вертикальный масштаб
Смотреть что такое «вертикальный масштаб» в других словарях:
Вертикальный масштаб — (a. vertical scale of height; н. Vertikalmaβstab; ф. echelle altimetrique; и. escala altimetrica) масштаб для изображения абс. высот точек на топографич. профилях или вертикальных разрезах земной коры. Oбычно B. м. крупнее горизонтального … Геологическая энциклопедия
вертикальный масштаб, масштаб высот — — [http://slovarionline.ru/anglo russkiy slovar neftegazovoy promyishlennosti/] Тематики нефтегазовая промышленность EN scale of height … Справочник технического переводчика
вертикальный масштаб, масштаб глубины — — [http://slovarionline.ru/anglo russkiy slovar neftegazovoy promyishlennosti/] Тематики нефтегазовая промышленность EN vertical scale … Справочник технического переводчика
КАРТА — уменьшенное обобщенное изображение поверхности Земли (или ее части) на плоскости. Человек создавал карты с древнейших времен, пытаясь наглядно представить взаимное расположение различных участков суши и морей. Собрание карт, обычно переплетенных… … Энциклопедия Кольера
Геологический разрез — геологический профиль, вертикальное сечение земной коры от её поверхности в глубину. Г. р. составляются по данным геологических наблюдений, по геологическим картам, материалам горных выработок, буровых скважин, геофизических исследований… … Большая советская энциклопедия
легенда к географическим картам — НАСЕЛЕННЫЕ ПУНКТЫ :: более 1 млн. жителей :: от 250 тыс. до 1 млн. жителей :: от 100 тыс. до 250 тыс. жителей :: менее 100 тыс. жителей Прописными буквами выделены столицы. ПУТИ СООБЩЕНИЯ :: Железные дороги … Географическая энциклопедия
Карты географические — (истор.) Первоначальное понятие о К. можно встретить даже у дикарей, особенно живущих по берегам и о вам и имеющих более или менее ясное представление об окружающих их территорию местностях. Путешественники, расспрашивавшие эскимосов С. Америки и … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
История картографии — Картография (от др. греч. χάρτης «хартия, лист папируса» и γράφω «пишу»), или наука об исследовании, моделировании и отображении пространственного расположения, сочетания и взаимосвязи объектов и явлений природы и общества, является… … Википедия
ПРОФИЛЬ УТРИРОВАННЫЙ — применяется при проектировании вторых путей и представляет собой особый вид продольного профиля жел. дор. линии. Горизонтальный масштаб П. у. принимается тот же, что и для нормального подробного продольного профиля, т. е. 100 м в 1 см (1 : 10… … Технический железнодорожный словарь
Картографическое произведение — произведение, главной частью которого является картографическое изображение. Библиогр. описание К. п. регламентируется ГОСТ 7.18 79. Схема такова (полужирным выделены обязательные элементы): Заголовок записи. Осн. заглавие: Сведения, относящиеся… … Издательский словарь-справочник
Вертикальный масштаб
Смотреть что такое «Вертикальный масштаб» в других словарях:
вертикальный масштаб — Отношение длины вертикального отрезка на трехмерном изображении к длине соответствующего вертикального отрезка в натуре … Словарь по географии
вертикальный масштаб, масштаб высот — — [http://slovarionline.ru/anglo russkiy slovar neftegazovoy promyishlennosti/] Тематики нефтегазовая промышленность EN scale of height … Справочник технического переводчика
вертикальный масштаб, масштаб глубины — — [http://slovarionline.ru/anglo russkiy slovar neftegazovoy promyishlennosti/] Тематики нефтегазовая промышленность EN vertical scale … Справочник технического переводчика
КАРТА — уменьшенное обобщенное изображение поверхности Земли (или ее части) на плоскости. Человек создавал карты с древнейших времен, пытаясь наглядно представить взаимное расположение различных участков суши и морей. Собрание карт, обычно переплетенных… … Энциклопедия Кольера
Геологический разрез — геологический профиль, вертикальное сечение земной коры от её поверхности в глубину. Г. р. составляются по данным геологических наблюдений, по геологическим картам, материалам горных выработок, буровых скважин, геофизических исследований… … Большая советская энциклопедия
легенда к географическим картам — НАСЕЛЕННЫЕ ПУНКТЫ :: более 1 млн. жителей :: от 250 тыс. до 1 млн. жителей :: от 100 тыс. до 250 тыс. жителей :: менее 100 тыс. жителей Прописными буквами выделены столицы. ПУТИ СООБЩЕНИЯ :: Железные дороги … Географическая энциклопедия
Карты географические — (истор.) Первоначальное понятие о К. можно встретить даже у дикарей, особенно живущих по берегам и о вам и имеющих более или менее ясное представление об окружающих их территорию местностях. Путешественники, расспрашивавшие эскимосов С. Америки и … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
История картографии — Картография (от др. греч. χάρτης «хартия, лист папируса» и γράφω «пишу»), или наука об исследовании, моделировании и отображении пространственного расположения, сочетания и взаимосвязи объектов и явлений природы и общества, является… … Википедия
ПРОФИЛЬ УТРИРОВАННЫЙ — применяется при проектировании вторых путей и представляет собой особый вид продольного профиля жел. дор. линии. Горизонтальный масштаб П. у. принимается тот же, что и для нормального подробного продольного профиля, т. е. 100 м в 1 см (1 : 10… … Технический железнодорожный словарь
Картографическое произведение — произведение, главной частью которого является картографическое изображение. Библиогр. описание К. п. регламентируется ГОСТ 7.18 79. Схема такова (полужирным выделены обязательные элементы): Заголовок записи. Осн. заглавие: Сведения, относящиеся… … Издательский словарь-справочник
Вертикальное и горизонтальное масштабирование, scaling для web
Для примера можно рассмотреть сервера баз данных. Для больших приложений это всегда самый нагруженный компонент системы.
Возможности для масштабирования для серверов баз данных определяются применяемыми программными решениями: чаще всего это реляционные базы данных (MySQL, Postgresql) или NoSQL (MongoDB, Cassandra и др).
Горизонтальное масштабирование для серверов баз данных при больших нагрузках значительно дешевле
Веб-проект обычно начинают на одном сервере, ресурсы которого при росте заканчиваются. В такой ситуации возможны 2 варианта:
MySQL является самой популярной RDBMS и, как и любая из них, требует для работы под нагрузкой много серверных ресурсов. Масштабирование возможно, в основном, вверх. Есть шардинг (для его настройки требуется вносить изменения в код) и репликация, которая может быть сложной в поддержке.
Вертикальное масштабирование 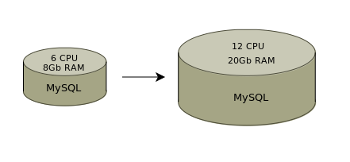
NoSQL масштабируется легко и второй вариант с, например, MongoDB будет значительно выгоднее материально, при этом не потребует трудозатратных настроек и поддержки получившегося решения. Шардинг осуществляется автоматически.
Таким образом с MySQL нужен будет сервер с большим количеством CPU и оперативной памяти, такие сервера имеют значительную стоимость.
Горизонтальное масштабирование
С MongoDB можно добавить еще один средний сервер и полученное решение будет стабильно работать давая дополнительно отказоустойчивость. 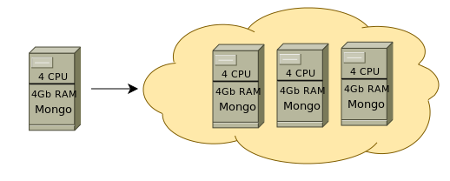
Scale-out или горизонтальное масштабирование является закономерным этапом развития инфраструктуры. Любой сервер имеет ограничения и когда они достигнуты или когда стоимость более мощного сервера оказывается неоправданно высокой добавляются новые машины. Нагрузка распределяется между ними. Также это дает отказоустойчивость.
Добавлять средние сервера и настраивать кластеры нужно начинать когда возможности для увеличения ресурсов одной машины исчерпаны или когда приобретение сервера мощнее оказывается невыгодно
Приведенный пример с реляционными базами данных и NoSQL является ситуацией, которая имеет место чаще всего. Масштабируются также фронтэнд и бэкенд сервера.
Чертежик
Метки


Чтение сборочного чертежа. Вертикальный и горизонтальный масштабы
Чтение сборочного чертежа не осуществимо без знаний что такое вертикальный и горизонтальный масштабы.
При выполнении студентом работы по чтению сборочного чертежа придерживаются следующей последовательности:
1.) По данному сборочному чертежу необходимо определить горизонтальный масштаб. Для этого необходимо к имеющимся размерам на сборочном чертеже приложить линейку горизонтально и посмотреть какова его длина, затем рассчитываем : Мгор=125:100=1,25, т.е. масштаб 1:1,25 (см. рис. 2)
 Рисунок 2 — Чтение сборочного чертежа. Определение горизонтального масштаба
Рисунок 2 — Чтение сборочного чертежа. Определение горизонтального масштаба
2.) определим вертикальный масштаб: имеющуюся длину на чертеже делим длину, отмеренное по линейке. Мверт=175:142=1,233, т.е. масштаб 1:1,233 (см. рис. 3)
 Рисунок 3 — Чтение сборочного чертежа. Определение вертикального масштаба
Рисунок 3 — Чтение сборочного чертежа. Определение вертикального масштаба
Пример: применим масштабы для детали №5
Допустим, необходимо начертить эскиз или рабочий чертеж детали под номером №5, то измеряем линейкой одну из горизонтальных длин и умножаем на горизонтальный масштаб, т.е. 40 х 1,25=50 мм. (см. рис. 4)
 Рисунок 4 — Горизонтальный масштаб
Рисунок 4 — Горизонтальный масштаб
Ширина по большой стороне детали равна 50 мм, таким образом определяются остальные горизонтальные длины детали.Определим одну из вертикальных длин. Измеряем линейкой деталь №5 по вертикали и умножаем на вертикальный масштаб, т.е. 21 х 1,233= 26 мм. (см. рис. 5)
 Рисунок 5 — Вертикальный масштаб
Рисунок 5 — Вертикальный масштаб
По такому принципу определяются и другие вертикальные длины детали.
Вертикальное автомасштабирование pod’ов в Kubernetes: полное руководство
Прим перев.: месяц назад Povilas Versockas, CNCF Ambassador и software engineer из Литвы, написал очень подробную статью о том, как работает и как использовать VPA в Kubernetes. Рады поделиться её переводом для русскоязычной аудитории!
Это полное руководство по вертикальному автомасштабированию pod’ов (Vertical Pod Autoscaling, VPA) в Kubernetes. Вот его краткое содержание:
Модель ресурсных требований Kubernetes;
Что такое вертикальное автомасштабирование pod’ов?
Работа с рекомендациями;
Когда использовать VPA?
Реальные примеры использования;
Модель рекомендаций VPA;
 Схема работы Kubernetes VPA от Banzai Cloud
Схема работы Kubernetes VPA от Banzai Cloud
Что ж, давайте приступим.
Зачем нам VPA?
При развертывании приложения в Kubernetes необходимо указывать его ресурсные запросы. Обычно инженеры начинают с некоторого случайного числа, взятого с потолка. Дальнейшая работа над приложениями и их деплой в кластер будут приводить к росту этих «взятых с потолка» заявок на ресурсы. И разница между заявленным и реальным потреблением ресурсов будет только расти.
Дело в том, что разработчикам довольно тяжело угадать правильный объем ресурсов. Им сложно оценить, сколько требуется приложению для оптимальной работы, установить правильную комбинацию CPU-мощностей, памяти и числа параллельно работающих реплик.
Кроме того, со временем модель использования приложения может меняться. Некоторым приложениям потребуется больше CPU и памяти. У других, менее популярных, требования к ресурсам, наоборот, снизятся.
С недостатком заявленных ресурсов обычно разбираются DevOps- или SRE-инженеры при поступлении соответствующих оповещений. SRE-инженеры видят, что приложение отбрасывает запросы конечных пользователей из-за «убийств» pod’ов, вызванных ошибкой Out-of-Memory, или оно начинает медленно работать из-за троттлинга процессора.
С другой стороны, избыток заявленных ресурсов не приводит к проблемам сразу, но вносит свой вклад в масштабный перерасход ресурсов. В результате команда по обслуживанию инфраструктуры/платформы вынуждена добавлять новые K8s-узлы, хотя реальная потребность в ресурсах невелика.
Решением этих проблем и занимается автомасштабирование. Горизонтальное масштабирование определяет оптимальное число реплик для приложения. Например, у вас может быть завышено количество pod’ов, что приводит к ненужному расходованию ресурсов.
В свою очередь, вертикальное масштабирование определяет оптимальные требования к CPU и памяти. В этой статье пойдет речь исключительно о вертикальном автомасштабировании pod’ов.
Но сначала давайте поговорим о модели ресурсных требований Kubernetes.
Модель ресурсных требований Kubernetes
Kubernetes требует от пользователей указывать заявки на ресурсы с помощью resource requests (запросов на ресурсы) и resource limits (лимитов на ресурсы). Давайте начнем с запросов:
Запросы на ресурсы резервируют некоторое количество ресурсов за приложением. Можно определять запросы для контейнеров в pod’е. Планировщик использует эту информацию, чтобы определить, куда разместить pod. Запросы можно представить как некоторый минимальный объем ресурсов, который требуется pod’у для нормальной работы.
Тут важно отметить, что приложение может задействовать больше ресурсов, если узел располагает свободными мощностями. А максимальный объем ресурсов, которыми может воспользоваться контейнер, устанавливается в лимитах. Если потребление памяти окажется больше указанного предела, pod будет убит. Если контейнер использует больше процессорной мощности, чем позволяет лимит, начинается троттлинг.
Лимиты фактически выступают этаким предохранительным клапаном. Они препятствуют потреблению приложением неограниченного объема памяти, если в нем имеется ее утечка. Точно так же они спасают вас от приложений, стремящихся «захватить» процессор целиком. Представьте, что кто-то развернул биткоин-майнеры: это вызовет процессорный «голод» для всех остальных приложений в кластере.
Важно, что если на узле нет свободных ресурсов, вы не сможете их получить. Таким образом, гарантия для запрашиваемых ресурсов обеспечивается только в случае их фактического наличия.
Кроме того, если вы не определите запросы, Kubernetes автоматически приравняет их к лимитам pod’а.
Многие ограничиваются заданием запросов на ресурсы, и это распространенная ошибка. Пользователи надеются, что в этом случае приложение будет располагать неограниченными ресурсами и ему не придется иметь дело с нехваткой памяти или троттлингом. Однако Kubernetes этого не допустит. Поэтому обязательно задавайте как запросы на ресурсы (resource requests), так и лимиты (limits).
Более того, эту ресурсную модель можно расширить. Могут быть и другие вычислительные ресурсы, такие как эфемерное хранилище, GPU, huge pages в Linux.
В статье же мы ограничимся процессорными мощностями и памятью, поскольку на данный момент Vertical Pod Autoscaler работает только с ними. Тем, кто желает узнать больше, рекомендую обратиться к соответствующему разделу документации Kubernetes (Managing Resources for Containers).
Что такое вертикальное автомасштабирование pod’ов?
Как следует из названия, вертикальное автомасштабирование pod’ов (VPA) позволяет автоматически устанавливать запросы на ресурсы и лимиты для контейнеров. Решения принимаются на основе прошлых данных об использовании CPU и памяти.
Основная цель VPA — уменьшить потери ресурсов и минимизировать риск снижения производительности из-за троттлинга CPU или ошибок, вызванных «убийством» pod’ов из-за Out Of Memory.
Поддержкой VPA занимаются инженеры Google. Система называется Autopilot и основана на опыте создания соответствующей внутренней системы для оркестратора контейнеров Borg. Результаты Google от использования Autopilot в production следующие:
«На практике избыток ресурсов для заданий под управлением Autopilot составил всего 23% — по сравнению с 46% для заданий, управляемых вручную. Кроме того, Autopilot на порядок сократил количество заданий, пострадавших от OOM».
— «Autopilot: workload autoscaling at Google»
Дополнительную информацию можно почерпнуть из самой публикации (Autopilot: workload autoscaling at Google).
VPA вводит несколько Custom Resource Definitions (CRD) для управления поведением автоматических рекомендаций. Как правило, разработчикам требуется добавить объект VerticalPodAutoscaler в свои deployment’ы.
Давайте разберемся, как его использовать.
Как использовать VPA?
Ресурс VPA предоставляют массу возможностей для управления рекомендациями. Чтобы получить лучшее представление об использовании VPA, посмотрим на сам объект VerticalPodAutoscaler:
Поле updateMode позволяет выбрать режим работы контроллера. Есть несколько вариантов:
Off – VPA не будет автоматически изменять ресурсные требования. Autoscaler подсчитывает рекомендации и хранит их в поле status объекта VPA;
Initial – VPA устанавливает запросы на ресурсы только при создании pod’а и не меняет их потом;
Recreate – VPA устанавливает запросы на ресурсы при создании pod’ов и обновляет их для существующих pod’ов, «вытесняя» (evict) в случаях, когда запрашиваемые ресурсы значительно отличаются от новой рекомендации;
С помощью controlledResources можно выбрать ресурсы для рекомендаций. Пока поддерживаются только CPU и память. Если типы ресурсов не указаны, то VPA будет давать рекомендации как по использованию процессора, так и по использованию памяти.
Объект VPA можно упростить, используя режим Auto и вычисляя рекомендации для CPU и памяти. А именно:
Теперь давайте посмотрим на рекомендации, которые VPA записывает в поле status соответствующего CRD.
Работа с рекомендациями
Просмотреть их можно с помощью:
kubectl describe vpa NAME
Давайте проанализируем пример отчета о состоянии:
Как видно, для контейнера prometheus предлагаются четыре различные оценки. При этом оценки объема памяти приводятся в байтах. Оценки CPU — в миллиядрах (m, millicores). Давайте разберемся, что означают эти оценки:
Lower bound (нижняя граница) — минимальная оценка для контейнера. Это значение не гарантирует, что приложение сможет стабильно работать. Такие минимальные запросы на CPU и память, скорее всего, окажут значительное влияние на производительность и доступность.
Upper bound (верхняя граница) — это максимальный рекомендованный объем ресурсов для контейнера. Запросы выше этих значений, скорее всего, будут приводить к тому, что ресурсы будут расходоваться впустую.
Оценку Target (цель) мы будем использовать для задания запросов на ресурсы.
Uncapped target (неограниченная цель) — это целевая оценка, которая получилась бы, если бы ограничения minAllowed и maxAllowed не были заданы.
Зачем нам четыре оценки? Vertical Pod Autoscaler использует Lower и Upper bound для вытеснения (eviction) pod’ов. Если текущий resource request ниже, чем lower bound, или выше, чем upper bound, и происходит 10%-ное изменение ресурсных запросов по сравнению с target-оценкой, то может произойти вытеснение.
Давайте разберемся, в каких случаях следует использовать Vertical Pod Autoscaler.
Когда использовать VPA?
Во-первых, можно добавить VPA к базам данных и stateful-нагрузкам при их запуске в Kubernetes. Как правило, stateful-нагрузки тяжелее поддаются горизонтальному масштабированию, поэтому автоматический способ, позволяющий отмасштабировать потребляемые ресурсы или точно оценить потребность в них, помогает решить многие проблемы с недостатком мощностей. Если база данных не настроена как высокодоступная или не готова к перерывам в работе, можно включить режимы Initial или Off. В этом режиме VPA не будет вытеснять pod’ы и ограничится рекомендациями запросов или их обновлением при перевыкате приложения.
Важно знать, что на данный момент VPA имеет некоторые ограничения, из-за которых его не всегда хорошо использовать.
Ограничения VPA
Прежде всего, не используйте VPA с рабочими нагрузками на базе JVM. Дело в том, что JVM не позволяет установить объем фактически используемой памяти, поэтому рекомендации могут сильно отклоняться от адекватных значений.
Также не стоит использовать VPA совместно с горизонтальным автомасштабированием (HPA), основанном на тех же метриках (CPU или памяти). В то же время два этих типа можно применять совместно, если HPA работает с кастомными метриками.
При работе в режиме RequestsAndLimits устанавливайте первичные лимиты для CPU таким образом, чтобы они многократно превышали request’ы. Связано это с известной проблемой Kubernetes/ядра Linux, которая в некоторых случаях может приводить к излишнему троттлингу (ситуация подробно разобрана в этой статье — прим. перев.). Многие пользователи Kubernetes либо полностью отключают троттлинг, либо устанавливают огромные лимиты CPU, чтобы обойти проблему. Как правило, это не приводит к плохим последствиям, поскольку использование CPU на узлах кластера обычно невелико.
Теперь давайте рассмотрим несколько примеров из реальной жизни.
Реальные примеры использования
Кластер MongoDB
Давайте начнем с кластера MongoDB, состоящего из трех реплик. Первоначальные требования StatefulSet’а к ресурсам таковы:
Pod Disruption Budget допускает отключение только одной реплики.
Далее мы разворачиваем StatefulSet без Vertical Pod Autoscaling и даем ему поработать некоторое время.
На этом графике показано использование памяти кластером MongoDB. Каждая из линий соответствует отдельной реплике. Видно, что фактическое использование памяти для двух реплик близко к 3 Гб, а для одной — около 1,5 Гб.
Спустя некоторое время мы включаем автоматизацию ресурсных требований, устанавливая объект Vertical Pod Autoscaler в режим Auto (автоматическое масштабирование ресурсов CPU и памяти). VPA рассчитывает рекомендацию и последовательно выселяет pod’ы. Вот как может выглядеть рекомендация:
VPA установил запросы на память на 3,41 Гб, лимит — на 5,6 Гб (такое же отношение, как у 6 Гб и 10 Гб), запросы и лимиты для CPU — на 12 миллиядер.
Давайте посмотрим, как это соотносится с первоначальными оценками. Мы запросили на 1,6 Гб меньше памяти на каждый pod. Таким образом, в общей сложности мы сэкономили 4,8 Гб памяти. Разница может показаться не особо существенной, но в случае большого числа кластеров MongoDB объем сэкономленной памяти стремительно возрастает.
Другой пример — etcd. Это высокодоступная база данных, использующая Raft в качестве алгоритма выбора лидера. Первоначально запрашиваются только ресурсы CPU:
Далее мы разворачиваем StatefulSet без Vertical Pod Autoscaling и даем ему поработать некоторое время:
На графике показано использование памяти кластером etcd. Каждая из линий соответствует отдельной реплике. Как видно, одна реплика использует около 500 Мб, две другие — по 300 Мб.
А этот график показывает использование CPU. Видно, что оно относительно постоянно и равно 0,03 ядра процессора.
Вот как выглядит рекомендация VPA:
VPA запросил 599 Мб памяти (без лимитов) и 93 миллиядра CPU (0.093 ядра) с лимитом в 65 ядер (придерживаясь первоначально установленного соотношения запрос/лимит — 1 к 700).
Таким образом, VPA зарезервировал предостаточно ресурсов для полноценной работы etcd. Изначально мы не запрашивали память для данного pod’а, что может привести к его планированию на слишком загруженный узел и вызвать проблемы. Аналогичным образом, запрошенные ресурсы CPU оказались недостаточны для работы etcd.
В нашем случае интересным открытием стало то, что текущий лидер использует значительно больше памяти, чем остальные реплики. Как видно, VPA рекомендовал одинаковый объем памяти всем репликам. Таким образом, существует разрыв между запрошенным и используемым объемом памяти. Поскольку вторичные узлы не будут использовать более 300 Мб памяти, пока не станут первичными, на каждом из этих узлов будут оставаться невостребованные ресурсы.
Хотя в данном примере разрыв вполне адекватен. В случае, если один из вторичных узлов станет лидером, он сможет воспользоваться зарезервированными ресурсами. Если бы мы их не зарезервировали, данный узел мог бы быть убит из-за OOM, что привело бы к простою.
Резервирование с CronJob
В заключительном примере пойдет речь о простом задании, которое запускается по расписанию, снимает копию базы MongoDB и сохраняет ее в S3. Задание запускается ежедневно и обычно занимает около 12 минут.
Первая пара запусков прошла без запросов на ресурсы: VPA собирал данные об их использовании. В это время VPA выводил ошибку «No pods match this VPA object». Для третьего запуска VPA предложил следующие рекомендации:
Теперь давайте разберемся, как работает Vertical Pod Autoscaling.
Как работает VPA?
Vertical Pod Autoscaler состоит из трех различных компонентов:
Recommender — использует некоторые эвристики для подсчета рекомендаций;
Updater — отвечает за вытеснение pod’ов в случае, когда происходит значительное изменение ресурсных требований;
Компонент Admission Controller задает ресурсные требования pod’а.
Теоретически любой из компонентов можно заменить кастомным. И все должно по-прежнему работать. Давайте рассмотрим компоненты подробнее:
Recommender
При работе с Prometheus Recommender выполняет запрос на PromQL, в котором используются метрики cAdvisor. Recommender позволяет настроить лейблы, используемые в запросе. Можно менять пространство имен, имена pod’ов/контейнеров, лейблы имен заданий Prometheus. В общем, он будет посылать запросы, похожие на этот:
Результатом таких запросов станет информация об использовании CPU и памяти. Recommender проанализирует результаты и будет использовать их для рекомендаций ресурсов.
О том, как VPA подсчитывает рекомендации, рассказано в следующем разделе («Модель рекомендаций VPA»).
Updater
При этом в Updater встроен ряд защитных механизмов, ограничивающих вытеснение pod’ов:
Поскольку используется API Kubernetes для вытеснения, Updater соблюдает Pod Disruption Budgets. PDB позволяют задать требования к доступности, чтобы предотвратить вытеснение слишком большого числа pod’ов. Например, если установить максимальное число недоступных (max unavailable) pod’ов равным единице, то компонент сможет вытеснять только один pod. Подробнее о PDB — здесь.
Updater принимает решение о вытеснении pod’ов на основе нижней и верхней границ. Он вытеснит pod, если запрос на ресурсы меньше нижней границы или больше верхней, а также присутствует значительное изменение запросов на ресурсы по сравнений с целевой оценкой. В настоящее время пороговая разница составляет 10%.
После вытеснения pod’а в игру вступает последний компонент — Admission Controller. Он отвечает за создание pod’а и применение рекомендаций.
Admission Controller
Компонент Admission Controller задает ресурсные требования pod’а.
Перед планированием pod’а Admission Controller получает webhook-запрос от API-сервера Kubernetes на обновление спецификации pod’а. Admission Controller делает это через конфигурацию mutating webhook’а (подробнее в документации к Kubernetes Admission Control). Просмотреть mutating webhook’и можно с помощью следующей команды:
kubectl get mutatingwebhookconfigurations
Если VPA установлен правильным образом, вы увидите конфигурацию mutating webhook’а для Admission Controller’а VPA.
Давайте теперь разберемся, как VPA рекомендует ресурсы.
Модель рекомендаций VPA для CPU
Предположим, у нас есть контейнер, и мы снимали данные об использовании CPU каждую минуту в течение 48 часов. График загрузки CPU выглядит следующим образом:
Для подсчета рекомендации для CPU мы создаем гистограмму с экспоненциально растущими границами интервалов. Первый интервал начинается от 0,01 ядра (1 миллиядра) и заканчивается примерно на 1000 ядрах CPU. Каждый интервал растет экспоненциально со скоростью 5%.
При добавлении данных об использовании CPU в гистограмму мы находим интервал, в который попадает фактическое использование процессора, и добавляем вес, зависящий от текущего запрошенного значения для контейнера.
Когда запрос на CPU увеличивается, растет и вес интервала. Это свойство делает предыдущие наблюдения менее значимыми, что помогает быстро реагировать на троттлинг процессора.
Давайте превратим график использования CPU, приведенный выше, в подобную гистограмму (с экспоненциальным ростом интервалов и данными, взвешенными с учетом распада). Предположим, что в течение всех 48 часов запрос на мощности CPU составляет 1 ядро.
Гистограмма будет выглядеть следующим образом:
Примечание: мы построили график только для первых 36 интервалов, поскольку остальные интервалы пусты. Значения интервалов варьируются в диапазоне от 0 до 0,958 ядра CPU (округленно). 37-й интервал имеет значение 1,016. Поскольку наш график никогда не достигает этого значения, он пуст.
Далее VPA подсчитывает три различных оценки: target (цель), lower bound (нижняя граница), upper bound (верхняя граница). Мы используем 90-й процентиль для цели, 50-й процентиль для нижней границы и 95-й процентиль — для верхней.
Давайте подсчитаем значения для примера, приведенного на первом рисунке:
Затем к обеим границам добавляется доверительный множитель. Доверительный множитель зависит от того, сколько дней собирались данные. Для верхней границы подсчет производится следующим образом:
оценка = оценка * (1 + 1/продолжительность сбора данных в днях)
Из формулы видно, что чем дольше мы ведем статистику, тем ниже множитель. То есть со временем верхняя граница будет приближаться к цели. Чтобы лучше разобраться в формуле, ниже приведены значения множителей для различных периодов:
В нашем примере статистика велась в течение двух дней, поэтому доверительный множитель для верхней границы равен 1,5.
Аналогичным образом нижнюю границу мы умножаем на доверительный интервал. Однако в этот раз формула немного другая:
оценка = оценка * (1 + 0.001/продолжительность сбора данных в днях)^-2
Из формулы видно, что чем дольше мы ведем статистику, тем выше множитель. Таким образом, со временем нижняя граница будет приближаться к целевому уровню. Чтобы лучше разобраться в формуле, ниже приведены значения множителей для различных периодов:
Как видно, он стремительно приближается к 1. В нашем примере статистика велась в течение двух дней. Поэтому доверительный множитель для нижней границы почти равен единице.
После добавления резерва к нашим оценкам и учета доверительных множителей конечные значения выглядят следующим образом:
Модель рекомендаций VPA для памяти
Хотя большинство шагов одинаковы, существуют и значительные отклонения от алгоритма для CPU. Начнем с потребления памяти. Оно выглядит следующим образом:
Обратите внимание, что на графике показано использование памяти за семь дней. Более длительный интервал в данном случае имеет принципиальное значение, поскольку оценка требуемой памяти начинается с вычисления пикового значения для каждого интервала. Используется пиковое значение, а не все распределение, поскольку обычно стараются выделить объем памяти, близкий к пиковому потреблению: ведь ее недостаток приведет к прекращению задач по OOM. В то же время алгоритм выделения CPU-мощностей не так чувствителен к данной проблеме, поскольку при недостатке ресурсов pod’ы сталкиваются с троттлингом, а не убиваются.
Давайте посмотрим, как эти пиковые агрегации выглядят в нашем примере:
Агрегация пиковых нагрузок на память
Кроме того, если в течение этого времени возникает событие Out Of Memory, мы анализируем использование памяти данным pod’ом, берем максимальное значение и прибавляем к нему 20% или 100 Мб (в зависимости от того, что больше). Этот метод позволяет VPA быстро адаптироваться к OOM-инцидентам.
После того, как пиковые значения установлены, их можно свести в гистограмму. VPA создает гистограмму с экспоненциально растущими границами интервалов. Первый интервал начинается с 10 Мб и заканчивается примерно на 1 Тб. Каждый интервал растет экспоненциально со скоростью 5%.
Давайте посмотрим, как выглядит гистограмма для пиковых значений из нашего примера:
Примечание: мы построили график только для интервалов с 16 по 38, поскольку остальные интервалы пусты. Значения интервалов варьируются от 225,62 Мб до 969,20 Мб (округленно). Значение 39-го интервала составляет 1088,10. Он пуст, так как наш график никогда не достигает этого значения.
Далее VPA подсчитывает три различных оценки: target (цель), lower bound (нижняя граница), upper bound (верхняя граница). Мы использует 90-й процентиль для цели, 50-й процентиль для нижней границы и 95-й процентиль — для верхней.
В нашем примере все три оценки одинаковы: 1027,2 Мб.
Оценки после вычисления 50-го, 90-го и 95-го процентиля
Затем к обеим границам добавляется доверительный множитель. Доверительный множитель зависит от того, сколько дней собирались данные. Формулы те же, что и при выведении оценок для CPU.
После добавления резерва и учета доверительных множителей конечные значения выглядят следующим образом:
1237422043 байт = 1,15 Гб
1238659775 байт = 1,15 Гб
1857989662 байт = 1,73 Гб
Обратите внимание, что зеленая линия — это верхняя граница, красная — нижняя. Цель не видна, так как она близка к красной линии (разница между ними составляет всего 1,18 Мб)



