HTTP сессия
Так как HTTP — это клиент-серверный протокол, HTTP сессия состоит из трёх фаз:
Начиная с версии HTTP/1.1, после третьей фазы соединение не закрывается, так как клиенту позволяется инициировать другой запрос. То есть, вторая и третья фазы могут повторяться.
Установка соединения
Так как HTTP это клиент-серверный протокол, соединение всегда устанавливается клиентом. Открыть соединение в HTTP — значит установить соединение через соответствующий транспорт, обычно TCP.
В случае с TCP, в качестве порта HTTP сервера по умолчанию на компьютере используется порт 80, хотя другие также часто используются, например 8000 или 8080. URL загружаемой страницы содержит доменное имя и порт, который можно и не указывать если он соответствует порту по умолчанию.
Отправка запроса клиента
Когда соединение установлено user-agent может послать запрос. (user-agent это обычно веб браузер, но может им не быть) Клиентский запрос это текстовые директивы, разделённые между собой при помощи CRLF (переноса строки). Сам запрос включает в себя три блока:
Примеры запросов
Получаем главную страницу developer.mozilla.org, http://developer.mozilla.org/, и говорим серверу, что user-agent предпочитает страницу на французском, если это возможно:
Обращаем внимание на пустую строку в конце, которая отделяет блок данных от блока заголовков. Так как в запросе отсутствует Content-Length: HTTP заголовок, блок с данными пуст и сервер может начать обработку запроса, как только получит пустую строку, означающую конец заголовков.
Отправляем результат сабмита формы:
Методы запроса
HTTP определяет набор методов запроса с указанием желаемого действие на ресурсе. Хотя они также могут быть и существительными, эти запросы методы иногда называют HTTP-командами. Наиболее распространённые запросы GET и POST :
Структура ответа от сервера
После того как присоединённый агент отправил свой запрос, веб сервер обрабатывает его и отправляет ответ. По аналогии с клиентским запросом, ответ сервера — это текстовые директивы разделённые между собой CRLF, сгруппированные в три разных блока:
Примеры ответов
Успешное получение веб страницы:
Сообщение о том, что запрашиваемый ресурс был перемещён:
Сообщение о том, что запрашиваемый ресурс не существует:
Коды статусов ответа
HTTP-коды ответов показывают, выполнен ли успешно определённый HTTP-запрос. Ответы сгруппированы в пять классов: информационные ответы, успешные ответы, редиректы, ошибки клиента и ошибки сервера.
Сессии. Подробное описание работы и объяснение механизма.
Подробно расписывать нужду в таком механизме я не буду. Это такие хрестоматийнык случаи, как корзина покупок в е-магазине, авторизация, а так же, и не совсем тривиальные проблемы, такие, например, как защита интерактивных частей сайта от спама.
В принципе, довольно несложно сделать собственный аналог сессий, не такой функциональный, как встроенный в PHP, но похожий по сути. На куках и базе данных.
При запросе скрипта смотрим, пришла ли кука с определенным именем. Если куки нет, то ставим ее и записываем в базу новую строку с данными пользователя. Если кука есть, то читаем из базы данные. Еще одним запросом удаляем из базы старые записи и вот у нас готов механизм сессий. Совсем несложно. Но есть некоторые нюансы, которые делают предпочтительным использование именно встроенного механизма сессий.
Если включена только первая, то при старте сессии (при каждом вызове session_start() ) клиенту устанавливается кука. Браузер исправно при каждом следующем запросе эту куку возвращает и PHP имеет идентификатор сессии. Проблемы начинаются, если браузер куки не возвращает. В этом случае, не получая куки с идентификатором, PHP будет все время стартовать новую сессию, и механизм работать не будет.
По умолчанию в последних версиях PHP включены обе опции. Как PHP поступает в этом случае? Кука выставляется всегда. А ссылки автодополняются только если РНР не обнаружил куку с идентификатором сессии. Когда пользователь в првый раз за этот сеанс заходит на сайт, ему ставится кука, и дополняются ссылки. При следующем запросе, если куки поддерживаются, PHP видит куку и перестает дополнять ссылки. Если куки не работают, то PHP продолжает исправно добавлять ид к ссылкам, и сессия не теряется.
Пользователи, у которых работают куки, увидят длинную ссылку с ид только один раз.
Следует помнить, что пхп лочит файл сессии. То есть, если один ваш скрипт стартует сессию и долго выполняется, а другой пытается в это время стартовать её с тем же идентификатором, то он зависнет. Поэтому в долго выполняющихся скриптах следует стартовать сессию только тогда, когда она нужна, и тут же закрывать её, с помощью session_write_close()
PHP для начинающих. Сессия

Начну с сессий — это один из самых важных компонентов, с которыми вам придется работать. Не понимая принципов его работы — наворотите делов. Так что во избежание проблем я постараюсь рассказать о всех возможных нюансах.
Но для начала, чтобы понять зачем нам сессия, обратимся к истокам — к HTTP протоколу.
HTTP Protocol
Изначально подразумевали, что по этому протоколу будет только HTML передаваться, отсель и название, а сейчас чего только не отправляют и =^.^= и(•_ㅅ_•)
Чтобы не ходить вокруг да около, давайте я вам приведу пример общения по HTTP протоколу.
Вот пример запроса, каким его отправляет ваш браузер, когда вы запрашиваете страницу http://example.com :
А вот пример ответа:
Это очень упрощенные примеры, но и тут можно увидеть из чего состоят HTTP запрос и ответ:
Т.е. если украсть cookie из вашего браузера, то можно будет зайти на вашу страничку в facebook от вашего имени? Не пугайтесь, так сделать нельзя, по крайней мере с facebook, и дальше я вам покажу один из возможных способов защиты от данного вида атаки на ваших пользователей.
Давайте теперь посмотрим как изменятся наши запрос-ответ, будь там авторизация:
Метод у нас изменился на POST, и в теле запроса у нас передаются логин и пароль. Если использовать метод GET, то строка запроса будет содержать логин и пароль, что не очень правильно с идеологической точки зрения, и имеет ряд побочных явлений в виде логирования (например, в том же access.log ) и кеширования паролей в открытом виде.
Как можно заметить, заголовки отправляемые браузером (Request Headers) и сервером (Response Headers) отличаются, хотя есть и общие и для запросов и для ответов (General Headers)
Сервер узнал нашего пользователя по присланным cookie, и дальше предоставит ему доступ к личной информации. Так, ну вроде с сессиями и HTTP разобрались, теперь можно вернутся к PHP и его особенностям.
PHP и сессия
Я надеюсь, у вас уже установлен PHP на компьютере, т.к. дальше я буду приводить примеры, и их надо будет запускать
Вот вам статейка на тему PHP is meant to die, или вот она же на русском языке, но лучше отложите её в закладки «на потом».
Перво-наперво необходимо «стартовать» сессию — для этого воспользуемся функцией session_start(), создайте файл session.start.php со следующим содержимым:
Запустите встроенный в PHP web-server в папке с вашим скриптом:
Запустите браузер, и откройте в нём Developer Tools (или что там у вас), далее перейдите на страницу http://127.0.0.1:8080/session.start.php — вы должны увидеть лишь пустую страницу, но не спешите закрывать — посмотрите на заголовки которые нам прислал сервер:
Там будет много чего, интересует нас только вот эта строчка в ответе сервера (почистите куки, если нет такой строчки, и обновите страницу):
Увидев сие, браузер сохранит у себя куку с именем `PHPSESSID`:
PHPSESSID — имя сессии по умолчанию, регулируется из конфига php.ini директивой session.name, при необходимости имя можно изменить в самом конфигурационном файле или с помощью функции session_name()
И теперь — обновляем страничку, и видим, что браузер отправляет эту куку на сервер, можете попробовать пару раз обновить страницу, результат будет идентичным:
Итого, что мы имеем — теория совпала с практикой, и это просто отлично.
Обновляем страничку и видим время сервера, обновляем ещё раз — и время обновилось. Давайте теперь сделаем так, чтобы установленное время не изменялось при каждом обновлении страницы:
Обновляем — время не меняется, то что нужно. Но при этом мы помним, PHP умирает, значит данную сессию он где-то хранит, и мы найдём это место…
Всё тайное становится явным
В вашей конфигурации путь к файлам может быть не указан, тогда файлы сессии будут хранится во временных файлах вашей системы — вызовите функцию sys_get_temp_dir() и узнайте где это потаённое место.
Так, идём по данному пути и находим ваш файл сессии (у меня это файл sess_dap83arr6r3b56e0q7t5i0qf91 ), откроем его в текстовом редакторе:
Как видим — вот оно наше время, вот в каком хитром формате хранится наша сессия, но мы можем внести правки, поменять время, или можем просто вписать любую строку, почему бы и нет:
Так, что мы ещё не пробовали? Правильно — украсть «печеньки», давайте запустим другой браузер и добавим в него теже самые cookie. Я вам для этого простенький javascript написал, скопируйте его в консоль браузера и запустите, только не забудьте идентификатор сессии поменять на свой:
Вот теперь у вас оба браузера смотрят на одну и туже сессию. Я выше упоминал, что расскажу о способах защиты, рассмотрим самый простой способ — привяжем сессию к браузеру, точнее к тому, как браузер представляется серверу — будем запоминать User-Agent и проверять его каждый раз:
Ключевое слово в предыдущем абзаце похоже, в реальных проектах cookies уже давно «бегают» по HTTPS протоколу, таким образом никто их не сможет украсть без физического доступа к вашему компьютеру или смартфону
Стоит упомянуть директиву session.cookie-httponly, благодаря ей сессионная кука будет недоступна из JavaScript’a. Кроме этого — если заглянуть в мануал функции setcookie(), то можно заметить, что последний параметр так же отвечает за HttpOnly. Помните об этом — эта настройка позволяет достаточно эффективно бороться с XSS атаками в практически всех браузерах.
По шагам
А теперь поясню по шагам алгоритм, как работает сессия в PHP, на примере следующего кода (настройки по умолчанию):
А есть ли жизнь без «печенек»?
PHP может работать с сессией даже если cookie в браузере отключены, но тогда все URL на сайте будут содержать параметр с идентификатором вашей сессии, и да — это ещё настроить надо, но оно вам надо? Мне не приходилось это использовать, но если очень хочется — я просто скажу где копать:
А если надо сессию в базе данных хранить?
Отдельно замечу, что не надо писать собственные обработчики сессий для redis и memcache — когда вы устанавливаете данные расширения, то вместе с ними идут и соответствующие обработчики, так что RTFM наше всё. Ну и да, обработчик нужно указывать до вызова session_start() 😉
Когда умирает сессия?
За время жизни сессии отвечает директива session.gc_maxlifetime. По умолчанию, данная директива равна 1440 секундам (24 минуты), понимать её следует так, что если к сессии не было обращении в течении заданного времени, то сессия будет считаться «протухшей» и будет ждать своей очереди на удаление.
Интересен другой вопрос, можете задать его матёрым разработчикам — когда PHP удаляет файлы просроченных сессий? Ответ есть в официальном руководстве, но не в явном виде — так что запоминайте:
Самая тривиальная ошибка
Ошибка у которой более полумиллиона результатов в выдаче Google:
Cannot send session cookie — headers already sent by
Cannot send session cache limiter — headers already sent
Для получения таковой, создайте файл session.error.php со следующим содержимым:
Во второй строке странная «магия» — это фокус с буфером вывода, я ещё расскажу о нём в одной из следующих статей, пока считайте это лишь строкой длинной в 4096 символов, в данном случае — это всё пробелы
Для проверки полученных знаний, я хочу, чтобы вы реализовали свой собственный механизм сессий и заставили приведенный код работать:
Блокировка
Ещё одна распространённая ошибка у новичков — это попытка прочитать файл сессии пока он заблокирован другим скриптом. Собственно, это не совсем ошибка, это недопонимание принципа блокировки 🙂
Но давайте ещё раз по шагам:
«Воткнутся» в данную ошибку очень легко, создайте два файла:
Есть пару вариантов, как избежать подобного явления — «топорный» и «продуманный».
«Топорный»
Использовать самописный обработчик сессий, в котором «забыть» реализовать блокировку 🙂
Чуть лучше вариант, это взять готовый и отключить блокировку (например у memcached есть такая опция — memcached.sess_locking) O_o
Потратить часы на дебаг кода в поисках редко всплывающей ошибки…
«Продуманный»
Куда как лучше — самому следить за блокировкой сессии, и снимать её, когда она не требуется:
— Если вы уверенны, что вам не потребуется вносить изменения в сессионные данные используйте опцию read_and_close при старте сессии:
Таким образом, блокировка будет снята сразу по прочтению данных сессии.
— Если вам таки нужно вносить изменения в сессию, то после внесения оных закрывайте сессию от записи:
В заключение
В этой статье вам дано семь заданий, при этом они касаются не только работы с сессиями, но так же познакомят вас с MySQL и с функциями работы со строками. Для усвоения этого материала — отдельной статьи не нужно, хватит и мануала по приведенным ссылкам — никто за вас его читать не будет. Дерзайте!
Что такое сессии и как с ними работать в php
Протокол http, используемый для загрузки содержимого web-страниц, работает следующим образом: клиент присылает серверу http-запрос, сервер его обрабатывает и отправляет клиенту сформированный ответ. Всё, на этом общение закончено. Если нужны новые данные — клиент посылает новый запрос, а сервер присылает новый ответ и так далее.
При этом существует ряд задач, когда серверу для формирования ответа нужно понимать, присылал ли этот клиент какие-то http-запросы ранее и что происходило в процессе их обработки. Самый очевидный пример — авторизация. Скажем, клиент в очередном http-запросе запрашивает какую-то страницу личного кабинета. Что делать серверу? Если клиент авторизован (ранее присылал правильные данные для авторизации), то нужно ему эту страницу показать, а если не авторизован — то не нужно. А как узнать, авторизован пользователь или не авторизован? Значит нужно где-то хранить результаты выполнения предыдущих http-запросов.
Как раз для таких случаев и придумали сессии, — специальный механизм, позволяющий серверу идентифицировать присылающих http-запросы клиентов, а также запоминать для этих клиентов различные данные.
Применительно к php можно сказать, что сессии — это механизм, позволяющий php-скрипту, обрабатывающему очередной http-запрос, сделать следующие вещи:
Работают сессии следующим образом: сервер запоминает данные сессии (какие-то переменные) в специальном хранилище, которое подписывает сгенерированным уникальным идентификатором. Этот же идентификатор отправляется клиенту. При следующем http-запросе клиент присылает серверу полученный идентификатор, по которому сервер понимает от какого клиента пришёл запрос и с каким хранилищем ему работать (откуда восстанавливать данные и куда их сохранять).
Для работы с сессиями в php существуют специальные встроенные функции. Этих функций довольно много, основные я опишу ниже, а остальные можете посмотреть в документации, например вот здесь. Функции для работы с сессиями имеют большое количество всяких настроек, которые можно настраивать через конфиг php-сервера (файл php.ini), либо задавать в качестве опций непосредственно при вызове соответствующих функций. Многие настройки можно посмотреть через php_info().
По-умолчанию в качестве хранилища данных сессий php использует обычные файлы во временной папке. За это отвечает опция session.save_handler, которая по умолчанию установлена в значение files. При желании можно назначить свои собственные обработчики на связанные с сессиями события (старт, идентификация, сохранение данных и так далее) и хранить данные сессии как угодно и где угодно. Путь ко временной папке можно узнать при помощи функции sys_get_temp_dir().
Скрипт php может передать клиенту идентификатор созданного хранилища с помощью установки cookie или дописывая его к расположенным на загруженной странице адресам в качестве параметра GET-запроса. Выбор способа определяется настройками session.use_cookies, session_use_only_cookies и session_use_trans_sid. По умолчанию php настроен на использование только cookies (первые две настройки установлены в единицу, а последняя — в ноль). Используемое имя сессионной куки по-умолчанию — PHPSESSID.
Клиент может передать php-скрипту на сервере полученный ранее идентификатор любым способом (через cookie в заголовке запроса или указывая в качестве параметра GET-запроса) независимо от настроек. В случае с редиректом через header(‘Location: url’) куки не работают и идентификатор сессии должен быть передан на сервер в качестве параметра GET-запроса.
Время жизни сессии определяется параметром session.gc_maxlifetime. По прошествии этого времени файлы данных сессии будут рассматриваться как мусор и могут быть удалены. Кроме того, можно задать время жизни отправляемой клиенту cookie (для этого используется параметр session.cookie_lifetime). По-умолчанию для session.cookie_lifetime установлено значение 0, которое означает, что кука будет актуальна до закрытия браузера (просроченные куки называются «протухшими»).
Далее давайте рассмотрим основные функции для работы с сессиями из php скриптов. Лучше всего установить какой-нибудь WAMP/WNMP комплект и попробовать проделать своими руками всё, о чём ниже пойдёт речь. Я обычно использую OpenServer + Firefox (в этом браузере удобнее всего вызывать отладчик — одной кнопкой F12).
Функция session_start() имеет довольно много опций, которые позволяют настраивать различные параметры сессии (имя, время жизни, безопасность и так далее). Подробности можно прочитать в документации. Если никакие опции не указывать, то будут использоваться настройки по-умолчанию, — из конфига php. Главное правило при использовании функции session_start() состоит в том, что она должна вызываться до какого-либо вывода (то есть до начала формирования тела ответа).
Вторая нужная функция — ini_set(). С помощью этой функции можно менять настройки php по-умолчанию. При этом значения в файле php.ini не изменяются, новые настройки действуют только для текущего скрипта и только до окончания его обработки.
Ещё одна нужная функция — session_name(). С помощью этой функции можно получить имя текущей сессии (если вызвать функцию без параметров) или изменить имя сессии (если указать в качестве параметра новое имя).
Вообще, как я уже сказал, функций довольно много, у большинства из них есть куча разных настроек, так что доку тут читать не перечитать.
HTTP сессия. Session. Состояние сеанса. Работа с сессиями в ASP.NET MVC
Давайте рассмотрим такое понятие как сессия (HTTP-сессия, Session). Или по-другому, сеанс пользователя. Почему важно понимать механизм работы сессий. И посмотрим, как можно работать с состояниями сеансов на платформе ASP.NET.
Прежде чем мы дадим определение термину «сессия», давайте немного рассмотрим предысторию, зачем вообще возникла потребность в сессиях, рассмотрим одну особенность протокола HTTP.
Одной из основных особенностей протокола HTTP является то, что он не обязывает сервер сохранять информацию о клиенте между запросами, то есть идентифицировать клиента. Это так называемый stateless-протокол. Связь между клиентом и сервером заканчивается как только завершается обработка текущего запроса. Каждый новый запрос к серверу подразумевается как абсолютно уникальный и независимый, даже если он был отправлен повторно от одного и того же источника.
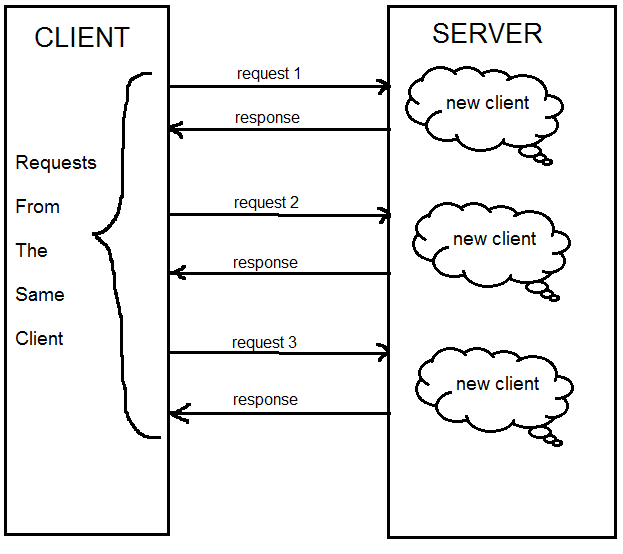
Что, если оставить stateless-природу протокола HTTP и не идентифицировать пользователя? Без состояний сеанса можно легко обойтись, если на вашем сайте представлена статичная (обезличенная) информация, например, новостная статья, состоящая из текста и изображений. В таком контексте совершенно необязательно ассоциировать несколько запросов с одним пользователем. Ведь содержание статьи никак не изменится, будь то десять запросов с одного устройства, либо десять запросов от разных людей с разных устройств.
Но как только мы собираемся передать персональную информацию на сервер, нам необходимо каким-то образом сделать так, чтобы сервер ассоциировал все наши запросы именно с нами, и в будущем верно определял все исходящие от нас запросы. Если этого не сделать, то с каждым новым запросом мы будем вынуждены повторно передавать необходимые персональные данные. Например, логин для входа в личный кабинет на сайте, или такую информацию как имя, адрес доставки, при совершении покупки в интернет-магазине.
Вот как раз в таких ситуациях, когда требуется персонализировать запросы от одного клиента, мы будем использовать сессии.
Когда клиент впервые передает персональные данные в запросе, на сервере создается новая сессия для этого клиента. В период времени жизни сессии все запросы от этого клиента будут однозначно распознаны и связаны с ним. По истечении этого времени связь с клиентом будет потеряна, и очередной запрос от него будет обрабатываться как абсолютно уникальный, никак не связанный с предыдущими.
Например, при совершении покупки в онлайн магазине персональная информация пользователя сохраняется в сессии, пока он путешествует по сайту. Это выбранные товары в корзине, адрес доставки, контактные данные и так далее.
Теперь давайте посмотрим, как это мы можем реализовать технически. Вообще существует несколько техник управления сессиями клиента, их количество и способ реализации во многом зависит от веб-платформы или технологии, что работает на сервере. В этом уроке мы рассмотрим следующие:
Попробуем их реализовать, используя платформу ASP.NET. Давайте кратко рассмотрим первые два механизма, и особое внимание уделим третьему, как более надежному, удобному и безопасному.
Скрытые поля на HTML-форме (hidden form fields)
Суть данного подхода состоит в том, что мы обеспечиваем навигацию по сайту при помощи стандартных html-форм. И при каждом следующем запросе мы сохраняем данные из предыдущего в скрытых полях на форме. Например:
Давайте рассмотрим особенности такого подхода. Плюсов практически нет, разве что реализовать данную технику можно очень быстро. Но опять же и другие подходы тоже можно реализовать очень быстро. А вот минусы есть, и довольно существенные:

Куки (cookies)
В данном подходе мы не храним сессионные данные непосредственно на форме, вместо этого используется стандартный механизм работы cookies между клиентом и сервером. В cookies и хранятся все пользовательские данные.
При выборе этого подхода опять же главной остается проблема безопасности наших данных, которые мы передаем на сервер – их легко подменить или украсть, они лежат в открытом виде. Также, если в настройках приватности браузера клиента отключен прием куки с сайтов, то такой вариант ведения сессии вовсе не будет работать.
Серверный механизм управления сессией (Session, SessionState)
Разберем, как работает механизм сессии со стороны сервера и со стороны клиента.
При стандартных настройках работы состояния сеанса для отслеживания серии запросов от одного клиента используется т.н. сессионная куки (session cookie). Алгоритм следующий:
В этом участке кода мы записываем в состояние сеанса имя пользователя. Это имя мы забираем с html-формы, которую он нам отправил. Дополнительно через свойства мы узнаем, создана ли эта сессия только что, то есть в рамках текущего запроса (если да, то и значение свойства IsNewSession будет равняться true), и уникальный идентификатор сессии. Этот идентификатор после обработки запроса будет автоматически записан в сессионную куки (если еще нет) и отправлен в ответе клиенту.
В браузере клиента можно наблюдать соответствующую куки и идентификатор его сессии:

В процессе следующего запроса от этого клиента давайте прочитаем его ранее сохраненное имя из сессии. Также принудительно завершим сессию. Работа с этим клиентом закончена, например, все данные обработаны и товар отправлен.
Как видно, работать с сессиями очень просто и удобно. Большинство процессов, связанных с обработкой сессии, происходит автоматически в фоновом режиме. Естественно, разработчик может вмешаться на любой стадии обработки сессии и внести свои коррективы.
В конфигурации выше мы указали, что таймаут сессии будет 40 минут, сессионные данные пользователя будут храниться в оперативной памяти, будут использоваться сессионные куки, также поменяли стандартное название такой куки на собственное.



