Строковый тип
В программировании, строковый тип (англ. string «нить, вереница») — тип данных, значениями которого является произвольная последовательность (строка) символов алфавита. Каждая переменная такого типа (строковая переменная) может быть представлена фиксированным количеством байтов либо иметь произвольную длину.
Содержание
Представление в памяти
Некоторые языки программирования накладывают ограничения на максимальную длину строки, но в большинстве языков подобные ограничения отсутствуют. При использовании Unicode каждый символ строкового типа может требовать двух или даже четырёх байтов для своего представления.
Основные проблемы в машинном представлении строкового типа:
В представлении строк в памяти компьютера существует два принципиально разных подхода.
Представление массивом символов
В этом подходе строки представляются массивом символов; при этом размер массива хранится в отдельной (служебной) области. От названия языка Pascal, где этот метод был впервые реализован, данный метод получил название Pascal strings.
Слегка оптимизированным вариантом этого метода является т. н. формат c-addr u (от англ. character-aligned address + unsigned number ), применяемый в Форте. В отличие от Pascal strings, здесь размер массива хранится не совместно со строковыми данными, а является частью указателя на строку.
Преимущества
Недостатки
Метод «завершающего байта»
Второй метод заключается в использовании «завершающего байта». Одно из возможных значений символов алфавита (как правило, это символ с кодом 0) выбирается в качестве признака конца строки, и строка хранится как последовательность байтов от начала до конца. Есть системы, в которых в качестве признака конца строки используется не символ 0, а байт 0xFF (255) или код символа «$».
Метод имеет три названия — ASCIIZ (символы в кодировке ASCII с нулевым завершающим байтом), C-strings (наибольшее распространение метод получил именно в языке Си) и метод нуль-терминированных строк.
Преимущества
Недостатки
Использование обоих методов
В таких языках, как, например, Оберон, строка размещается в массиве символов определённой длины, причём её конец обозначается нулевым символом. По умолчанию, весь массив заполнен нулевыми символами. Такой способ позволяет объединить многие преимущества обоих подходов, а также избежать большинство их недостатков.
Реализация в языках программирования
Операции
Представление символов строки
До последнего времени один символ всегда кодировался одним байтом (8 двоичных битов; применялись также кодировки с 7 битами на символ), что позволяло представлять 256 (128 при семибитной кодировке) возможных значений. Однако для полноценного представления символов алфавитов нескольких языков (многоязыковых документов, типографских символов — несколько видов кавычек, тире, нескольких видов пробелов и для написания текстов на иероглифических языках — китайском, японском и корейском) 256 символов недостаточно. Для решения этой проблемы существует несколько методов:
Строковые типы данных
Строковые типы данных используются для значений, которые содержат символьные строки.
Строковый тип (string)
Строковый тип данных может содержать символы окончания строки, перевода каретки, табуляции и другие символы.
Декларация строковых данных в схеме выглядит следующим образом:
Соответствующий элемент в XML документе может выглядеть так:
Примечание: XML процессор не будет модифицировать значение элемента, если используется тип данных string.
Нормализованная строка (normalizedString)
Нормализованная строка normalizedString является производным от строкового типа данных.
Тип normalizedString также содержит символьные данные, однако XML процессор удалит символы переноса стоки, перевода каретки и символы табуляции.
В схеме элемент с таким типом данных декларируется следующим образом:
В XML документе такой элемент будет выглядеть так:
При этом в данном примере XML процессор заменит все символы табуляции пробелами.
Символьный тип данных (token)
Символьный тип token также является производным от строкового типа данных.
Значения символьного типа также содержат символьные данные, однако XML процессор удалит символы переноса стоки, перевода каретки, табуляции, начальные и конечные пробелы, а также множественные пробелы.
В схеме элемент с таким типом данных декларируется следующим образом:
В XML документе такой элемент будет выглядеть так:
При этом в данном примере XML процессор удалит все символы табуляции.
Строковые типы данных
Все приведенные в следующей таблице типы являются производными от строкового типа данных (за исключением самого строкового типа string).
| Название | Описание |
|---|---|
| ENTITIES | |
| ENTITY | |
| ID | Строка, представляющая идентификационный атрибут (используется только с атрибутами схемы) |
| IDREF | Строка, представляющая IDREF атрибут (используется только с атрибутами схемы) |
| IDREFS | |
| language | Строка, содержащая корректный идентификатор языка |
| Name | Строка, содержащая корректное XML имя |
| NCName | |
| NMTOKEN | Строка, представляющая NMTOKEN атрибут (используется только с атрибутами схемы) |
| NMTOKENS | |
| normalizedString | Строка, которая не содержит символы перевода строки, переноса каретки или табуляции |
| QName | |
| string | Любая строка |
| token | Строка, которая не содержит символы перевода строки, переноса каретки, табуляции, начального и конечного пробелов или множественные пробелы |
Ограничения по строковым типам данных
Со строковыми типами данных можно использовать следующие ограничения:
Строковые значения
Строкой (string) называется последовательность символов, которая рассматривается как единое целое, но при этом обеспечивает доступ к отдельным символам. Примеры строк:
Обратите внимание: в РНР не поддерживается символьный тип данных. Строковый тип может рассматриваться как единое представление для последовательностей, состоящих из одного или нескольких символов.
Строки делятся на две категории в зависимости от типа ограничителя — они могут ограничиваться парой кавычек (» «) или апострофов (‘ ‘). Между этими категориями существуют два принципиальных различия. Во-первых, имена переменных в строках, заключенных в кавычки, заменяются соответствующими значениями, а строки в апострофах интерпретируются буквально, даже если в них присутствуют имена переменных,
Два следующих объявления дают одинаковый результат:
Однако результаты следующих объявлений сильно различаются:
My favorite food is meatloaf.
Таблица.1.Служебные символы в строках
| Последовательность | Смысл |
| \n | Новая строка |
| \r | Возврат курсора |
| \t | Горизонтальная табуляция |
| \\ | Обратная косая черта |
| \$ | Знак доллара |
| \» | Кавычка |
| \2 | Восьмеричная запись числа (в виде регулярного выражения) |
| \x[0-9A-Fa-f] | Шестнадцатиричная запись числа (в виде регулярного выражения) |
Второе принципиальное различие заключается в том, что в строках, заключенных в кавычки, распознаются все существующие служебные символы, а в строках, заключенных в апострофы, — только служебные символы «\\» и «\». Следующий пример наглядно демонстрирует различия между присваиванием строк, заключенных в кавычки и апострофы:
Если вывести обе строки в браузере, окажется, что строка в кавычках содержит внутренние символы новой строки, а в строке в апострофах последовательность \n выводится как обычные символы. Хотя многие служебные символы в браузерах несущественны, при форматировании для других условий они играют очень важную роль. Помните об этом, выбирая между кавычками и апострофами, и вам удастся избежать многих неожиданностей.
Синтаксис встроенной документации
Второй вариант синтаксиса ограничения строк, представленный в HTML4, называется встроенной документацией (here doc). В этом варианте синтаксиса строка начинается с символов
Обращение к отдельным символам строк
К отдельным символам строки можно обращаться как к элементам массива с последовательной нумерацией (см. следующий раздел). Пример:
Основы работы со строками в Visual Basic
Тип данных String представляет последовательность символов (каждый из которых, в свою очередь, представляет экземпляр типа данных Char ). В этом разделе рассматриваются основные понятия строк в Visual Basic.
Строковые переменные
Экземпляру строки можно назначить литеральное значение, которое представляет ряд символов. Пример:
Переменная String также может принимать любое выражение, результатом которого является строка. Ниже приведены примеры.
Этот код вызывает ошибку, так как компилятор завершает строку после второй пары кавычек, а остаток строки интерпретируется как код. чтобы решить эту проблему, Visual Basic интерпретирует две кавычки в строковом литерале как одну кавычку в строке. В следующем примере показан правильный способ указания кавычек в строке:
В предыдущем примере два символа кавычек перед словом Look становятся одним символом кавычек в строке. Три символа кавычек в конце строки представляют один символ кавычек в строке и конечный символ строки.
Строковые литералы могут содержать несколько строк:
Результирующая строка содержит последовательности новых строк, используемых в строковом литерале (vbcr, vbcrlf и т. д.). Вам больше не требуется использовать старое решение:
Символы в строках
Неизменность строк
Строка является неизменяемой. Это означает, что ее значение нельзя изменить после ее создания. Однако это не мешает назначить строковой переменной более одного значения. Рассмотрим следующий пример.
Здесь строковая переменная создается, получает значение, которое затем изменяется.
Строковый тип данных
Урок 34. Информатика 10 класс (ФГОС)

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока «Строковый тип данных»
· Символьная строка и её описание на языке Pascal.
· Хранение строк в оперативной памяти компьютера.
· Операции функции и процедуры для обработки строк.
Строка – это последовательность символов. Количество символов в строке называется её длиной. Строковые значения в языке Паскаль записываются, как и символы, замкнутыми между апострофами.
Строковые переменные в языке Pascal имеют тип string. Рассмотрим, как объявить такую переменную. Вначале как у любой другой переменной указывается имя, после которого следует двоеточие. После него, через пробел, следует тип переменной – string. Через пробел после этого слова, в индексных скобках, следует число – максимальная длина строки. Максимальную длину строки указывать необязательно, в этом случае она по умолчанию указывается максимально возможной, то есть равной 255 символам.
Описание строки в разделе описания переменных
Рассмотрим, как строка хранится в оперативной памяти компьютера. Строку можно разделить на 2 части. Вторая часть представляет собой массив символьных величин. Эти величины имеют индексы – порядковые номера символов в строке. Первая часть строки – это её нулевой байт. В нём хранится длина строки, то есть количество занятых символьных позиций. Таким образом, чтобы узнать какое количество оперативной памяти занимает строка, нужно её максимальную длину, указанную в описании, умножить на 2 байта – размерность одного символа в кодовой таблице Unicode-16, после чего к полученному числу прибавить 1 байт, в котором храниться длина строки. Таким образом строка, максимальная длина которой не указана при описании будет занимать 511 байт оперативной памяти.
V = × 2 байта + 1 байт
Расчёт оперативной памяти, необходимой для хранения строки
Как и к элементам массива, к символам строки можно обращаться через их индексы, которые могут быть заданы целочисленными переменными, значениями или выражениями, которые не должны превышать значение максимальной длины строки.
Обращение к символу строки
Строковые и символьные величины совместимы между собой, то есть они могут употребляться в одном выражении.
Рассмотрим операции, применяемые для обработки строк. Прежде всего это сцепление строк или конкатенация. Это бинарная операция. Она обозначается знаком арифметического сложения. Её результатом является строка, которая состоит из исходных, записанных слева направо. Длина результирующей строки не должна превышать 255 символов.
Также для строк реализованы все операции отношения. Как и для числовых величин, их результатом будет логическая величина, то есть «Истина» или «Ложь». Строки при этом сравниваются последовательно, от первого символа к последнему, до первого отличного символа. Большей будет та строка, в которой первый отличный символ будет иметь больший код в кодовой таблице.

Задача: Написать программу, которая формирует строку, состоящую из n звёздочек. n вводится с клавиатуры. Это положительное число, не превышающее 255.
Напишем логические скобки. Тело программы будет начинаться с оператора writeln, выводящего на экран сообщение о том, что это программа, формирующая строку из n звёздочек. Дальше будет следовать оператор write, выводящий запрос на ввод n и оператор read, для считывания его значения. Дальше присвоим строке s значение пустой строки, которое задаётся двумя апострофами, между которыми нет символов. Дальше напишем цикл для заполнения строки звёздочками. Это будет цикл для i, изменяющегося от 1 до n. В нём будет оператор, присваивающий строке s склейку её текущего значения и символа звёздочка. После цикла будет следовать оператор write, выводящий на экран сообщение о том, что получившаяся строка равна значению s.
writeln (‘Программа, формирующая строку из n звёздочек.’);
write (‘Получившаяся строка: ‘, s);
Исходный код программы
Запустим программу на выполнение и зададим n = 7. Программа вывела строку из 7 звёздочек.

Программа работает правильно. Задача решена.
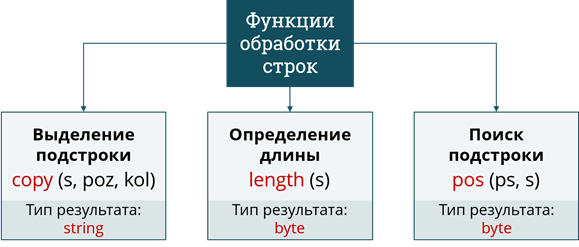
Рассмотрим функции, применяемые для обработки строк. Первая из них – выделение подстроки. Она записывается служебным словом copy и принимает на вход 3 аргумента: исходную строку и 2 числа – порядковый номер символа с которого начинается выделяемая подстрока и количество символов, которое содержит подстрока. Она возвращает строковое значение заданной подстроки.
Следующая функция – определение текущей длины строки. Она записывается служебным словом length, после которого в скобках следует единственный аргумент – строка, длину которой нужно определить. Функция возвращает целое число – количество символов в заданной строке.
Последняя функция, применяемая для обработки строк – поиск первого вхождения подстроки в строку. Она записывается служебным словом pos, сокращённо от английского «position». После этого слова, через пробел, в скобках следует 2 строковых аргумента: искомая подстрока и строка в которой производится поиск. Эта функция возвращает одно целое число – номер символа, с которого начинается искомая подстрока в строке.
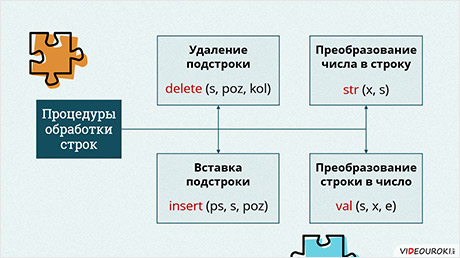
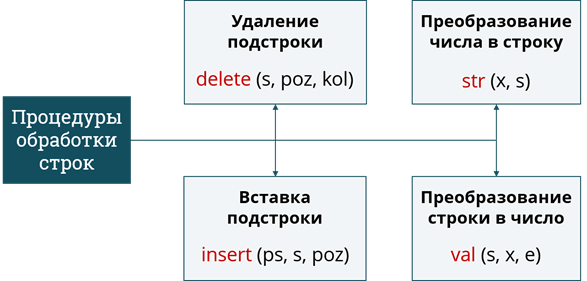
Также для обработки строк используется несколько процедур. Первая – это удаление подстроки из строки. Она записывается служебным словом delete, после которого в скобках указывается 3 параметра: исходная строка, позиция с которой начинается удаляемая подстрока и количество символов в удаляемой подстроке. По окончании работы процедуры длина исходной строки уменьшится на количество символов в подстроке.
Также есть и противоположная процедура вставки подстроки в строку. Она записывается служебным словом insert. После него, через пробел, в скобках следует 3 параметра: вставляемая подстрока, исходная строка и целое число – позиция, начиная с которой в исходной строке будет следовать вставляемая подстрока. По окончании работы процедуры длина исходной строки увеличится на количество символов в подстроке, итоговая длина должна быть не больше указанной в описании исходной строки.
Также при работе со строками бывают полезны ещё 2 процедуры. Первая из них преобразует число в строку. Она записывается служебным словом str, после которого, через пробел, в скобках указываются 2 параметра: целое или вещественное число и строка, в которой по окончании работы процедуры будет сохранено строковое представление числа.
Не менее полезна и обратная процедура – преобразование строки в число. Она записывается служебным словом val, сокращённо от английского «value». После него, через пробел, в скобках следует 3 параметра: преобразуемая строка, числовая переменная для хранения полученного числа и ещё одна целочисленная переменная, в которую будет возвращён номер некорректного символа в исходной строке, если её невозможно преобразовать в число или 0 в случае успешного преобразования.
Задача: Заданная строка состоит из слов и целых чисел, разделённых одиночными пробелами. Сохранить отдельно слова и числа, которые встречаются в строке и вывести их на экран. Количество слов и чисел не превышает 50, длина каждого слова – не более 20 символов, а каждое число – не больше 2 000 000 000.
Для решения задачи мы будем выделять часть строки до первого пробела, после чего определять слово это или число, и сохранять в один из двух соответствующих массивов. После чего мы будем удалять выделенную подстроку строку из исходной строки вместе с пробелом. После этого мы повторим указанные действия. Так будет продолжаться пока в строке не останется символов.
Напишем программу для решения задачи. Назовём её slova_i_chisla. Для работы программы нам потребуются 2 строки: исходная строка, которую так и назовём – stroka, а также для хранения подстроки – строка s из 20 символов. Так же нам потребуется 2 массива из 50 элементов для хранения слов и чисел. Первый массив назовём sloava. Он будет состоять из строк по 20 символов. Второй массив назовём chisla, его элементами будут целые числа, принадлежащие к типу integer. Также понадобится несколько числовых переменных: для количества слов – переменная kol_slov, для количества чисел – kol_chisel, для позиции первого пробела – space и номер текущего элемента массива – i. По условию задачи они будут принадлежать к целочисленному типу byte. Ещё нам понадобятся две переменные для перевода подстроки в число. Назовём их соответственно chislo и code и укажем принадлежащими к целочисленному типу integer.
Напишем логические скобки. Тело программы будет начинаться с оператора writeln, выводящего на экран сообщение о том, что это программа выделения слов и чисел из строки, и запрос на ввод строки. Дальше будет следовать оператор readln, считывающий значение исходной строки. Присвоим переменным kol_slov и kol_chisel значения 0, так как мы ещё не выделили ни одного слова или числа. Дальше запишем цикл для выделения слов и чисел из строки. Это будет цикл с предусловие. Условием продолжения его работы будет то, что в исходная строка не пуста. В логических скобках запишем тело цикла. В начале найдём пробел в исходной строке. Для этого переменной space присвоим значение функции pos, которая будет искать первый пробел в исходной строке. Если пробела в строке не найдено, то в строке всего одно слово или число. Поэтому мы установим указатель пробела после него. Для этого присвоим переменной space значение равное сумме длины исходной строки – length (stroka) и 1. Дальше в строку s, с помощью функции Копи выделим первое слово или число из исходной строки. Нам нужна подстрока, начиная с первого символа до первого пробела, позиция которого хранится в переменной space, не включая сам пробел. Дальше с помощью процедуры val попробуем преобразовать строку s в число, если преобразование не удастся – номер ошибочного символа сохраним в переменной code. Дальше запишем условный оператор, который проверяет, удалось ли преобразование. Его условием будет: code = 0. Если это условие выполняется, то преобразование числа удалось, поэтому после слова then, в логических скобках, запишем операторы для сохранения числа. Это будут операторы увеличения kol_chisel на 1, и сохранения числа в массиве числа с индексом, равным kol_chisel. Если преобразование подстроки в число не удалось, значит это слово, поэтому после слова else, в логических скобках напишем операторы для сохранения подстроки s в массиве slova. Это будут операторы увеличения kol_slov на 1 и сохранения строки s в массиве slova с индексом равным kol_clov. Дальше нам нужно удалить выделенную подстроку из исходной строки для этого вызовем процедуру delete, которая будет удалять из исходной строки подстроку, начиная с первой позиции до первого пробела space, включая пробел. На этом описание цикла выделения слов и чисел завершено. После окончания работы нам будет достаточно вывести на экран элементы массивов слов и чисел, через пробел, с соответствующими поясняющими сообщениями.
slova: array [1..50] of string [20];
chisla: array [1..50] of integer;
kol_slov, kol_chisel, space, i: byte;
chislo, code: integer;
writeln (‘Программа, выделяющая слова и числа из строки. Введите строку.’);



