Сегментация памяти (Схема памяти компьютера)
Представляю, Вам, перевод статьи одного из разработчиков PHP, в том числе версии 7 и выше, сертифицированного инженера ZendFramework. В данный момент работает в SensioLabs и большую часть занимается низкоуровневыми вещами, в том числе программированием в С под Unix. Оригинал статьи здесь.
Ошибка Сегментации: (Компьютерная верстка памяти)
Несколько слов, о чем эта запись в блоге
Я планирую в будущем писать технические статьи о PHP, связанные с глубоким пониманием памяти. Мне нужно, чтобы мои читатели имели такие знания, которые им помогут понять некоторые концепции дальнейшего объяснения. Для того, чтобы ответить на этот вопрос, нам придется перемотать время назад в 1960-е года. Я собираюсь объяснить вам, как работает компьютер, а точнее, как происходит доступ к памяти в современном компьютере, а затем вы поймете, из-за чего происходит это странное сообщение об ошибке — Segmentation Fault.
То, что вы будете читать здесь, краткое изложение основ дизайна компьютерной архитектуры. Я не буду заходить слишком далеко, если это не нужно, и буду использовать хорошо известные формулировки, так что, кто работает с компьютером каждый день может понять такие важные понятия о том, как работает ПК. Существует много книг о компьютерной архитектуре. Если вы хотите углубиться дальше в этой теме, я предлагаю вам достать некоторые из них и начать читать. Кроме того, откройте исходный код ядра ОС и изучите его, будь то ядро Linux, или любое другое.
Немного истории computer science

8.1 Основные понятия сегментации
Рассмотрим пример, когда программа использует одно адресное пространство.

программа использует одно адресное пространство
Недостатки такой системы:
Один участок может полностью заполниться, но при этом останутся свободные участки. Можно конечно перемещать участки, но это очень сложно.
Эти проблемы можно решить, если дать каждому участку независимое адресное пространство, называемое сегментом.
Рассмотрим то же пример с использованием сегментов:

Каждый сегмент может расти или уменьшаться независимо от других.
В этом случае адрес имеет две части:
Сегменты не мешают друг другу.
Начальный адрес процедуры всегда начинается с (n,0). Что упрощает программирование.
Облегчает совместное использование процедур и данных.
Раздельная защита каждого сегмента (чтение, запись).
8.2 Реализация сегментации
Если страницы имеют фиксированный размер, то сегменты нет.
У сегментов так же, как и у страниц, существует проблема фрагментации.
Т.к. памяти часто не хватает, стали использовать страничную организацию сегментов. При которой в памяти может находиться только часть сегмента.
8.2.1 Сегментация с использованием страниц: MULTICS
Каждая программа обеспечивалась до 2^18 сегментов (более 250 000), каждый из которых мог быть до 65 536 (36-разрядных) слов длиной.
Т.к. записей в таблице более 250 000, она сама разбита на страницы.
Сама таблица является отдельным сегментом.

Сегмент с таблицей дескрипторов указывающих на таблицы страниц для каждого сегмента
Нормальный размер страницы равен 1024 словам. Если сегмент меньше 1024, то он либо не разбит на страницы, либо разбит на страницы по 64 слова.

Когда происходит обращение к памяти, выполняется следующий алгоритм:
По номеру сегмента находится дескриптор сегмента.
Проверяется, находиться ли таблица страницы в памяти. Если в памяти, определяется ее расположение. Если нет, вызывается сегментное прерывание.
Проверяется, находиться ли страница в памяти. Если в памяти, определяется ее расположение в памяти. Если нет в памяти, вызывается страничное прерывание.
К адресу начала страницы прибавляется смещение, в результате получаем адрес нужного слова в оперативной памяти.
Происходит запись или чтение.

Преобразование адреса в системе MULTICS
Так как такой алгоритм будет работать достаточно медленно. Аппаратура системы MULTICS содержит высокоскоростной буфер быстрого преобразования адреса (TLB) размером в 16 слов. Адреса 16 наиболее часто использующихся страниц хранятся в буфере.
8.2.2 Сегментация с использованием страниц: Intel Pentium
Каждая программа обеспечивается до 16К сегментов, каждый из которых может быть до 1 млдр 36-разрядных слов длиной.
Основа виртуальной памяти системы Pentium состоит из двух таблиц:
Каждый селектор (указывает на дескриптор) представляет собой 16-разрядный номер.

Селектор в системе Pentium
13 битов определяют номер записи в таблице дескрипторов, поэтому эти таблицы ограничены, каждая содержит 8К (2^13) сегментных дескрипторов.
1 бит указывает тип используемой таблицы дескрипторов LDT или GDT.

Уровни привилегированности в системе Pentium
Уровни привилегированности запрещают выполняемому коду обратиться к более низкому уровню.

Дескриптор программного (не данных) сегмента в системе Pentium (всего 8 байт (64 бита)).
Если размер сегмента указан в страницах, он может достигать 2^32 байтов (2^20 * 4Кбайт (2^12) (размер страницы в Pentium)).
Алгоритм получение физического адреса:
Селектор загружается в регистр (для сегмента команд в CS, для сегмента данных в DS).
Определяется глобальный или локальный сегмент (LDT или GDT).
Дескриптор извлекается из LDT или GDT, и сохраняется в микропрограммных регистрах.
Если дескриптор в памяти и смещение не выходит за пределы сегмента, программа может продолжить работу, если нет, происходит прерывание.
Система Pentium прибавляет базовый адрес к смещению, и получает линейный адрес,
— если страничная организация памяти не используется, то он является физическим адресом (адрес получен),
— если страничная организация памяти используется, то он является виртуальным адресом.
В случае, если используется страничная организация памяти, линейный адрес переводится в физический с помощью таблицы страниц.

Преобразование пары (селектора, смещение) в физический адрес
При 32-разрядном (2^32=4Гбайт) адресе и 4Кбатной странице, сегмент может содержать 1 млн страниц (4Гбайт/4Кбайта). Поэтому используется двухуровневое отображение (создана таблица (страничный каталог) содержащая список из 1024 таблиц страниц), благодаря чему можно снизить количество записей в таблице страниц до 1024.
В этом случае сегмент в 4 Мбайта (1024 записи по 4 Кбайта страницы), будет иметь страничный каталог только с одной записью (и 1024 в таблице страниц), вместо 1 млн в одной таблице.

Отображение линейного адреса на физический адрес
В системе Pentium также есть буфер быстрого преобразования адреса (TLB), в котором хранятся наиболее часто используемые комбинации Каталог-Страница на физический адрес страничного блока. Только если комбинация в TLB отсутствует, выполняется это алгоритм.
8.3 Особенности реализации в UNIX
В LUNIX системе на 32-разрядной машине каждый процесс получает 3Гбайта виртуального пространства для себя, и 1Гбайт для страничных таблиц и других данных ядра.
На компьютерах Pentium, используется двухуровневые таблицы страниц, и размер страниц фиксирован 4Кбайта
На компьютерах Alpha, используется трехуровневые таблицы страниц, и размер страниц фиксирован 8Кбайт
Для каждой программы выделяется 3 сегмента:
Сегментная организация памяти
Презентацию к данной лекции Вы можете скачать здесь.
Введение
Принципы сегментной организации памяти
рис. 17.1 иллюстрирует данную точку зрения на программу как на набор сегментов в памяти.
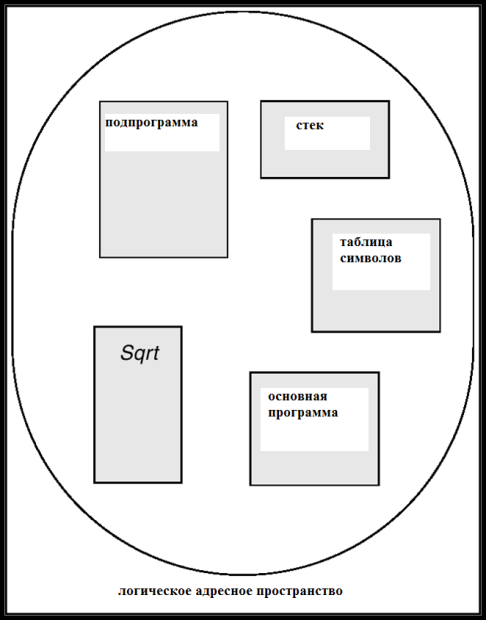
Архитектура сегментной организации памяти
Многие принципы архитектуры сегментной организации схожи с принципами страничной организации (см. «Страничная организация памяти» ), однако во всех случаях приходится учитывать, что длина сегмента переменна, и хранить ее в явном виде в таблицах.
Перемещение ( relocation ) программ и данных при сегментной организации динамическое, т.е. выполняется во время исполнения программы с помощью таблицы сегментов.
Возможен общий доступ (sharing) нескольких процессов к одному и тому же сегменту, т.е. поддерживается концепция разделяемых сегментов. При этом логический номер общего сегмента для разных процессов будет одним и тем же.
Стратегии распределения памяти при сегментной организации: метод первого подходящего или метод наиболее подходящего (см. «Страничная организация памяти» ). Метод наименее подходящего при сегментной организации смысла не имеет, так как он не улучшает ситуацию с фрагментацией (ввиду переменной длины сегментов). Соответственно, при сегментной организации возможна внешняя фрагментация, для борьбы с которой применяется компактировка (см. «Страничная организация памяти» ).
Например, если сегмент является сегментом данных, то система устанавливает в таблице сегментов бит защиты от исполнения равным 0. Если это сегмент кода, то целесообразна установка в 0 битов защиты от чтения и от записи.
Биты защиты связываются с сегментами. Совместный доступ к коду осуществляется на уровне сегментов.
В системе «Эльбрус» к стандартному набору признаков защиты был добавлен еще один: защита от записи в сегмент адресной информации (данный признак целесообразен, если, например, сегмент предназначен для записи в файл ).
Поскольку сегменты различаются по длине, распределение памяти в виде сегментов – это общая задача динамического распределения памяти (см. «Страничная организация памяти» ).
Организация памяти
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Сегмент данных
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес. 
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке: 
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Сегментная адресация памяти
Содержание
Аппаратная реализация
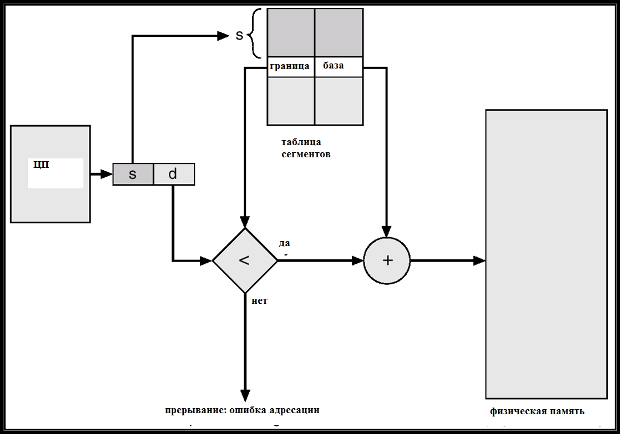
В системе, использующей сегментацию, адреса памяти компьютера состоят из идентификатора сегмента и смещения в сегменте. Аппаратный блок управления памятью (MMU) ответственен за перевод сегмента и смещения в адрес физической памяти, и за выполнение проверок, чтобы удостовериться, что перевод может быть произведен и что ссылка на сегмент и смещение разрешены.
У каждого сегмента есть длина и связанный с ним набор полномочий (например, чтение, запись, выполнение). Процессу позволяют сделать ссылку в сегмент в том случае, если тип ссылки разрешен полномочиями, и если смещение в сегменте находится в диапазоне, определенном длиной сегмента. Иначе возникает ошибка сегментации.
Сегменты могут также использоваться, чтобы реализовать виртуальную память. В этом случае у каждого сегмента есть связанный флаг, указывающий, присутствует ли сегмент в оперативной памяти или нет. Если сегмент, к которому получают доступ, не присутствует в оперативной памяти, выбрасывается исключение, и операционная система считает сегмент в память из внешнего хранилища.
Сегментация была реализована несколькими различными способами на различных аппаратных средствах, с или без разбивки на страницы. Сегментация памяти Intel x86 не соответствует ни одной модели и обсуждена отдельно ниже.
Сегментация без разбиения на страницы
Связанная с каждым сегментом информация, которая указывает, где сегмент расположен в памяти— база сегмента. Когда программа ссылается на ячейку памяти, смещение добавляется к базе, чтобы генерировать адрес физической памяти.
Реализация виртуальной памяти в системе, используя сегментацию без разбивки на страницы требует, чтобы все сегменты перемещались между оперативной памятью и внешней памятью. Когда сегмент загружен, операционная система должна выделить достаточное количество непрерывной свободной памяти, чтобы содержать весь сегмент. Часто результатом фрагментации является невозможность выделить именно непрерывный участок заданной памяти.
Сегментация с разбиением на страницы
Вместо фактической ячейки памяти информация о сегменте включает адрес таблицы страниц для сегмента. Когда программа ссылается на ячейку памяти, смещение переводится в адрес памяти, используя таблицу страниц. Сегмент может быть расширен, просто выделением другой страницы памяти и добавлением ее к таблице страниц сегмента.
Реализация виртуальной памяти в системе, используя сегментацию с разбивкой на страницы обычно только перемещает отдельные страницы назад и вперед между оперативной памятью и внешней памятью, подобно простой страничной реализации адресации памяти. Страницы сегмента могут быть расположены где угодно в оперативной памяти и не должны быть непрерывными. Обыкновенно это приводит к уменьшению ввода/вывода между основной и внешней памятью, а также к уменьшению фрагментации памяти.
Совместное использование сегментов
Сегментирование физической памяти не только не позволяет виртуальной памяти отъедать физическую, но также даёт возможность совместного использования физических сегментов с помощью виртуальных адресных пространств разных процессов.


Если дважды запустить задачу А, то кодовый сегмент у них будет один и тот же: в обеих задачах выполняются одинаковые машинные инструкции. В то же время у каждой задачи будут свои стек и куча, поскольку они оперируют разными наборами данных.
При этом оба процесса не подозревают, что делят с кем-то свою память. Такой подход стал возможен благодаря внедрению битов защиты сегмента (segment protection bits).
Для каждого создаваемого физического сегмента ОС регистрирует значение bounds, которое используется MMU для последующей переадресации. Но в то же время регистрируется и так называемый флаг разрешения (permission flag). Поскольку сам код нельзя модифицировать, то все кодовые сегменты создаются с флагами RX. Это значит, что процесс может загружать эту область памяти для последующего выполнения, но в неё никто не может записывать. Другие два сегмента — куча и стек — имеют флаги RW, то есть процесс может считывать и записывать в эти свои два сегмента, однако код из них выполнять нельзя. Это сделано для обеспечения безопасности, чтобы злоумышленник не мог повредить кучу или стек, внедрив в них свой код для получения root-прав. Так было не всегда, и для высокой эффективности этого решения требуется аппаратная поддержка. В процессорах Intel это называется “NX bit”.
Флаги могут быть изменены в процессе выполнения программы, для этого используется mprotect().
Под Linux все эти сегменты памяти можно посмотреть с помощью утилит /proc/

Здесь есть все необходимые подробности относительно распределения памяти. Адреса виртуальные, отображаются разрешения для каждой области памяти. Каждый совместно используемый объект (.so) размещён в адресном пространстве в виде нескольких частей (обычно код и данные). Кодовые сегменты являются исполняемыми и совместно используются в физической памяти всеми процессами, которые разместили подобный совместно используемый объект в своём адресном пространстве.
Shared Objects — это одно из крупнейших преимуществ Unix- и Linux-систем, обеспечивающее экономию памяти.
Также с помощью системного вызова mmap() можно создавать совместно используемую область, которая преобразуется в совместно используемый физический сегмент. Тогда у каждой области появится индекс s, означающий shared.
Ограничения сегментации
Итак, сегментация позволила решить проблему неиспользуемой виртуальной памяти. Если она не используется, то и не размещается в физической памяти благодаря использованию сегментов, соответствующих именно объёму используемой памяти.
Но это не совсем верно.
Допустим, процесс запросил у кучи 16 Кб. Скорее всего, ОС создаст в физической памяти сегмент соответствующего размера. Если пользователь потом освободит из них 2 Кб, тогда ОС придётся уменьшить размер сегмента до 14 Кб. Но вдруг потом программист запросит у кучи ещё 30 Кб? Тогда предыдущий сегмент нужно увеличить более чем в два раза, а возможно ли это будет сделать? Может быть, его уже окружают другие сегменты, не позволяющие ему увеличиться. Тогда ОС придётся искать свободное место на 30 Кб и перераспределять сегмент.
Главный недостаток сегментов заключается в том, что из-за них физическая память сильно фрагментируется, поскольку сегменты увеличиваются и уменьшаются по мере того, как пользовательские процессы запрашивают и освобождают память. А ОС приходится поддерживать список свободных участков и управлять ими.
Фрагментация может привести к тому, что какой-нибудь процесс запросит такой объём памяти, который будет больше любого из свободных участков. И в этом случае ОС придётся отказать процессу в выделении памяти, даже если суммарный объём свободных областей будет существенно больше.
ОС может попытаться разместить данные компактнее, объединяя все свободные области в один большой чанк, который в дальнейшем можно использовать для нужд новых процессов и перераспределения.
Но подобные алгоритмы оптимизации сильно нагружают процессор, а ведь его мощности нужны для выполнения пользовательских процессов. Если ОС начинает реорганизовывать физическую память, то система становится недоступной.
Так что сегментация памяти влечёт за собой немало проблем, связанных с управлением памятью и многозадачностью.Нужно как-то улучшить возможности сегментации и исправить недостатки. Это достигается с помощью ещё одного подхода — страниц виртуальной памяти.



