Предметные и информационные модели
Все модели можно разбить на два больших класса: модели предметные (материальные) и модели информационные.

Предметные модели воспроизводят геометрические, физические и другие свойства объектов в материальной форме (глобус, анатомические муляжи, модели кристаллических решеток, макеты зданий и сооружений и др.).
Информационные модели представляют объекты и процессы в образной или знаковой форме.
Образные модели (рисунки, фотографии и др.) представляют собой зрительные образы объектов, зафиксированные на каком-либо носителе информации (бумаге, фото- и кинопленке и др.). Широко используются образные информационные модели в образовании (учебные плакаты по различным предметам) и науках, где требуется классификация объектов по их внешним признакам (в ботанике, биологии, палеонтологии и др.).
Знаковые информационные модели строятся с использованием различных языков (знаковых систем). Знаковая информационная модель может быть представлена в форме текста (например, программы на языке программирования), формулы (например, второго закона Ньютона F = ma), таблицы (например, периодической таблицы элементов Д. И. Менделеева) и так далее.
Типы информационных моделей :
Табличные – объекты и их свойства представлены в виде списка, а их значения размещаются в ячейках прямоугольной формы. Перечень однотипных объектов размещен в первом столбце (или строке), а значения их свойств размещаются в следующих столбцах (или строках)
Иерархические – объекты распределены по уровням. Каждый элемент высокого уровня состоит из элементов нижнего уровня, а элемент нижнего уровня может входить в состав только одного элемента более высокого уровня
Сетевые – применяют для отражения систем, в которых связи между элементами имеют сложную структуру
По степени формализацииинформационные модели бывают образно-знаковые и знаковые. Напримеры:
Образно-знаковые модели :
Геометрические (рисунок, пиктограмма, чертеж, карта, план, объемное изображение)
Структурные (таблица, граф, схема, диаграмма)
Словесные (описание естественными языками)
Алгоритмические (нумерованный список, пошаговое перечисление, блок-схема)
Знаковые модели:
Математические – представлены матем.формулами, отображающими связь параметров
Специальные – представлены на спец. языках (ноты, хим.формулы)
Формализация.
Процесс построения информационных моделей с помощью формальных языков называется формализацией.
Естественные языки используются для создания описательных информационных моделей. В истории науки известны многочисленные описательные информационные модели. Например, гелиоцентрическая модель мира, которую предложил Коперник, формулировалась следующим образом:
С помощью формальных языков строятся формальные информационные модели (математические, логические и др.). Одним из наиболее широко используемых формальных языков является математика. Модели, построенные с использованием математических понятий и формул, называются математическими моделями. Язык математики является совокупностью формальных языков.
Язык алгебры позволяет формализовать функциональные зависимости между величинами. Так, Ньютон формализовал гелиоцентрическую систему мира, открыв законы механики и закон всемирного тяготения и записав их в виде алгебраических функциональных зависимостей. В школьном курсе физики рассматривается много разнообразных функциональных зависимостей, выраженных на языке алгебры, которые представляют собой математические модели изучаемых явлений или процессов.
 — матем. запись закона всемирного тяготения
— матем. запись закона всемирного тяготения
Язык алгебры логики (алгебры высказываний) позволяет строить формальные логические модели. С помощью алгебры высказываний можно формализовать (записать в виде логических выражений) простые и сложные высказывания, выраженные на естественном языке. Построение логических моделей позволяет решать логические задачи, строить логические модели устройств компьютера (сумматора, триггера) и так далее.
В процессе познания окружающего мира человечество постоянно использует моделирование и формализацию. При изучении нового объекта сначала обычно строится его описательная информационная модель на естественном языке, затем она формализуется, то есть выражается с использованием формальных языков (математики, логики и др.).
Визуализация
В процессе исследования формальных моделей часто производится их визуализация. Для визуализации алгоритмов используются блок-схемы: пространственных соотношений между объектами — чертежи, моделей электрических цепей — электрические схемы, логических моделей устройств — логические схемы и так далее.
Что такое предметные модели
Понятие модели. Информационная модель. Виды информационных моделей.
Человечество в своей деятельности (научной, образовательной, технологической, художественной) постоянно создает и использует модели окружающего мира.
Модели позволяют представить в наглядной форме объекты и процессы, недоступные для непосредственного восприятия (очень большие или очень маленькие объекты, очень быстрые или очень медленные процессы и др.).
Наглядные модели часто используются в процессе обучения. В курсе географии первые представления о нашей планете Земля мы получаем, изучая ее модель — глобус, в курсе физики изучаем работу двигателя внутреннего сгорания по его модели, в химии при изучении строения вещества используем модели молекул и кристаллических решеток, в биологии изучаем строение человека по анатомическим муляжам и др.
Модели играют чрезвычайно важную роль в проектировании и создании различных технических устройств, машин и механизмов, зданий, электрических цепей и т. д. Без предварительного создания чертежа невозможно изготовить даже простую деталь, не говоря уже о сложном механизме.
Развитие науки невозможно без создания теоретических моделей (теорий, законов, гипотез и пр.), отражающих строение, свойства и поведение реальных объектов.
Все художественное творчество фактически является процессом создания моделей. Более того, практически любое литературное произведение может рассматриваться как модель реальной человеческой жизни. Моделями в художественной форме отражающими реальную действительность, являются также живописные полотна, скульптуры, театральные постановки и пр.
Моделирование — это метод познания, состоящий в создании и исследовании моделей.
Модель — это некий новый объект, который отражает существенные особенности изучаемого объекта, явления или процесса. Один и тот же объект может иметь множество моделей, а разные объекты могут описываться одной моделью. Так, в механике различные материальные тела (от планеты до песчинки) могут рассматриваться как материальные точки, т.е. объекты разные – модель одна.
Предметные и информационные модели
Все модели можно разбить на два больших класса: модели предметные (материальные) и модели информационные.
Предметные модели воспроизводят геометрические, физические и другие свойства объектов в материальной форме (глобус, анатомические муляжи, модели кристаллических решеток, макеты зданий и сооружений и др.).
Информационные модели представляют объекты и процессы в образной или знаковой форме.
Образные модели (рисунки, фотографии и др.) представляют собой зрительные образы объектов, зафиксированные на каком-либо носителе информации (бумаге, фото- и кинопленке и др.). Широко используются образные информационные модели в образовании (учебные плакаты по различным предметам) и науках, где требуется классификация объектов по их внешним признакам (в ботанике, биологии, палеонтологии и др.).
Знаковые информационные модели строятся с использованием различных языков (знаковых систем). Знаковая информационная модель может быть представлена в форме текста (например, программы на языке программирования), формулы (например, второго закона Ньютона F = ma), таблицы (например, периодической таблицы элементов Д. И. Менделеева) и так далее.
Иногда при построении знаковых информационных моделей используются одновременно несколько различных языков. Примерами таких моделей могут служить географические карты, графики, диаграммы и пр. Во всех этих моделях используются одновременно как язык графических элементов, так и символьный язык.
На протяжении своей истории человечество использовало различные способы и инструменты для создания информационных моделей. Так, первые информационные модели создавались в форме наскальных рисунков, в настоящее же время информационные модели обычно строятся и исследуются с использованием современных компьютерных технологий.
Процесс построения информационных моделей с помощью формальных языков называется формализацией.
Естественные языки используются для создания описательных информационных моделей. В истории науки известны многочисленные описательные информационные модели. Например, гелиоцентрическая модель мира, которую предложил Коперник, формулировалась следующим образом:
Земля вращается вокруг своей оси и вокруг Солнца;
орбиты всех планет проходят вокруг Солнца.
С помощью формальных языков строятся формальные информационные модели (математические, логические и др.). Одним из наиболее широко используемых формальных языков является математика. Модели, построенные с использованием математических понятий и формул, называются математическими моделями. Язык математики является совокупностью формальных языков.
Визуализация
В процессе исследования формальных моделей часто производится их визуализация. Для визуализации алгоритмов используются блок-схемы: пространственных соотношений между объектами — чертежи, моделей электрических цепей — электрические схемы, логических моделей устройств — логические схемы и так далее.
Так при визуализации формальных физических моделей с помощью анимации может отображаться динамика процесса, производиться построение графиков изменения физических величин и так далее. Визуальные модели обычно являются интерактивными, то есть исследователь может менять начальные условия и параметры протекания процессов и наблюдать изменения в поведении модели.
Основные этапы разработки и исследования моделей на компьютере
Использование компьютера для исследования информационных моделей различных объектов и систем позволяет изучить их изменения в зависимости от значения тех или иных параметров. Компьютерное моделирование является одним из эффективных методов изучения сложных систем. Часто компьютерные модели проще и удобнее исследовать, они позволяют проводить вычислительные эксперименты, реальная постановка которых затруднена или может дать непредсказуемый результат.
Процесс разработки моделей и их исследования на компьютере можно разделить на несколько основных этапов:
Построение описательной информационной модели (выделение существенных параметров).
Создание формализованной модели (запись формул).
Построение компьютерной модели.
Анализ полученных результатов и корректировка исследуемой модели.
На первом этапе исследования объекта или процесса обычно строится описательная информационная модель. Такая модель выделяет существенные с точки зрения целей проводимого исследования параметры объекта, а несущественными параметрами пренебрегает.
На втором этапе создается формализованная модель, то есть описательная информационная модель записывается с помощью какого-либо формального языка. В такой модели с помощью формул, уравнений, неравенств и пр. фиксируются формальные соотношения между начальными и конечными значениями свойств объектов, а также накладываются ограничения на допустимые значения этих свойств.
Однако далеко не всегда удается найти формулы явно выражающие искомые величины через исходные данные. В таких случаях используются приближенные математические методы, позволяющие получать результаты с заданной точностью.
На третьем этапе необходимо формализованную информационную модель преобразовать в компьютерную на понятном для компьютера языке. Существуют два принципиально различных пути построения компьютерной модели:
1) создание алгоритма решения задачи и его кодирование на одном из языков программирования;
2) формирование компьютерной модели с использованием одного из приложений (электронных таблиц, СУБД и т. д.).
В процессе создания компьютерной модели полезно разработать удобный графический интерфейс, который позволит визуализировать формальную модель, а также реализовать интерактивный диалог человека с компьютером на этапе исследования модели.
Четвертый этап исследования информационной модели состоит в проведении компьютерного эксперимента. Если компьютерная модель существует в виде программы на одном из языков программирования, ее нужно запустить на выполнение и получить результаты.
Если компьютерная модель исследуется в приложении, например в электронных таблицах, можно провести сортировку или поиск данных, построить диаграмму или график и так далее.
Пятый этап состоит в анализе полученных результатов и корректировке исследуемой модели. В случае различия результатов, полученных при исследовании информационной модели, с измеряемыми параметрами реальных объектов можно сделать вывод, что на предыдущих этапах построения модели были допущены ошибки или неточности. Например, при построении описательной качественной модели могут быть неправильно отобраны существенные свойства объектов, в процессе формализации могут быть допущены ошибки в формулах и так далее. В этих случаях необходимо провести корректировку модели, причем уточнение модели может проводиться многократно, пока анализ результатов не покажет их соответствие изучаемому объекту.
Что же такое «Модель предметной области»?
Сегодня зашел в канал #school в русскоязычном GoCommunity в Slack и обнаружил там один интересный диалог. Данный диалог навел меня на некоторые мысли относительно того, как коллеги интерпретируют понятие “модель предметной области (домена)”.
Как оказалось, существует достаточно много неверных или не совсем точных, а иногда совсем неточных интерпретаций данного термина, что по сути искажает его. Вокруг этого диалога и родилась идея данной статьи. Подробности под катом.
Вопрос об архитектуре.
Подскажите как правильно архитектуру делать, вот допустим я сделал табличку в базе, попросил реформ сгенерировать мне реформ модель, могу я в своем приложении эту модель как домен модель использовать, или лучше создать свою домен модель и сделать адаптер который будет выдавать мне именно мою доменнную модель создавая ее из модели реформа?”
Самое простое — архитектура с анемичной моделью. это когда модель DB = модель домена = модель ответов API. rich domain model — редкий зверь и обычно вырождается в анемичую. Под анемичной подразумевается DTO структура. обычный набор аттрибутов(полей) без методов. Логика вырождается в набор функций, оперирующих такими dto. Фаулер временами считает такую архитектуру антипаттерном. Но потом хорошим микросервисным решением, и.т.д
Прочитав это, я вдруг понял, почему вокруг так много споров в организации слоя бизнес-логики, и почему у многих не получается применять на практике такие подходы как Clean Architecture и т.п. Ведь что значит “архитектура с анемичной моделью”?
Если вы попробуете найти такое понятие в сети, вы его скорее всего не обнаружите, потому что такой архитектуры нет. Есть понятие “AnemicDomainModel”, и если обратится к тому же Фаулеру, окажется, что это просто процедурный подход к созданию архитектуры приложений (привет Fortran, ALGOL, COBOL, BASIC, Pascal и C). Это в сущности и есть то, что автор ответа называет “архитектура с анемичной моделью”.
Модель предметной области (домена).
Далее возникает следующий вопрос, а является ли “анемичная модель” моделью по сути? Я думаю, нет, и вот почему.
Правда заключается в том, что модель предметной области — это не модель данных, в отличие от “модели БД” или “модели ответа API”. Модель предметной области, имеет вполне конкретное определение. Тем более неправильно мешать ее с моделью БД, которая по сути является моделью данных.
Когда речь идет о модели предметной области, имеется ввиду именно концептуальная модель. А это совокупность понятий предметной области и отношений между ними (т.е. совокупность поведения и данных). В целом главной чертой, отличающей одну модель предметной области от другой, является именно набор бизнес-правил.
Да, концептуальная модель может работать с данными, которые представлены в разном виде (данные из БД или ответы API), но суть от этого не изменится, первостепенно поведение. Мы передаем на вход модели данные, чтобы получить определенный результат на выходе. Этот результат достигается с помощью реализации бизнес-логики внутри модели (другими словами применения бизнес-правил). Я нахожу здесь аналогию с математическими моделями и моделированием технологических процессов (привет студенческие годы).
Чем чревата подмена понятий?
Когда вы называете структуры данных “моделью домена”, вы вольно или нет подменяете понятия. Это приводит к тому, что зачастую бизнес-логика размазывается по всему приложению. На самом деле, моделью предметной области в таком случае является тот самый размазанный набор функций, оперирующий структурами данных.
В случае разработки средних и больших приложений, непонимание или смешивание этих понятий, как правило, приводит к ряду проблем и вопросов уже на старте разработки системы, не говоря уже о долгосрочной поддержке. Среди них, к примеру, встречаются такие распространенные вопросы как:
Если вернуться к тому, что диалог о моделях предметной области возник в Go комьюнити, я бы сказал так. В силу того, что Go является мультипарадигменным языком и поддерживает ряд наиболее удачных ООП концепций (Композиция, Интерфейсы), не стоит игнорировать их при моделировании предметной области и писать код исключительно в процедурном стиле, как будто вы работаете с BASIC или С.
Правильно интерпретируя понятие “модель предметной области” становится вполне очевидно, почему зачастую принято выделять бизнес-логику в отдельный слой. Так же становится понятно, каким образом можно выделить этот самый слой и реализовать Clean Architecture или любую другую ее вариацию. Выделяя отдельный слой, мы по сути создаем библиотеку, которая реализует концептуальную модель в виде программного кода. Как результат, бизнес-логика становится инкапуслирована в рамках этой библиотеки, а не размазана по всему приложению (как при чистом процедурном подходе).
Конечно, понимание этих концепций не избавит вас от ошибок при проектировании, не сделает из вас идеального разработчика или системного архитектора и не научит делать все правильно с первого раза. Здесь важна не только теория, но и практика. Тем не менее, как только вы правильно поймете концепции и интерпретируете определения, многие вещи станут для вас на порядок очевиднее и проще.
Подведем итоги.
Всем добра! Спасибо за внимание.
PS. Буду рад выслушать конструктивную критику, а так же ваше видение того, что такое «модель предметной области». Ссылки на первоисточники приветствуются.
UPD: Статья не является попыткой вольной интерпретации понятия «модель предметной области» и вкладывания в это понятие одному мне известного смысла. Я хочу донести вот что: Смысл в данное понятие давно вложен, и оно подробно описано в книгах и статьях по ComputerScience. Статья является попыткой донести до коллег по цеху важность правильного восприятия этих самых концепций не искажая их смысл (Это важно, потому что на практике позволит писать более осмысленный код).
UPD2: Я не enterprise-архитектор теоретик. Я такой же практикующий разработчик как и вы. Я пишу код каждый день и рассуждаю об этих вещах с целью сделать свой код лучше, а заказчиков счастливее. Если на ваш взгляд, я исказил первоначальный смысл, поделитесь ссылками на первоисточники а так же укажите, где я выразился некорректно, так чтобы я смог это исправить.
UPD3: Т.к. многие интерпретируют термин «предметная область» по разному, привожу некоторые примеры предметных областей, чтобы не было путаницы и подмены понятий. Предметная область всегда зависит от того, какую проблему вы решаете с помощью разработки приложения:
Уроки проектирования. Предметная область и ее математические модели
“Многого можно добиться добрым словом. Но гораздо большего можно добиться добрым словом и пистолетом”( Аль Капоне). “Но иногда помогает только пистолет”( не Аль Капоне).
Чтобы не быть обвиненным в пропаганде вооруженного бандитизма, сразу поясню, что под пистолетом здесь понимается математическая модель предметной области. Поэтому афоризм трансформируется в “Многого можно добиться словами. Но гораздо большего можно добиться словами и математикой. А иногда помогает только математика”. Теряется острота, но правда ведь остается.
История одного проекта
«Это было недавно, это было давно»
Начинающим программистом я устроился в ВЦ банка и столкнулся со знаменитой, по тем временам, задачей “Операционный день банка”. Фактически это бухучет, который обязательно должен завершиться выдачей правильных бухгалтерских регистров к концу дня. Говоря более высоким стилем, это система реального времени с квантом реальности в одни сутки.Начинаю знакомиться с предметной областью. Иду в отдел постановок, в котором сидят женщины выпускницы института народного хозяйства – нархоза. Пытаюсь выяснить, что такое дебет и кредит. У каждой дамы свое мнение. Одно из них такое: мне показывают какой-то первичный документ, со структурой “самолетик” – так мне это назвали. Голова самолетика – входящее сальдо счета, левое крыло – это дебет, правое — кредит, хвост — исходящее сальдо. Я впал в ступор от таких объяснений. Пошел в библиотеку и после нескольких сумбурных книг типа “Учет и операционная техника в банках ” наткнулся на книгу “Теория бухгалтерского учета”. Автор – Палий. Он дал полуфилософское изложение учета, начиная от Луки Паччоли. Мне изложение весьма понравилось и я кое-что узнал о бухучете. Меня поразило, что о таких приземленных вещах как бухучет, можно говорить чуть ли не философски.
Потом, долго работая в ВЦ банка, участвуя во многих предпроектных обследованиях я пришел к выводу, что от конечных пользователей проку мало и что нужно крутиться самому, рыться в библиотеках(интернета еще не было) и самому определять, что пользователю надо и потом его убеждать в этом. Хотя до последнего я не дотягивал. Работаю я с таким представлением о пользователях и вдруг такой случай. Банкир, довольно высокого ранга, выходит в наш ВЦ со своей постановкой по обработке показателей всех строек БССР — постановка ТЭПС(Технико-Экономические Показатели Строек). Постановка сверхсложная с лесом математических формул в которых так и мелькают трехэтажные индексы. Мой шеф с ней не разобрался и положил её под сукно. И тут меняется руководство ВЦ. Моего шефа, подсуконника, увольняют. Новый начальник ВЦ сразу обратился к упомянутой постановке. Несколько месяцев изучаем постановку и, оказывается, что все можно представить в понятном виде и без леса трехэтажных формул. Но для внедрения нужен, как теперь говорят, реинжиниринг бизнеса. У нас он свелся к тому, что появились новые входные документы, новая бизнес-операция по заполнению этих документов, операция-запрос к БД, анализ полученных результатов. Для двух последних выделялись из штата бизнес-аналитики. Существующие формы документов(план финансирования, смета, титульный список и т.д.) были не только не машиночитаемы, но и человеку вводить с них данные в компьютер было сверхнеудобно, поэтому мы предложили ввести новые, промежуточные формы документов, с которых было удобно вводить данные. Но эти новые документы нужно было заполнять со старых. Со всеми требуемыми нововведениями выходим на руководство.
Руководство банком ознакомилось с ними, согласилось с ними, придало им законность приказом по банку и работа закипела. Внизу в филиалах и отделениях нас все проклинали за огромную дополнительную работу по заполнению входных документов. Дело в том, что низ делал черновую работу по заполнению входных документов, а результатами обработки этих данных не пользовались: компьютер стоял в столице в ВЦ головного аппарата. Вот этот аппарат и занимался аналитикой, сам не занимаясь подготовкой данных.
Проект естественным образом распался на три части:
Работали напряженно, но без авралов, без ночных смен, без работы в выходные. Не распивали ни чая ни кофе. Это еще не входило в традицию. К тому же кофе был дефицитом. Да и более-менее приличный чай тоже. Мы были молодые и крепкие. Но босс один раз сломался и с сердечным приступом попал в больницу. А мы немного отдохнули и подтянули “хвосты”. Но босс вызывал нас и в больницу по поводу “Как дела?”.
Программировали на ассемблере. И я не уверен, что на языке высокого уровня было бы быстрее. Создали свой отладчик и начали кодировать и отлаживать. Никаких фреймворков, никаких библиотек. Библиотеки создавали сами. Они были не универсальны, а заточены под проект. Менее чем через год проект заработал. База – файловая БД. Она состоит из базы данных(файлы прямого доступа) и базы знаний(файлы последовательного доступа). База знаний – это формулы расчета показателей, описания всевозможных выборок-фильтров и описание всевозможных группировок выходных данных. Выборки реализовывались как логические функции. Группировки реализовывались как деревья, каждый узел которого связывался с определенной выборкой и определенной функцией агрегации. Все это непрерывно изменялось, пополнялось самими пользователями или с нашей помощью. Автоматизируемая бизнес-функция – генерация динамических аналитических отчетов по задаваемым показателям, фильтрам и группировкам. И вот проект сдали в эксплуатацию. И понеслось. Машина только и штампует отчеты(АЦПУ печатало не посимвольно, а построчно). Были и 100-страничные и больше. Аналитик что-то выискивал в них, вместо того, чтобы поиск доверить машине. А все потому, что онлайн-доступ проект не предоставлял. Не было еще такой возможности. Хотя и теперь, при возможности в любое время задать онлайновый запрос к БД, остались многостраничные отчеты. И используются генераторы отчетов, как инструмент такой штамповки. Я не понимаю зачем они нужны.
А кончилось дело тем, что и постановщика и нашего босса — начальника нашего ВЦ(он руководил проектом) забрали в Москву. Босс и постановщик поучаствовали в разделе госпремии. Мы, разработчики не получили деньгами ничего, но многому научились на проекте. Босс стал еще большим боссом – он возглавил ГВЦ союзного банка. Он стал проталкивать аналогичный проект для всего Союза, но уже с учетом наших проколов. Однако грянули перемены, Промстройбанк уже не занимался стройками, а стал обычным коммерческим банком и проект ТЭПС стал Промстройбанку не нужен.
А постановщик возглавил в перестройку некий Московский банк и в наши командировки в Москву рассказывал перестроечные детективы: как на него наезжала мафия, если он не давал кредиты: угрозы, поджоги, автоаварии. Но это, как говорится, уже совсем другая история.
Слабое место обнаружилось не в кодах, не в БД, а в алгоритме. Недостаточность знаний не позволило нам построить универсальный интерпретатор выражений. И это привело к тому, что проект вышел на вторую реализацию — московскую.
И еще один промах, на мой взгляд. Но с этим не согласился босс. У нас показатель кодировался по такому шаблону: ддссгг, где дд – код документа, сс – строка документа, гг – графа документа. А сам документ представлял собой прямоугольную сетку, в каждой ячейке которого был проставлен код показателя в правом верхнем углу ячейки. Вот пример формулы вычисления производного показателя:

Понятно, что это не способствует ни запоминанию, ни осмыслению, и не представляет основы для расширения знаний. Короче, явно не виден экономический смысл.
Мне казалось разумным ввести мнемонические коды. И тогда вышеприведенная формула приняла бы примерно такой вид:

Но над этим нужно было много поработать и убеждать и руководителя и пользователей-банкиров. Они в то время боялись математики как огня. Не знаю как сейчас.
Итак, главные недочеты имели алгоритмический и психологический, точнее эргономический характер. Архитектура ПО, структура БД, кодирование остались неизменными.
Уроки разработки
Я не знаю, будет ли толк из этих уроков для современных айтишников. Больно далеко уж разошлись дороги айтишников тогда и теперь. Это просто выводы на то время.
Пользователи редко отчетливо представляют, что им нужно. А если представляют, то в сильно завуалированном виде, который нужно еще перелопачивать, трансформировать, фильтровать. Изначально хаос и в голове айтишника. А нужно выделить порядок, отбросить фантазии, структурировать возможное и представить результат понятным и убедительным образом. Иначе говоря, из хаоса нужно выделить реалистичную систему.
Успех проекта зависит от первого лица заказчика. Это один из постулатов Глушкова – классика советской кибернетики. Без непосредственного участия первого лица заказчика проект не был бы реализован.
Успех разработки обеспечивает не столько интеллект, сколько воля руководителя проекта. Иногда он должен сказать, как Королев: “Луна твердая”, и прекратить бесконечные дебаты.
Компетентность идет следом за волей. Здесь проколы также имеют тяжелые последствия. Например, наш дилетантизм не позволил единым образом запрограммировать любую арифметико-строко-логическую функцию над показателями строек. И только когда мы узнали об обратной польской записи, мы поняли свой прокол.
Составные технологического успеха: компетентность, дисциплина, жесткий контроль руководителя, здравый смысл в руководстве и проектировании, фиксация проектных решений и строгое следование им. Никаких жестких формальных рамок каких-либо технологий управления. Мы поневоле придерживались будущего принципа Agile принимать все требования банка – нашего заказчика. Иначе и не могло быть, так как ВЦ был на содержании банка и попробуй откажись. Однако радикальных перемен, инициируемых заказчиком, не было.
По поводу контрольных совещаний я вспоминаю максиму “Cобирая информацию, не проводи совещаний, проводя совещание, не собирай информации”. Один мой босс этим и руководствовался, а второй ровно наоборот.
На совещаниях нужен индивидуальный подход к участникам. Есть олимпиадники, которые быстро схватывают и быстро предлагают решение. Есть антиолимпиадники, которым нужно время на раскачку и время на принятие решения. И это решение может быть и лучше решения олимпиадника. Я, к примеру, никогда не преуспевал на очных олимпиадах, но вполне прилично выступал на заочных. Среди крупных математиков были и олимпиадники и нет, и кого из них больше я не знаю.
Я понял, что на успех проекта влияет не только (а может и не столько) инструментарий, но и широта общего мировоззрения айтишника. Не имея представления о нейроне, не выдумаешь нейронную сеть. Не имея представления о генетике и естественном отборе, не выдумаешь генетический алгоритм. Можно не знать деталей, но поле мышления должно охватывать крупными мазками такие понятия: рекурсия, подпрограмма, сопрограмма, граф, дерево, список, стек, сортировка, паттерн, БД, функция, композиция и декомпозиция функций… Главное — такое мировоззрение должно охватывать предметную область.
От языка программирования далеко не все зависит. Я, кстати, программировал и на Коболе, и на ассемблере (IBM), и на PL/1, и на С, и на Delphi, и на Prologe, и на C# и к своему стыду никогда детально не знал языка, а всегда держал под рукой какой-нибудь учебник(поэтому я не прошел бы сегодня собеседование ни в одну солидную фирму). Это, видимо, замедляло разработку, но зато не обременяло мой ум деталями, оставляя свободное пространство для более широких понятий. Достаточно было того, что я когда-то нагрузил его знанием IBM DOS, а потом нагрянула IBM OS и все мои знания пошли коту под хвост. А как знать PL/1, где целый том был посвящен ошибкам при преобразовании данных? Нужно иметь широкое представление о стратегических вещах. Надо уметь анализировать предметную область, уметь построить удобную реалистичную модель, знать какие есть алгоритмы, построить удобную архитектуру ПО. А язык? — Есть коряво пишущие знатоки русского языка и есть не совсем грамотные хорошие писатели. Самое замечательное знание языка программирования не обеспечивает хорошего программирования.
Шедевры есть на хинди, на греческом, на арамейском, на французском…Можно, конечно, вести бесконечные дебаты о скобках, комментариях, константах, паттернах, зацепленности и расцепленности, подмечать локальные огрехи, а глобальный продукт написать никуда не годный.
Есть еще неформализуемый здравый смысл, который еще нужен в ИТ. Мне встречался разработчик, который детально знал SQL и очень умно рассуждал о нем, но запросы к БД писал ужас, что такое. Локальные отличные знания инструмента и глобальная гармония проекта находятся, по-видимому, на разных полюсах интеллекта. И ещё, я не верю, что полуграмотный в родном языке, способен написать грамотный “роман” на языке программирования. Рассказик – может быть, роман – нет. Я помню в каким нетерпением ждал появления Алгол-68: он позиционировался как язык поэтов программирования. Но не дождался.
А вот что написал Дейкстра о языке программирования в своей книге “Дисциплина программирования”: “Когда начинаешь писать подобную книгу, сразу возникает проблема: каким языком программирования пользоваться? И это не только вопрос представления! Наиболее важным, но в то же время и наиболее незаметным свойством любого инструмента является его влияние на формирование привычек людей, которые имеют обыкновение им пользоваться. Когда этот инструмент — язык программирования, его влияние, независимо от нашего желания, сказывается на нашем способе мышления. Проанализировав в свете этого влияния все известные мне языки программирования, я пришел к выводу, что ни они сами, ни их подмножества не подходят для моих целей. С другой стороны, я считал себя настолько не подготовленным к созданию нового языка программирования, что дал зарок не заниматься этим в ближайшее пятилетие, и я твердо знаю, что этот срок еще не вышел. (Прежде, помимо всего прочего, мне нужно было написать эту монографию.) Я попытался выбраться из этого тупика, создав лишь подходящий для моих целей мини-язык и включив в него только те элементы, которые представляются совершенно необходимыми и достаточно обоснованными»
Он требует не забывать о соседних системах и надсистеме. И, значит, нужно прогнозировать расширение и реализовывать заготовки впрок, так чтобы не пришлось радикально менять проект при его расширении. Заготовки впрок противоречит принципу “не делай ничего впрок”. Именно и делай впрок, если работаешь не на дядю, а на себя.
У рядового разработчика была ничтожная денежная мотивация. Пусть ты в 10 раз производительнее коллеги, а получать будешь на 10% больше его. Поэтому мало кто читал что-то кроме системной документации, а многие и этого не читали, а все приставали с вопросами к знающим. Правда, документации хватало – письменный стол можно было завалить ряда в три книжками документации по матобеспечению ЕС ЭВМ. Но были люди и увлеченные. В том числе и я. Помню до сих пор какое впечатление на меня, дилетанта в программировании, произвели в техническом плане книги “Вычислительные структуры” Холла, первый том Кнута, “Систематическое программирование” Вирта и еще некоторые. А в идейном плане — “Дисциплина программирования” Дейкстры и “Наука программирования” Гриса.
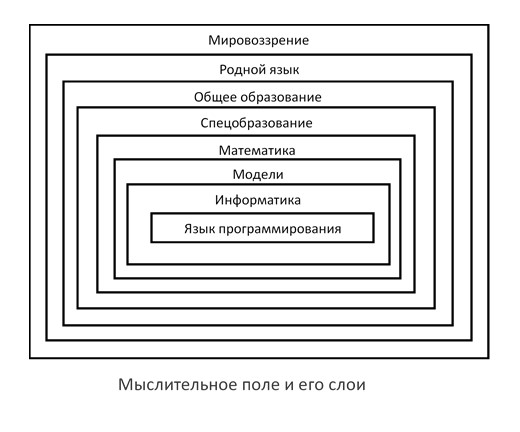
Примеры применения сфер поля мышления айтишника:
Язык программирования. Здесь доминирует формальный подход. Это строгий синтаксис, это фиксированные программные конструкты: выбор, присваивание, циклы, селекторы, итераторы, интерфейсы, объекты, методы. Этот готовые решения в виде библиотек, это заготовки типа “делай как я” – паттерны. Здесь процветает сленг. Но, в поисках вдохновения, программирование требует “заскоков” в вышестоящие слои поля мышления, откуда черпаются идеи. А язык программирования диктует только форму, в которой предстанут эти идеи.
Желательно иметь представление об ассемблере, императивном языке, логическом языке, функциональном языке, SQL, NoSQL. Из процедурных языков я программировал на ассемблере, PL/1, Delphi, C#. Из логических — Prolog. SQL само-собой разумеется. Из функциональных ни одного, хотя я и пришел в ИТ из точных наук и, казалось бы, они должны были заинтересовать меня. И я хоть и стар, мне стало стыдно и я загорелся желанием попробовать или Haskell или F#. А может Idris, о котором я в первый раз услышал в Как развернуть односвязный список на собеседовании. Меня очень впечатлили леммы и теоремы в этой статье.
Информатика. Это теоретические основы для языков программирования. Это узкое мировоззрение айтишника. Понятийные островки: cинтаксис, прагматика, формальные языки, алгоритмы, машина Тьюринга, вычислительные структуры.
Модели. К ним относятся схемы БД, модели UML, модели SADT, HTML, CSS, TCP/IP, семиуровневая модель OSI, формализм Бэкуса-Наура, регулярные выражения.
Математика. Она предоставляет аппарат для точного знания и снабжает универсальными средствами: отношения, множества, функции, формулы, уравнения. Это язык точного рассуждения. Но она представляет не только аппарат для решения задач, но и может прямо влиять на язык программирования. Пример — Haskell и теория категорий в математике. Это весьма привлекательная идея слить статичный язык математики с языком программирования.
Специальное образование. Для меня, например, это – физика. Для кого-то математика. Для профессионала – информатика. А иногда и экономика, менеджмент.
Общее образование. Знакомство с генами и теория естественного отбора естественно приводит к понятию генетического алгоритма. Знакомство с нейрофизиологией мозга приводит к понятию нейронной сети.
Родной язык. Синтаксис обычного языка наводит на мысль о синтаксисе языка программирования. Привычки родного языка влияют на алгоритмическое мышление. Пример приводит Дейкстра в своей книге ”Дисциплина программирования ”, где он отметил различие семитов и несемитов в подходе начинать слева-направо или наоборот. Меня удивляет как мало внимания писатели уделяют внимания синтаксису и обсуждению на каком языке лучше писать. Писатели не жалуются, что синтаксис мешает им творить шедевры, а пишут на английском, немецком, русском… Я встретил только у Набокова (“Дальние берега”) сравнительные рассуждения о писательстве на английском и русском. А немецкий не оставил у него никакого впечатления. Но это Набоков.
А вот программистов, в отличие от писателей, часто заносит в синтаксис и начинаются дебаты об отступах, скобках, дилемма “имена с подчёркиванием или имена стиля CamelCase” и т.п.
Засилие американизмов в жаргоне программистов – это может быть неявное желание расширить поле мышления? Читая на Хабре статьи некоторых современных программистов, я начинаю комплексовать: поминутно лезу в Википедию, чтобы понять сленг. Ну это уже мои проблемы.
Я с грустью замечаю, что русский язык становится от американизмов такой же “трасянкой”, как мой родной белорусский язык стал “трасянкой” от русизмов.
Меня очень поразила фраза Толстого «Если допустить, что жизнь человеческая может управляться разумом, — то уничтожится возможность жизни «(«Война и мир», т.4, Эпилог). Похоже, что это надо очень и очень иметь ввиду политикам. А как это перекликается с квантовой механикой, где подсматривание за процессом, радикально нарушает его течение! А может это аукнется и в программировании, при попытках построить разумных роботов, контролируемых человеком или программой.
Мировоззрение. Это сфера невербального мышления и вербально-философского мышления. Исходя из философии бихевиоризма мы можем сказать: если что-то ведет себя как человек, то это человек. Главное отличие человека от животных — осмысленная речь. Из такого бихевиористического подхода родился тест Тьюринга. Проблема искусственного интеллекта также порождается мировоззрением из размышлений о разуме, интеллекте. Лингвистическая философия с её акцентацией на языки и роль слов ведет к формальным языкам. Герменевтика ставит проблему истолкования текстов программ. И, кто знает, может быть знание идей Кассирера в его труде «Философия символических форм» откликнется и в программировании, или может быть феноменология Гуссерля повлияет на феноменологию программирования. Мне кажется миры программ сильно повлияют на философию, и она станет более конструктивной, обретя в мире программ инструменты проверки своих концепций. И тогда будет явным и обратное влияние.
В формальных языках синтаксис сливается с семантикой слов. А в мировоззрении вообще нет никакого синтаксиса. Неспособность мыслить метафорично (уровень родного языка) лишает наши тексты литературности. Где в программировании эссе, рассказы, повести, романы, стихи и поэмы? Где герменевтика текстов программ? Для меня образец метафоричности в программировании – Дейкстра с его книгой “Дисциплина программирования”. Итак, возможно новыми конструктивными понятиями должны выступить метафоричность, литературность, герменевтика… И тут, я понял, что “Остапа понесло”. Да, я увлекся и, похоже, нарушил другую максиму Витгенштейна: “То, что вообще может быть сказано, должно быть сказано ясно; о том же, что сказать невозможно, следует молчать“.
Математизация
Сначала приведу цитату из Арнольда: “Слово «математика» означает «точное знание». Варварские народы, не склонные к таковому, не имели и соответствующего слова в языке, поэтому сейчас почти во всех языках используется непонятный греческий термин. Исключение составляет лишь голландский язык, где Стевин уже в XVII в. боролся с засорением терминологии иноязычными «сайтами» и «файлами», «баксами» и «киллерами», и настаивал на переводе всех терминов словами родного языка, так что их термин—«вискунде», «знание», приближает уже для детей математику к реальному миру”.
Не потому ли так высок уровень физики, математики, информатики в маленькой Голландии, которая по нобелевским лауреатам обходит Россию, не говоря уже о моей Беларуси, которая по населению сравнима с Голландией, а по территории больше. А может по той же причине и футбол там отличный?
Под математикой я понимаю не только формульное представление. Главное — точные начальные понятия и строгие выводы. Так таблицы БД я понимаю как функции, заданные таблично. Ключ в таблицах – гарантия однозначности функции, нормализация – выделение самых базисных функций из композиции которых можно составлять более сложные (например, view БД).
В связи с математизацией я попробовал в проектах вести понятие внешней и внутренней постановки. Внешняя – для пользователя в терминах предметной области. Внутренняя — для ИТ-шников в терминах информатики и математики. Внутренняя представляет точную трансляцию внешней. Это трансляция представлений пользователя в представления проектировщика и он легко мог переходить к техническому проектированию. Тем самым проектировщик освобождался от детального знания предметной области, а мыслил уже в родных терминах. Но это нововведение было многими встречено в штыки и не прижилось.
Когда я понял важность постановки и её моделирования, я во избежание двусмысленностей всегда старался сделать и математическую модель задачи. А вот в проекте ТЭПС мы узнали на вербальном уровне, что такое конструктивная математическая формула, но не представили ее в формализме Бэкуса-Наура и тем-самым лишились возможности написать универсальный интерпретатор формул.
Исходя из важности математического представления, я приведу далее несколько математических моделей.
Математическая модель бухучета
Модель эта была составлена постфактум для собственного удовольствия, а не для проекта.
Структурные элементы бухучета

Это баланс источников и стоков. Это справедливо для любого момента времени. Значит для любого ∆t:

Из двух последних соотношений следует

Это баланс изменений.
Каждый объект учета может увеличиваться (Uv) или уменьшаться (Um).
Для источников:


Аналогично для стоков:

Баланс изменений примет вид


Договорились говорить об уменьшении источников как о дебете(Dt), а об увеличении как о кредите(Kt).
Для стоков, наоборот: уменьшение – кредит(Kt), увеличение – дебет(Dt). И это логично в силу антиподности источников и стоков.
Тогда


Это баланс дебета и кредита.
Счета, учитывающие источники называются пассивными, а их общий размер называется пассивом. Обозначим его как  .
.
Счета учитывающие стоки называются активными, а их общий размер называется активом. Обозначим его как  .
.
Дебет, кредит, сальдо

Для счета пассивов:


Капитал и основные уравнения бизнеса
Среди счетов актива можно выделить счета на которых учитываются требования фирмы – средства которые мы вправе когда-либо затребовать вернуть. Это выданная ссуда, например. Это деньги в кассе. А вот счет Расходы к требованиям не относится. Дальше, среди счетов пассива можно выделить счета на которых учитываются обязательства фирмы – средства которые мы должны когда-нибудь вернуть. Это полученная ссуда, например. А вот счет Доходы к обязательствам не относится. Обязательства – заемные средства. Но у фирмы есть и собственные средства – капитал фирмы. Размещая заемные средства и собственные средства мы трансформируем их в требования. Это и есть текущая функция бизнеса в абстрактном выражении.
Среди счетов актива можно выделить счета на которых учитываются размещения средств фирмы – средства которые мы куда-то направили с целью получения прибыли. Требования входят в размещения.
Среди счетов пассива можно выделить счета на которых учитываются привлечения бизнесом средств от стороннего бизнеса. Это полученные ссуды – средства которые мы куда-то направили с целью получения прибыли. Обязательства входят в привлечения.

Или более привычно:

Это уравнение состояний
Весь бизнес работает ради прибыли. В учете это отображается так:

Или более привычно

Это уравнение потоков.
Часть прибыли можно капитализировать и тем самым расширить финансовую базу бизнеса.
План счетов
Все множество допустимых счетов, называется планом счетов. Он диктуется государством. План счетов состоит из дерева Пассив и дерева Актив, содержащим соответственно все пассивные и активные счета. Формально можно объединить два дерева в одно, введя вершину “План счетов” и подчинив ей деревья Пассив и Актив.
Разработчик волен расширять дерево плана счетов вниз в своих интересах. Так счет привлеченных депозитов дифференцируется до индивидуальных депозитных счетов. Счет выданных кредитов дифференцируется до индивидуальных ссудных счетов. Расчетный счет дифференцируется до индивидуальных счетов субъектов, ведущих расчеты через банк.
Иногда пользователь заинтересован в двух планах счетов.
Хозяйственные операции

На размер проводки дебет-счет должен дебетоваться, а кредит-счет кредитоваться.
Хозяйственная операция реализуется одной или несколькими проводками. Если дебет-счет и кредит-счет оба пассивны или оба активны, то баланс не меняется. Если дебет-счет активен, а кредит счет пассивен, то баланс увеличивается. Если дебет-счет пассивен, а кредит-счет активен, то баланс уменьшается. Если проводка реализуется только по дебету или только по кредиту, то баланс будет нарушен. Отсюда ясно, что при машинной реализации проводка должна реализовываться как транзакция, иначе баланс будет нарушен. Кстати в англоязычной литературе проводка так и называется “транзакция”.
Отображение хозяйственной операции на проводки – главная задача бухгалтера. Он, в зависимости от хозяйственной операции и экономических характеристик субъектов проводки (плательщик и получатель), должен определить проводки. Иногда здесь возможны варианты и тогда искусство бухгалтера состоит в том, чтобы выбрать проводки выгодные для фирмы бухгалтера.
Баланс Актив=Пассив

И все это должно быть сгруппировано по плану счетов S, так что:

Это баланс активов и пассивов. Он представляет баланс состояний.
Информационная структура в которой приведены все активы и пассивы в разрезе плана счетов называется бухгалтерским балансом. Обычно его приводят в виде двух иерархий: слева на листе баланса иерархия пассива, справа на листе баланса иерархия актива. И завершается эти иерархии общим размером актива и пассива. Эти размеры должны совпадать. Иначе – ошибка.
Баланс Дебет=Кредит

И все это должно быть сгруппировано по платежным документам, или интегрировано до уровня плана счетов(оборотно-сальдовая ведомость).
Это баланс оборотов — баланс потоков.
Расширения учета как применение системного подхода
Системный подход требует не забывать, что проект всегда погружен в надсистему и возможно будет расширен, так что в расширение захватятся некоторые части надсистемы. Так что если такое расширение весьма вероятно, то заранее нужно побеспокоиться об атрибутах, избыточных для данного проекта, но нужных для расширенного проекта. Бухгалтерский учет естественным образом может быть расширен до операционного и управленческого учета, а ещё дальше до бизнес-аналитики в широком смысле.
В той реализации операционного дня в которой я участвовал, с платежного документа вводились только проводки. Для операционного учета нужно вводить и код хозяйственной операции. Кроме того, нужно знать инициатора хозяйственной операции и бухгалтера, определившего проводки.
Для управленческого учета нужно привязать субъектов хозяйственной операции к подразделению фирмы. А также желательно больше знать об экономическом содержании операции. Для этого нужно идентифицировать экономический объект операции: транспорт, здание, компьютер, НДС, …
Экономические показатели
С точки зрения экономики сальдо и обороты счета – это экономические показатели. Тогда естественно спросить, а почему мы должны ими ограничиться, ведь это не вся экономика. Нужна численность работников, уровень инфляции, рыночные ставки и т.д. Кроме того, состояние счета в бухучете – это текущее состояние, а бизнесу нужно и прогнозное значение и детальный анализ прошлого, текущего и прогнозного состояний. Так мы приходим к абстракции экономического показателя. Для примера рассмотрим показатель Гэп в коммерческих банках. Если мы будем иметь на счетах дату прогнозного платежа и ее размер, то мы можем вычислять так называемый гэп.
TrС(t1,t2) – требования срочности (t1,t2) и чувствительные к изменениям процентной ставки. Pr% — процентная прибыль. Тогда
 — это, по определению, гэп срочности (t1,t2)
— это, по определению, гэп срочности (t1,t2)
Гэп – одна из основных характеристик процентного риска и риска ликвидности. Так если изменится рыночная ставка на ∆r, то, как учит экономика, имеем возможный скачок в процентной прибыли:

Это и говорит о важности гэпа как меры процентного риска.
Математическая модель эмпирического риска
Если приведенная выше модель бухгалтерского учета была факультативной в проекте Операционный день, то приводимая ниже была практически необходима.
Эмпирическая вероятность – вероятность, основывающаяся на опытных данных, а не исчисленная по всем правилам теории вероятностей. Обычно для строгого применения теории вероятностей недостаточно данных, а иногда и неясно как ее применить. Так, для коммерческих рисков неясно как применить понятие вероятностного пространства. Поэтому можно попробовать применить некие модельные интуитивные подходы.
Обычно разработчики ПО не выдумывают своей математики, а пользуются готовой. Но иногда необходимо придумывать математическую модель. Для меня это произошло при разработке математической модели оптимального портфеля. Там все размеры депозитов, кредитов должны учитывать риски досрочного снятия депозита и риски невозврата кредита.
Всякая оценка рыночного решения носит вероятностный характер. Всякое решение сопряжено с риском. Само понятие риска – вероятностное понятие. Риск есть вероятность потери определенного ресурса в определенной ситуации. Существуют разные типы рисков для разных операций: риск страны при вложении капитала в эту страну, риск отрасли при вложении капитала в эту отрасль, риск актива при покупке актива, риск клиента при выдаче ссуды клиенту. Здесь мы рассмотрим модель эмпирического риска, т.е. модель, учитывающая реальные размеры проигрыша по рисковому фактору в течение всего времени отслеживания этого фактора.
Композиция рисков
Обычно задаются коэффициентом риска для ссуды определенного вида залога. Так залог под ценные бумаги государства обычно менее рискован чем залог под ценные бумаги частного предприятия. Кроме того, каждый клиент характеризуется своим коэффициентом риска независимо от вида залога.
Стоит задача определить  — интегральный коэффициент риска по клиенту и ссуде совместно, зная
— интегральный коэффициент риска по клиенту и ссуде совместно, зная  — риск по ссуде и
— риск по ссуде и  — риск по клиенту, которому выдается ссуда.
— риск по клиенту, которому выдается ссуда.
Обобщим. Вместо конкретных типов риска введем абстрактный фактор риска. Пусть есть два фактора риска: фактор 1 и фактор 2.Зная риски  ,
,  по каждому фактору нужно найти композитный риск r. Риск по первому фактору — это вероятность события “неуспех по фактору 1”. Риск по второму фактору — это вероятность события “неуспех по фактору 2”. Композитный риск — это вероятность события (неуспех по фактору 1 ИЛИ неуспех по фактору 2). Тогда привлекая теорию вероятностей имеем
по каждому фактору нужно найти композитный риск r. Риск по первому фактору — это вероятность события “неуспех по фактору 1”. Риск по второму фактору — это вероятность события “неуспех по фактору 2”. Композитный риск — это вероятность события (неуспех по фактору 1 ИЛИ неуспех по фактору 2). Тогда привлекая теорию вероятностей имеем

риски не складываются!
И только при общей сумме рисков много меньше единицы риски можно складывать.
Тогда для конкретных рисков по типам ссуд и клиентам имеем

Модели определения ссудного риска по клиенту
В банке не было никаких методик определения риска. Разработчикам нужно было создать собственную методику. Эмпирическая база – кредитная и депозитная история клиента. И нужно найти эмпирическую формулу для риска.
Для эмпирической формулы вероятности представляются естественными следующие содержательные требования:



