Заимствование
Заи́мствование — это копирование (обычно неполное и неточное) слова или выражения из одного языка в другой. Заимствованием также называют само заимствованное слово. Заимствование в языках является одним из важнейших факторов их развития. В зависимости от языка, из которого было заимствовано слово, такие слова называют «англицизмы», «арабизмы», «германизмы» и т. п. В некоторых случаях название заимствования может не совпадать с названием языка: например заимствования из чешского языка называются богемизмами, из французского — галлицизмами. Название заимствования может охватывать группу родственных языков — славянизм, тюркизм, и т. д.
Содержание
Сужение значения при заимствовании
Если в исходном языке слово было многозначным, то при заимствовании обычно берётся только одно из его значений, т. е. происходит сужение значения слова, например:
То же относится и к калькам:
Роль заимствований
Заимствование увеличивает лексическое богатство языка, служит источником новых корней, словообразовательных элементов и терминов и представляет собой следствие условий социальной жизни человечества. Процесс заимствования лежит уже в самой основе языковой деятельности. Однообразие звуковое и формальное, замечаемое в пределах того или иного языка или говора, объясняется процессом постоянного взаимного заимствования одними индивидуумами у других. Возможно, далее, более или менее активное взаимное заимствование между разными языками, родственными или не родственными между собой.
Результаты этого заимствования двояки:
Заимствование может быть изустное и книжное (являющееся уже на более высоких ступенях культурного развития). При помощи последнего возможно заимствование элементов, принадлежащих более древней стадии того же языка (воскрешение архаизмов, например в поэтическом языке: Рихард Вагнер в своих музыкальных драмах, граф Алексей Толстой и др.). В огромном большинстве случаев заимствование чужих слов вызывается культурным заимствованием. Отсюда громадное значение заимствованных слов для истории культуры. Чуждое происхождение известных названий указывает на иноземное происхождение и соответствующих понятий или предметов.
Примеры
Не подлежит сомнению, что заимствование происходило в широких размерах и в доисторическую эпоху. Очень может быть, что некоторые слова, принимаемые за общеиндоевропейские, были взяты в ПИЕ из других языков. Как бы слабо ни было культурное развитие нераздельных индоевропейцев, все-таки они должны были иметь торговые и другие сношения с прочими народами, причем несомненно могло происходить и заимствование. Наука пока не в состоянии определить подобные древнейшие заимствования, хотя кое-что, вероятно, будет раскрыто при дальнейшей совместной работе археологов и языковедов.
Самым надёжным критерием при определении заимствования слова является его фонетический состав. Противоречие звуков слова известным фонетическим законам, характерным для данного языка, свидетельствует обыкновенно о чуждом происхождении слова. Так, например, русское слово «брада», употреблявшееся раньше в высокой речи, рядом с основным словом «борода», заимствовано из старославянского (через церковно-славянский язык), потому что ра (вместо ожидаемого оро, имеющегося в природном русском слове борода) противоречит звуковому закону так называемого полногласия (то же самое с град — город, страж — сторож и т. д.).
Прочие критерии — семасиологический (разница в значении), морфологический (разница в формальном отношении) — менее надёжны и могут применяться только при невозможности узнать происхождение слова по его фонетическому составу. Так, высокопарное значение слов муж и жена в смысле homo и mulier рядом с природным их значением супруга и супруги, возможно, заимствовано из латинского при посредстве церковно-славянского, хотя по фонетическому составу слова эти ничем не отличаются от природных.
Заимствование представляет следующие две крупные категории:
Обыкновенно различают слова «усвоенные» (нем. Lehnwörter ) и «иностранные» (нем. Fremdwörter ). К первым принято относить слова, в основном усвоенные очень давно и не производящие впечатления чего-то чуждого, то есть ставшие «родными» в данном языке, например, князь, витязь, известь, комната, корабль, лошадь, таможня, хлеб, царь, церковь и т. д. Ко вторым относятся слова, усвоенные в основном недавно и сохраняющие ещё свой иноземный облик: аберрация, офицер, дифференциация, параллакс, адъютант и т. д. Это деление, однако, не может быть названо строго-научным; оно основано на субъективном впечатлении, весьма изменчивом, и служит только основанием хотя какой-нибудь классификации. Критику его можно найти у С. Булича, «Церковно-славянские элементы в современном литературном и народном русском языке» (ч. I, СПб., 1893. Введение); там же указана важнейшая литература вопроса о З. и охарактеризован самый процесс его. См. его же, «Заимствованные слова и их значение для развития языка» («Русск. филолог. вестник», Варшава, 1886, № 2).
Таинственный противник: нечеткие заимствования
Неправомерное Заимствование — это многоголовая гидра, враг, постоянно меняющий свое лицо. Наши лучшие частные сыщики готовы зацепиться за любое злодеяние, совершенное этим врагом. Однако противник не дремлет, он хитер и коварен: явно подставляясь в одном деле, он невероятно умело заметает следы в других. Иногда его удается поймать с поличным с помощью нашего самого шустрого сотрудника — Суффиксного Массива. Иногда противник мешкает, и скрупулезный, но неторопливый Поиск Парафраза успевает вычислить его местоположение. Но зло коварно, и нам постоянно нужны новые силы для борьбы с ним.
Сегодня мы расскажем о нашем новом детективе специального назначения по имени Нечеткий Поиск, а также о его первом столкновении с нечеткими заимствованиями.
С вами детективное агентство Антиплагиат, приготовьтесь к Делу о Таинственном Противнике

Место происшествия
При проверке местности (документа) Антиплагиат проверяет, не поступали ли звонки о возможном преступлении в этом районе. В качестве очевидцев, которые будут сигнализировать нам о преступлении, выступает Индекс шинглов.
«Шингл — это кусочек текста размером в несколько слов». Каждый такой кусочек хешируется, и в индексе ищутся документы, которые имеют шинглы с теми же хешами, что и в проверяемом документе.
Очевидец, видя совпадение по хешу двух шинглов, звонит нам с сообщением о преступлении. К сожалению, индекс шинглов нельзя наказать за ложный вызов, он невосприимчив к санкциям, из-за чего звонков происходит очень много. Агентство определяет документы с наибольшим скоплением таких звонков — места потенциального преступления.
Первая зацепка
Теперь ты детектив, сынок.
Отныне тебе запрещается верить в совпадения.
© «Темный рыцарь: возрождение легенды» («The Dark Knight Rises», реж. К. Нолан, 2012).
Детектив Нечеткий Поиск прибыл на место преступления. Достаточно крупные преступники не остаются незамеченными, ведь чем больше масштаб преступления, тем больше шансов оставить зацепку. Для Нечеткого Поиска такими зацепками являются короткие совпадения фиксированной длины. Кажется, что наш детектив упускает большую долю умело заметающих следы преступников, однако лишь 5% злоумышленников не оставляют такой зацепки. Важно не потерять преступников, поэтому детектив быстро сканирует местность, используя особую методику обнаружения совпадений.
Дневник детектива о методике работы. Первый этап
Воспользуемся двумя особенностями задачи:
Второе условие необходимо, чтобы ограничить количество найденных четких дубликатов. Ведь шингл, встречающийся 1000 раз в документе и в источнике, даст 1000000 пар совпадений. Такие часто повторяющиеся шинглы можно увидеть только в неочищенных документах с попытками обхода.
Очищенный от обходов документ представлен в виде последовательности слов. Приводим слова к нормальной словоформе, затем хешируем их. Получим последовательность целых чисел (на гифке — последовательность букв). Все шинглы этой последовательности хешируются и заносятся в хеш-таблицу с значением позиции начала подстроки. Затем для каждого шингла в документе-кандидате ищутся совпадения в хеш-таблице. Так формируются четкие дубликаты фиксированной длины. Тесты показывают трехкратное ускорение при использовании нового метода в сравнении с суффиксным массивом.

Вычисляем преступника
— Есть еще какие-то моменты, на которые вы посоветовали бы мне обратить внимание?
— На странное поведение собаки в ночь преступления.
— Собаки? Но она никак себя не вела!
— Это-то и странно, — сказал Холмс.
© Артур Конан-Дойль, «Серебряный» (из серии «Записки о Шерлоке Холмсе»)
Итак, Нечеткий Поиск отыскал несколько зацепок, по которым нужно установить преступников. Наш герой использует свои дедуктивные способности на полную катушку, чтобы по крупицам, постепенно восстановить образ преступника по найденным зацепкам. Сыщик постепенно расширяет картину происходящего, дополняя ее новыми деталями, обнаруживая все новые и новые улики, пока эта картина, наконец, не станет полной. Нашего детектива иногда заносит, и его приходится спускать с небес на землю и убеждать, что нам нужна личность преступника, а не биография его двоюродной сестры. Нечеткий Поиск ворчит, но смиренно сужает картину до желаемых масштабов.
Дневник детектива о методике работы. Второй этап

Второй этап распространяет дубликаты влево и вправо по документу. Распространение происходит от «центров» — найденных четких дубликатов. Для сравнения суффиксов используем расстояние Левенштейна — минимальное количество удалений/замен/вставок слов, необходимое для приведения одной строки к другой. Дистанцию можно вычислять динамически для суффиксов дубликата, используя алгоритм Вагнера-Фишера, опирающийся на рекурсивное определение расстояния Левенштейна. Однако этот алгоритм квадратичный по сложности и не позволяет контролировать долю ошибок. Еще одной проблемой является точное определение границ дубликатов. Для решения этих вопросов мы применяем несколько прямолинейных, но, тем не менее, эффективных процедур.
На этом шаге предлагается сначала последовательно заполнять Матрицу Расстояний Левенштейна для суффиксов нечеткого дубликата (потом, аналогично, для префиксов). Поскольку мы проверяем суффиксы на «похожесть», нас интересуют только значения вблизи диагонали этой матрицы (Расстояние Левенштейна больше либо равно разности длин строк). Это позволяет добиться линейной сложности. Задав максимально допустимое расстояние Левенштейна, будем заполнять таблицу, пока не встретим столбец со значениями больше допустимых. Такой столбец сигнализирует о том, что наш нечеткий дубликат недавно закончился и слова практически полностью перестали совпадать. Заранее сохранив для каждой заполненной клетки предыдущую оптимальную, спускаемся из клетки с минимальным в критическом столбце штрафом, пока не встретим несколько совпадений, после которых ошибка начала резко расти. Это и будут границы найденного нечеткого дубликата.
Дополнительно, чтобы ошибки не накапливались, вводится процедура, которая сбрасывает число ошибок, начиная распространение заново, если мы наткнулись на «островок» из последовательных совпадений.
Банда преступников
— Завтра с одногруппниками планируем собраться!
— В одного большого одногруппника?
— Что?
Нечеткому Поиску осталась несложная задачка: объединить преступников, пойманных в одном и том же месте, в банды, оправдать невиновных подозреваемых и собрать полученные результаты воедино.
Склейка дубликатов решает сразу 3 проблемы. Во-первых, второй этап «распространение дубликатов» поглощает модификации слов и словосочетаний, но не целых предложений. Если увеличить «способность распространения» алгоритма, то он начнет распространятся по случайно найденным совпадениям и на слишком большое расстояние, а границы дубликатов будут определяться хуже. Так мы потеряем столь важный нам Precision, которым обладал четкий поиск.
Во-вторых, второй этап плохо распознает перестановку двух дубликатов. Хотелось бы, чтобы перестановка двух предложений местами образовывала фразу, близкую к исходной, но для строки из уникальных символов перестановка префикса и суффикса местами приводит к строке, максимально удаленной от исходной (в метрике Левенштейна). Получается, что второй этап при перестановке предложений находит два расположенных рядом дубликата, которые хочется объединить в один.
И третья причина — это Granularity, или Гранулярность. Гранулярность — это метрика, которая определяет усредненное количество найденных дубликатов в одном истинном заимствовании, которое мы обнаружили. Другими словами, гранулярность показывает, насколько хорошо мы находим заимствование целиком вместо нескольких частей, покрывающих его. Формальное определение гранулярности, а также определение микро-усредненной точности и полноты можно посмотреть в статье «An evaluation framework for plagiarism detection».
Гифка показывает, что иногда два дубликата можно склеить лишь после того, как один из них приклеится к третьему дубликату. Соответственно, просто одним проходом слева направо по документу полноценную склейку произвести не получится.
Список дубликатов на входе отсортирован по левой границе в документе.
Текущий дубликат пробуем склеить с несколькими ближайшими кандидатами перед ним.
Если получается, пробуем склеить еще раз, если нет — переходим к следующему дубликату.
Поскольку количество дубликатов не больше, чем длина документа, а каждая перепроверка уменьшает количество дубликатов на 1 и выполняется за константное время, то сложность этого алгоритма — O(n).
В качестве правила для склейки дубликатов используется набор нескольких параметров, но, если забыть про микрооптимизации качества, то мы будем склеивать те дубликаты, для которых максимум из расстояний в документе и источнике достаточно мал.
Локальность склейки обеспечивает O(1) дубликатов, к которым можно приклеить текущий дубликат.
Профессиональная подготовка новичка
Детективу необходимо было приспособиться под особенности нашего городка, адаптироваться под местность, прогуляться по неприметным улочкам и узнать получше его жителей. Для этого новичок проходит специальный курс обучения, в котором он изучает схожие ситуации на тренировочном полигоне. Детектив на практике изучает зацепки, дедукцию и построение социальных связей для максимально эффективной поимки преступников.
Параметрическую модель было необходимо оптимизировать. Для определения оптимальных параметров модели использовалась выборка PlagEvalRus.
Выборка разбита на 4 коллекции:
Поиск оптимальных параметров модели мы осуществляли с помощью метода спуска с мультистартом. Максимизировалась  -мера с
-мера с  (упор на точность). Приведем здесь наиболее значимые оптимальные параметры.
(упор на точность). Приведем здесь наиболее значимые оптимальные параметры.
| Параметр модели | Описание | Manually_Paraphrased (более строгая модель) | Manually_Paraphrased 2 (менее строгая модель) |
|---|---|---|---|
| MinExactCiteLength | Длина четкого дубликата для 1-го этапа | 5 | 3 |
| MinSymbolCiteLength | Минимальная длины итоговой цитаты в символах | 70 | 95 |
| Limit | Максимально допустимое расстояние Левенштейна | 5 | 10 |
| MinExpandLength | Количество совпадение для обнуления штрафа распространения | 2 | 2 |
| GlueDistance | Расстояние в словах для склейки дубликатов | 11 | 29 |
| MinWordLength | Минимальная длины итоговой цитаты в словах | 10 | 11 |
Статистика раскрытых дел
Испытательный срок нашего Нечеткого Поиска подошел к концу. Давайте сравним его продуктивность с продуктивностью другого детектива, Суффиксного Массива. Тренировочный курс Нечеткий Поиск проходил по программе Manually_Paraphrased.
В полевых условиях новичок показал значительное превосходство в доле раскрытых дел. Скорость его работы также не может не радовать. В нашем агентстве не хватало такого ценного сотрудника.
Сравнивая качество модели с суффиксным массивом, заметим значительное улучшение гранулярности, а также более качественное обнаружение средне и сильно-модифицированных заимствований.
Тестируя на документах размером вплоть до 10 7 слов, убеждаемся в линейности обоих алгоритмов. На процессоре i5-4460 программа обрабатывает пару «документ-источник» длиной в миллион слов менее чем за секунду.
Сгенерировав тексты с большим числом заимствований, убеждаемся, что нечеткий поиск (синяя линия) не медленнее суффиксного массива (красная линия). Наоборот, суффиксный массив страдает на больших документах от слишком большого количества дубликатов. Мы сравнили быстродействие при минимальной длине дубликата равной 5 словам. Но для достаточного покрытия заимствованиями мы используем четкий поиск с минимальной длиной дубликата равной 3 словам, что на гигантских документах приводит к значительному падению производительности (оранжевая линия). Стоит заметить, что обычные документы содержат меньше заимствований, и на практике этот эффект выражен значительно меньше. Зато такой эксперимент позволяет понять расширение границ применимости моделей новым нечетким поиском.
Примеры:
| Оригинал | Заимствование |
|---|---|
| «За сочетание захватывающих историй с анализом человеческой натуры» в 2014 году он получил заслуженную награду — Национальную медаль США в области искусств | В 2014 году награжден Национальной медалью США в области искусств с формулировкой «за сочетание захватывающих историй с анализом человеческой натуры» |
| складываться культура тоталитаризма, где подавлялось всякое инакомыслие. Для построения социализма были поставлены следующие задачи: ликвидация безграмотности, создание системы высших учебных заведений, подготовку кадров | Складывается культура тоталитаризма. Всякое инакомыслие подавлялось. Для достижения главной цели построения социализма были пост лены следующие задачи: 1.Культурная революция, включающая ликвидацию безграмотности, создание гигантской системы ВУЗов; НИИ, библиотек, театров, подготовку кадров |
Видно, что алгоритм, несмотря на малую вычислительную сложность, справляется с обнаружением замен/удалений/вставок, а третий шаг позволяет обнаруживать заимствования с перестановкой предложений и их частей.
Эпилог
Нечеткий Поиск работает в команде с другими нашими инструментами: Быстрым Поиском Документов-кандидатов, Извлечением Форматирования Документа, Масштабным Отловом Попыток Обхода. Такая команда позволяет быстро найти потенциальный плагиат. Нечеткий Поиск прижился в этой команде и выполняет свои поисковые функции качественнее, и, что немаловажно, быстрее, чем это делал Суффиксный Массив. Наше агентство будет еще лучше справляться со своими задачами, а недобросовестные авторы столкнутся с новыми проблемами при использовании не оригинального текста.
ЗАИМСТВОВАНИЕ
ЗАИМСТВОВАНИЕ, процесс, в результате которого в языке появляется и закрепляется некоторый иноязычный элемент (прежде всего, слово или полнозначная морфема); также сам такой иноязычный элемент. Заимствование – неотъемлемая составляющая процесса функционирования и исторического изменения языка, один из основных источников пополнения словарного запаса. Заимствованная лексика отражает факты этнических контактов, социальные, экономические и культурные связи между языковыми коллективами. Так, в германских языках имеется обширный пласт древнейших латинских заимствований, относящихся к различным предметным сферам, в славянских языках древнейшие заимствования – из германских и иранских языков. Например, немецкое слово Arzt «врач» произошло из латинского archiater (из греческого 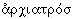 , букв. «главный врач»), Kreuz «крест» из лат. crucem, Tafel – из лат. tabula, schreiben из лат. scribere и т.д. Из древнейших заимствований в русском языке можно назвать слово князь (из др.-германского kuningaz), шлем (из др.-герм. helmaz); из иранских языков – например, слово собака. Заимствования бывают прямыми или опосредованными. Так, многие европейские слова были заимствованы русским языком через посредство польского, например музыка (слово греческого происхождения, пришедшее в русский язык через Европу и Польшу, о чем свидетельствует звук ы вместо и и изначальное ударение муз
, букв. «главный врач»), Kreuz «крест» из лат. crucem, Tafel – из лат. tabula, schreiben из лат. scribere и т.д. Из древнейших заимствований в русском языке можно назвать слово князь (из др.-германского kuningaz), шлем (из др.-герм. helmaz); из иранских языков – например, слово собака. Заимствования бывают прямыми или опосредованными. Так, многие европейские слова были заимствованы русским языком через посредство польского, например музыка (слово греческого происхождения, пришедшее в русский язык через Европу и Польшу, о чем свидетельствует звук ы вместо и и изначальное ударение муз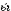 ка), слово рынок (из польского rynek с тем же значением, возникшего, в свою очередь, из немецкого Ring «кольцо, круг») и др. Есть заимствованные слова с очень долгой и сложной историей, например слово лак: в русский язык оно пришло из немецкого или голландского, в эти языки – из итальянского, итальянцы же заимствовали его, скорее всего, у арабов, к которым оно попало через Иран из Индии. История таких «странствующих» слов воспроизводит историю соответствующих реалий.
ка), слово рынок (из польского rynek с тем же значением, возникшего, в свою очередь, из немецкого Ring «кольцо, круг») и др. Есть заимствованные слова с очень долгой и сложной историей, например слово лак: в русский язык оно пришло из немецкого или голландского, в эти языки – из итальянского, итальянцы же заимствовали его, скорее всего, у арабов, к которым оно попало через Иран из Индии. История таких «странствующих» слов воспроизводит историю соответствующих реалий.

При заимствовании значение слова часто сдвигается. Так, французское слово chance означает «удача» (Tu a de la chance! – «Тебе повезло!»), в то время как русское слово шанс означает лишь «возможность удачи». Русское слово азарт происходит из французского hasard «случай»; семантический переход произошел за счет словосочетания jeu d’hasard – «азартная игра», букв. «игра случая». Иногда значение слова меняется до неузнаваемости. Например, русское слово идиот произошло из греческого 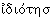 «частное лицо»; слово сарай восходит к персидскому слову со значением «дворец» (в русский язык оно вошло через тюркское посредство). Бывает и так, что заимствованное слово возвращается в своем новом значении обратно в тот язык, из которого оно пришло. Такова, по-видимому, история слово бистро, пришедшего в русский язык из французского, где оно возникло после войны 1812, когда части русских войск оказались на территории Франции – вероятно, как передача реплики «Быстро!»
«частное лицо»; слово сарай восходит к персидскому слову со значением «дворец» (в русский язык оно вошло через тюркское посредство). Бывает и так, что заимствованное слово возвращается в своем новом значении обратно в тот язык, из которого оно пришло. Такова, по-видимому, история слово бистро, пришедшего в русский язык из французского, где оно возникло после войны 1812, когда части русских войск оказались на территории Франции – вероятно, как передача реплики «Быстро!»
Вообще говоря, у языка, оказавшегося перед лицом иностранного слова, обозначающего некоторое отсутствующее в нем нужное понятие (это может быть как новый «предмет», так и новая «идея»), имеется три возможности: 1) заимствовать само это слово: таким образом в языке появляются заимствования в узком смысле, например русское ярмарка является заимствованием нем. Jahrmarkt, хор – др.-греч. 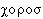 , кворум из лат. quorum, идиллия из нем. Idylle, поэзия из франц. poésie, кайф из араб. kejf, дизайн из англ. design и т.д.; 2) создать новое слово из своих морфем по образцу иностранного: таким образом в языке появляются словообразовательные кальки: напр., русское слово языкознание создано по образцу немецкого Sprachwissenschaft, кислород – по образцу латинского oxygenium, предмет – по образцу objectum и т.п.; 3) использовать для выражения нужного значения уже имеющееся слово, придав ему новое значение по образцу иностранного слова, имеющего ту же полисемию или ту же внутреннюю форму (это называется семантическим калькированием); например, русский глагол трогать приобрел переносное значение «волновать чувства» под влиянием французского toucher, имеющего оба значения (прямое и переносное); русские слова влияние и вдохновение приобрели современное «абстрактное» значение под влиянием франц. influence и inspiration. Слова и значения, созданные по второй и третьей модели, называют заимствованиями в широком смысле (см. также КАЛЬКА).
, кворум из лат. quorum, идиллия из нем. Idylle, поэзия из франц. poésie, кайф из араб. kejf, дизайн из англ. design и т.д.; 2) создать новое слово из своих морфем по образцу иностранного: таким образом в языке появляются словообразовательные кальки: напр., русское слово языкознание создано по образцу немецкого Sprachwissenschaft, кислород – по образцу латинского oxygenium, предмет – по образцу objectum и т.п.; 3) использовать для выражения нужного значения уже имеющееся слово, придав ему новое значение по образцу иностранного слова, имеющего ту же полисемию или ту же внутреннюю форму (это называется семантическим калькированием); например, русский глагол трогать приобрел переносное значение «волновать чувства» под влиянием французского toucher, имеющего оба значения (прямое и переносное); русские слова влияние и вдохновение приобрели современное «абстрактное» значение под влиянием франц. influence и inspiration. Слова и значения, созданные по второй и третьей модели, называют заимствованиями в широком смысле (см. также КАЛЬКА).
В научной терминологии, стремящейся к однозначности, чаще используется первый и второй механизм. Второй и третий механизмы составляют важнейшие источники обогащения литературного языка. Таким образом, лексика общезначимого характера включает заимствования всех трех типов. Основной поток заимствований в узком смысле (т.е. иноязычных слов) идет через разговорную речь профессиональных сфер и жаргоны различных социальных групп.
Нередко в языке сосуществуют слова, идентичные по своей внутренней форме, но одно из них является прямым заимствованием, а другое – калькой; при этом они обычно не полностью совпадают, а иногда весьма существенно расходятся по значению, например: субъект и подлежащее, оппозиция и противопоставление, композиция и сложение, позиция и положение, позитивный и положительный, президент и председатель, биография и жизнеописание и т.п. Такая дублетность весьма характерна для русского, в меньшей степени – для немецкого языка и не характерна для французского и английского.
Среди заимствований выделяется группа так называемых интернационализмов, т.е. слов греко-латинского происхождения, получивших распространение во многих языках мира. Сюда относятся, например, греческие слова: философия, демократия, проблема, система, атом, анализ, синагога, симпозиум, хирург и т.п.; латинские: республика, революция, университет, принцип, субъект, прогресс, нация и т.п. Помимо готовых латинских и греческих слов, в международной научной терминологии широко используются отдельные греко-латинские морфемы: корни, приставки и суффиксы (многие греческие морфемы были заимствованы латинским языком еще в античную эпоху). К строительным элементам греческого происхождения относятся, например: био-, гео-, гидро-, антропо-, пиро-, хроно-, психо-, микро-, демо-, тео-, палео-, нео-, микро-, макро-, поли-, моно-, авто-, псевдо-, пара-, анти-, гомео-, алло- а-; -логия, -графия, -метрия, -филия, -фобия, -лиз, -оз, -тика, -ика и др.; латинского: социо-, суб-, супер-, интер-, ультра-, экстра-, квази-, дис-, де-, ре-; -ит, -ор, -тор, -фикация, -изация и др. При построении терминов интернациональные греческие и латинские элементы могут комбинироваться между собой (напр., телевизор, социология), а также с морфемами, заимствованными из новых европейских языков, например спидометр (от англ. speed «скорость»), европеизация, русификация и т.п. Наиболее распространенные иноязычные морфемы заимствуются вместе со своими деривационными связями; так, от всех слов греческого происхождения на -з(ис) и -зия, в том числе в новообразованных научных терминах, образуются, в соответствии с греческой (а не русской) морфологией, прилагательные на -тический: гомеостаз(ис) – гомеостатический, идиосинкразия – идиосинкратический и т.п.
Слова греческого происхождения в русском языке бывают двух типов – в соответствии с эпохой и способом их заимствования. Наиболее многочисленную группу составляют те греческие слова, которые пришли в русский язык через латынь и новые европейские языки – сюда относится вся международная научная терминология, а также множество общезначимых слов, таких как тема или сцена. С другой стороны, поскольку культурным и культовым образцом для средневековой Руси была Византия, в русском языке оказалось много слов, заимствованных из греческого языка византийской эпохи, который отличался от классического греческого, в частности произношением некоторых букв. Это произношение (называемое Рейхлиновым) отличается от так называемого Эразмова (принятого при передаче греческих слов в западноевропейской традиции) в следующих отношениях. В более близком к классическому Эразмовом чтении греческая буква 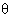 передается на письме как th (произносится как русское т), греческая буква
передается на письме как th (произносится как русское т), греческая буква 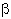 – как b; буква
– как b; буква 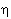 , а также древний дифтонг
, а также древний дифтонг 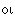 – как e. В русских словах, пришедших через посредство западных языков, на месте указанных греческих букв используются, соответственно, буквы т, б, е/э (е в середине слова, э – в начале), например: тема, театр, библиотека, гомеопатия, этика, экономика, Эдип. В византийском (Рейхлиновом) чтении буква передается по-русски как ф, – как в, буквы и дифтонгов ,
– как e. В русских словах, пришедших через посредство западных языков, на месте указанных греческих букв используются, соответственно, буквы т, б, е/э (е в середине слова, э – в начале), например: тема, театр, библиотека, гомеопатия, этика, экономика, Эдип. В византийском (Рейхлиновом) чтении буква передается по-русски как ф, – как в, буквы и дифтонгов , 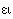 – как и. Это произношение отражено в словах, пришедших в русский язык непосредственно из византийского греческого: алфавит (из названий греческих букв «альфа» и «бета»), варвар, кафедра, Афины, Фивы, фита (название впоследствии упраздненной буквы русского алфавита, соответствующей греческой букве «тета»), финик (из греч.
– как и. Это произношение отражено в словах, пришедших в русский язык непосредственно из византийского греческого: алфавит (из названий греческих букв «альфа» и «бета»), варвар, кафедра, Афины, Фивы, фита (название впоследствии упраздненной буквы русского алфавита, соответствующей греческой букве «тета»), финик (из греч. 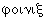 ) и др. Греческое начальное
) и др. Греческое начальное 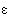 в старых заимствованиях, т.е. в словах, пришедших прямо из Византии, передается как е (епископ, епитимья, Евгения и т.п.) – в отличие от новых заимствований, пришедших из европейских языков, где оно передается как э (эпитет, этнография, эвфемизм и т.п.). Некоторые слова существуют в русском языке в обоих вариантах – например, ритм и рифма; собственные имена: Теодор и Федор, Марта и Марфа; в название Фермопилы входит тот же корень, что в слове термометр (со значением «тепло») и т.п. Наконец, в русском языке имеются единичные слова, заимствованные из древнегреческого в его классическом варианте, – например, философский термин ойкумена (букв. «населенная»), восходящий к тому же слову
в старых заимствованиях, т.е. в словах, пришедших прямо из Византии, передается как е (епископ, епитимья, Евгения и т.п.) – в отличие от новых заимствований, пришедших из европейских языков, где оно передается как э (эпитет, этнография, эвфемизм и т.п.). Некоторые слова существуют в русском языке в обоих вариантах – например, ритм и рифма; собственные имена: Теодор и Федор, Марта и Марфа; в название Фермопилы входит тот же корень, что в слове термометр (со значением «тепло») и т.п. Наконец, в русском языке имеются единичные слова, заимствованные из древнегреческого в его классическом варианте, – например, философский термин ойкумена (букв. «населенная»), восходящий к тому же слову 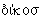 «дом», которое входит в слова экономика или экология.
«дом», которое входит в слова экономика или экология.
Особенно важную роль в русском языке играют заимствования из церковнославянского – близкородственного языка, на котором велось на Руси богослужение и который вплоть до середины 17 в. выполнял одновременно функцию русского литературного языка. Церковнославянизмы имеют особый статус в русском языке, так как они всегда воспринимались не как заимствование чужих слов, а скорее как восстановление более древней (= правильной) формы собственных русских слов, искаженных в результате неправильного употребления (исторически это не совсем так – хотя бы потому, что русский язык не является прямым потомком церковнославянского). Заимствования из церковнославянского происходили на протяжении почти всей письменной истории русского языка; в результате современный русский литературный язык оказался пронизан церковнославянизмами на всех уровнях – в фонетике, морфологии, лексике и синтаксисе. Поскольку церковнославянский был языком, употреблявшимся в «высоких» сферах и заимствования из него происходили в условиях функциональной и ценностной поляризации, характерной для языковой ситуации средневековой Руси (ситуации церковнославянско-русской диглоссии), большинство лексических церковнославянизмов принадлежит к разным вариантам «необиходного» языка – бюрократическому, книжному, поэтическому и т.д. (например, извещать, предвещать, надлежать, изъять, благодеяние, благосостояние, сосуществование, изгнание, долженствование и т.п.). Многие слова существуют в русском языке одновременно в двух вариантах – русском и церковнославянском, которые различаются между собой в фонетическом, семантическом и функционально-стилистическом отношениях, а именно, русское слово является нейтральным или «низким», а церковнославянское – «высоким» или нейтральным, например: город – град, берег – брег, житье – житие, обнять – объять, одёжа – одежда; в том числе, в именах собственных: Марья – Мария, Авдотья – Евдокия, Иван – Иоанн, Михайла – Михаил и т.п. В некоторых таких парах смысловое расхождение настолько велико, что ее члены воспринимаются как разные слова, и при этом ослабевает или даже вообще утрачивается соответствующая стилистическая дифференциация. Так устроена в русском языке, например, пара нёбо (русское) и небо (церк.-слав.), невежа и невежда, горожанин и гражданин, встать и восстать и т.п. Многие церковнославянизмы настолько глубоко укоренились, что рядовой носитель русского языка даже не подозревает об их заимствованном происхождении, – как, например, суффикс активного причастия -ущ/-ющ, -ащ/-ящ- (бегущий, свистящий и т.п.), вытеснивший соответствующий русский -уч/-юч, -ач/-яч (он сохранился, например, в словах могучий или горячий), а также, например, слова: благоразумный, благородный, могущество, имущество, преимущество, вероломный, первоначальный, предпочитать, гостеприимство, суеверие, беззаконие, прежде, пещера, помощь, вождь, юность, шлем и многие другие.
Для того чтобы стать заимствованием, пришедшее из чужого языка слово должно закрепиться в новом для себя языке, прочно войти в его словарный состав – как вошло в русский язык множество иностранных слов, таких, как хлеб, кружка, зонтик, магазин, кот, лошадь, собака, обезьяна, галстук, компот, трактор, танк, гавань, парус, икона, церковь, хор, спорт, рынок, базар, музыка, вокзал, машина, гол, изба, стекло, селедка, суп, огурец, помидор, котлета, картошка, кастрюля, тарелка, чай, сахар и т.д., многие из которых оказались настолько освоены русским языком, что только лингвисты знают об их иноязычном происхождении.
При заимствовании происходит адаптация слова к фонологической системе заимствующего языка, т.е. отсутствующие в ней звуки заменяются на наиболее близкие. Эта адаптация может происходить постепенно: иногда иноязычные слова в течение некоторого времени сохраняют в своем произношении звуки, в данном языке отсутствующие, – как, например, в заимствованных из «престижного» французского языка немецких словах Chance, Restorant (оба слова произносится «на французский манер» с носовым гласным). В заимствованном из того же французского русском слове жюри также произносится отсутствующий в русском языке звук – мягкое ж. В слове резюме перед конечным орфографическим е произносится согласный звук, промежуточный между твердым и мягким (так называемое 3-е смягчение). Еще недавно аналогичный звук произносился, например, в слове кафе; сейчас в этом слове, как и в многих других, пришедших из французского ранее (пенсне, кашне и т.п.), произносится твердый согласный. Таким образом происходит адаптация к фонологической системе заимствующего языка. Следующий этап этого процесса освоения иностранного слова состоит в замене твердых согласных перед орфографическим е на мягкие. С твердым согласным произносятся, например, слова декольте, фонема, тембр, темп и т.п.; с мягким – более «освоенные» русским языком слова тема, декрет, рейс, театр, телефон, сейф и т.п. Многие слова допускают колебания в произношении (т.е. находятся «на полпути»): компьютер, декан, майонез, тент и т.п.
Помимо фонетической, заимствованное слово подвергается также грамматической (морфологической) адаптации. Характер этой адаптации зависит от того, насколько внешний облик заимствованного слова соответствует морфологическим моделям заимствующего языка. Такие слова, как спорт или вокзал, легко вошли в русский язык, сразу попав в морфологический класс слов мужского рода 2-го склонения (куда относятся слова стол, дом и т.п.). Но, например, слово шампунь, попав в русский язык, не сразу приобрело устойчивую категорию рода, имея в качестве образца как слова мужского рода типа конь или огонь, так и слова женского рода типа дрянь или полынь; соответственно, формой твор. падежа было как шампунем, так и шампунью (впоследствии за этим словом закрепился мужской род). Именно в силу существования мощного механизма уподобления имеющимся моделям такое сопротивление со стороны русского языка встречает предписываемый нормой пресловутый мужской род слова кофе, которое автоматически уподобляется словам среднего рода – таким, как поле или горе.
Из потока иностранных слов, наводняющего язык в эпохи социальных потрясений и научно-технических революций, удерживается лишь некоторая часть. Процесс адаптации иноязычных слов, управляемый, как и все языковые процессы, прежде всего внутриязыковыми факторами, до какой-то степени может регулироваться и экстралингвистичесими силами – по крайней мере, возможности вмешательства человека и общества в этот процесс больше, чем в том случае, когда речь идет о фонетических и в особенности грамматических изменениях. В языковом сообществе всегда имеются консервативные силы, препятствующие проникновению в язык «засоряющих» его иностранных слов – как и вообще всем инновациям (изменениям в произношении, в том числе в ударении, сдвигам значения, проникновению в литературный язык жаргонизмов, профессионализмов и т.д.). Защита языка от иностранных слов имеет обычно еще и ярко выраженную идеологическую окраску. Однако, независимо от вызвавших их к жизни идеологических устремлений, такие консервативные силы объективно выполняют весьма важную общественную функцию поддержания естественного баланса между старым и новым, необходимого для нормального функционирования языка. Например, авторитет А.И.Солженицына, являющегося противником употребления иноязычных слов и предлагающего заменять их словами русского происхождения, возможно, окажется достаточно велик, чтобы оказать некоторое влияние на судьбу тех или иных иноязычных слов. Иногда языковое сообщество идет даже на административные меры. Так, во Франции в порядке борьбы, прежде всего, с англицизмами недавно был введен список из приблизительно 3000 слов, ограничивающий возможности употребления иностранных слов в создаваемых на французском языке текстах, предназначенных для средств массовой информации (телевидение, реклама и т.п.).



