Оконные функции в SQL — что это и зачем они нужны
Авторизуйтесь
Оконные функции в SQL — что это и зачем они нужны
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
Примечание Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010: 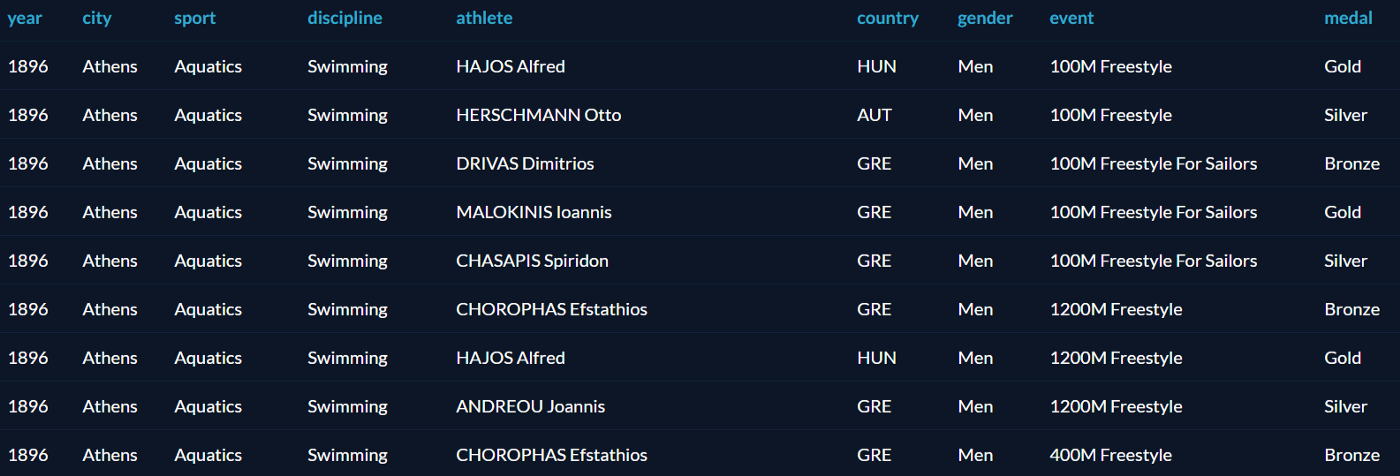
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
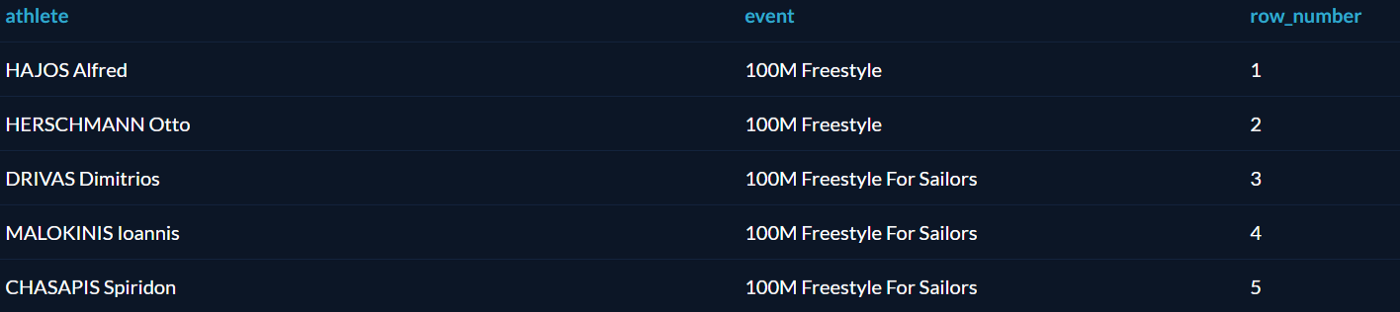
Каждая пара «спортсмен — вид спорта» получила номер, причём к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:

PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
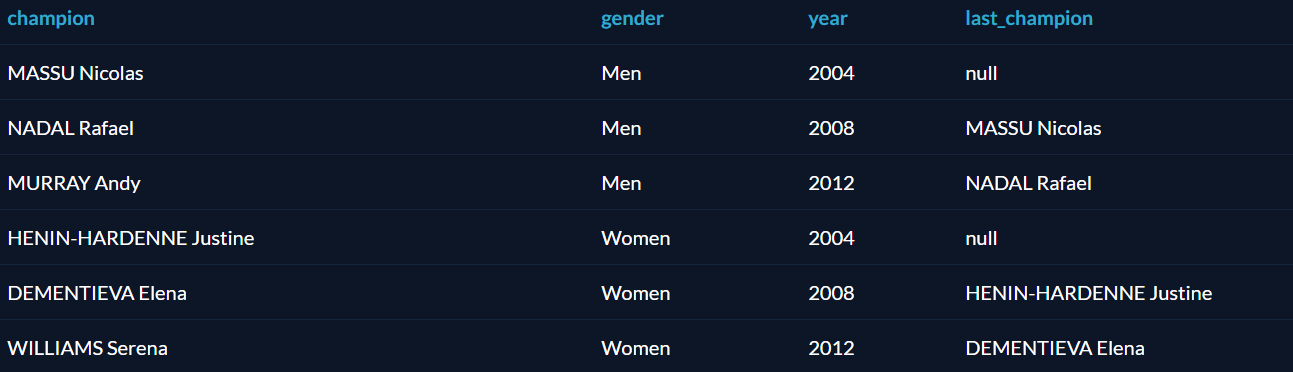
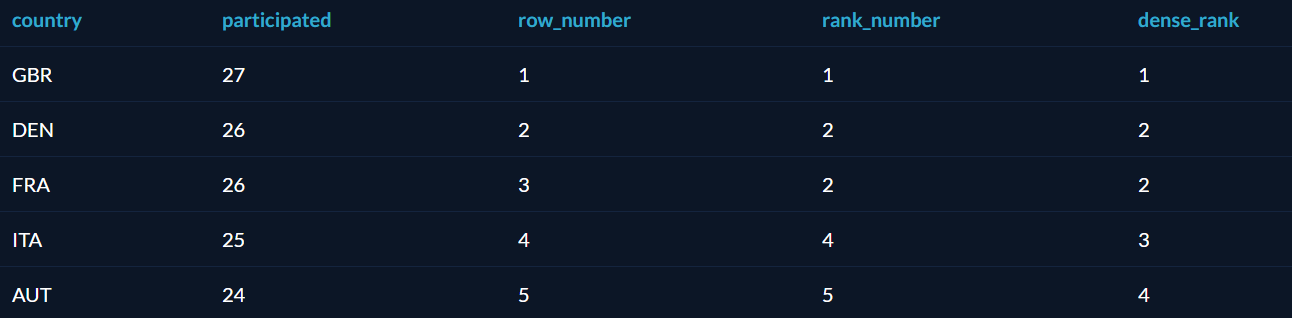
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
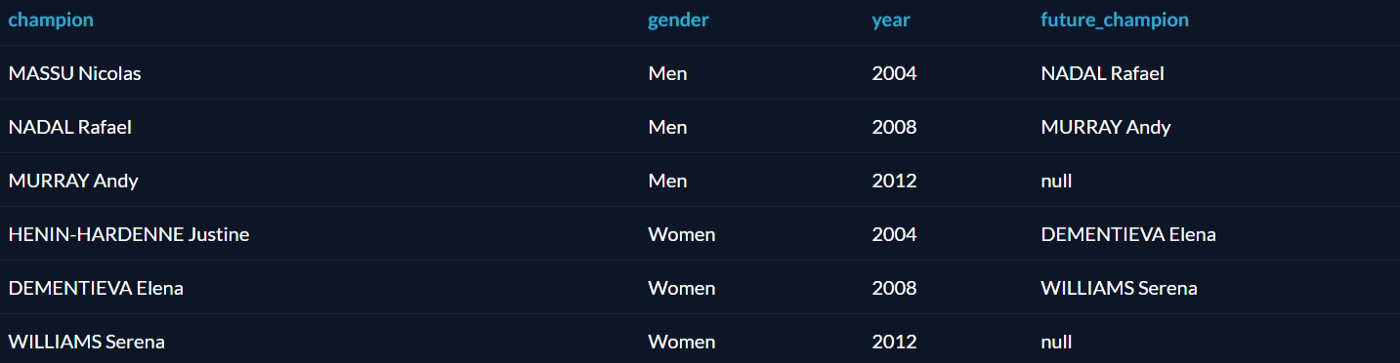
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.
Учимся применять оконные функции

Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы
У вас может возникнуть вопрос – «Что значит оконные?»
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.
Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:

Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:

Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
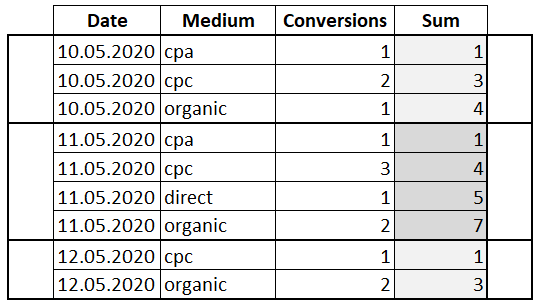
К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
Разберем на примере:
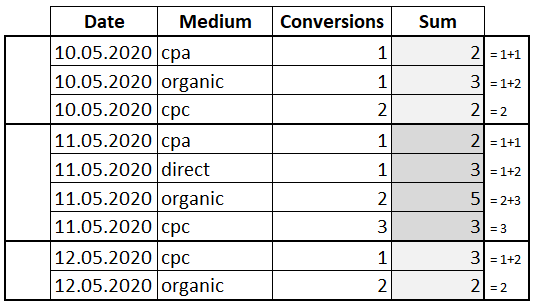
В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
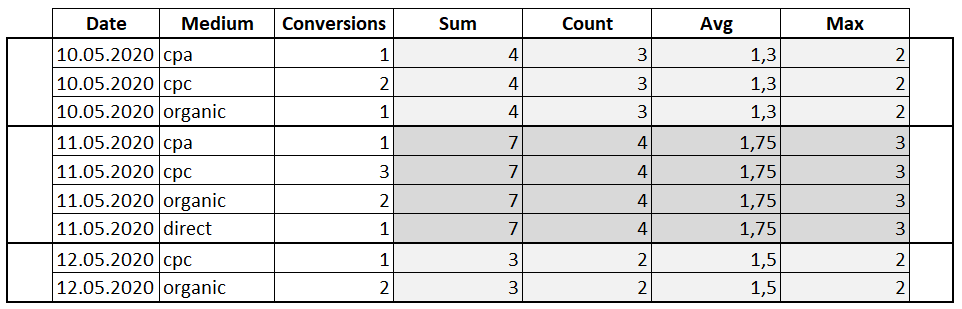
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
Пример использования агрегатных функций с оконной инструкцией OVER:
Ранжирующие функции
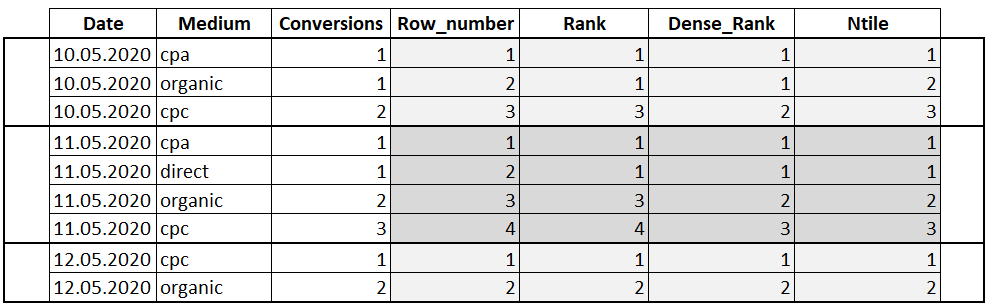
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
Функции смещения
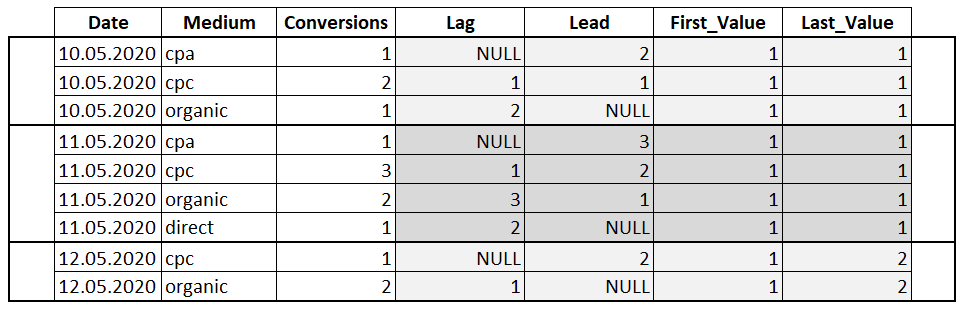
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.

Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
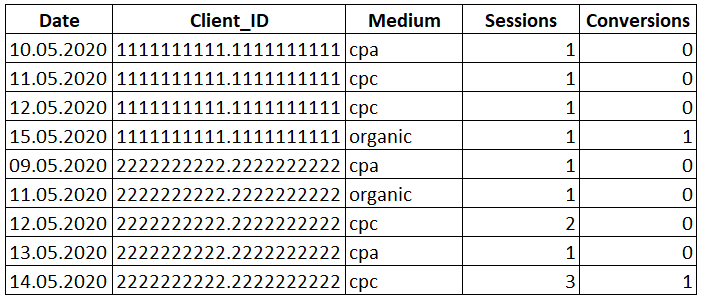
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.
Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
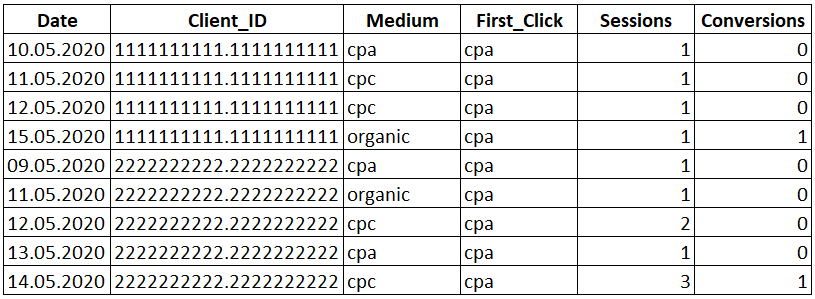
Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.

С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
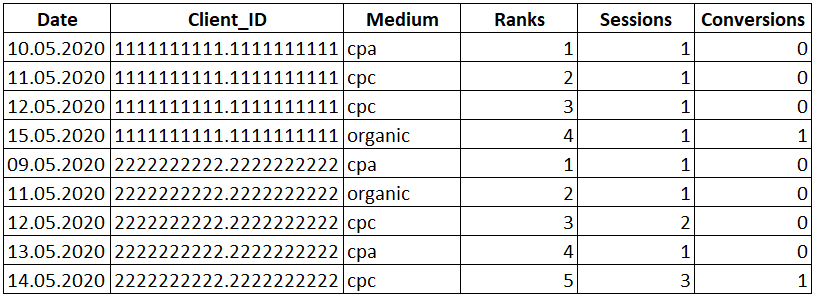
Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.

Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
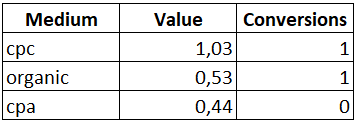
Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Как посчитать всё на свете одним SQL-запросом. Оконные функции PostgreSQL

Я с удивлением обнаружил, что многие разработчики, даже давно использующие postgresql, не понимают оконные функции, считая их какой-то особой магией для избранных. Ну или в лучшем случае «копипастят» со StackOverflow выражения типа «row_number() OVER ()», не вдаваясь в детали. А ведь оконные функции — полезнейший функционал PostgreSQL.
Попробую по-простому объяснить, как можно их использовать.
Для начала хочу сразу пояснить, что оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Т.е. для простоты понимания можно считать, что postgres сначала выполняет весь запрос (кроме сортировки и limit), а потом только просчитывает оконные выражения.
Синтаксис примерно такой:
Окно — это некоторое выражение, описывающее набор строк, которые будет обрабатывать функция и порядок этой обработки.
Причем окно может быть просто задано пустыми скобками (), т.е. окном являются все строки результата запроса.
Например, в этом селекте к обычным полям id, header и score просто добавится нумерация строк.
В оконное выражение можно добавить ORDER BY, тогда можно изменить порядок обработки.
Обратите внимание, что я добавил еще и в конце всего запоса ORDER BY id, при этом рейтинг посчитан все равно верно. Т.е. посгрес просто отсортировал результат вместе с результатом работы оконной функции, один order ничуть не мешает другому.
Дальше — больше. В оконное выражение можно добавить слово PARTITION BY [expression],
например row_number() OVER (PARTITION BY section), тогда подсчет будет идти в каждой группе отдельно:
Если не указывать партицию, то партицией является весь запрос.
Тут сразу надо немного сказать о функциях, которые можно использовать, так как есть очень важный нюанс.
В качестве функции можно использовать, так сказать, истинные оконные функции из мануала — это row_number(), rank(), lead() и т.д., а можно использовать функции-агрегаты, такие как: sum(), count() и т.д. Так вот, это важно, агрегатные функции работают слегка по-другому: если не задан ORDER BY в окне, идет подсчет по всей партиции один раз, и результат пишется во все строки (одинаков для всех строк партиции). Если же ORDER BY задан, то подсчет в каждой строке идет от начала партиции до этой строки.
Давайте посмотрим это на примере. Например, у нас есть некая (сферическая в вакууме) таблица пополнений балансов.
и мы хотим узнать заодно, как менялся остаток на балансе при этом:
Т.е. для каждой строки идет подсчет в отдельном фрейме. В данном случае фрейм — это набор строк от начала до текущей строки (если было бы PARTITION BY, то от начала партиции).
Если же мы для агрегатной фунции sum не будем использовать ORDER BY в окне, тогда мы просто посчитаем общую сумму и покажем её во всех строках. Т.е. фреймом для каждой из строк будет весь набор строк
от начала до конца партиции.
Вот такая особенность агрегатных функций, если их использовать как оконные. На мой взгляд, это довольно-таки странный, интуитивно неочевидный момент SQL-стандарта.
Оконные функции можно использовать сразу по несколько штук, они друг другу ничуть не мешают, чтобы вы там в них не написали.
Если у вас много одинаковых выражений после OVER, то можно дать им имя и вынести отдельно с ключевым словом WINDOW, чтобы избежать дублирования кода. Вот пример из мануала:
Здесь w после слова OVER идет без уже скобок.
Результат работы оконной функции невозможно отфильтровать в запросе с помощью WHERE, потому что оконные фунции выполняются после всей фильтрации и группировки, т.е. с тем, что получилось. Поэтому чтобы выбрать, например, топ 5 новостей в каждой группе, надо использовать подзапрос:
Еще пример для закрепления. Помимо row_number() есть несколько других функций. Например lag, которая ищет строку перед последней строкой фрейма. К примеру мы можем найти насколько очков новость отстает от предыдущей в рейтинге:
Прошу в коментариях накидать примеров, где особенно удобно применять оконные фунции. А также, какие с ними могут возникнуть проблемы, если таковые имеются.
Подписывайтесь на подкаст о разработке «Цинковый прод», где мы обсуждаем базы данных, языки программирования и всё на свете!
Группировки и оконные функции в Oracle
Привет, Хабр! В компании, где я работаю, часто проходят (за мат извините) митапы. На одном из них выступал мой коллега с докладом об оконных функциях и группировках Oracle. Эта тема показалась мне стоящей того, чтобы сделать о ней пост.

С самого начала хотелось бы уточнить, что в данном случае Oracle представлен как собирательный язык SQL. Группировки и методы их применения подходят ко всему семейству SQL (который понимается здесь как структурированный язык запросов) и применимы ко всем запросам с поправками на синтаксис каждого языка.
Всю необходимую информацию я постараюсь кратко и доступно объяснить в двух частях. Пост скорее будет полезен начинающим разработчикам. Кому интересно — добро пожаловать под кат.
Часть 1: предложения Order by, Group by, Having
Здесь мы поговорим о сортировке — Order by, группировке — Group by, фильтрации — Having и о плане запроса. Но обо всем по-порядку.
Order by
Оператор Order by выполняет сортировку выходных значений, т.е. сортирует извлекаемое значение по определенному столбцу. Сортировку также можно применять по псевдониму столбца, который определяется с помощью оператора.
Преимущество Order by в том, что его можно применять и к числовым, и к строковым столбцам. Строковые столбцы обычно сортируются по алфавиту.
Сортировка по возрастанию применяется по умолчанию. Если хотите отсортировать столбцы по убыванию — используйте дополнительный оператор DESC.
SELECT column1, column2, … (указывает на название)
FROM table_name
ORDER BY column1, column2… ASC|DESC;
Давайте все рассмотрим на примерах: 
В первой таблице мы получаем все данные и сортируем их по возрастанию по столбцу ID.
Во второй мы также получаем все данные. Сортируем по столбцу ID по убыванию, используя ключевое слово DESC.
В третьей таблице используется несколько полей для сортировки. Сначала идет сортировка по отделу. При равенстве первого оператора для полей с одинаковым отделом применяется второе условие сортировки; в нашем случае — это зарплата.
Все довольно просто. Мы можем задать более одного условия сортировки, что позволяет более грамотно сортировать выходные списки.
Group by
В SQL оператор Group by собирает данные, полученные из базы данных в определенных группах. Группировка разделяет все данные на логические наборы, что дает возможность выполнять статистические вычисления отдельно в каждой группе.
Этот оператор используется для объединения результатов выборки по одному или нескольким столбцам. После группировки будет только одна запись для каждого значения, использованного в столбце.
С использованием оператора SQL Group by тесно связано использование агрегатных функций и оператор SQL Having. Агрегатная функция в SQL — это функция, возвращающая какое-либо одно значение по набору значений столбца. Например: COUNT(), MIN(), MAX(), AVG(), SUM()
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
Group by стоит после условного оператора WHERE в запросе SELECT. По желанию можно использовать ORDER BY, чтобы отсортировать выходные значения.
Итак, опираясь на таблицу из предыдущего примера, нам нужно найти максимальную зарплату сотрудников каждого отдела. В итоговой выборке должно получиться название отдела и максимальная зарплата.
Решение 1 (без использования группировки):
Решение 2 (с использованием группировки):
В первом примере решаем задачу без использования группировки, но с использованием подселекта, т.е. в один селект вкладываем второй. Во втором решении используем группировку.
Второй пример вышел короче и читабельнее, хотя выполняет такие же функции, что и первый.
Как у нас работает Group by: сначала разбивает два отдела на группы qa и dev. Потом для каждого из них ищет максимальную зарплату.
Having
Having это инструмент фильтрации. Он указывает на результат выполнения агрегатных функций. Предложение Having используется в SQL там, где нельзя применить WHERE.
Если предложение WHERE определяет предикат для фильтрации строк, то Having используется после группировки для определения логичного предиката, фильтрующего группу по значениям агрегатных функций. Предложение необходимо для проверки значений, полученных при помощи агрегатных функций из групп строк.
Сначала мы выводим отделы со средней зарплатой больше 4000. Затем выводим максимальную зарплату с применением фильтрации.
Решение 1 (без использования GROUP BY и HAVING):
Решение 2 (с использованием GROUP BY и HAVING):
В первом примере используется два подселекта: один для нахождения максимальной зарплаты, другой для фильтрации средней зарплаты. Второй пример, опять же, вышел намного проще и лаконичнее.
План запроса
Нередко бывают ситуации, когда запрос работает долго, потребляя значительные ресурсы памяти и дисков. Чтобы понять, почему запрос работает долго и неэффективно, мы можем посмотреть план запроса.
План запроса — это предполагаемый план выполнения запроса, т.е. как СУБД будет его выполнять. СУБД распишет все операции, которые будут выполняться в рамках подзапроса. Проанализировав все, мы сможем понять, где в запросе слабые места и с помощью плана запроса сможем оптимизировать их.
Исполнение любого SQL предложения в Oracle извлекает так называемый “план исполнения”. Этот план исполнения запроса является описанием того, как Oracle будет осуществлять выборку данных, согласно исполняемому SQL предложению. План представляет собой дерево, которое содержит порядок шагов и связь между ними.
К средствам, позволяющим получить предполагаемый план выполнения запроса, относятся Toad, SQL Navigator, PL/SQL Developer и др. Они выдают ряд показателей ресурсоемкости запроса, среди которых основными являются: cost — стоимость выполнения и cardinality (или rows) — кардинальность (или количество строк).
Чем больше значение этих показателей, тем менее эффективен запрос.
Ниже можно увидеть анализ плана запроса. В первом решении используется подселект, во втором — группировка. Обратите внимание, что в первом решении обработано 22 строки, во втором — 15.
Анализ плана запроса:
Ещё один анализ плана запроса, в котором применяется два подселекта:
Этот пример приведен как вариант нерационального использования средств SQL и я не рекомендую вам его использовать в своих запросах.
Все перечисленные выше функции упростят вам жизнь при написании запросов и повысят качество и читабельность вашего кода.
Часть 2: Оконные функции
Оконные функции появились ещё в Microsoft SQL Server 2005. Они осуществляют вычисления в заданном диапазоне строк внутри предложения Select. Если говорить кратко, то “окно” — это набор строк, в рамках которого происходит вычисление. “Окно” позволяет уменьшить данные и более качественно их обработать. Такая функция позволяет разбивать весь набор данных на окна.
Оконные функции обладают огромным преимуществом. Нет необходимости формировать набор данных для расчетов, что позволяет сохранить все строки набора с их уникальными ID. Результат работы оконных функций добавляется к результатирующей выборке в еще одно поле.
SELECT column_name(s)
Агрегирующая функция (столбец для вычислений)
OVER ([PARTITION BY столбец для группировки]
FROM table_name
[ORDER BY столбец для сортировки]
[ROWS или RANGE выражение для ограничения строк в пределах группы])
OVER PARTITION BY — это свойство для задания размеров окна. Здесь можно указывать дополнительную информацию, давать служебные команды, например добавить номер строки. Синтаксис оконной функции вписывается прямо в выборку столбцов.
Давайте рассмотрим все на примере: в нашу таблицу добавился еще один отдел, теперь в таблице 15 строк. Мы попытаемся вывести работников, их з/п, а также максимальную з/п организации.
В первом поле мы берем имя, во втором — зарплату. Дальше мы применяем оконную функцию over(). Используем её для получения максимальной зарплаты по всей организации, так как не указаны размеры “окна”. Over() с пустыми скобками применяется для всей выборки. Поэтому везде максимальная зарплата — 10 000. Результат действия оконной функции добавляется к каждой строчке.
Если убрать из четвертой строки запроса упоминание оконной функции, т.е. остается только max (salary), то запрос не сработает. Максимальную зарплату просто не удалось бы посчитать. Так как данные обрабатывались бы построчно, и на момент вызова max (salary) было бы только одно число текущей строки, т.е. текущего работника. Вот тут и можно заметить преимущество оконной функции. В момент вызова она работает со всем окном и со всеми доступными данными.
Давайте рассмотрим еще один пример, где нужно вывести максимальную з/п каждого отдела:
Фактически мы задаем рамки для “окна”, разбивая его на отделы. В качестве ранжирующего примера мы указываем department. У нас есть три отдела: dev, qa и sales.
“Окно” находит максимальную зарплату для каждого отдела. В результате выборки мы видим, что оно нашло максимальную зарплату сначала для dev, затем для qa, потом для sales. Как уже упоминалось выше, результат оконной функции записывается в результат выборки каждой строки.
В предыдущем примере в скобках после over не было указано. Здесь мы использовали PARTITION BY, которое позволило задать размеры нашего окна. Здесь можно указывать какую-то доп информацию, передавать служебные команды, например, номер строки.
Заключение
SQL не так прост, как кажется на первый взгляд. Все описанное выше — это базовые возможности оконных функций. С их помощью можно “упростить” наши запросы. Но в них скрыто намного больше потенциала: есть служебные операторы (например ROWS или RANGE), которые можно комбинировать, добавляя больше функциональности запросам.
Надеюсь, пост был полезен для всех интересующихся данной темой.



