Статические данные: что это, способы задать статические данные

Статические и динамические данные — это то, с чем постоянно сталкивается программист, используя любой язык программирования. Программирование — это постоянная манипуляция какой-то информацией через:
Все это — представители статических или динамических данных. Начинающие программисты редко задаются вопросом, какие данные они используют в конкретный момент в программе. Это понимание обычно приходит с опытом. В начале карьеры программирование происходит по сценариям: «так научили» или «так работало в прошлый раз».
Динамические и статические данные в программировании
Более эффективные программы. Если программист понимает типы данных, ему будет легче правильно манипулировать памятью и хранилищем. В больших программах это особенно важно.
Статические данные — что это?
Как это выглядит в коде:
int myAge = 101; // при помощи «int» мы указываем, что это «целое число»
string myName = «Дормидонт» //при помощи «string» мы указываем, что наши данные — это «строка»
public int add(int x, int y) <
Чуть выше мы показали, как в Java объявить статические переменные со значениями «число» и «строка», а также изобразили пример функции, которая будет складывать два целых числа. Получается, что, используя статические данные (переменные, функции, аргументы), мы как бы «подсказываем» компилятору или интерпретатору, с каким типом данных он имеет дело. Если бы мы просто написали имя переменной «myAge», компилятор Java не догадался бы, что имеет дело с целыми числами. Хотя для нас как для людей ясно, что «мой возраст» — это число.
Статические данные используются в языках со статической типизацией. К таким языкам относят:
Динамические данные — что это?
Динамические данные — это данные, которым не нужно сразу определять тип. Определение типа данных лежит на плечах самого языка. Давайте рассмотрим вот такой код:
$myAge = 101; //определяем переменную, содержащую «числа»
$nyName = «Дормидонт» //определяем переменную, содержащую «строки»
//определяем функцию, которая будет складывать два числа
Динамические данные могут меняться в процессе выполнения программы. К примеру, дальше по скрипту мы могли написать что-то подобное:
$myAge = «сто один год» //определяем тип данных типа «строка»
Таким образом, мы одной и той же переменной «myAge» вначале задали тип данных «число», а чуть позже задали тип данных «строка». В Java такое не пройдет.
Вот и получается, что динамические данные определяются характеристиками самого языка. К динамически типизированным языкам относят:
Статические и динамические системы
Мы определили, что есть 2 системы ввода данных, которые определяют вид данных — это:
динамическая система — определяет динамические данные;
статическая система — определяет статические данные.
Статический подход — это лишняя «писанина» кода. Каждый раз нужно объявлять тип данных. В небольшой программе это не так страшно, но когда счет идет на десятки тысяч строк кода, это принимает совсем другие масштабы.
Тип данных в динамической системе определяется во время исполнения программы.
Заключение
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
АЛГОРИТМЫ И СТРУКТУРЫ ДАННЫХ
Электронный учебный материал для студентов всех специальностей факультета Прикладная информатика Кубанского государственного аграрного университета
Поиск
Введите ваш запрос для начала поиска.
Об авторах
Курс разработан на кафедре Компьютерных технологий и систем Кубанского государственного аграрного унивеситета. Авторами являются заведующий кафедрой, доктор технических наук, профессор Лойко Валерий Иванович и доцент кафедры, кандидат физико-математических наук Лаптев Сергей Владимирович.
Основные цели сайта
Сайт предназанчен для максимально эффективного и быстрого доступа ко всем материалам курса «Алгоритмы и структуры данных», имеющимся на кафедре компьютерных технологий и систем КубГАУ. Основной задачей его создания является повышения эффективности освоения дисциплины студентами и всеми желающими.
Понятие структуры данных
Графическое представление элемента структуры данных.

Как бы сложна ни была структура данных, в конечном итоге она состоит из простых данных (смотрите рисунки ниже).

Память машины состоит из миллионов триггеров, которые обрабатывают поступающую информацию. Мы, занося информацию в компьютер, представляем ее в каком-то виде, который на наш взгляд упорядочивает данные и придает им смысл. Машина отводит поле для поступающей информации и задает ей какой-то адрес. Таким образом получается, что мы обрабатываем данные на логическом уровне, как бы абстрактно, а машина делает это на физическом уровне.
Последовательность переходов от логической организации к физической показана на рисунке ниже

Классификация структур данных
Структуры данных классифицируются:
1. По связанности данных в структуре:
— если данные в структуре связаны очень слабо, то такие структуры называются несвязанными (вектор, массив, строки, стеки)
— если данные в структуре связаны, то такие структуры называются связанными (связанные списки)
2. По изменчивости структуры во времени или в процессе выполнения программы:
— полустатические структуры (стеки, деки, очереди)
3. По упорядоченности структуры:
— линейные (вектора, массивы, стеки, деки, записи)
— нелинейные (многосвязные списки, древовидные структуры, графы)
Наиболее важной характеристикой является изменчивость структуры во времени.
Статические структуры данных
Векторы

M1: Array [1..100] of integer;
M2: Array [1..10] of real;
Вектор состоит из совершенно однотипных данных и количество их строго определено.
Массивы

Для доступа к элементу двумерного массива необходимы значения пары индексов (номер строки и номер столбца, на пересечении которых находится элемент). На физическом уровне двумерный массив выглядит также, как и одномерный (вектор), причем трансляторы представляют массивы либо в виде строк, либо в виде столбцов.
Записи
Запись представляет из себя структуру данных последовательного типа, где элементы структуры расположены один за другим как в логическом, так и в физическом представлении. Запись предполагает множество элементов разного типа. Элементы данных в записи часто называют полями записи.

Логическая структура записи может быть представлена как в графическом виде, так и в табличном.
Таблицы

При задании таблицы указывается количество содержащихся в ней записей.
Операции с таблицами:
1. Поиск записи по заданному ключу.
2. Занесение новой записи в таблицу.
Введение в типы данных: статические, динамические, сильные и слабые
В этой статье будет объяснено, что такое типы данных, что подразумевается под терминами «статический», «динамический», «сильный» или «слабый», когда мы говорим о типах данных, и почему это должно нас волновать.
Что такое типы данных?
Если вы занимались программированием, вы наверняка видели переменные, параметры или значения, возвращаемые функциями. Они повсюду в мире программирования. Многие программисты начинают их использовать, даже не зная, что они задают компьютеру под капотом. При определении этих значений программист указывает компьютеру, как будет называться переменная, но также сообщает компьютеру, какой это тип данных. Это целое число? Это строка символов? Это одиночный символ или сложный тип, такой как a Point? Чтобы понять типы данных, нам может быть проще перевернуть термин и подумать о нем как о «типе данных», с которым мы имеем дело.
Если вы просмотрели информацию в Интернете, вы могли прочитать противоречивую информацию о «статических» и «динамических» типах данных, а также о «сильных» и «слабых» типах данных. Это не одно и то же. Когда мы будем рассматривать различные термины ниже, имейте в виду, что язык может включать комбинацию статических / динамических и сильных / слабых типов данных. Они не эксклюзивны. Например, язык может быть статичным и сильным или статичным и слабым. Но прежде чем мы зайдем слишком далеко в определение этих терминов, зачем нам вообще это волновать?
Почему мы должны заботиться о типах данных?
Каждый язык программирования имеет систему типов данных. Без системы типов компьютеры не знали бы, как представлять данные в наших программах. Они не знали бы, как взять этот тип данных и добавить их к этому другому типу данных или даже как сохранить данные. Задавая переменную как целое число, компьютер знает, сколько байтов ему нужно для представления значения и, что более важно, как он может выполнять с ним операции. Сложение двух целых чисел отличается от сложения двух строк. Единственный способ, которым компьютер знает, как обрабатывать данные, — это знать типы данных, с которыми он имеет дело.
Вы можете начать программировать, даже не зная ничего о действующих системах типов. Это часть красоты этих языков высокого уровня. Но понимание типов данных, с которыми вы имеете дело, и того, как лучше всего представить данные, с которыми вы работаете, дает огромные преимущества, такие как перечисленные ниже.
Статические и динамические системы ввода данных
Итак, типы данных — это то, как мы сообщаем компьютеру тип данных, с которыми имеем дело. Однако когда программист говорит, что система типов языка является статической или динамической, что они имеют в виду?
Языки с типизированными статическими данными — это те языки, которые требуют от программиста явного определения типа данных при создании фрагмента данных (будь то переменная, параметр, возвращаемое значение и т. Д.). Как правило, эти типы также фиксируются как такие на время существования программы и не меняют свой тип. Давайте посмотрим на пример:
В приведенном выше примере показано несколько определяемых переменных и пример функции, которая складывает два числа. Как видите, мы явно сообщаем языку (в данном случае Java), что имеем дело с целыми числами, строками и числами типа double. Без этих подсказок компилятору он не знал бы, как лечить myNumber. Это просто имя, которое имеет смысл для нас, а не для компьютера.
Некоторые языки со статической типизацией включают Java, C #, C ++ и Go. Но это лишь некоторые из многих.
Давайте сравним это с языком динамической типизации данных. Ниже приведен пример:
Некоторые из многих языков, которые являются динамическими, включают JavaScript, PHP, Python и Ruby.
Почему вы предпочитаете статику динамической или наоборот?
В случае языков со статическими типизированными данными, явно сообщая компилятору типы данных, с которыми вы имеете дело, он может обнаруживать типичные ошибки и ошибки в коде задолго до развертывания. Если вы определяете одно значение как целое число, а другое как строку, компилятор может поймать ошибку сложения во время компиляции и не позволит вам завершить сборку программы. Это хорошо тем, что чем раньше вы обнаружите ошибку, тем надежнее будет ваш код и тем меньше будет стоить вам и вашим клиентам ее исправление. Намного легче исправить ситуацию на ранней стадии, чем позже после развертывания.
Итак, статика — это правильный путь? Что ж, компромисс в том, что вы должны явно определить все, прежде чем использовать его. Вам нужно ввести больше кода, вы должны заранее знать тип данных, с которыми вы имеете дело (не всегда то, что вы знаете), и вы должны знать, что будет происходить в ваших операциях. Вы должны знать, что 1 / 3даст вам, 0а не.33333и тому подобное.
Динамические языки дают вам дополнительную гибкость в этой области. Программисты часто описывают их как «более выразительные». В PHP, например, вы получите то,.3333…что и ожидали. Однако проблема в том, что если интерпретатор ошибается в типах данных, вы должны знать об этом. В противном случае он может проскользнуть мимо. Поскольку мы не можем уловить все, код на динамических языках имеет тенденцию быть немного более подверженным ошибкам и нестабильным. Типы данных в этих динамических языках обычно определяются во время выполнения. Это затрудняет обнаружение многих ошибок, пока они не попадут в производственную среду. Он может нормально работать на вашей локальной машине разработки, но производственная среда выполнения может немного отличаться, что приведет к различным предположениям интерпретатора.
JavaScript — это язык, который считается динамическим. С введением TypeScript, надмножества JavaScript, программисты представили идею явного объявления типов данных для переменных, чтобы сделать язык более статичным. По мере роста популярности JavaScript — даже за пределами браузера с такими инструментами, как Node.js — программисты хотели добавить преимущества статической типизации данных, чтобы исключить некоторые неправильные предположения, которые JavaScript делает при работе с типами данных. JavaScript печально известен своими неверными догадкамипри работе с данными и их типами. Это пример превращения JavaScript, динамического языка, в нечто большее, чем язык со статической типизацией, для раннего обнаружения ошибок и создания более здорового кода. Это тем более важно, учитывая, что JavaScript проникает в серверные приложения с помощью Node.js.
Короче говоря, статические типы данных дают вам строгую среду и обычно дают более надежный код. Динамические языки дают вам гибкость и возможность писать код быстрее, но могут привести к большему количеству ошибок в коде, если вы не будете осторожны при проверке типов.
Сильные и слабые системы ввода данных
Как кратко упоминалось ранее, термины сильных и слабых типов данных часто путают со статическими и динамическими. Люди склонны смешивать статичность как синоним сильного и динамичного как слабого. Это не тот случай.
Сильные / слабые типы данных — это то, как язык обрабатывает значения, с которыми он оперирует. Будет ли язык незаметно делать какие-то предположения при работе с типами данных и помогать вам, или он просто остановится и пожалуется, что не знает, что делать? Давайте посмотрим на пример того, как это работает:
В этом примере C ++ мы пытаемся сложить целое число и строку. Да, язык статически типизирован, но он не пытается скрыть для программиста bцелое число, чтобы он мог сложить два числа вместе. Он просто сразу помечает проблему и отказывается. Эта проверка выполняется, когда мы пытаемся скомпилировать программу (или иногда IDE, когда вы ее пишете). Здесь мы пытаемся использовать тип таким образом, который противоречит его определению как строка. Строго типизированные языки включают в некоторой степени C #, Java, Go, Python и C ++, и все они помечают что-то подобное.
Теперь у C ++ есть способы ослабить свою строго типизированную систему, но это выходит за рамки данной статьи. Мы рассмотрим слабые типы данных, а затем поговорим о сильных / слабых вместе и о том, что все не так четко, как статическая / динамическая типизация.
Слабые языки с типизированными данными пытаются помочь программисту в выполнении своих операций. Давайте взглянем на JavaScript и посмотрим, как он может выполнять операцию, аналогичную той, что мы сделали в нашем примере на C ++ выше:
Если вы знаете что-нибудь о JavaScript и его особенностях, вы знаете, что приведенный выше код будет работать без проблем. Программисту это ни на что не укажет. Но он не выведет 10 на консоль, как вы могли ожидать. Вы могли подумать, что он увидит целое число и строку и скажет: «Ого, подожди минутку, я не знаю, что с этим делать!» Вместо этого JavaScript пытается принудить или преобразовать одно из значений, чтобы оно было похоже на другое, выполнить вычисление, дать результат и двигаться дальше. Здесь результат будет, «55»поскольку он преобразует значение переменной aв строку, а затем объединяет их. Результатом будет строковый тип данных.
Как видите, сила языка в том, насколько сильно он пытается использовать свои типы, чтобы понять намерения программиста и двигаться дальше.
Используя эти термины, мы можем сказать, что такой язык, как Python, который является динамическим, также является строго типизированным. Вам не нужно явно определять тип при создании значения (динамическая часть), но если вы попытаетесь и затем используете этот тип так, как он не ожидает, он немедленно отметит проблему и завершит работу (сильный набор текста).
Почему вы предпочитаете сильную слабую или наоборот?
Сильные языки — это строгие языки. Опять же, они удостоверяются, что точно знают, что намерен делать программист. Если возникает ошибка, чаще всего это ошибка программиста, не понимающего операций. Эти ошибки также потенциально указывают на непонимание проблемы. Если вы пытаетесь добавить 5число к «5«строке, то, возможно, вы не понимаете, почему это не имеет смысла для компьютера. Это заставляет вас прийти к истине об операции и прямо говорит компьютеру, что вы хотите сделать (обычно с помощью некоторой формы механизма преобразования / преобразования). Это, как правило, приводит к созданию более надежного и менее подверженного ошибкам кода в производственной среде, но добавляет время и препятствия для перепрыгивания во время разработки.
Слабые языки, опять же, больше полагаются на гибкость и выразительность, убирая строгую строгость сильного языка и позволяя программисту запустить свой код и запустить его. Но обратная сторона заключается в том, что компьютер делает предположения, которых программист, возможно, не предполагал.
JavaScript, язык со слабой типизацией (который также бывает динамическим), снова был усилен TypeScript, чтобы сделать его сильнее. Обработка типов данных в TypeScript позволяет программисту писать JavaScript с использованием явных типов и получать преимущества строго типизированного языка. Он обнаруживает множество ошибок во время компиляции и помогает предотвратить попадание расплывчатых предположений JavaScript в производственные системы. Но опять же, это происходит за счет более формального и строгого формата кодирования во время разработки. Даже редакторы кода, знающие TypeScript, могут помечать ошибки по мере их написания. VS Code — отличный тому пример.
Степени силы
Теперь мы рассмотрели сильную и слабую типизацию. Важно отметить, что, в отличие от четкой границы, существующей со статической / динамической типизацией, языки могут демонстрировать разную степень силы или слабости. Это ставит языки в широкий спектр. Вот почему в одних статьях говорится, что C ++ слаб, а в других — что он силен. Это отношения. Что делает его спектром, так это то, что некоторые языки предлагают инструменты, помогающие с преобразованием и изменением типов на лету. Некоторые используют такие вещи, как указатели. Вот почему вы можете слышать, как люди говорят, что Java более строго типизирован, чем C или C ++, хотя очевидно, что C ++ строго типизирован по сравнению с JavaScript.
Я считаю, что не так важно понимать все нюансы того, что делает язык сильным или слабым. Если вы знаете некоторые основы и можете различать уровни силы, вы будете в хорошей форме при выборе языка для данного проекта и его требований.
Выбор стиля, подходящего для вашего проекта
Есть много причин, по которым вы можете выбрать один язык вместо другого для своего следующего проекта. Системы типов, как правило, не попадают в список большинства людей из-за более серьезных соображений, таких как:
Но когда дело доходит до систем типов, имейте в виду, что если вы работаете над критически важным проектом, который должен быть эффективным с точки зрения памяти, строгим и где ошибки могут быть обнаружены на ранней стадии, вы можете захотеть взглянуть на что-то статически типизированное.. Если язык не должен делать предположений и требует явных инструкций, помогающих с критическими алгоритмами, также подумайте о том, что является строго типизированным. Это языки, которые вы, как правило, найдете, например, в играх с рейтингом «AAA».
Однако, если вы хотите получить что-то быстро и гибко, что дает некоторую выразительность программисту, то языки с динамической или слабой типизацией могут быть лучше.
Или вы можете предпочесть языки, в которых они сочетаются. Отчасти поэтому многие выбирают такой язык, как Python.
Заключение
В этой статье сделана попытка охватить вводные различия между системами статических и динамических типов, а также различия между системами сильных / слабых типов. Мы говорили о том, как они сравниваются, почему вы можете выбрать один из них, какие языки подходят для каждой из этих систем, и как вы можете использовать эти различия, чтобы выбрать язык для вашего следующего проекта.
Надеюсь, вы нашли эту статью информативной. Если вы уберете только одну вещь из этой статьи, пусть это будет идея о том, что статичность не обязательно означает сильную, а динамика не обязательно означает слабую. Языки могут содержать различные комбинации каждого из них. В случае сильного и слабого набора текста у вас может быть разная степень силы по отношению друг к другу.
Классификация структур данных

На этапе создания спецификаций и требований, необходимых для разработки качественного ПО, важно определить структуру и формат данных, используемых в программном приложении. Каким же образом классифицируются структуры данных? Какие форматы представления данных используются? Чем различаются статические, динамические и полустатические структуры? Об этом — наша статья.
Вне зависимости от сложности и содержания любые данные представлены в памяти электронно-вычислительных устройств (ЭВМ) в виде последовательности битов (двоичных разрядов), причем их значения — это соответствующие двоичные числа. Однако сами по себе битовые последовательности структурированы недостаточно, поэтому они не очень удобны для практического использования. Именно поэтому на практике применяют структуры данных, которые организованы более сложно. Понятие структуры тесно связано с понятием типа данных.
Классификация
Структуры данных бывают физические и логические. В отличие от последних, физические отражают, по сути, способ представления данных в памяти ЭВМ, поэтому их называют еще и внутренними.
По своему составу структуры данных классифицируют на следующие типы:
— простые. Их нельзя разделить на составные части, которые больше, чем биты, то есть мы говорим о неделимых единицах. Для простого типа ясно определен размер и способ размещения структуры в памяти ПК;
— сложные, они же интегрированные. Состоят из других структур данных, которые бывают как простые, так и, в свою очередь, тоже сложные.
По наличию связей структуры бывают:
— несвязные: массивы, векторы, строки, стеки (Last In, First Out), очереди (First In, First Out);
— связные (к примеру, связные списки).
Также существует понятие изменчивости — это изменение количества элементов либо связей между ними. По признаку изменчивости структуры бывают:
— статические;
— полустатические;
— динамические.
Классификацию можно посмотреть на картинке ниже:
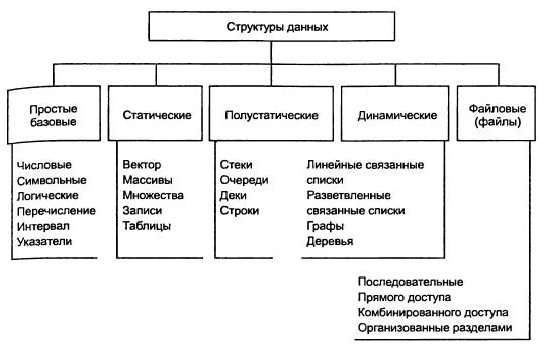
Здесь отдельного упоминания заслуживают файлы как структуры данных. Файлами называют, к примеру, совокупность записей, структурированных одинаково. Файлы бывают:
— прямого или комбинированного доступа;
Следующий критерий — характеристика упорядоченности элементов. По признаку упорядоченности структуры бывают:
— нелинейные: деревья, графы, многосвязные списки;
— линейные. По характеру распределения компонентов в памяти ЭВМ они могут иметь последовательное распределение (строки, векторы, массивы, стеки, очереди) и произвольное связное распределение (односвязные и двусвязные списки).
Когда мы указываем тип данных, мы четко определяем:
— размер памяти, который отводится под конкретную структуру;
— способ размещения структуры в памяти;
— значения, которые допустимы для этого типа данных;
— операции, которые поддерживаются.
Простые структуры данных
Как уже было сказано выше, это основа для создания более сложных структур. Также простые структуры называют примитивными либо базовыми (типами данных). Какие структуры сюда относят:
Для примера — структура простых типов для языка программирования Pascal:
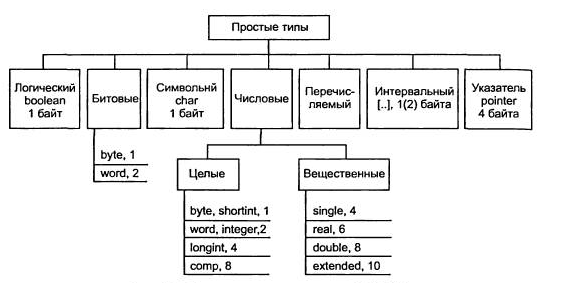
Далее — формат представления беззнаковых чисел:

И формат представления чисел со знаком:

Статические структуры
Это не что иное, как структурированное множество простых структур. К примеру, тот же вектор можно представить упорядоченным множеством чисел. Для статических структур изменчивость несвойственна, ведь размер памяти ЭВМ, который отводится для этих данных, является постоянным, выделяясь на этапе компиляции либо выполнения программы.
Вектор
Вектором также называют и одномерный массив. Это структура данных, где число элементов фиксировано, причем речь идет об однотипных компонентах. У каждого компонента — свой индекс (уникальный номер). С физической точки зрения векторные компоненты размещаются в памяти в ячейках, расположенных подряд.
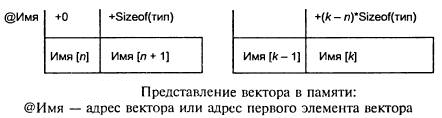
Двумерный массив
Двумерный массив (он же матрица) представляет собой вектор, причем каждый его элемент — тоже вектор. Если учесть внешние сходства, тогда то, что является справедливым для вектора, является справедливым и для матрицы.
Множество
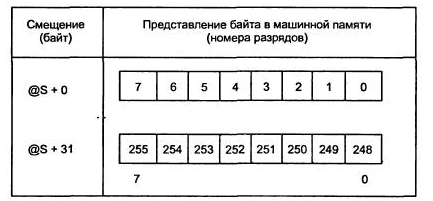
Это набор неповторяющихся данных одного типа. Множество способно принимать все значения базового типа, а так как он не должен превышать 256 значений, то типом элементов множеств могут быть char, byte и их производные.
В памяти множество хранится в виде массива битов, причем каждый бит показывает, принадлежит ли элемент объявленному множеству. Таким образом, максимальное число элементов множества равно 256, а множество может занимать не больше 32 байт.
Записи
Комбинированный тип данных, в котором значения представляют собой нетривиальную структуру. Записи формируются из нескольких полей разного типа, причем внешний доступ к этим полям происходит по именам полей. Из этого можно сделать простейшее заключение: записи — это средство представления программных моделей реальных объектов, ведь реальный объект имеет несколько внешних свойств, описываемых разнотипными данными.
К примеру, с помощью записи можно описать преподавателя университета. В этом случае объект «преподаватель» будет иметь следующие характеристики:
В памяти компьютера это можно представить:
— в виде последовательности полей, которые занимают произвольную непрерывную область памяти:

— в виде связного списка, имеющего указатели на значения полей записи:
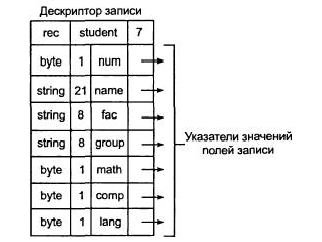
Полустатические структуры
— поддержка простых способов изменения этой длины;
— изменение длины возможно не в произвольных, а в определенных пределах, которые не будут превышать максимально-допустимые (предельные) значения.
С точки зрения логики полустатическая структура — это последовательность данных, связанная отношениями линейного списка. Доступ к элементу возможен по порядковому номеру.
С физической точки зрения полустатические структуры представлены в виде вектора, располагаясь в непрерывной области памяти ПК. Также их можно представить в качестве однонаправленного связного списка, где каждый последующий компонент адресуется указателем, который находится в текущем компоненте.
Примеры: стеки, строки, очереди, деки.
Динамические структуры
Не обладают постоянным размером, в результате чего память выделяется в момент создания элементов либо в процессе выполнения программы. Когда необходимость в элементе отпадает, занимаемая им память освобождается.
Так как компонент находится в памяти не по порядку и не в одной области, его адрес нельзя вычислить из адреса начального либо предыдущего компонента. Именно поэтому компонентная связь формируется через указатели, которые содержат соответствующие адреса в памяти. Это не что иное, как связное представление данных в памяти. Вывод напрашивается сам собой: такое представление обеспечивает высокую изменчивость структуры.
• размер структуры ограничивается лишь объемом памяти ЭВМ;
• во время изменения логической последовательности элементов (выполнении основных операций по удалению, добавлению, изменению порядка следования) нужна лишь коррекция указателей.
• работа с указателями требует от разработчика высокой квалификации;
• на указатели тратится дополнительная память;
• на доступ тратится дополнительное время.
Связные линейные списки
Это простейшие динамические структуры. Они представляют собой упорядоченные множества, которые содержат переменное число компонентов, причем отсутствуют ограничения по длине.
Ниже изображен односвязный список:

— INF — информационное поле, которое содержит данные;
— NEXT — указатель на последующий компонент списка;
— «Голова списка» — указатель на начало;
— nil — указатель на последний элемент.
На практике использовать и обрабатывать односвязный список не всегда удобно, ведь нельзя перемещаться в противоположную сторону, что ставит под вопрос оперативное выполнение некоторых операций. Однако такая возможность существует у двухсвязного списка, ведь в нем каждый элемент обеспечивает хранение двух указателей: на последующий и на предыдущий компоненты. Также для удобства обработки он имеет особый элемент — указатель конца списка. Но за повышенное удобство и оперативное выполнение операций надо платить — в случае с двухсвязным списком наличие 2-х указателей в каждом компоненте повышает сложность и становится причиной дополнительных затрат памяти.
Заключение
В качестве заключения скажем, что структуризация данных осуществляется сегодня множеством различных способов. Понимание особенностей структур данных, их строения, функций и основных характеристик позволит вам повысить качество создаваемого программного обеспечения, не говоря уже о более оперативной разработке. Также при определении формата данных нужно всегда учитывать специфику поставленных задач, делая это еще на этапе создания спецификаций и требований.



