, можно представить таким образом:
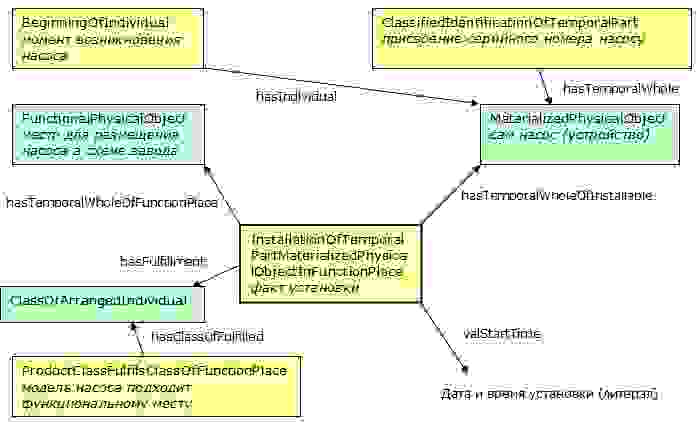
На этой диаграмме экземпляры шаблонов окрашены желтым цветом, экземпляры (instances) объектов – зеленым.
Такая структура, заполненная минимально необходимыми данными (без аннотаций), при импорте в SPARQL точку доступа превращается в 36 триплетов (скачать OWL и получающийся из него набор триплетов можно по этой ссылке). Отметим, что структура этих данных в триплетах получается вполне разумной, и не так уж сильно отличается от структуры модели без использования стандарта. Увеличение числа триплетов по сравнению с «обычной» семантической моделью в два с лишним раза связано с добавлением новых информационных объектов, а также ссылок на определения базовых типов, содержащихся во многих из них. Однако преобразование в триплеты справочных данных, особенно – определений шаблонов, даст гораздо худшие результаты с точки зрения оптимальности структуры графа. Так, определение только одного шаблона InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace составляет 148 триплетов, многие из которых включают blank nodes (узлы графа, не имеющие собственных идентификаторов). В том числе, многие триплеты связывают между собой два blank node. Работа с такими структурами средствами SPARQL сильно затруднена. На практике это выльется в серьезное возрастание сложности программного обеспечения, реализующего возможности создания или просмотра шаблонов. Для сравнения, «обычная» семантическая модель тех же самых данных укладывается всего в 38 триплетов, то есть она на порядок компактнее, чем модель ISO 15926 (не забудем, что упомянутые выше 148 триплетов описывают только один шаблон, а их в нашем примере четыре, плюс определения необходимых стандартных типов). Еще одно важное отличие состоит в том, что модель ISO содержит связи со внешними элементами, находящимися за пределами той точки доступа, в которой размещена текущая онтология – в частности, в RDL (Reference Data Library, каталог справочных данных; ниже мы еще вернемся к этим каталогам).
Рассмотрим возможности анализа модели, построенной по правилам ISO 15926. Выполним те же задачи, которые описаны выше для «обычной» семантической модели. Пусть мы хотим узнать, в какое именно место был установлен насос с известным нам серийным номером. В модели ISO нам потребуется следующая последовательность простых запросов:
Получаем в результате идентификатор экземпляра шаблона ClassifiedIdentificationOfTemporalPart. Теперь спрашиваем, с каким физическим объектом «насос» связан этот шаблон:
Получаем идентификатор насоса (объект типа MaterializedPhysicalObject). Теперь можем получить список экземпляров шаблона, описывающего установку насоса:
Получили идентификатор экземпляра шаблона InstallationOfTemporalPartMaterializedPhysicalObjectInFunctionPlace. Узнаем теперь, на какое функциональное место производилась установка:
Итак, нам потребовалось пройти четыре ребра графа. Очень важно, что для того, чтобы составить эти запросы, программист должен быть детально знаком с принципами ISO 15926, и обладать аннотированной библиотекой шаблонов (которой, на самом деле, нет в открытом доступе).
Сравнение аналитического потенциала моделей
Другой интересный аспект анализа этого графа связан со временем (учет темпорального аспекта является одной из сильных сторон ISO 15926). Если мы захотим узнать, какой насос был установлен на определенном функциональном месте в определенное время, нам придется сделать это при помощи не очень удобных средств работы с датами SPARQL. Сконструируем необходимый запрос.
Получаем эпизоды установки насоса, зная идентификатор функционального места:
Теперь получим идентификатор насоса – ради разнообразия примеров, сделаем это в том же самом запросе:
С насоса, скорее всего, будет ссылка на его тип в RDL – с ее помощью мы сможем узнать, какой именно это насос; но эту часть модели мы оставили за пределами нашего примера. Осталось добавить в запрос условие на даты установки:
Сочетание использования условия FILTER по дате установки, сортировки ORDER BY и ограничения количества выводимых результатов LIMIT дает нам только один нужный результат – позволяет отобрать эпизод установки насоса, предшествующий заданной дате.
На «обычной» семантической модели этот запрос будет иметь точно такую же структуру, и точно такое же количество элементов:
Еще один интересный аспект использования моделей, построенных в соответствии с ISO 15926, связан с использованием RDL – библиотек справочных данных. В них хранятся определения типов устройств, их функций и т.д. Эти библиотеки доступны во внешних SPARQL точках доступа, обычно принадлежащих каким-либо отраслевым ассоциациям. В нашем графе есть одна ссылка на RDL – это определение типа функционального объекта, говорящее нам о том, что им должно быть устройство с функцией насоса. Если мы запросим информацию о типе имеющегося у нас объекта FunctionalPhysicalObject,
то получим ссылку на RDL: (а заодно узнаем, что наш функциональный объект относится к классу WholeLifeIndividual, и нескольким другим корневым классам ISO 15926 – не очень полезная для нас информация). Если теперь мы захотим узнать, что означает данное определение, мы должны будем выполнить запрос к другой точке доступа, где хранится данный RDL:
Такой запрос вернет нам всю информацию, которая есть в RDL по данному типу устройств. В качестве RDL могут использоваться как библиотеки справочных данных (каталоги), поддерживаемые отраслевыми ассоциациями и регулирующими органами, так и частные каталоги, например, поставщиков определенного оборудования.
В «обычных» семантических моделях мы также можем использовать федеративные запросы. Мы можем создать общий каталог, например, оборудования, и разместить его в открытой точке доступа. Весь вопрос только в том, чьим «авторитетом» будет подкреплено такое хранилище информации. Придание авторитета справочникам является функцией различных ассоциаций. При этом, если не кривить душой, соответствие или не соответствие справочника тому или иному стандарту не добавляет к его «авторитету» практически ничего. Если же в качестве RDL используется каталог какой-то определенной компании, например, поставщика оборудования, то вопрос наличия «авторитета» полностью лишается смысла.
Сходства и различия «обычной» семантики и ISO 15926
Выводы из рассмотренных примеров использования семантических моделей вполне очевидны:
1. С технологической точки зрения, «обычные» семантические модели вполне симметричны моделям ISO 15926, если говорить о проектных данных (выражающих информацию о конкретных системах и процессах). Модели ISO имеют бóльшую сложность, и этот разрыв, в сравнении с «обычными» моделями, растет в зависимости от объема модели по линейному закону. Это объясняется наличием отдельных сущностей для выражения темпоральных частей объектов, а также необходимостью классифицировать объекты в соответствии с классификатором типов верхнего уровня.
2. С точки зрения вычислительного потенциала этих моделей – вычисления на них также несколько сложнее, чем в «обычной» семантике, но различие не является радикальным. Более существенно то, что для построения запросов необходимо не только знакомство с моделью, но и владение концепциями ISO 15926, а также наличие навигатора по шаблонам (который, насколько нам известно, отсутствует в открытом доступе; набор шаблонов и порядок их утверждения, насколько нам известно, тоже далеки от желаемых).
3. Система справочных данных и высокоуровневых сущностей ISO 15926 сильно усложнена по сравнению с «обычной» семантикой (если брать за показатель количество триплетов, требуемых для выражения модели – в 10 раз и более). В особенности это касается библиотек высокоуровневых сущностей, таких, как шаблоны. Работа с определениями (не экземплярами!) этих сущностей средствами семантических технологий значительно затруднена. Тем не менее, любое приложение, предоставляющее пользователю возможности работы с шаблонами, и «прячущее» от него их низкоуровневое представление, должно обладать широкими возможностями такой работы (поиск и просмотр, создание и редактирование определений шаблонов, их заполнение). Частичным решением проблемы может быть работа с шаблонами, выраженными не в виде триплетов в RDF-хранилище, а в виде файлов OWL.
4. Концепции ISO 15926, считающиеся его «ноу-хау», и обеспечивающие особую ценность этого стандарта – использование федеративного доступа и библиотек RDL, учет темпоральных частей – доступны и в «обычной» семантике. Все зависит от того, каким образом построена модель данных, и как реализовано разделение данных на проектные и справочные. Кстати, заметим, что нет никаких практических препятствий для использования библиотек RDL, построенных в соответствии с ISO 15926, в приложениях, использующих не соответствующие ему модели данных.
5. Действительную ценность стандарта составляет, прежде всего, его статус стандарта; общепринятые способы классификации и сами классификаторы (а также способы их администрирования) обеспечивают потенциал использования стандарта для интеграции между различными предприятиями, но несколько усложняют выполнение вычислительных задач на моделях. Это естественная ситуация: за любую универсальность приходится платить быстродействием.
Таким образом, стандарт ISO 15926 представляет собой один из способов построения семантических моделей, обладающий определенными достоинствами и недостатками по сравнению с другими способами, содержащими меньше высокоуровневого формализма. С точки зрения практической реализации и потенциала использования, между стандартом и другими способами нет принципиальной разницы, которая позволила бы противопоставить их как различные технологии. Декларирование наличия такой разницы могло бы считаться маркетинговым приемом пропаганды стандарта, если бы оно не играло вместе с тем отпугивающей роли для специалистов, уже знакомых с «обычными» семантическими технологиями (как это происходит сейчас на практике). К тому же, объяснить разницу между ISO 15926 и «обычной» семантикой на технологическом уровне людям, не являющимся ИТ-специалистами, но принимающим решения о создании той или иной программной инфраструктуры, крайне сложно.



