Витрины данных DATA VAULT
В предыдущих статьях, мы познакомились с основами DATA VAULT, расширением DATA VAULT до более подходящего для анализа состояния и созданием BUSINESS DATA VAULT. Настало время завершать серию третьей статьей.
Как я анонсировал в предыдущей публикации, эта статья будет посвящена теме BI, а точнее подготовке DATA VAULT в качестве источника данных для BI. Рассмотрим, как создать таблицы фактов и измерений и, тем самым, создать схему звезда.
Когда я начал изучать англоязычные материалы по теме создания витрин данных над DATA VAULT у меня возникло ощущение достаточной сложности процесса. Так как статьи имеют внушительный объем, там присутствуют отсылки к изменениям в формулировках, появившихся в методологии Data Vault 2.0, обозначается важность этих формулировок.
Однако, углубившись в перевод, стало понятно, что процесс этот не так уж и сложен. Но, возможно у вас сложится другое мнение.
И так, давайте переходить к сути.
Таблицы измерений и фактов в DATA VAULT
Самое сложная для понимания информация:
На этом теория, в принципе заканчивается.
Но, все же, на мой взгляд, необходимо отметить пару понятий, которые могут встретиться в статьях о методологии DATA VAULT:
Понятие “Information Marts” появилось в методологии Data Vault 2.0, оно заменило старое понятие “Data Marts”. Это изменение обусловлено осознанием задачи по реализации модели данных для построения отчетов как преобразование данных в информацию. Схема “Information Marts”, в первую очередь, должна обеспечивать бизнес пригодной для принятия решений информацией.
Достаточно многословные определения отражают два простых факта:
Создание витрины, хранящей актуальную информацию каждого атрибута нескольких сателлитов, входящего в хаб, например, номер телефона, адрес, ФИО, подразумевает использование PIT таблицы, через обращение к которой легко получить все даты актуальности. Витрины такого типа относят к “Information Marts”.
Оба подхода актуальны как для измерений, так и фактов.
Для создания витрин, хранящих информацию о нескольких линках и хабах может быть задействовано обращение к BRIDGE таблицам.
Этой статьей я завершаю цикл о концепции DATA VAULT, надеюсь информация, которой я поделился будет полезна в реализации ваших проектов.
Как всегда, в завершении, несколько полезных ссылок:
Что такое витрина данных? Определение, разновидности и примеры
Что такое хранилище данных? Как правило, это база, в которой хранится вся масса информации по деятельности той или иной компании.
Оглавление

Что такое хранилище данных? Как правило, это база, в которой хранится вся масса информации по деятельности той или иной компании. Но нередко бывает нужным выделить из всего этого масштабного комплекса данные по одному направлению работы организации, подразделению, служебному вопросу. Здесь приходит на помощь иной тип хранилища – так называемые витрины данных. Что это, каковы ее достоинства, недостатки, разновидности, мы с вами будем рассматривать на протяжении статьи.
Что это?
Что такое витрины данных? Английский вариант – Data Mart. Существует несколько синонимов понятия:
Определимся с трактовкой термина “витрина данных”:
Дать объявление в витрину данных не получится. Она является одним из типов хранения внутренней информации организации, а не предоставления сведений широкому кругу пользователей.

Концепция хранилища
Идея создания витрин данных была предложена в 1991 году Forrester Research. Авторы представляли данное хранилище информации как определенное множество специфических баз данных, которые содержат в себе сведения, относящиеся к конкретным векторам деятельности корпорации.
Forrester Research выделяли следующие сильные стороны своего проекта – витрин данных:
Но те же Forrester Research говорили и о слабых сторонах своего изобретения:
Перейдем теперь к новой теме.

Конструирование витрин
Главный пример витрин данных – это тематические подмножества заранее агрегированной информации. Соответственно, такие БД гораздо легче проектировать и настраивать. Создают подобные витрины для поиска конкретных ответов на запросы пользователя. Данные в них адаптируются создателем под определенные группы сотрудников. Подобная оптимизация облегчает процедуру наполнения витрин, способствует повышению производительности подобных БД.
Известно, что конструирование комплексных хранилищ данных – довольно сложный процесс, который может растянуться даже на несколько лет. А вот витрины данных, конкретизированные по отдельным структурам предприятия, фирмы, создавать проще и быстрее. Надо сказать, что несколько витрин могут успешно сосуществовать и с основным хранилищем информации, давая о нем частичное представление.
Как мы упоминали, проектирование витрин данных – технологически облегченный процесс. Но создателям ВД нужно помнить о том, что при построении впоследствии могут возникнуть проблемы с интеграцией информации (в случае, если проектирование производилось без учета комплексной бизнес-модели).

Независимые витрины: примеры
Витрина данных SQL – аналитическая структура, поддерживающая работу одного из приложений, подразделения, бизнес-раздела. Его сотрудники обобщают свои требования к информации, приспосабливают витрину к собственным служебным нуждам. Далее проходит обеспечение персонала, контактирующего с этими данными, определенными средствами интерактивной отчетности.
Независимые витрины данных исторически складываются в крупных организациях, которые имеют большое число самостоятельных подразделений с собственными отделами информационных технологий. Примеры их можно выделить следующие:
Достоинства независимых витрин
Давайте выделим ключевые преимущества витрин данных, которые найдены непосредственными создателями и пользователями:
Недостатки независимых витрин
Давайте определимся с минусами витрин данных, которые выделяют пользователи и проектировщики:

Смешанная концепция
А что будет, если соединить между собой концепции витрин данных и хранилища данных? Таким вопросом задался в 1994 году М. Демарест. Именно он предложил объединить вышеуказанные концепции для дальнейшего использования хранилища (базы) данных в качестве интегрированного единого источника при проектировании витрин данных.
Данное решение объединяет в себе три уровня:
Данная многомерная структура со временем станет стандартной во многих компаниях. Главная причина того – объединение в ней достоинств двух подходов:
 m_i_kuznetsov
m_i_kuznetsov
 m_i_kuznetsov
m_i_kuznetsov Размышления о разработке программного обеспечения и информационных систем
То, что действительно важно, но чему нигде не учат
Обычно, говоря о структуре реляционной базы данных, имеют в виду нечто такое:

Тут всё просто до безобразия. Имеется структура справочной информации о некоторой инфраструктуре обмена данными между офисами разных организаций. Офисы находятся в разных регионах. Передача данных осуществляется с использованием офисного коммуникационного оборудования по линиям связи, принадлежащим другим организациям-провайдерам. Способ организации передачи данных обзовём каналом передачи, пусть для простоты он просто указывает на используемое оборудование и линию связи. Сразу скажу, что пример надуманный, но хорошо иллюстрирует суть обсуждаемой темы.
Факт передачи данных по конкретному каналу фиксируется в отдельной таблице.
Для решения этой задачи вам придётся получить два набора данных об организациях-отправителях и организациях-получателях, для чего дважды пройти по всей структуре справочников от таблицы фактов обмена данными до таблицы организаций. Только после этого вы сможете объединить оба набора по идентификатору сессии обмена данными и получить результирующий отчёт. Если в таблице обмена данными хранится очень много данных, то такой запрос будет выполняться очень долго.
Напрашивается естественное решение: заранее подготовить набор данных с тем, чтобы при возникновении потребности пользователей в подготовке отчёта просто выполнить сортировку и фильтрацию данных. Для этого можно создать витрину данных:

Ещё плюс в том. что витрина позволяет изолировать читаемые данные от часто изменяемых и тем самым пользователи не будут ждать, пока будет происходить обновление справочников или балком заливаться информация о фактах обмена данными. Можно будет задать регламент обновления витрин и довести его до сведения пользователей, что сделает работу вашей системы предсказуемой и оперативной.
Таким образом, весь процесс работы с данными выглядит следующим образом.

Исходные данные поступают в нормализованную структуру в виде справочной и оперативной информации.
Далее по расписанию, событию или команде пользователя вызывается хранимая процедура, которая выполняет преобразование исходных данных в витрину. В нашем случае ХП будет формировать те самые перечни организаций-отправителей и организаций-получателей, объединять оба перечня и сохранять результат в витрине. В некоторых случаях хранимая процедура параметризуется. Например, можно указать интервал времени, в рамках которого будут извлекаться факты обмена данными, что позволит не перестраивать всю витрину, а добавлять в неё только новые данные.
Выборка данных при чтении или выгрузке производится только из витрин.
По истечении срока хранения данных витрина очищается другой хранимой процедурой. Очистка (или даже пересоздание таблицы витрины) может также производиться в других случаях: при обнаружении ошибки в исходных данных, для быстрого перестроения всей витрины и т.п.
В заключение дам несколько ремарок.
Во-первых, я нарочно указал в справочниках в качестве значений идентификаторов объектов их коды. Часто объекты справочной информации классифицируются на основе некоторых общепризнанных классификаторов (международных, государственных, отраслевых, корпоративных и т.п.). Например, код региона может задаваться в соответствии с Общероссийским классификатором экономических регионов (ОКЭР). Пользователям удобнее работать с классификатором, чем запоминать длиннющие названия. Да и набирать на клавиатуре коды классификаторов проще.
Соответственно, в структуре витрины коды классификаторов должны присутствовать. Но если в вашей конкретной системе всё не так однозначно, то вы вправе сами решить, нужны ли вам идентификаторы исходных данных в витрине, или нет.
В-третьих, вы сами должны решить, нужно ли в витрине создавать вторичные ключи, указывающие на записи в таблицах исходных данных. Я предпочитаю не делать в базе данных ничего лишнего без явной на то нужды.
В-четвёртых, витрины можно и часто нужно вытаскивать в отдельную БД. Этот подход хорошо работает, в том числе, при использовании NoSQL-хранилища в качестве первичной базы данных, на основе информации которой формируются витрины уже в реляционной структуре.
Data Mart vs Data Warehouse
Некоторое время назад я начал разбираться в OLAP и в данном посте хочу проверить правильность собственных мыслей на счет этих двух понятий.
Терминология
Data Mart — витрина данных, в переводе.
Data Warehouse — хранилище данных.
Но дело в том, что оба эти термина могут переводится как Хранилище данных…
Data Mart — срез Data Warehouse.

(кликабельно)
Есть два подхода к построению хранилищ данных:
Первый проще, по Кимбелу (Kimball)
Тут информация от OLTP системы напрямую попадает в data mart, откуда уже OLAP берет необходимые ему данные. Первый случай очевидно иллюстрирует подход М. Демареста (M.Demarest), который, как говорит Wikipedia:
в 1994 году предложил объединить две концепции и использовать хранилище данных в качестве единого интегрированного источника данных для витрин данных.
Второй, по Инману (Inman), см. книгу.
Здесь информация от OLTP сначала попадает в хранилище данных (data warehouse), потом только в data mart, откуда OLAP снова берет необходимую ему информацию.
Мы же адаптируем подход Инмана, который называет хранилищем данных настоящую релиционную бд, тогда как Кимбел — смесь data mart`ов.
Data mart — это база данных, созданная по требованиям моделирования измерений (dimensional modelling) и состоит из таблиц фактов и таблиц измерений.
Data Mart
При реализации системы по методологии Кимбела, фронтендом бд должен выступать data mart, который использует Analysis Services для куба в качестве источника данных
Data Warehouse
(кликабельно)
таким образом является сложнее data mart`a, включает в себя не только бд, но и систему поддержки принятия решений и клиент-серверную архитектуру, тогда как data mart по сути является бд, созданной с учетом требований будущих кубов.
Источники:
http://ru.wikipedia.org/wiki/Витрина_данных
http://ru.wikipedia.org/wiki/Хранилище_Данных
Книга Expert Cube Development with Microsoft SQL Server 2008 Analysis Services, на английском

которую я перевожу у себя в блоге.
Все о Process Mining от ProcessMi
Все о технологии Process Mining — кейсы, термины, решения и аналитика. Российский и зарубежный опыт от группы экспертов ProcessMi
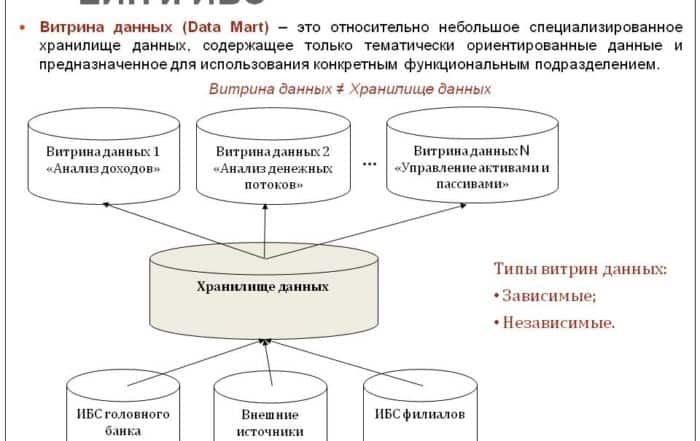
Витрина данных

Витрина данных – это один из срезов хранилища данных, являющийся массивом тематической информации, направленной на удовлетворение запросов одного отдела/департамента/службы и др. Иными словами, витрина – это пул тематических сведений, которые относятся к одному направлению работы компании. Например, маркетингу, продажам, HR или финансам.
Несмотря на специфичное название, витрины не предоставляют информацию, а хранят в себе внутрикорпоративные данные. Кроме того, это достаточно небольшие по объему хранилища либо и вовсе его часть, которая используется конкретной структурной единицей. Обязательное условие: если в корпоративной системе две или больше витрин, то содержащиеся в повторяющихся секциях данные, должны быть идентичными.
История
Появление и развитие витрин очень плотно связано с OLAP – технологией обработки данных. Их история (формально, не концептуально) началась в 1993 году благодаря Теду Кодду. Однако в дальнейшем выяснилось, что такие системы неудобны для их использования в качестве посредника между транзакционными системами. Возникла потребность в некой платформе, которая будет хранить аналитические данные. Были созданы ХД – хранилища данных (Data Warehouse). Но накопление важной и конфиденциальной информации, а также географическая распределенность стали точкой преткновения: потенциальные финансовые потери вследствие несанкционированного доступа, невозможность быстрого реагирования и обслуживания.
Выходом стало создание витрин данных (Data Mart), которые содержали в себе необходимое количество информации из ХД. Их наполнение могло происходить в часы снижения активности пользователей, в случае повреждения или сбоев все данные можно восстановить благодаря искомому хранилищу.
Преимущества витрин данных:
Однако есть и свои минусы, где главный – отсутствие обеспечения целостности и непротиворечивости хранимых в витрине данных.
Типы витрин
Существует несколько типов витрин:
Источником такой витрины является хранилище данных. Такой тип позволяет объединить все бизнес-данные в единое ХД. В случае, если требуется одна или несколько витрин, зависимость будет обеспечивать согласованность и интеграцию во все системы хранения данных.
Зависимые витрины данных могут строиться с использованием двух подходов. При первом корпоративное ХД и сами витрины создаются так, чтобы при необходимости пользователь мог получить доступ и туда, и туда. Во втором – результаты ETL хранятся во временной области хранения вместо физической базы данных, поэтому пользователь может получить доступ только к витрине данных.
Такой тип создается без использования центрального хранилища данных и рекомендуется для небольших подразделений или групп внутри организации. Независимые витрины получают данные непосредственно из операционного источника/внешнего источника. Однако существует вероятность дублирования информации на нескольких витринах. Из-за того, что данные витрин не консолидируются, нет полной картины работы компании.
Кроме двух классических типов, существует еще один, называемый гибридной витриной данных. Он объединяет входные данные из других источников, кроме центрального хранилища данных, и поддерживает большие структуры хранения.



