Семантический веб
Эта концепция была принята и продвигается Консорциумом W3. Для её внедрения предполагается создание сети документов, содержащих метаданные о ресурсах Всемирной паутины и существующей параллельно с ними. Тогда как сами ресурсы [2] предназначены для восприятия человеком, метаданные используются машинами (поисковыми роботами и другими интеллектуальными агентами) для проведения однозначных логических заключений о свойствах этих ресурсов.
Содержание
Основная идея
Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещённую в ней информацию более понятной для компьютеров. Машинная обработка возможна в семантической паутине благодаря двум её важнейшим характеристикам:

Критика
Практическая реализуемость
Несмотря на все преимущества, предоставляемые семантической паутиной в случае её внедрения, существуют сомнения в возможности её полной реализации.
Разные комментаторы высказывают различные причины, которые могут быть препятствием к этому, начиная с человеческого фактора [3] (люди склонны избегать работы по поддержке документов с метаданными, открытыми остаются проблемы истинности метаданных, и т. д.), и заканчивая косвенным указанием Аристотеля на отсутствие очевидного способа деления мира на концепты, что ставит под сомнение возможность существования онтологии верхнего уровня, критической для семантической паутины (см. понятие differentia specifica в «Топике»).
Дублирование информации
Необходимость описания метаданных так или иначе приводит к дублированию информации. Каждый документ должен быть создан в двух экземплярах: размеченным для чтения людьми, а также в машинно-ориентированном формате. Этот недостаток семантической паутины был главным толчком к созданию так называемых микроформатов и языка RDFa. Последний является вариантом языка RDF и отличается от него тем, что не определяет собственного синтаксиса, а предназначен для внедрения в XML-атрибуты XHTML-страниц.
Реализация
Языки описания
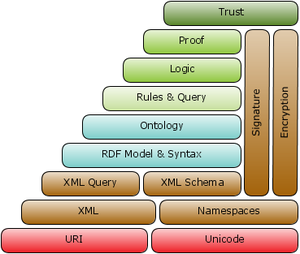
Техническую часть семантической паутины составляет семейство стандартов на языки описания, включающее XML Schema, RDF, RDF Schema, OWL, а также некоторые другие. Располагая их в порядке повышения уровня абстракции, реализуемого тем или иным языком, получаем:
Логический вывод
Форматы описания метаданных в семантической паутине предполагают проведение логического вывода на этих метаданных, и разрабатывались с оглядкой на существующие математические формализмы в этой области. Математическое обоснование тех или иных конструкций языка описания необходимо для проведения заключений о свойствах программ, обрабатывающих данные в этом формате.
Простая структура предикатов языка RDF, в свою очередь, позволяет использовать при его обработке опыт из теорий логических баз данных, логики предикатов, и т. д.
Проекты
Дублинское ядро
Одним из первых серьёзных и популярных проектов, основанным на принципах семантической паутины, стал проект «Дублинское ядро» (англ. Dublin Core ), реализуемый инициативной организацией Dublin Core Metadata Initiative (DCMI). Это открытый проект, цель которого — разработать стандарты метаданных, которые были бы независимы от платформ и подходили бы для широкого спектра задач. Конкретнее, DCMI занимается разработкой словарей метаданных общего назначения, стандартизирующих описания ресурсов в формате RDF.
RSS (версий 0.90 и 1.0)
Помимо недостатков, RSS унаследовал и все достоинства форматов из семейства семантической паутины: гибкость RSS позволяет использовать его не только для проверки на наличие новой информации на регулярно обновляющихся сайтах, но и для подкастов, и торренткастов (см. Broadcatching).
Заметим, что формат RSS версии 2.0, хотя и не является форматом, основанным на RDF, позволяет внедрение произвольного XML-содержимого, находящегося в собственных пространствах имён XML. Это позволяет использовать RDF-описания также и в нём (используя пространство имён rdf ).
Проект «» («Друг друга») позволяет описывать отношение знакомства с помощью RDF. Любой его участник может идентифицировать себя уникальным образом с помощью URI (например, mailto-адресом электронной почты, адресом блога, и т. п.), создать свой профиль, используя предопределённые для FOAF отношения на языке RDF, и перечислить идентификаторы людей, которых этот участник знает. Это описание может обрабатываться автоматически; на его основе можно строить сети доверия, анализировать структуру социальных групп, и т. д.
Семантические веб-сервисы
В то время как совокупность ресурсов и их метаданных можно считать статической частью семантической паутины, её динамическую часть представляют т. н. семантические веб-сервисы — законченные элементы программной логики с однозначно описанной семантикой, доступные через Интернет и пригодные для поиска, композиции и выполнения.
Технически, семантический веб-сервис отличается от обычного веб-сервиса наличием не только описания интерфейса (обычно на языке типов данных, передаваемых сервису, возвращаемых значений и генерируемых ошибок, но и семантического описания всех его характеристик. Заметим, что дублирования данных, упомянутого в числе недостатков семантической паутины, здесь не происходит: WSDL-описания изначально были предназначены для машинной обработки.
Потенциальная выгода от использования семантических веб-сервисов заключается в возможности автоматического поиска (а также композиции) программными агентами подходящих сервисов для решения поставленных задач. Тем не менее, сложность этой задачи в её общей формулировке пока позволяет добиваться некоторых положительных результатов только в узкоспециализированных отраслях, явным образом выигрывающих от внедрения сервисно-ориентированной архитектуры, например в интеграции корпоративных приложений.
Семантический веб и микроформаты
20.1. Семантический веб
20.1.1. Введение
Эта концепция была принята и продвигается Консорциумом W3 [2]. Для ее внедрения предполагается создание сети документов, содержащих метаданные о ресурсах Всемирной паутины и существующей параллельно с ними. Тогда как сами ресурсы предназначены для восприятия человеком, метаданные используются машинами ( поисковыми роботами и другими интеллектуальными агентами) для проведения однозначных логических заключений о свойствах этих ресурсов.
20.1.2. История
Semantic Web был задуман консорциумом W3 достаточно давно. С середины 90-х писались разные статьи и заметки, которые не привлекали особого внимания широкой общественности. Переломным моментом стала статья, опубликованная 17 мая 2001 г. в журнале Scientific American Тимом Бернерса-Ли, Джеймсом Хэндлером и Орой Лассила «The Semantic Web «
У этой статьи было одно назначение – привлечь внимание к Semantic Web всех, кого только можно было. Интерес к Semantic Web в 2001 году, конечно, появился, но профессиональные разработчики после прочтения этой статьи поняли, что до прихода Semantic Web еще должно пройти много времени, т.к. W3C не разработал к тому времени совершенно никаких технологий (кроме языка RDF ), которые могли бы хоть как-то помочь осуществить задуманное.
10 февраля 2004 г. на сайте W3C появляется описание языка » OWL » (язык описания онтологий ).
В 2005 г. на сайте W3 появляется описание RDF /A – синтаксиса, который уже сейчас позволяет встраивать метаданные RDF в документы XHTML.
20.1.3. Основные идеи
Semantic Web – это эволюция World Wide Web, информация в которой машинно-обрабатываемая (а не только ориентированная на обработку человеком), таким образом, позволяя браузерам или другим программным агентам производить поиск, распределять и комбинировать информацию намного проще [3]. Semantic Web предусматривает объединение этих разных видов информации в единую структуру, где каждому элементу «человеческой» информации будет соответствовать машинный код – специальный смысловой тэг.
Semantic Web в математической форме представляет собой разновидность графа – набора вершин, соединенных дугами. В Semantic Web роль вершин выполняют понятия базы знаний, а дуги (причем направленные) задают отношения между ними. Таким образом, семантическая сеть отражает семантику предметной области в виде понятий и отношений. Идея состоит в том, чтобы глобальной семантической сетью было подмножество систем, которые замкнуты на специфичных путях достижения достаточного удобства для машин. Таким образом, Семантическая Сеть сама собой не будет задавать выводящую машину. Она будет задавать валидность операции и требовать связей между ними.
Рассмотрим состояние современной глобальной сети и принципы работы современных поисковых систем [4].
Представление информации в сети:
Информация предназначена только для просмотра человеком, из чего вытекают следующие принципы работы поисковых систем сегодня:
Из-за этого возникают следующие проблемы:
Но есть и ряд положительных тенденций, которые позволяют практически приблизиться к Semantic Web :
Семантическая паутина – это надстройка над существующей Всемирной паутиной, которая призвана сделать размещенную в ней информацию более понятной для компьютеров. Машинная обработка возможна в семантической паутине благодаря двум ее важнейшим характеристикам [7]:
Пользователи получат массу вполне ощутимых преимуществ от реализации Семантической Сети. Когда все программы, будь то браузер, почтовый клиент или Веб-сайт, смогут понимать смысл той информации, с которой работает пользователь. Они смогут предоставлять ему дополнительные сервисы. Работа человека станет более эффективной, серфинг более осмысленным, а поиск в Интернете – более точным.
Здесь стоит отметить, что поисковые агенты получат возможность взаимодействовать не только с информацией, хранимой в сети и доступной ей для обработки, но еще и между собой. Это дает возможность, как проверять результат, полученный одним агентом, так и находить более качественное решение, а также уточнять полученные результаты. Это напоминает модель взаимодействия двух людей, обладающих определенными знаниями и ведущих диалог. Нельзя не заметить, что в данном случае у людей вероятно возникновение нового знания в результате этого диалога. То же самое можно сказать об агентах – в результате взаимодействия двух агентов может появиться новое для агента знание.
Однако при всей очевидной важности Semantic Web существует множество трудностей и неразрешимостей в его реализации.
Мечта логиков последнего столетия – найти язык, в котором все предложения были бы ложны или истины и, по возможности, без других вариантов. Эта попытка ограничить язык, чтобы избежать возможность внутренних противоречивых утверждений, которые не могут быть разделены только на истину и ее отсутствие.
В Semantic Web это выглядит как сугубо академическая проблема: когда на самом деле нечто оперирует с массой недостоверной информации с любой точки зрения и ограничивается тем, что использует для ограничения подсистемы Веб. Очевидно, оно не должно иметь возможность выводить внутренне-противоречивые утверждения, но это не страшно, когда язык достаточно мощный, чтобы описать это. Действительно, достоверные системы должны дать нам мощность сказать «Утверждение ложно» и цикл, который, если верить замкнутому противоречию будет разрешен сам по себе или преднамеренно. Типичный ответ системы, которая ищет утверждения, приводящие к внутреннему противоречию, возможно, будет похож на результат поиска противоречия из того же источника [5].
Проблема ложности не только в возможности выразить парадокс, но и в возможности, учитывая парадокс вывода иметь возможность вывести ложность.
Очень важным моментом является то, как информация будет представлена в сети. Тут есть определенные требования.
Системы представления знаний должны обладать следующими свойствами [4]:
Все это позволяет расширить возможности поиска, поиск в сети становится не просто сбором документов и оценки связи слов, например, стоящих друг от друга на определенном расстоянии, которым при формировании результатов запроса расставляются веса, влияющие на их порядок при выдаче
Таким образом, достигается один из главных эффектов Semantic Web – получение нового, «синтетического» смысла, выводимого на связях документов, содержавших этот смысл только потенциально. Такой результат, очевидно, следует понимать как первый этап извлечения «глубинной» семантики первого уровня.
С другой стороны, это уже означает, что, получив отношения между документами, можно шагнуть гораздо дальше простой выдачи текстовой информации. Можно не только выдать результаты, можно их, как минимум, проанализировать и подготовить, а на следующем шаге – создать автоматизированные системы обработки этой информации, тем самым, решив целый ряд практических проблем.
Технологии Semantic Web могут быть использованы в разных прикладных областях. Например, в области интеграции данных, в результате чего данные из разных источников и в разных форматах могут быть интегрированы в одном приложении; в области описания и классификации ресурсов для обеспечения более качественных, учитывающих предметную область, средств поиска информации; в области каталогизации, для описания содержимого и взаимосвязей между Веб-сайтами, страницами, или цифровыми библиотеками; в области программных агентов с развитой логикой, для облегчения распространения информации; в области рейтинговых систем; при описании коллекций страниц которые логически составляют один документ; для описания прав интеллектуальной собственности Веб-страниц и во многих других.
На эту основу, опираются дополнительные строительные блоки. Приведем несколько примеров.
Как и все инновационные технологии, Semantic Web претерпевает эволюцию: сначала развивается в исследовательских лабораториях, затем получает поддержку Open Source сообщества, потом появляются небольшие специализированные «стартапы», и, наконец, технология начинает получать широкую поддержку со стороны бизнеса. Так же, классическая Всемирная Паутина изначально была разработана в центре Физики Высоких Энергий.
20.1.4. Технологии и инструменты
20.1.4.1. Стек стандартов Semantic Web
Десятилетиями создатели информационных технологий упускали из виду предмет своей деятельности – информацию. Точнее, информация присутствовала, но как-то неявно, обычно ее отождествляли с данными. Semantic Web – одно из тех явлений в мире ИТ, которые заставляют всерьез задуматься о различии между данными и информацией [6].

Источник: О стеке стандартов Semantic Web [6]
Элементы семантической паутины
Сложность структуры современного информационного общества постоянно растёт. В связи с этим, требования к эффективности алгоритмов обработки информации также увеличиваются. В последнее время наиболее популярными направлениями в этой области являются Data Mining (DM), Knowledge Discovery in Databases (KDD) и Machine Learning (ML). Все они предоставляют теоретическую и методологическую базу для изучения, анализа и понимания огромных объёмов данных.
Однако этих методов не достаточно, если сама структура данных будет настолько плохо пригодной для машинного анализа, как исторически сложилось на сегодняшний момент в Internet.
Для решения данной проблемы предпринята глобальная инициатива реорганизации структуры данных Internet в целях преобразования его в Семантическую Паутину предоставляющую возможности по эффективному поиску и анализу данных как человеком так и программным агентам.
В этой статье рассмотрены основные технологии позволяющие реализовать Semantic WEB.
Важнейшим недостатком существующей структуры Internet является то, что он практически не использует стандартов представления данных удобных для понимания компьютером, а вся информация предназначена в первую очередь для восприятия человеком. К примеру, для того, чтобы получить время работы семейного врача, достаточно зайти на сайт поликлиники и найти его в списке всех практикующих врачей. Однако, если это просто сделать человеку то программному агенту в автоматическом режиме это практически невозможно, если только не создавать его с учётом жёсткой структуры конкретного сайта. 
Процесс дисциляции знания
Для решения подобных проблем используются онтологии, позволяющие описать любую предметную область в понятных для машины терминах и эффективно использовать мобильных агентов.
При использовании такого подхода, дополнительно к видимой человеком информации на каждой странице имеются также и служебная информация, позволяющая эффективно использовать данные программными агентами.
В свою очередь онтологии являются составной частью глобального видения развития сети Internet на новый уровень, называемый Semantic WEB (SW).
Стек понятий семантической паутины
Важнейшие понятия Semantic WEB
Для достижения столь сложной цели как глобальная реорганизация всемирной сети требуется целый набор взаимосвязанных технологий. На вышеприведённом рисунке приводится общая структура понятий Semantic WEB. Ниже приводится краткое описание ключевых технологий.
Semantic WEB
Понятие семантической паутины является центральным в современном понимании эволюции Internet. Считается, что в будущем данные в сети будут представлены как в обычном виде страниц, так и в виде метаданных, примерно в одинаковой пропорции, что позволит машинам использовать их для логических заключений реализуя все преимущества от использования методов ML. Повсеместно будут использоваться унифицированные идентификаторы ресурсов (URI) и онтологии.
Однако, не всё так радужно, существуют и сомнения в возможности полной реализации семантической паутины. Основные тезисы в пользу сомнения в возможности создания эффективной семантической паутины:
• Человеческий фактор люди могут врать, ленится добавлять метаописания, использовать неполные или просто неправильные метаданные. Как вариант решения данной проблемы можно использовать автоматизированные средства создания и редактирования метаданных.
• Излишнее дублирование информации, когда каждый документ должен иметь полное описание как для человека так и для машины.
Это отчасти решается внедрением микроформатов.
Кроме самих метаданных, важнейшей составной частью SW является семантические Web сервисы. Они являются источниками данных для агентов семантической паутины, изначально нацелены на взаимодействие с машинами, имеют средства рекламы своих возможностей.
URI (Uniform Resource Identifier)
URI является унифицированным идентификатором любого ресурса. Может указывать как на виртуальный так и на физический объект. Представляет собой уникальную символьную строку. Самым известным URI на сегодня является URL, являющейся идентификатором ресурса в Internet и дополнительно содержащий информацию о местонахождении адресуемого ресурса.
Базовый формат URI
Онтологии
Рассмотрим общую структуру применения онтологий.
Часть возможной онтологии адресов
Пример возможного правила в онтологии адресов. В случае использования данной онтологии для того, чтобы отослать письмо в американский университет, достаточно указать его название, программный агент сам найдёт его адрес на основе стандартной адресной информации с сайта университета, если нужно отослать письмо на конкретный факультет, то с сайта будет получен список всех факультетов и выбран нужный, и уже с сайта требуемого факультета взят адрес, далее, используя вышеприведённую онтологию программа определит формат адреса принятый в США.
Компьютер не понимает всей информации в полном смысле слова, но использование онтологий позволяет ему намного более эффективно и осмысленно пользоваться доступными данными.
Конечно, остаётся много вопросов, к примеру, как в начале агент найдёт сайт требуемого университета? Однако для этого уже сейчас разработаны средства. К примеру, Язык Онтологии Сетевых Сервисов (Web Services Ontology Language, ) который позволяет сервисам рекламировать свои возможности, услуги.
Таксономии
Таксономии являются одним из вариантов реализации онтологий. С помощью таксономии возможно определить классы, на которые делятся объекты некоторой предметной области, а также то, какие отношения существуют между этими классами. В отличие от онтологий, задача таксономий чётко определена в рамках иерархической классификации объектов.
Современные языки описания онтологий
RDF (Resource Description Framework) язык описания метаданных ресурсов, главной его целью является представление утверждений в виде одинаково хорошо воспринимаемом как человеком, так и машиной.
Атомарным объектом в RDF является триплет: субъект — предикат — объект. Считается, что любой объект, можно описать в терминах простых свойств и значений этих свойств.
Пример таблицы с выделенными параметрами
Пример таблицы с выделенными параметрами
Перед двоеточием должен указываться Уникальный Идентификатор Ресурса URI (Uniform Resource Identifier), однако в целях экономии трафика допускается указать только пространство имён.
Также, в целях улучшения восприятия человеком, существует практика представления схем RDI в. виде графов.
Пример схемы RDI в виде графа
Не соответствует ни одной дескрипционной логике, так — как в принципе является не разрешимым.
На данный момент язык OWL является основным инструментом описания онтологий.
Программные (мобильные, пользовательские) агенты (SA)
В рассматриваемой ПРО SA считается программой, действующей от имени пользователя, самостоятельно выполняющей сбор информации на протяжении некоторого, возможно длительного времени. Также важной их особенностью является возможность взаимодействовать с другими агентами и сервисами для достижения поставленной цели.
В отличии от ботов поисковых машин, которые просто сканируют диапазоны WEB страниц, агенты перемещаются от сервера к серверу, на отправном сервере он уничтожается, а на принимающем создаётся с полным набором собранной ранее информации. Такая модель позволяет агенту использовать доступные серверу, источники данных, которые не доступны посредством WEB интерфейса.
Понятно, что на сервере должна быть установлена платформа, позволяющая принять агента и обслужить его запросы. Также важно уделить внимание безопасности и целостности агентов. Для этого применяется подход выделенных пространств, когда агент работает в некотором безопасном окружении с ограниченными правами и возможностями воздействия на систему.
Агенты по своей реализации делятся на обычные и обучающиеся.
Если первые предназначены для выполнения чётко поставленных задач, то в основу вторых заложена гибкость, обычно они создаются на основе нейронных сетей. Использование нейронных сетей позволяет агенту постоянно подстраиваться под требования пользователя, а также более эффективно взаимодействовать с Internet.
Микроформаты
div class =»vevent» >
a class =»url» href =»http://www.web2con.com/» >
http://www.web2con.com/
a >
span class =»summary» >
Web 2.0 Conference
span > :
abbr class =»dtstart» title =»2007-10-05″ >
October 5
abbr >
—
abbr class =»dtend» title =»2007-10-20″ >
19
abbr >
,at the
span class =»location» >
Argent Hotel, San Francisco, CA
span >
div >
В данном примере приведено описание создания корневого класса контейнера с датой (class=«vevent») и соотнесение с событием некоей даты в стандартном формате ISO date.
В этой сфере существуют множество новых разработок, к примеру, для автоматического построения автоматических классификаторов используют разные уровни онтологий в зависимости от исследуемых данных.
Эта статья является попыткой объединения данных из различных источников для получения представления об общей структуре развития Семантической Паутины.
Информационные интеллектуальные сети и Семантический Веб
Информационные интеллектуальные сети, Семантический Веб, Веб 3.0, ИИ… Эти слова все чаще стали появляться в нашем обиходе.
Целая эпоха универсального Интернета заканчивается. Она начинает сменяться до того, как мы начинаем это ощущать. На смену едва оформившемуся термину Web 2.0 уже приходит другой, непонятный и загадочный на первый взгляд — Web 3.0, или же просто «Семантический Веб».
О том, что это такое и куда движется наш интернет, я хотел поговорить в этой статье.
Сейчас сеть становится персональной. «Интернет все больше знает о нас». Отчасти, мы сами способствуем этому, раздавая свою персональную информацию в социальных сетях, пользуясь поисковыми системами, будучи авторизованными.
Это означает, что скоро, вводя в строку поиска «Хочу постричься недорого», пользователь получит ответ в виде ближайшей парикмахерской к его местоположению в виде четкого ответа на четкий вопрос – нам не надо будет переходить по 10, 20, 50 ссылкам из поисковой выдачи разных поисковиков, расстраиваясь в очередной раз, что очередная открытая вкладка – это очередной дорогой салон, продвигаемый силами SEO специалистов.
Это касается различных сфер жизни и деятельности человека – начиная от бытовых и заканчивая более глобальными. Например, покупка автомобиля или квартиры, поиск работы и другие.
Более того, поисковая система сможет определить, какой именно автомобиль нужен пользователю на основе информации о том, какими тест-драйвами он больше всего интересуется и какие автомобильные сайты посещает, в каком районе и в каком ценовом диапазоне вы хотите найти квартиру, не голодны ли вы, какую еду предпочитаете и так далее.
С развитием семантического веба после сбора определенных данных о пользователе технологии позволят составить его социально-демографический портрет. Собранные пользовательские данные компьютеры будут понимать уже как портрет личности.
Во многом такой динамике способствует стремление упростить сервисы и сделать упрощенный доступ пользователей к контенту. Ставшая модной в последняя время, авторизация через социальные сети (Вконтакте, Facebook), специальные сервисы (OpenID, OAuth), комментирование через виджеты социальных сетей.
Наши сотовые сети завязывают на себя персональную информацию.
Информация – вот что будет играть решающую роль в будущем интернете!
Продвигаемая крупными игроками рынка технология NFC – предоставляющая возможность совершать покупки, используя мобильный телефон (в том числе, оплачивать проезд в метро, например), все больше связывает наши сим-карты, телефоны, банковские карты, стягивая нашу персональную информацию в единую точку.
Попробуем во всем разобраться, но пока начнем по порядку с малого. Для начала давай-те вместе с вами рассмотрим интеллектуальные информационные системы (ИИС).
Информационные интеллектуальные системы
ИИС (intelligent information system) – это информационная система, которая основана на концепции использования базы знаний для генерации алгоритмов решения задач различных классов в зависимости от конкретных информационных потребностей пользователей.
Особенности и признаки интеллектуальности ИС
Коммуникативные способности ИИС характеризуют способ взаимодействия (интерфейса) конечного пользователя с системой.
Интеллектуальными считаются задачи, связанные с разработкой алгоритмов решения ранее нерешенных задач определенного типа
Интеллект представляет собой универсальный алгоритм, способный разрабатывать алгоритмы решения конкретных задач.
Если в ходе эксплуатации ИС выяснится потребность в модификации одного из двух компонентов программы, то возникнет необходимость ее переписывания. Это объясняется тем, что полным знанием проблемной области обладает только разработчик ИС, а программа служит “недумающим исполнителем” знания разработчика. Этот недостаток устраняются в интеллектуальных информационных системах.
Недостатки ИС и их устранение в ИИС
Классификация ИИС
I класс: системы с интеллектуальным интерфейсом (коммуникативные способности):
II класс: экспертные системы (решение сложных задач):
III класс: самообучающиеся системы (способность к самообучению):
Интеллектуальные БД
Интеллектуальные БД – отличаются от обычных возможностью выборки по запросу информации, которая может явно не храниться, а выводиться из имеющейся БД (например, вывести список товаров, цена которых выше отраслевой).
Естественно-языковой интерфейс предполагает трансляцию естественно-языковых конструкций на машинный уровень представления знаний. При этом осуществляется распознавание и проверка написанных слов по словарям и синтаксическим правилам. Данный интерфейс облегчает обращение к интеллектуальным БД, а также голосовой ввод команд в системах управления.
Гипертекстовые системы предназначены для поиска текстовой информации по ключевым словам в базах.
Системы контекстной помощи – частный случай гипертекстовых и естественно-языковых систем.
Системы когнитивной графики позволяют осуществлять взаимодействие пользователя ИИС с помощью графических образов.
Семантический Веб
HTML-страница описывает как представить информацию визуально в Веб-браузере и трудно поддаётся смысловому анализу компьютерами. Для неё невозможно автоматизировать даже такие тривиальные задачи, как нахождение людей, проектов, программ в Интернете.
Технология Семантический Веб (Semantic Web) позволяет компьютеру интерпретировать информацию в Вебе наравне с людьми, для чего разработана графовая модель описания ресурсов RDF (Resource Description Framework), которая является спецификацией W3C.
С помощью RDF можно создавать любые утверждения о любых ресурсах.
Графовая модель RDF
Утверждения о ресурсах в модели RDF состоят из троек.
Ресурсы и свойства представляются в виде URI, а литералы в формате Unicode. URI позволяет уникальным образом идентифицировать ресурсы в Вебе, а Unicode решает проблему мультиязычности.
RDF схема – это не XML схема
RDF схема описана в утверждениях RDF.
В отличие от XML схемы определяет ресурсы (термины) предметной области, а не ограничивает структуру RDF.
За ресурсами RDF схемы в спецификации W3C закреплена семантика.
Пример RDF схемы, описанной с помощью RDF
Семантика данных – что это такое?
Под семантикой данных будем понимать возможность формального описания смысла передаваемых данных, делая их независимыми от приложений. Это особенно важно в контексте рассматриваемых нами перспектив развития Интернета – побеждает тот, у кого есть данные. Может быть очень много приложений, сайтов, сервисов, но сами по себе они будут очень мало чего значить. Будут выигрывать те, кто сможет предоставлять свой контент в любом, удобном пользователю контенте.
Какие данные можно использовать независимо от сервисов, в которых они используются сегодня: данные из баз данных, XML-документы, приложения в социальных сетях? Нет, потому что их семантика зашита в логике программы и/или неформально в спецификациях. Только данные снабжённые явной семантикой можно сделать действительно независимыми от приложений!
Зачем нужен RDF? Чем плох XML?
Вложенность тегов XML несет только синтаксис, но не несёт никакой семантики. Если мы рассмотрим различные возможные формы представления утверждения “Иван Петров преподает курс информатики” в формате XML:
Приложение, которое использует первый формат, не сможет понять два других формата и наоборот. Поэтому, XML хорош только как формат (синтаксис) для обмена данными, но не как модель описания семантики данных! Это же можно сказать и про другие популярные форматы (JSON, например).
Где в RDF семантика?
На уровне модели RDF семантика появляется благодаря использованию онтологий OWL (Ontology Web Language), благодаря которым компьютер может понимать, как известный ему ресурс или свойство связано с другим, неизвестным ему ресурсом или свойством соответственно и производить другие логические выводы над утверждениями RDF.
Онтологии основываются на математическом аппарате формальной логики (description logic, DL), малое подмножество которого охвачено RDF схемой. DL является вычислимым подмножеством логики первого порядка.
Пример использования семантики
Как проинтерпретирует следующие утверждения приложение, которое понимает только ресурсы словаря foaf?
Оно поймёт, что Pugofka: semantic #Lector является foaf:Person и выведет новое утверждение:
Семантические хранилища
Предполагается, что большие объёмы RDF данных будут храниться в семантических хранилищах и для доступа к ним использоваться язык запросов SPARQL – аналог SQL.
Пример запроса “вывести все проекты, созданные Pugofka” на SPARQL:
В качестве примеров развития направления можно привести создание новых проектов. Так, например, компания «Clark&Parsia» (http://clarkparsia.com/) уже имеет несколько серьезных проектов в сфере Семантического Веба, и на первые числа Апреля назначен старт бета-тестирования RDF-базы данных под названием StarDog.
Уровни Семантического Веба
Эволюционный подход
Семантический Веб это не замещение существующего интернета, а всего лишь его эволюционное развитие. RDF/XML либо внедряется внутрь HTML или доступен по URL.
По этому принципу уже широко используются в WWW RDF-данные с использованием словарей RSS, FOAF (Friend Of A Friend), DOAP (Description Of A Project).
Пример кода FOAF на странице пользователя LiveJournal
Семантический веб – цели, задачи, примеры
Семантический Веб создан не на пустом месте. В него заложены фундаментальные основы:
Технологии, которые задействованы в Семантическом Вебе
Примеры программной поддержки технологии
Направления исследования
Задачи и проблемы Семантического Веба:
Заключение
Семантический Веб – это динамичная, постоянно развивающаяся концепция, а не набор комплексных, работающих систем.
Веб 3.0 – очень многогранное и, на текущий момент, до сих пор не сформированное понятие. Его можно рассматривать с разных точек зрения.
Например, с точки зрения машинной обработки данных – Семантический веб – это идея хранить данные такие образом, чтобы они были определенными и связанны, а также существовала возможность их дальнейшей автоматизированной обработки, интеграции и многократного использования в различных сервисах, приложениях и т.п.
С точки зрения интеллектуальных агентов, то целью будет являться более «машиноориентированный» Веб,
с тем, чтобы можно было наиболее эффективно использовать поисковых пауков (агентов) для поиска и обработки информации.
С точки зрения распределенных баз данных, баз знаний, то концепция Семантического Веба заключается в описании, добавлении дополнительной мета информации, которая позволяет однозначно идентифицировать и сопоставить информацию.
Концепция Веб 3.0 подразумевает наличие целой инфраструктуры.
С точки зрения обслуживания пользователей (потребителей контента) – идея Веб 3.0 заключается в минимизации действий пользователю и выдаче в качестве ответа на его запрос непосредственного ответа на его запрос, который будет учитывать не только его запрос, но и всю его историю, особенности (социально–психологический портрет), вкусы, интересы и многие другие факторы.
С точки зрения качества поиска – реализация поиска не только по ключевым словам или контексту, но и по контенту. Выдача точного ответа на запрос пользователя. Во многом, использование поисковой системы, как экспертной системы.
С точки зрения веб-сервисов Семантический Веб обеспечивает доступ не только к существующим статическим сайтам, но и к динамическим, приложениям, сервисам и другим ресурсам, содержащим полезный контент.



