Как создать отладочный сайт и тестировать на нем новые функции? ➤ Staging site

Как можно быстро протестировать на своем сайте новую функцию, обновление, дизайн, новый плагин и т.д. При этом ваш рабочий сайт будет работать и дальше без всяких сбоев и вмешательств. Ведь очень важно перед крупными изменениями сделать бэкап сайта, а еще лучше протестировать новые возможности перед использованием их на рабочем сайте. Ведь, иногда новые возможности и обновления могут сломать ваш сайт.
Что такое Staging сайт (Отладочный сайт) и как это можно использовать на практике?
Разработка любого сайта проходит в целом через 4 этапа:
Все сайты проходят через эти этапы. Кто-то быстро, а кто-то медленно, все зависит от сложности проекта. В мелких проектах каждый этап может выполнять вообще один человек — фрилансер. В более крупных проектах, за каждый этап отвечает своя группа специалистов. Например, на первом этапе подключаются программисты, верстальщики, дизайнеры и т.д. На втором этапе — тестировщики программного обеспечения.
Если проект крупный, то рабочий сайт работает на одном сервере, а Development работает на др. сервере, чтобы не нагружать рабочий сервер. Мелкие проекты и обычные сайты могут Development и Production делать на одном сервере.
Что такое отладочный сайт?
Отладочный сайт это веб-сайт используемый для сборки, отладки и тестирования этого сайта перед выкладыванием на рабочий сервер. Процесс тестирования программного продукта обычно происходит на точной копии оборудования и программного обеспечения, используемого на «боевом» сервере. Обычно перед выкладыванием свежей версии программного продукта его выливают на сайт для тестирования, где пользователи могут убедиться в том, что все заказанные возможности работают так, как предполагалось.
Как это можно использовать на практике?
Для мелкого проекта отладочный сайт мы можем использовать для тестирования и экспериментов.
Например, у нас есть рабочий сайт и нам нужно обновить WordPress до версии 5.5. Но, каковы будут последствия обновления? За последние дни на моем Youtube-канале и в Telegram появились сообщения об ошибках, конфликтах и неработающих плагинах. Вы не застрахованы от разного рода ошибок и конфликтов, которые могут появится после обновления.
И что делать? Протестируйте новую версию WordPress на отладочном сайте! Если все будет хорошо, то тогда вы спокойно сможете обновить WordPress и на рабочем сайте.
В каких еще случаях можно использовать отладочный сайт?
Как сделать отладочный сайт?
Как быстро можно сделать отладочный сайт для своих экспериментов и тестирования? Существуют бесплатные и платные плагины для создания отладочных сайтов. Рассмотрим два плагина, чтобы вы поняли сам принцип. См. видео.
Улучшаем тестирование путем использования реального трафика
TL;DR Чем ближе к реальности ваши тестовые данные, тем лучше. Попробуйте Gor — автоматическое перенаправление production трафика на тестовую площадку в реальном времени.
Здесь в Granify мы обрабатываем огромное количество генерируемых пользователями данных, наш бизнес построен на этом. Мы должны быть уверены что данные собираются и обрабатываются правильно.
Вы даже не представляете насколько странными могут быть данные пришедшие от пользователей. Источником могут быть прокси-серверы, браузеры о которых вы никогда не слышали, ошибки на клиентской стороне, и так далее.
Не важно сколько у вас тестов и фикстур, они просто не могут покрыть все случаи. Трафик с production всегда будет отличаться от ожидаемого.
Более того, мы может просто все сломать при обновлении версии, даже если все тесты прошли. На моей практике это случается постоянно.
Есть целый класс ошибок которые очень непросто найти автоматизированным и ручным тестирование: concurrency, ошибки в настройке серверов, ошибки которые проявляются при вызове команд только в определенном порядке, и многое другое.
Но мы можешь сделать несколько вещей что бы упростить поиск таких багов и улучшить стабильность системы:
Всегда тестируем на staging
Наличие Staging среды обязательно, и она должна быть идентична production. Использование таких средств как Puppet или Chef сильно облегчает задачу.
Вы должны требовать что бы разработчики всегда в ручную тестировали свой код на staging. Это помогает найти самые очевидные ошибки, но это все еще очень далеко от того что может случится на production трафике.
Тестируем на реальных данных
Есть несколько техник для позволяющих протестировать ваш код на реальных данных (я рекомендую использоваться обе):
1. Обновлять только 1 из production серверов, таким образом часть ваших пользователей будет обрабатываться новым кодом. Эта техника имеет несколько минусов: часть ваших пользователей может увидеть ошибки, и вам возможно придется использоваться «липкие» сессии. Это довольно похоже на A/B тестирование.
2. Воспроизведение production трафика (log replay)
Илья Григорик написал замечательную статью про нагрузочное тестирование используя log replay технику.
Все статьи что я читал на эту тему упоминают log replay как средство для нагрузочного тестирования используя реальные данные. Я же хочу показать как использовать эту технику для ежедневного тестирования и нахождения ошибок.
Такие программы как jMeter, httperf or Tsung имеют поддержку log replay, но она либо в зачаточном состоянии либо сфокусированная на нагрузочном тестировании а не эмуляции реальных пользователей. Чувствуете разницу? Реальные пользователе это не только набор запросов, очень важно правильный порядок и время между запросами, различные HTTP заголовки и так далее. Для нагрузочного тестирования это порой не важно, но для поиска ошибок это критично. К тому же эти средства сложны в настройке и автоматизации.
Разработчики очень ленивы. Если вы хотите что бы ваши разработчики использоватли какую либо программу/сервис, он должен быть максимально автоматизирован, а еще лучше что бы оно работало так что никто ничего не заметил.
Воспроизводим production трафик в автоматическом режиме
Я написал простую программу Gor
Gor — позволяет автоматические воспроизводить production трафик на staging в реальном времени, 24 часа в сутки, с минимальными затратами. Таким образом ваша staging среда всегда получает порцию реально трафика.
Gor состоит из 2-ух частей: Listener и Replay сервера. Listener устанавливается на production веб серверы, а дублирует весь трафик на Replay сервер на отдельной машине, который уже направляет его на нужные адрес. Принцип работы показан на диаграмме ниже:
Gor поддерживает ограничение количества запросов. Это очень важная настройка, так как staging как правильно использует меньше машин чем production, и вы может выставить максимальное кол-во запросов в секунду которое может выдержать ваша staging среда.
Вы можете найти подробную документацию на странице проекта.
Так как Gor написан на Go, для запуска мы можете просто использовать уже скомпилированный дистрибутив Downloads
В Granify, мы используем Gor в production в течении некоторого времени, и очень довольны результатами.
Введение в методологию DevOps. Основные определения
Цель:Получить вводные знания по DevOps, ознакомится с методологией и основными определениями.
Но это не совсем верно. DevOps это не технология и не язык программирования. Сам по себе DevOps это методология разработки программного обеспечения.
Методология DevOps сосредоточена на коммуникации, сотрудничестве и интеграции между подразделениями разработки и эксплуатации. Создание продукта требует больших временных затрат и состоит из нескольких итераций, таких как разработка идеи-концепции, написание кода, тестирование, деплой приложения. Конечной целью является качественный продукт, доставленный вовремя. Над этим работает команда разработчиков, тестировщики и адмнинов. Каждая команда обладает своей зоной ответственности.
Разработчики пишут код, причем каждый пишет свою часть,которую потом интегрирует в общий продукт.
Задача operations команды, в свою очередь, заключается в том, чтобы готовый код правильно функционировал в различных средах разработки.
Все команды взаимно зависят друг от друга, без их взаимодействия и эффективной коммуникации продукт разработан не будет.
Каждая итерация требует временных затрат и, конечно же, компаниям-разработчикам программного обеспечения и заказчикам этого программного продукта хочется сократить время поставки без потери качества. Сделать это за счет сокращения времени написания кода или тестирования, невозможно.
Экономия времени возможна только за счет сокращения времени простоя между итерациями разработки ПО. Другими словами, за счет сокращения времени ожидания командами своей работы.
Теперь у вас есть понимание классической DevOps методологии. На практике чаще всего применяются DevOps концепции, относящиеся к инфраструктуре приложений, а под DevOps инженером понимаю специалиста, который отвечает за инфраструктуру, развертывание, мониторинг и доступность приложений. Также DevOps инженер отвечает за настройку окружений для разработчика, тестировщика и в продакшене.
DevOps концепции, которые используются чаще всего на практике.
SaaS. PaaS. IaaS.
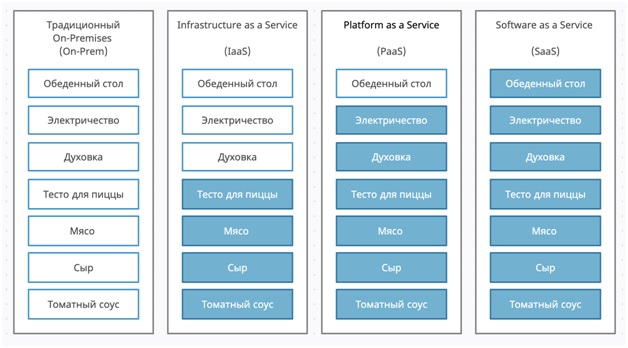
Pet vs Cattle
Концепция, название которой переводится как «Домашние питомцы против рогатого скота». Звучит странно, поэтому на русский язык название концепции чаще всего не переводится. В целом концепция заключается в двух различных подходах к управлению системами на серверах.
Оба подхода имеют право на жизнь и используются по сей день в разных видах, но уже чаще на разных уровнях и с разными типами приложений.
Минусы и плюсы разумеется есть у обоих подходов, и в основном это касается ресурсов затрачиваемых на поддержку системы и глубины знаний требуемых для поддержки этой самой системы.
Dev, Stage и Production Развертывание для сайтов WordPress?
Итак, мой вопрос, как вы, ребята, делаете это? У меня был быстрый Google и я увидел, что там было несколько плагинов, это единственный способ? Какие из них делают работу лучше всего с точки зрения простоты использования, скорости, надежности, пользовательского интерфейса и т. Д.?
У меня есть установка, которой я очень горжусь, и она отлично работает для моей команды.
Общая структура
Среды разработки
Сценическая среда
Когда коммиты передаются из develop ветки в Gitosis, они автоматически развертываются на нашем промежуточном сервере. Промежуточная база данных является подчиненной производственной базе данных.
Производственная среда
Когда коммиты отправляются в Gitosis в master филиале, он автоматически развертывается на производственном сервере.
Проблема с wp-config.php
Другие заметки
У меня было около 10 разработчиков, которые работали над этой структурой больше года, и работать с ней было мечтой. Надежный, безопасный, быстрый, функциональный и гибкий, вы не можете требовать гораздо большего!
Во-первых, я считаю важным рассмотреть, что вы собираетесь использовать для контроля версий. Я рекомендовал бы против положить весь каталог WP под VC. Я думаю, что имеет смысл поместить wp-content / themes / YourThemeName в VC. Для большого сайта с большим количеством сложных плагинов я мог бы увидеть случай включения wp-content / plugins. Если вам абсолютно необходимо, вы можете включить wp-content / uploads. Ответы ниже будут немного меняться, в зависимости от того, какой у вас контроль версий.
Учитывая это, вот что я использую:
Разработка: Оформление рабочей копии вашего репо в вашу среду WP. Установите POST-COMMIT Hook в SVN, чтобы обновить этот репо при каждом коммите. Это будет синхронизировать. (Считайте это непрерывной интеграцией бедняка.)
Производство: Проверьте именованный тег версии, представляющий окончательного кандидата. Когда вам нужно будет использовать новую версию, переключите тег и обновите репо.
Основы организации CI/CD
В данной статье рассмотрим основные варианты организации CI/CD, которые можно реализовать с использованием werf.
Цель организации CI/CD для нас проста: доставить новые изменения в коде до конечного пользователя как можно быстрее. CI/CD состоит из 2‑х частей: CI подразумевает непрерывное слияние изменений в основную кодовую базу, а CD непрерывную доставку этих изменений до пользователя.
Сначала мы дадим понятия окружений и workflow, а затем перейдем к описанию готовых workflow, которые можно сконструировать из приведённых составляющих. Рекомендуется также ознакомиться со следующими статьями для настройки конкретных CI/CD систем:
Основы
NOTICE: По тексту далее git можно интерпретировать как имя нарицательное для любой системы контроля версий, однако werf поддерживает лишь эту систему контроля версий. Предполагается знакомство читателя с такими терминами, связанными с git, как: ветка (branch), тег (tag), мастер (master), коммит (commit), слияние изменений (merge), rebase, реверт (revert), fast-forward merge, процедура git push-force. Рекомендуется ознакомиться и понять каждый из приведенных терминов для полного понимания материала данной статьи.
Окружение
Production
В этом окружении работает разрабатываемая система, это целевое окружение для всех изменений, которые делают разработчики системы. Этим окружением пользуются реальные пользователи в процессе эксплуатации системы.
Существуют также так называемые production-like окружения, особенность которых в том, что конфигурация выделенных для окружения ресурсов (инфраструктура, конфигурация железа, версии софта, операционная система, сетевая организация), а также внешние сервисы — по максимуму насколько возможно совпадают с production окружением. Есть нюансы, из-за которых различия могут быть, но в каждом конкретном production-like окружении определяются свои допустимые риски связанные с различием с production окружением. Примеры таких окружений: staging и testing — рассмотрены далее.
Staging
Staging — это production-like окружение, в котором происходит финальная проверка перед выкатом на production. Staging даёт возможность полнее протестировать бизнес-функции приложения и обычно это то место, куда идут менеджеры, тестировщики, заказчики.
В случае, если приложение связано с какими либо внешними сервисами, staging — это единственное окружение помимо production, где можно проверить как новая версия работает в связке с реальными версиями внешних систем.
Testing
Testing — это production-like окружение, цель которого: выявить возникшие у приложения проблемы на production окружении. В данном окружении могут работать “долгие” автоматизированные тесты приложения, которые проверяют множество аспектов его работы. Чем больше различий между testing и production, тем больше рисков получить нерабочее приложение после очередного выката, поэтому рекомендуется максимально повторять production окружение (одинаковый софт, версии, библиотеки, IP-адреса и порты, железо и т.д.).
Review
Динамический (временный) контур, используемый разработчиками при разработке для оценки работоспособности написанного кода, первичной оценки работоспособности приложения и проведения таких экспериментов, которые нельзя делать на production-like окружениях.
Особенность review-окружений в том, что их можно создавать динамически в любых количествах (в разумных пределах, насколько позволяют ресурсы). Как правило, создание и удаление такого окружения инициируется разработчиком через CI/CD систему, также такое окружение может быть удалено автоматически после отсутствия активности в течение некоторого времени.
Релизы и CI/CD
Релиз — это оформленная версия приложения с какими-то изменениями с момента предыдущего релиза.
В каскадном (или водопадном) подходе к разработке софта релизы обычно делаются редко и содержат множество изменений. Доставка таких релизов в окружения также происходит редко, но в этот момент все усилия команды тратятся на слежение за новой версией, исправление ошибок, проверку что всё прошло успешно. Обычно это отдельный и очень ответственный этап разработки, и пока он длится, новых изменений никто не делает (а если и делает, то пока нет возможности доставить их пользователю до нового релиза). Новая версия ещё не была проверена в реальной жизни, или была проверена тестами, но этого всё равно может быть недостаточно — с этим связаны большие риски, что новая версия приложения не заработает.
В CI/CD подходе релизы делаются часто, и релизы могут содержать мало изменений. Поощряется, чтобы разработчики разбивали новые фичи на такие куски, которые можно сразу обкатать на production-like или production окружениях. Более того, разработчики, которые прониклись таким подходом, сами хотят как можно быстрее пустить новый код в работу и получить обратную связь — после этого опираясь на проверенный код проще делаются новые изменения. До конца доделанным можно считать лишь тот код, который не только написан, но и задействован в production.
Важный момент в организации настоящего CI/CD процесса в том, чтобы изменения в коде быстро доносились до production-like окружений — будь то staging, testing или же сам production. Типичным антипаттерном при использовании CI/CD является единовременный выкат на production-like или production окружение множества накопившихся изменений, сделанных ранее в проекте. Такое может происходить из-за неправильной организации управления проектом, в которой разработчикам не позволяется выкатывать на production-like окружения без каких-то лишних согласований (естественно проверку кода автоматическими тестами никто не отменял). Либо это может быть связано с тем, что CI/CD система технически построена на неудобных инструментах и примитивах, и со стороны кажется, что она похожа на CI/CD, а по факту неудобна для разработчиков (например, использование git-тегов с сообщением для каждого релиза).
Хорошая CI/CD система должна помогать разработчикам удобно доносить изменения до production в течение минут, иметь возможности отката, тестировать эти изменения на лету, но не ставить лишних барьеров и не требовать бессмысленных повторяющихся действий.
Также признаком хорошо построенной CI/CD системы является синхронизация состояния кода в git и выкаченного приложения на production-like и production окружениях. Например, приложение, выкаченное для staging соответствует последнему изменению сделанному в ветку staging (это лишь один из вариантов организации). Если код в ветке staging сломан, то и выкаченное приложение в окружении staging также сломано. Пользоваться приложением нельзя, но и пользоваться кодом из ветки staging тоже нельзя — ведь на нерабочем коде нельзя построить новых изменений. Поэтому мы держим код ветки staging (последний коммит в эту ветку) и приложение в синхронизированном состоянии, а не откатываем окружение staging на старый коммит. И поэтому в данной ситуации логично либо быстро фиксить проблему и выкатывать новое изменение в ветку с автоматическим выкатом на контур, либо делать revert внесённого изменения с автоматическим выкатом на контур — одно из двух.
В дальнейших разделах мы определим возможные варианты конфигураций workflow и насколько каждый из них соответствует подходам CI/CD.
Что такое pipeline и workflow
С помощью git пользователь вносит изменения в кодовую базу проекта. Каждый коммит в гит активирует так называемый pipeline со стороны CI/CD системы. Pipeline разбит на стадии, которые могут запускаться последовательно или параллельно.
Главное назначение pipeline — донести внесённое в гит изменение до некоторого окружения. В случае непрохождения какой-то стадии pipeline прерывается и пользователь тем самым получает обратную связь. Коммит, который успешно проходит по всем необходимым стадиям попадает на некоторый контур/окружение.
Бывают следующие основные типы стадий:
Pull request
Пользователь вносит изменения в кодовую базу путём создания коммитов в git и pull request-ов в CI/CD системе. Обычно pull request — это сущность, которая связывает коммит в git и pipeline (а также позволяет делать review, оставлять комментарии и пр.). В разных CI/CD системах pull request может называться по-разному (Merge Request в GitLab CI) или вообще отсутствовать (Jenkins).
Workflow
Pipeline-ы и стадии внутри pipeline-ов могут быть активированы как автоматически, так и вручную. Способы активации pipeline-ов, их устройство, связь с гит, требуемые действия со стороны пользователя — всё это будет определяться так называемым workflow. Возможно множество вариантов workflow для достижения одной и той же цели. Далее мы рассмотрим те варианты, которые можно реализовать с использованием werf.
Варианты ручного запуска pipeline
Ручной запуск pipeline предполагает:
Стадия тестирования
Для правильной организации CI/CD критично во время внесения изменений в кодовую базу проекта получать быструю обратную связь в автоматическом режиме с помощью тестов. Причём стадию тестирования можно разбить на 2 условных этапа: на первичном этапе тесты проходят быстро и покрывают большую часть функций, на вторичном этапе тесты могут работать долго и проверять больше аспектов приложение. Первичные тесты обычно запускаются автоматически и их прохождение является обязательным условием для допуска изменений к релизу.
Что читать дальше
Дальше рекомендуется ознакомиться с инструкцией по вашей CI/CD системе:
Если вы хотите узнать больше подробностей по методике составления workflow или для вашей CI/CD системы не нашлось инструкции, тогда можно ознакомится с дальнейшими разделами где определяются составляющие workflow и готовые конфигурации workflow. После этого вы будете готовы выбрать готовую конфигурацию или составить свою и реализовать её для вашей CI/CD системы с использованием werf.
Составляющие workflow для отдельных окружений
Далее рассмотрим различные варианты выката production и других окружений в связке с git. Каждый пункт определяет строительный блок, который можно использовать для работы с определённым окружением. Мы будем называть такой строительный блок блоком workflow. Из блоков workflow в дальнейшем можно собрать свой workflow или взять готовую конфигурацию (см. далее готовые конфигурации workflow).
Review окружения создаются и удаляются динамически по требованию разработчиков. С этим связаны особенности выката в эти окружения. В разделах, связанных с review, будет описано не только как создать review-окружение, но и как его удалить.
Выкат на production из master автоматически
Merge или коммит в ветку master вызывает pipeline выката непосредственно на production.
Состояние ветки в любой момент времени отражает состояние окружения. Поэтому данный вариант является соответствующим подходу true CI/CD.
Выкат на production из master по кнопке
Pipeline выката в production может быть запущен вручную только на коммите из ветки master. Запуск pipeline производится средствами CI/CD системы вручную: кнопка в CI/CD системе или вызов API.
Выкат на production из тега автоматически
Создание нового тега автоматически вызывает pipeline выката на production-окружение из коммита, связанного с этим тегом.
Выкат на production из тега по кнопке
Pipeline выката в production-окружение может быть вызван только на существующем теге в git. Запуск pipeline производится средствами CI/CD системы вручную: кнопка в CI/CD системе или вызов API.
Выкат на production из ветки автоматически
Merge или коммит в специальную ветку вызывает pipeline выката непосредственно на production (вариант похож на (master-автоматически)(#master-автоматически), но используется отдельная ветка).
Состояние специальной ветки в любой момент времени отражает состояние окружения. Поэтому данный вариант является соответствующим подходу true CI/CD.
Выкат на production из ветки по кнопке
Pipeline выката в production может быть запущен вручную только на коммите из специальной ветки. Запуск pipeline производится средствами CI/CD системы вручную: кнопка в CI/CD системе или вызов API.
Выкат на production-like из pull request по кнопке
Pipeline выката в production может быть запущен на любом коммите в pull request. Запуск pipeline производится средствами CI/CD системы вручную: кнопка в CI/CD системе или вызов API.
Выкат на staging из master автоматически
Merge или коммит в ветку master вызывает pipeline выката непосредственно на staging окружение.
Состояние ветки в любой момент времени отражает состояние окружения. Поэтому данный вариант является соответствующим подходу true CI/CD.
Выкат на staging из master по кнопке
Pipeline выката в staging может быть запущен вручную только на коммите из ветки master. Запуск pipeline производится средствами CI/CD системы вручную: кнопка в CI/CD системе или вызов API.
Выкат на production-like из ветки автоматически
Merge или коммит в специальную ветку вызывает pipeline выката непосредственно на production-like окружение (вариант похож на (master-автоматически)(#master-автоматически), но используется отдельная ветка). Для каждого конкретного production-like окружения, как то: staging или testing — используется отдельная ветка.
Состояние специальной ветки в любой момент времени отражает состояние окружения. Поэтому данный вариант является соответствующим подходу true CI/CD.
Выкат на production-like из ветки по кнопке
Pipeline выката в production-like окружение может быть запущен вручную только на коммите из специальной ветки. Запуск pipeline производится средствами CI/CD системы вручную: кнопка в CI/CD системе или вызов API.
Выкат на review из pull request автоматически
Создание pull request автоматически вызывает выкат в отдельное review окружение. Название этого окружения связано с именем ветки. Дальнейшие коммиты в ветку, связанную с pull request автоматически вызывают выкат в review окружение.
Выкат на review из ветки по шаблону автоматически
Создание pull request для ветки, подходящей под определённый паттерн автоматически вызывает выкат в отдельное review окружение. Название этого окружения связано с именем ветки. Дальнейшие коммиты в ветку, связанную с pull request автоматически вызывают выкат в review окружение.
Например, для паттерна review_* создание pull request для ветки review_myfeature1 вызовет автоматическое создание соответствующего review окружения.
Выкат на review из pull request по кнопке
Выкат на review из pull request автоматически после ручной активации
Review-окружение для pull request создаётся после его ручной активации средствами CI/CD системы. С этого момента любой коммит в ветку, связанную с pull request, вызывает автоматический выкат на review окружение. После работы с review его можно деактивировать вручную средствами CI/CD системы.
Сравнение составляющих блоков для построения workflow
Степень управляемости через git
| Откат через git | Ручной откат | |
|---|---|---|
| Выкат через git | Выкат на production из master автоматически; Выкат на production из тега автоматически; Выкат на production из ветки автоматически; Выкат на staging из master автоматически; Выкат на production-like из ветки автоматически; Выкат на review из pull request автоматически; Выкат на review из ветки по шаблону автоматически; Выкат на review из pull request автоматически после ручной активации (полуавтоматический); | Выкат на production из master автоматически; Выкат на production из тега автоматически; Выкат на production из ветки автоматически; Выкат на staging из master автоматически; Выкат на production-like из ветки автоматически; Выкат на review из pull request автоматически; Выкат на review из ветки по шаблону автоматически; Выкат на review из pull request автоматически после ручной активации (полуавтоматический); |
| Ручной выкат | Выкат на review из pull request автоматически после ручной активации (полуавтоматический); | Выкат на production из master по кнопке; Выкат на production из тега по кнопке; Выкат на production из ветки по кнопке; Выкат на production-like из pull request по кнопке; Выкат на review из pull request по кнопке; Выкат на review из pull request автоматически после ручной активации (полуавтоматический); |
Соответствие CI/CD
| True CI/CD | Рекомендовано для werf | |
|---|---|---|
| Выкат на production из master автоматически | да | да |
| Выкат на production из master по кнопке | нет | нет |
| Выкат на production из тега автоматически | нет | да |
| Выкат на production из тега по кнопке | нет | да |
| Выкат на production из ветки автоматически | да | нет |
| Выкат на production из ветки по кнопке | нет | нет |
| Выкат на production-like из pull request по кнопке | нет | да |
| Выкат на staging из master автоматически | да | да |
| Выкат на staging из master по кнопке | нет | нет |
| Выкат на production-like из ветки автоматически | да | нет |
| Выкат на production-like из ветки по кнопке | нет | нет |
| Выкат на review из pull request автоматически | да | нет |
| Выкат на review из ветки по шаблону автоматически | да | нет |
| Выкат на review из pull request по кнопке | нет | нет |
| Выкат на review из pull request автоматически после ручной активации | да | да |
Готовые конфигурации workflow
Мы предлагаем пользователю на выбор несколько готовых конфигураций workflow для проекта. Эти конфигурации составлены из приведенных выше блоков workflow. В документации эти готовые конфигурации могут называться также стратегиями workflow.
Конкретные конфиги по каждой из конфигураций можно найти в инструкциях по конкретной CI/CD системе. Например, Gitlab CI: ссылка, Github Actions: ссылка.
№1 Fast and Furious
Конфигурация рекомендована в качестве наиболее соответствующей канонам CI/CD, которую можно реализовать с помощью werf.
В данной конфигурации может быть произвольное число production-like окружений, как то: testing, staging, development, qa, и т.д.
| Окружение | Блок workflow |
|---|---|
| Production | Выкат на production из master автоматически + откат через revert |
| Staging / Testing / Development / QA | Выкат на production-like из pull request по кнопке |
| Review | Выкат на review из pull request автоматически после ручной активации |
№2 Push the button
| Окружение | Блок workflow |
|---|---|
| Production | Выкат на production из master по кнопке |
| Staging | Выкат на staging из master автоматически |
| Testing / Development / QA | Выкат на production-like из ветки автоматически |
| Review | Выкат на review из pull request по кнопке |
№3 Tag everything
Не все проекты сходу готовы к внедрению CI/CD. В таких проектах используется более классический метод создания релизов только после активной фазы разработки. Переход к CI/CD в таких проектах требует усилий по преодолению привычных вещей и переосмысления как от разработчиков, так и от devops. Поэтому для таких проектов мы предлагаем и классическую конфигурацию, которая также рекомендована для werf в случае невозможности использования fast & furious.
| Окружение | Блок workflow |
|---|---|
| Production | Выкат на production из тега автоматически |
| Staging | Выкат на staging из master автоматически или выкат на staging из master по кнопке |
| Review | Выкат на review из pull request автоматически после ручной активации |
№4 Branch, branch, branch
Управляем выкатом прямо через git с использованием веток и процедур git merge, rebase и push-force. Через создание определённых имен веток получаем автоматический выкат на review окружения.
Рекомендуем для тех, кто хочет управлять CI/CD полностью из git. Отметим, что подход также является соответствующим канонам CI/CD, как и fast & furious.



