Кто такой Data Scientist?

Дата-сайентист (он же Data Scientist, специалист по Data Science) может найти себе работу в любой сфере: от розничной торговли до астрофизики. Потому что именно он — настоящий повелитель больших данных. Вместе с автором кейсов для курса по Data Science Глебом Синяковым разбираемся, почему в современном мире всем так нужны дата-сайентисты.
Чем занимается Data Scientist?
Data Scientist применяет методы науки о данных (Data Science) для обработки больших объемов информации. Он строит и тестирует математические модели поведения данных. Это помогает найти в них закономерности или спрогнозировать будущие значения. Например, по данным о спросе на товары в прошлом, дата-сайентист поможет компании спрогнозировать продажи в следующем году. Модели строят с помощью алгоритмов машинного обучения, а с базами данных работают через SQL.
Где нужен и какие задачи решает Data Scientist?
Дата-сайентисты работают везде, где есть большие объемы информации: чаще всего это крупный бизнес, стартапы и научные организации. Поскольку методы работы с данными универсальны, специалистам открыты любые сферы: от розничной торговли и банков до метеорологии и химии. В науке они помогают совершать важные открытия: проводят сложные исследования, например, строят и обучают нейронные сети для молекулярной биологии, изучают гамма-излучения или анализируют ДНК.
В крупных компаниях дата-сайентист — это человек, который нужен всем отделам:
В стартапах они помогают разрабатывать технологии, которые выводят продукт на новый уровень: TikTok использует машинное обучение, чтобы рекомендовать контент, а MSQRD, который купил Facebook, — технологии по распознаванию лица и искусственный интеллект.
Пример задачи:
Если дата-сайентисту нужно спрогнозировать спрос на новую коллекцию кроссовок, то он:
Что ему нужно знать?
Дата-сайентист должен хорошо знать математику: линейную алгебру, теорию вероятности, статистику, математический анализ. Математические модели позволяют найти в данных закономерности и прогнозировать их значения в будущем. А чтобы применять эти модели на практике, нужно программировать на Python, уметь работать с SQL и библиотеками (набор готовых функций, объектов и подпрограмм) и фреймворками (ПО, объединяющее готовые компоненты большого программного проекта) для машинного обучения (например, NumPy и Scikit-learn). Для более сложных задач дата-сайентистам нужен язык С или C++.
Результаты анализа данных нужно уметь визуализировать, например, с помощью библиотек Seaborn, Plotly или Matplotlib.
Что такое Data Science и кто такой Data Scientist
Что делает Data Scientist, сколько получает и как им стать, даже если вы не программист. Объясняем и делимся полезными ссылками.

Что такое Data Science?
Data Science — это работа с большими данными (англ. Big Data). Большие данные — это огромные объёмы неструктурированной информации: например, метеоданные за какой-то период, статистика запросов в поисковых системах, результаты спортивных состязаний, базы данных геномов микроорганизмов и многое другое. Ключевые слова здесь — «огромный объём» и «неструктурированность». Чтобы работать с такими данными, используют математическую статистику и методы машинного обучения.
Специалист, который делает такую работу, называется дата-сайентист (или Data Scientist). Он анализирует большие данные (Big Data), чтобы делать прогнозы. Какие именно прогнозы — зависит от того, какую задачу нужно решить. Итог работы дата-сайентиста — прогнозная модель. Если упростить, то это программный алгоритм, который находит оптимальное решение поставленной задачи.

Пишу научпоп, люблю делать сложное понятным. Рисую фантастику. Увлекаюсь спелеологией. Люблю StarCraft, шахматы, «Монополию».

Эти прогнозы и правда полезны?
Да. Очень многие сервисы, к которым мы уже привыкли, создали дата-сайентисты. И вы сталкиваетесь с результатами их работы каждый день. Например, это прогнозы погоды, чат-боты, голосовые помощники… А ещё — алгоритмы, рекомендующие музыку и видео под вкус конкретного пользователя. Список возможных друзей в социальных сетях — тоже результат Data Science. В основе поисковых систем и программ для распознавания лиц тоже лежат алгоритмы, написанные дата-сайентистами.

То есть Data Science — то же самое, что и обычная бизнес-аналитика?
Нет, это не одно и то же. Основная разница заключается в результате. Data Scientist ищет в массивах данных связи и закономерности, которые позволят ему создать модель, предсказывающую результат, — то есть можно сказать, что Data Scientist работает на будущее. Он использует программные алгоритмы и математическую статистику и решает поставленную задачу в первую очередь как техническую.
Бизнес-аналитик сосредоточен не столько на технической, программной стороне задачи, сколько на коммерческих показателях компании. Он работает со статистикой и может оценить, например, насколько эффективна была рекламная кампания, сколько было продаж в предыдущем месяце и так далее. Вся эта информация может использоваться для улучшения бизнес-показателей компании. Если данных много и нужен какой-то прогноз или оценка, то для решения технической стороны этой задачи бизнес-аналитик может привлечь дата-сайентистов.
Поясним на примере. Допустим, программа анализирует финансовые операции клиента и рекомендует выдать ему кредит или отказать. То есть задача программы — оценить платёжеспособность клиента. Создание такого програмного алгоритма — работа дата-сайентиста.
А бизнес-аналитик не занимается такими техническими задачами. Его не интересует работа с конкретным клиентом, но он может проанализировать всю статистику банка по кредитам, например, за последние три месяца — и рекомендовать банку сократить или увеличить объёмы кредитования. Это бизнес-задача: предлагаются действия, которые увеличат доходность банка либо снизят финансовые риски.
Работа бизнес-аналитика и дата-сайентиста нередко пересекается, просто каждый занимается своей частью задачи.

А где обычно работает Data Scientist?
Вот несколько вариантов:
И это далеко не полный список. Везде, где нужны прогнозы, совершаются сделки или оцениваются риски, пригодится Data Scientist. Вот несколько примеров рабочих моделей. Некоторые неожиданные: например, Corrupt Social Interactions — модель, выявляющая коррупцию в Департаменте строительства (Department of Building) США. Или сервис А Roommate Recommendation — он помогает подобрать соседа по комнате в кампусе или хостеле.

Понятно. А работу найти легко? Это точно востребовано?
Легко ли найти работу — зависит и от кандидата тоже. Но сама профессия весьма востребована. В 2016 году американская компания Glassdoor опубликовала рейтинг 25 лучших вакансий в США и профессия Data Scientist возглавила этот список. С тех пор востребованность стала даже выше.
Алгоритмы машинного обучения сейчас стремительно развиваются, прогнозы на их основе становятся точнее, а сфер их применения всё больше. Это значит, что у профессии Data Scientist большое будущее.

Но это за рубежом. А что в России?
У нас спрос на этих специалистов тоже постоянно растёт. Например, в 2018 году вакансий с названием Data Scientist было в 7 раз больше по сравнению с 2015 годом, а в 2019 году рост продолжился.
На середину апреля 2020 года на hh.ru — 323 вакансии с заголовком Data Scientist, из них 204 вакансии — в Москве, 39 — в Санкт-Петербурге и остальные — в других городах.

А сколько они зарабатывают?
Как и везде, это зависит от опыта работы и навыков дата-сайентиста, особенностей компании и сложности конкретного проекта. Но общий расклад примерно такой (данные приведены по состоянию на февраль 2020 года):
Высококвалифицированные специалисты по Data Science могут получать в месяц 250 тысяч рублей и более.

Вы сказали, что Data Scientist создаёт программный алгоритм. А что конкретно он делает?
В разных компаниях деятельность дата-сайентиста будет различаться. Однако основные этапы похожи:

Что нужно знать и уметь, чтобы работать в Data Science?
Если в общих чертах, то нужно знать математику, математическую статистику, программирование, принципы машинного обучения и ту отрасль, где всё это будет использоваться.
И умение работать в команде тоже никто не отменял: дата-сайентисту приходится общаться с разными специалистами.

Если у меня нет технического образования, то о работе в Data Science лучше не мечтать?
Будем откровенны — гуманитариям осваивать эту профессию может быть непросто: для работы в Data Science нужно хорошее знание математики и программирования. А у гуманитария этих знаний чаще всего нет. И наоборот: чем увереннее вы чувствуете себя в этом уже на старте, тем проще будет учиться.
Однако не стоит опускать руки: очень многое зависит от мотивации, от того, насколько вы готовы восполнять пробелы в своем образовании. Сейчас люди приходят в Data Science с разным бэкграундом и в разном возрасте. Вот пример одной такой истории — возможно, она вас поддержит.

А с чего лучше начать?
Начать лучше с математики. Очень сложная математика не понадобится, но вы должны свободно ориентироваться в таких понятиях, как производная, дифференциал, определитель матрицы, и в том, что с ними связано. Освоить это вам помогут книги и лекционные курсы. Например, книга «Математический анализ» Липмана Берса, написанная довольно простым языком.

А что дальше? Там было что-то о статистике?
Да, потому что математическая статистика используется в любой аналитике. И Data Science не исключение. Вот несколько бесплатных курсов, которые помогут вам изучить статистику.

Кажется, с математической частью закончили. Что по программированию?
Следующим шагом будет изучение Python. Сейчас этот язык программирования, пожалуй, основной инструмент в Data Science. Среди его достоинств — относительная простота и гибкость. Освоить Python вполне по силам новичку, который до того не программировал. Неслучайно этот язык нередко рекомендуют для начинающих.
По Python есть много курсов, как платных, так и бесплатных. Вот один из бесплатных курсов. И ещё один: «Питонтьютор».
У Skillbox тоже есть курс, он называется «Профессия Python-разработчик». Курс платный, длится год, и за это время студенты фактически осваивают с нуля новую профессию (как теорию, так и практику) и собирают личное портфолио — с помощью наставника. Поэтому по окончании курса им уже есть что показать потенциальному работодателю.

Что учить после Python?
Теперь можно изучать алгоритмы машинного обучения. Когда освоитесь с ними, уже сможете работать в Data Science.
Вот несколько бесплатных онлайн курсов по машинному обучению (много курсов на английском, но кое-что есть и на русском).
Мало знать методы машинного обучения, нужно уметь применять их для решения практических задач. Научиться этому можно на платформе Kaggle, где собрано огромное количество реальных задач.
Если вы хорошо знаете английский, он поможет вам быстрее развиваться в Data Science. Если нет — самое время его выучить.

Очень много всего. Может быть, есть курсы, где можно освоить сразу всё?
Да, есть и такие. Например, наш курс по Data Science. Он так и называется — «Профессия Data Scientist». На наш курс приходят как люди с опытом в программировании, так и совсем новички, программа курса это учитывает. Обучение длится около года, в нём уже есть все блоки, которые мы описали выше.
Учиться можно онлайн, из любого города. Наши преподаватели — практики с опытом работы 10–15 лет. У вас будет возможность не только освоить теорию, но и практиковаться на реальных задачах, получая рекомендации от наставника. Очень важный бонус — помощь при трудоустройстве.
Кто такой дата-сайентист
Если вы не знаете, чем заняться ближайшие 15 лет, — идите в дата-сайенс, помогите нейросетям захватить мир.
В последнее время на слуху два термина: биг дата и дата-саенс. Сегодня — что это такое и зачем нужно.
Большие данные
Начнём с простого — big data, или «большие данные». Это модный термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5-6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — биг дата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это биг дата.
Ещё биг дата: данные о звонках и смс у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещённые сайты; данные о покупках в конкретном магазине (которые хранятся в их кассе); данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы… Короче, любой большой массив данных.
Почему появился такой термин: в конце девяностых компании в США стали понимать, что сидят на довольно больших массивах данных, с которыми непонятно что делать. И чем дальше — тем этих данных больше.
Раньше данные были, условно говоря, по кредитным картам, телефонным счетам и из профильных государственных ведомств; а теперь чем дальше — тем больше всего считается. Супермаркеты научились вести сверхточный учёт склада и продаж. Полиция научилась с высокой точностью следить за машинами на дороге. Появились смартфоны, и вообще вся человеческая жизнь стала оцифровываться.
И вот — данные вроде есть, а что с ними делать? Тут на сцену выходит дата-сайенс — дисциплина о больших данных.
Дата-сайенс
Дата-сайентисты — люди, которые занимаются большими данными: находят закономерности и делают на их основе полезные для своей компании выводы.
Например, мы — управляющая компания магазина «Пятёрочка». В каком-то районе у нас открыто три магазина. Мы можем попросить дата-сайентиста проанализировать транзакции в наших магазинах и сделать прогноз, можно ли какие-то из них закрыть, сохранив общую выручку на прежнем уровне.
Или мы хотим открыть кофейню. У нас есть данные об общественном транспорте города, о положении кофеен в городе и стоимости аренды в разных домах. Мы можем попросить дата-сайентиста предсказать, где в городе не хватает кофеен относительно пассажирских потоков.
Допустим, мы мобильный оператор. Мы хотим сделать тариф «Юный хайпожор» для юных любителей отведать хайпа. Мы отдаём нашу клиентскую базу и данные о поведении клиентов дата-сайентисту, и тот считает нам экономику будущего тарифа и потенциальный объём рынка, а также помогает выделить самых голодных до хайпа людей.
Иногда эти ребята помогают с управлением в компаниях: они на основе данных пишут отчёты, которые показывают слабые места на производстве и дают рекомендации по их устранению. Или отвечают на вопросы из серии «Почему наши менеджеры так мало продают?» или «Где стоять продавцу-консультанту, чтобы к нему обращались чаще всего?».
Что знают и умеют дата-сайентисты
Вот начальный список навыков, знаний и умений, которые нужны любому дата-сайентисту для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое.
Есть те, кто говорит, что это всё не нужно, и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну, вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Мы уже писали, что Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
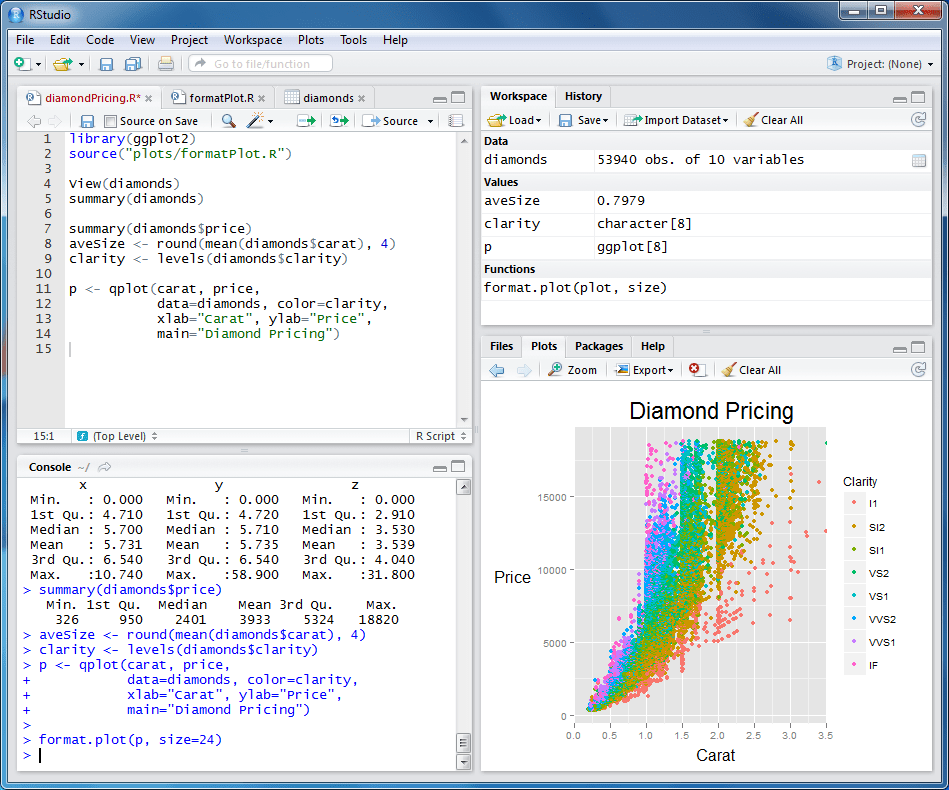 R и статистика в действии. Картинка с Хабра.
R и статистика в действии. Картинка с Хабра.
Умение получать и визуализировать данные. Не всем дата-сайентистам везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего они сами должны выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Второй важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
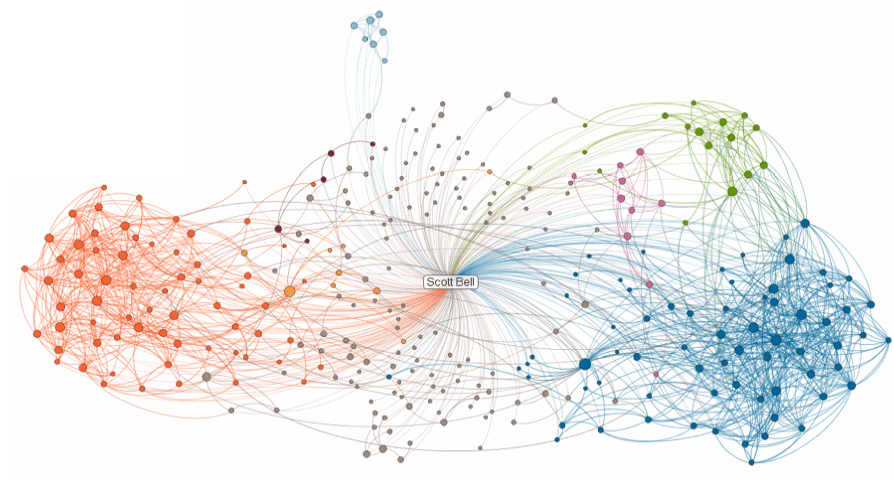 Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Как это выглядит в жизни
Дата-сайентист в современном понимании — очень молодая профессия. Компании уже поняли, что эти ребята помогут им заработать или сэкономить миллионы долларов, поэтому они создают для них новые отделы и рабочие места.
С другой стороны, такой набор знаний — редкость, поэтому дата-сайентистов сейчас на рынке очень мало: гораздо меньше, чем предложений о работе. Именно поэтому у них такие высокие зарплаты — компании сами борются за то, чтобы нанять такого специалиста.
Так как это направление только развивается, у многих программистов есть шанс попасть туда и работать аналитиком. Для этого нужно прокачивать умение писать код, математику и статистику. Если вы всё это уже знаете и умеете — можете попробовать себя в «профессии будущего».
В «Яндекс-практикуме» есть курс для аналитиков — это начало пути дата-сайентиста. Можно попробовать бесплатный урок и посмотреть, как вам — понравится или нет.
Чем занимается специалист по Data Science и как начать работать в этой области?
Специалист в области Data Science строит на основе данных модели, которые помогают принимать решения в науке, бизнесе и повседневной жизни. Он может работать с неструктурированными массивами информации в разных сферах: от выявления элементарных частиц в экспериментах на БАК, анализа метеорологических факторов, анализа данных о перемещениях автотранспорта до исследования финансовых операций, поисковых запросов, поведения пользователей в Интернете.
В результате получаются модели, которые прогнозируют погоду, загруженность дорог, спрос на товары, находят снимки, где могут оказаться следы нужных элементарных частиц, выдают решения о предоставлении кредита, могут рекомендовать товар, книгу, фильм, музыку.
Анна Чувилина, автор и менеджер программы «Аналитик данных» Яндекс.Практикума, рассказала, какие задачи решает специалист в области Data Science или датасаентист, в чем состоит его работа и чем он отличается от аналитика данных.
Что такое Data Science?
Data Science — это применение научных методов при работе с данными, чтобы найти нужное решение. В широком смысле, естественные науки основаны на Data Science. Например, биолог проводит эксперименты и анализирует результаты для проверки своих гипотез. Он должен уметь обобщать частные наблюдения, исключать случайности и делать верные выводы.
Датасаентист работает с данными так же, как ученый в любой другой сфере. Он использует математическую статистику, логические принципы и современные инструменты визуализации, чтобы получить результат.
Сбор данных — это способ измерить процессы вокруг нас. А научные методы позволяют расшифровать большие массивы данных, найти в них закономерности и применить для решения конкретной задачи.
Кто такой специалист по Data Science?
Датасаентист обрабатывает массивы данных, находит в них новые связи и закономерности, используя алгоритмы машинного обучения, и строит модели. Модель — это алгоритм, который можно использовать для решения бизнес-задач.
Например, в Яндекс.Такси модели прогнозируют спрос, подбирают оптимальный маршрут, контролируют усталость водителя. В результате стоимость поездки снижается, а качество растет. В банках модели помогают точнее принимать решения о выдаче кредита, в страховых компаниях — оценивают вероятность наступления страхового случая, в онлайн-коммерции — увеличивают конверсию маркетинговых предложений.
Глобальные поисковые системы, рекомендательные сервисы, голосовые помощники, автономные поезда и автомобили, сервисы распознавания лиц — все это создано с участием датасаентистов.
Анализ данных — это часть работы датасаентиста. Но результат его труда — это модель, код, написанный на основе анализа. В этом главное отличие между датасаентистом и аналитиком данных. Первый — это инженер, который решает задачу бизнеса как техническую. Второй — бизнес-аналитик, больше погруженный в бизнес-составляющую задачи. Он изучает потребности, анализирует данные, тестирует гипотезы и визуализирует результат.
«Датасаентист решает задачи с помощью машинного обучения, например распознавание изображений или предсказание расхода материала на производстве. Результат его работы — работающая модель по техническому заданию, которая будет решать бизнес-задачу», — Анна Чувилина, автор и менеджер программы «Аналитик данных» в Яндекс.Практикуме.
Специалист по Data Science проходит те же карьерные ступени, что и другие профессионалы в IT: джуниор, мидл, тимлид или сеньор. В среднем, каждая ступень занимает от года до двух. Более опытный специалист лучше понимает бизнес-задачи и может предложить лучшее решение для них. Чем выше уровень, тем меньше датасаентист сфокусирован только на технических задачах. Он может оценивать проект и его смысловую составляющую.
Задачи специалиста по Data Science
Задачи различаются от компании к компании. В крупных корпорациях датасаентист работает с несколькими направлениями. Например, для банка он может решать задачу кредитной оценки и заниматься процессами распознавания речи.
Этапы работы над задачей у датасаентистов из разных сфер похожи:
Каждая новая итерация позволяет лучше понять проблемы бизнеса, уточнить решение. Поэтому каждый этап повторяется снова и снова для развития модели и обновления данных.
Data Science работает и для стартапов, и для крупных корпораций. В первых специалисты работают в одиночку или небольшими командами над отдельными задачами, а во вторых — реализуют долгосрочные проекты в связке с бизнес-аналитиками, аналитиками данных, разработчиками, инфраструктурными администраторами, дизайнерами и менеджерами.
Руководитель проекта с аналитиками берёт на себя большую часть работы: общается с бизнесом, собирает требования, формирует техническое задание. В зависимости от уровня и принципов работы в компании, специалист по Data Science участвует в переговорах или получает задачи от руководителя проекта и аналитиков.
Следующий этап — сбор данных. Если в компании не налажены процессы для получения данных, датасаентист решает и эту задачу. Он внедряет инструменты, которые помогают автоматически получать и предварительно очищать, структурировать нужную информацию.
Разметка данных — это тоже способ навести в них порядок. Каждой записи присваивается метка, по которой можно определять класс данных: это спам или нет, клиент платежеспособен или недостаточно. Для этой задачи редко используют алгоритмы, метки проставляют вручную. Качественно размеченные данные имеют большую ценность.
«Со стороны заказчика часто присылаются первые данные, которые не готовы для анализа. Специалист их изучает и пытается понять взаимосвязи внутри данных. Для этого часто используется пайплайн — стандартная последовательность действий для процесса анализа данных, которая у каждого своя. Во время ‘‘просмотра’’ у специалиста возникают гипотезы относительно данных, которые он потом будет проверять», — говорит Анна Чувилина, автор и менеджер программы «Аналитик данных» в Яндекс.Практикум.
Во время обработки данные переводятся в формат, удобный для машинного обучения, чтобы запустить первое, «пробное» обучение. Оно должно подтвердить или опровергнуть гипотезы о данных, которые есть у специалиста по Data Science. Если гипотезы не подтверждаются, работа с этим набором данных прекращается. Если одна или несколько гипотез окажутся жизнеспособными — на выходе получается первая версии модели. Её можно назвать baseline-моделью или базовой, относительно которой на следующих итерациях можно искать улучшения в качестве работы модели. Это минимально работающий продукт, который можно показать, протестировать и развивать дальше.
Вместе с моделированием или перед ним выбирают метрики для оценки эффективности модели. Как правило, это две категории: метрики для бизнеса и технические. Бизнес-метрики отвечают на вопрос «каков экономический эффект от работы данной модели?» Технические определяют качество модели, например, точность предсказаний.
Модель оценивают на контролируемость и безопасность. Например, для задач медицинской диагностики это решающий фактор. Когда модель готова и протестирована, то её встраивают в производственный процесс (например, кредитный конвейер) или продукт (например, мобильное приложение). Она начинает приносить пользу в реальной жизни.
Ошибки в моделях могут дорого стоит компании. Например, неверная скоринговая модель создаст ситуацию, когда ненадежные заемщики массово не смогут возвращать кредиты. В результате банк понесёт убытки.
Что нужно для старта
Знание математической статистики, базовые навыки программирования и анализа данных нужны для входа в любую сферу, где может быть занят датасаентист. Следующие этапы потребуют более глубоких знаний. Набор необходимых скиллов и инструментов будет во многом зависеть от задач конкретной компании.
«Для решения простых задач и попадания на уровень джуниора достаточно базовых знаний машинного обучения, математического аппарата и программирования. От специалиста уровня мидл и сеньор уже требуется умение тонко настраивать параметры, которые влияют на общее качество результата. Список разделов из высшей математики и понимание математической постановки каждой модели на этому уровне на порядок выше, чем для джуниора» — Анна Чувилина, автор и менеджер программы «Аналитик данных» в Яндекс.Практикум.
Как правило, в Data Science используют SQL, Python, для сложных вычислений — C/C++. Хороший уровень английского поможет быстрее расти за счет чтения профессиональной литературы и общения с другими профессионалами отрасли.
Бэкграунд разработчика хорошо подходит для переквалификации в датасаентисты. Разработчики знают языки программирования, разбираются в алгоритмах и имеют представление о принципах работы инструментов в ИТ. В таком случае переход в новую специальность займет несколько месяцев. Важные конкурентные преимущества, доступные профессионалам из других сфер: лучшее понимание предметной области, сильные коммуникативные навыки.
От начинающего специалиста по Data Science работодатель ждёт:
Опыт работы с реальными бизнес-проектами для работодателя важнее, чем ученая степень или профильное высшее образование. Дипломы сильных вузов и тематические научные работы ценятся больше при выборе привлеченных консультантов на стратегические проекты. А по практическому опыту выбирают датасаентиста для решения ежедневных задач компании.
Перед датасаентистом не стоит задача охватить все области математического знания или освоить каждый программный инструмент, который можно применить для анализа данных и построения модели. Над масштабными и сложными проектами обычно работают группы специалистов. Здесь навыки и знания каждого дополняют общий инструментарий. Чтобы стартовать в профессии достаточно любить программирование, математику и не бояться сложных задач.



