Партиционирование таблиц в mySQL
Начиная с версии 5.1 mySQL поддерживает горизонтальное партицирование таблиц. Что это такое? Партиционирование (partitioning) — это разбиение больших таблиц на логические части по выбранным критериям.. На нижнем уровне для myISAM таблиц, это физически разные файлы, по 3 на каждую партицию (описание таблицы, файл индексов, файл данных). Для innoDB таблиц в конфигурации по умолчанию – разные пространства таблиц в файлах innoDB (не забываем, что innoDB позволяет настраивать индивидуальные хранилища на уровне баз данных или даже конкретных таблиц).
CREATE TABLE orders_range (
customer_surname VARCHAR(30),
store_id INT,
salesperson_id INT,
order_date DATE,
note VARCHAR(500)
) ENGINE = MYISAM
PARTITION BY RANGE( YEAR(order_date) ) (
PARTITION p_old VALUES LESS THAN(2008),
PARTITION p_2008 VALUES LESS THAN(2009),
PARTITION p_2009 VALUES LESS THAN(MAXVALUE)
);
Что мы получаем? Первая «таблица» будет хранить данные за «архивный» период, до 2008го года, вторая — за 2008й год, и «третья» — все остальное.
Самое вкусное — запросы при этом совершенно не надо переписывать/оптимизировать:
select * from orders_range where order_date=’2009-08-01′;
И вот что при этом происходит:
Мы видим, что при выполнении этого запроса работа будет идти исключительно с «подтаблицей» p_2008.
Более того, ускорение достигается даже в случае выполнения запросов, затрагивающих все данные во всех партициях — ведь в этом случае сначала происходит первичная «обработка» таблиц по меньше, потом данные объединяются и производятся финальные вычисления. Так вот как раз «первые» этапы, в данном случае будут происходить гораздо быстрее.
Какие еще есть преимущества?
Главным преимуществом я бы назвал тот факт, что партиция с «оперативными» данными (т.е. последними, по которым наиболее часто происходит выборка) имеют минимальный размер, и как следствие, могут постоянно находится в оперативной памяти.
Если у вас есть таблица логов, в которую непрерывно идет запись и жесткие диски не успевают, а ставить рейд вам не позволяет религия, вы можете настроить партиционирование по хеш-функции, и указать по одной партиции на каждый доступный вам жесткий диск. В таком случае, новые данные будут равномерно писаться на все жесткие диски.
Какие способы «разделения» данных предоставляет mySQL?
По диапазону значений
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20),
PARTITION p3 VALUES LESS THAN (30)
);
По точному списку значений
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20)
)
Зачем, спросите вы? Разбивать на партиции необходимо либо исходя из соображений оптимизации выборки (что чаще) либо исходя из соображений оптимизации записи (реже). Соответственно, идеальный вариант — это когда вы разбиваете таблицу на максимально возможное количество партиций так, что бы 90% всех выборок происходило в пределах одной партиции. И если у вас сложная логика выборки (например, объекты расположенные в северных кварталах города, ID которых идут в разнобой) то иногда есть смысл перечислять их принудительно.
PARTITION BY HASH(store_id)
PARTITIONS 4;
Вы никак не управляете партицированием, просто указываете, по какому полю строить хеш и сколько «подтаблиц» создавать. Зачем? Гораздо быстрее происходит выборка по указанному полю. В некоторых случаях позволяет достигнуть «равномерного разброса» и ускорения записи данных.
Почти то же самое что и HASH, но более логично — по ключу.
PARTITION BY KEY(s1)
PARTITIONS 10;
Т.е. выборка по указанному ключевому полю происходит максимально эффективно.
Но тут так же следует определиться со способом партицирования. Хорошо подходит для счетчика посетителей, когда его логин является единственным идентификатором, по которому необходимо выбирать все остальные данные.
Нет вертикального партицирования. Это когда разные столбцы (поля) находятся в разных «подтаблицах». Поскольку иногда это бывает полезно, вы можете достичь этого самостоятельно, пусть даже не так прозрачно: разделить таблицу на две, связав их по первичному ключу. Если вам совсем хочется красоты — можете дополнительно создать по ним VIEW, например для того что бы не переписывать старые части кода.
Зачем это делать? Например, в таблице, где у вас в основном числа и даты, есть одно поле VARCHAR (255) для комментариев, которое используется на порядок реже чем остальные поля. В случае если его вынести в другую таблицу, то мы получим фиксированный размер строки (mySQL сможет совершенно точно вычислять позицию нужной строки по индексу в файле данных). Таблица станет более устойчивой к сбоям в случае внештатных ситуаций (опять же, из-за фиксированного размера строки). Ну и существенно уменьшится сам размер таблицы.
И заканчивая статью приведу пример более «реального» партицирования таблиц — помесячно. Так как LIST/RANGE принимают только целочисленные значения, то надо немного исхитрится:
PARTITION BY RANGE( TO_DAYS(order_date) ) (
PARTITION y2009m1 VALUES LESS THAN( TO_DAYS(‘2009-02-01’) ),
PARTITION y2009m2 VALUES LESS THAN( TO_DAYS(‘2009-03-01’) ),
PARTITION y2009m3 VALUES LESS THAN( TO_DAYS(‘2009-04-01’) )
);
PS: В mysql всегда приходится немного «исхитриться», так что скучно с ней не будет никогда, а мы в свою очередь никогда не останемся без работы 🙂
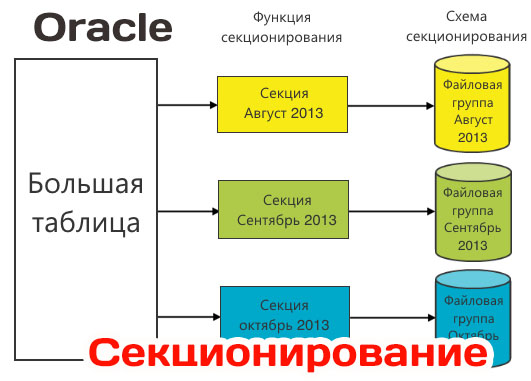
Секционирование таблиц в Oracle на практике

Одним из эффективных способов повышения производительности работы баз данных является секционирование таблиц и индексов. Рассмотрим разные методы секционирования и их особенности
Создание секционированных таблиц в Oracle
В этой части статьи рассматриваются особенности создания секционированных таблиц, в следующей речь пойдет об особенностях перевода существующих больших несекционированчых таблиц в секционированные таблицы, а также особенности секционирования индексов и работа с секциями.
Задачи, решаемые секционированием
Прежде чем приступить к секционированию, надо четко определить задачи, которые предполагается решить
Ключ секционирования
Увидеть, какой столбец в таблице виртуальный позволяет запрос:
Методы секционирования таблиц
Секционирование повышает эффективность работы с таблицами и индексами
Выбранный ключ секционирования, как правило, определяет методы секционирования. В настоящее время имеются следующие методы секционирования таблиц:
Последние три появились в Oracle 11g. вместе с тем последние два у нас пока не нашли большого применения.
Секционирование методом Range по диапазону ключа
В практике секционирования по методу Range используем два вида секционирования: по диапазону дат и по диапазону значений.
Секционирование методом Range по диапазону дат
При секционировании этим методом нами используются секционирование по дням, месяцам и по годам. Секционирование этим методом покажем на примере таблицы HISTLG в схеме AIF. Ключом секционирования выступает столбец updated (дата корректировки строки), при этом секции создаются с шагом секций в один месяц. Команда создания секционированной таблицы create имеет вид:
Увидеть секции таблицы можно по запросу:
А содержимое секции по запросу:
Секционирование методом RANG по диапазону значений
Секционирование по диапазону значений похоже на секционирование по диапазону дат, только вместо ключа по дате используется ключ по столбцу, принимающему числовое значение (желательно имеющее равномерное распределение по всему диапазону значений). Для этого хорошо подходит столбец с уникальным значением. Рассмотрим на примере той же таблицы AIF.HISTLG, секционированной выше по диапазону дат. В качестве ключа секционирования используется столбец ISN с уникальными значениями. Команда создания таблицы имеет вид:
где PARTITION BY RANGE (ISN) говорит о секционировании no RANGE при ключе секционирования ISN, интервал создания секции через 1000 значений.
Создание новой секции в секционированной таблице по методу Range
Каждый раз при создании секционированной таблицы возникает непростой вопрос: как создавать новые секции. До Oracle 11g было три варианта создания новой секции.
Фраза UPDATE GLOBAL INDEXES обеспечивает исправность индексов после команды Split.
Например, в следующем году информация за январь пишется снова в ту же секцию января, что и в прошедшем году. При этом секции чистятся от прошлогодней информации. Преимущество этого метода в том, что не надо создавать новые секции.
В Oracle 11g появилась новая замечательная возможность автоматического создания секций с использованием при создании таблицы фразы INTERVAL (такой подход называется интервальное секционирование Interval Partitioning). Тогда при создании секций методом Range по интервалу дат с использованием фразы Interval команда создания секционированной таблицы примет вид:
где фраза INTERVAL(1000) задает режим автоматического создания секции через 1000 значений ISN.
Таким образом, в Oracle 11g у команды create создания секционированной таблицы существенно меньшее число строк, а о создании новой секции своевременно позаботится Oracle.
Секционирование по списку ключей LIST
Другие стандартные варианты секционирования по методу LIST изложены в различных источниках.
Хеш-секционирование HASH
Следует заметить, что если в качестве ключа секционирования используется столбец, в котором имеем очень неравномерное распределение значения столбца (малая уникальность), то применение хеш-секционирования не целесообразно. При этом число секций не имеет особого значения, поскольку все значения ключевого столбца «свалятся» в одну-две секции.
Замечание. Увидеть размер секций в mb по всем указанным выше методам можно по запросу:
Составное секционирование
Системное секционирование (system partitioning)
Появилось в Oracle 11 g и применяется, как правило, для таблиц, которые не могут быть секционированы никакими другими методами. В этом методе Oracle сам управляет, какую строку таблицы в какую секцию помещать. Для этого метода необходимо просто написать название секций, например, секции Р1, Р2, РЗ:
Увидеть разбиение таблицы на секции можно по запросу:
Замечание. В таблице подвергнуться секционированию может не только сама таблица, но и индексы таблицы. В силу объемности и важности материала о секционировании индексов пойдет речь во второй части. Там же будет рассказано об особенностях перехода от несекционированных больших по объему таблиц к секционированным таблицам, в том числе о возникающих в этих случаях особенностях поведения индексов, триггеров, синонимов и т.д. этих таблиц.
Partitioned Tables and Indexes
SQL Server поддерживает секционирование таблиц и индексов. Данные секционированных таблиц и индексов делятся на блоки, которые могут распределяться между несколькими файловыми группами в базе данных. Данные секционируются горизонтально, поэтому группы строк сопоставляются с отдельными секциями. Все секции одного индекса или таблицы должны находиться в одной и той же базе данных. Таблица или индекс рассматриваются как единая логическая сущность при выполнении над данными запросов или обновлений. До версии SQL Server 2016 (13.x); SP1 секционированные таблицы и индексы были доступны не в каждом выпуске SQL Server. Сведения о функциях, поддерживаемых различными выпусками SQL Server, см. в статье Возможности, поддерживаемые различными выпусками SQL Server 2016.
SQL Server поддерживает по умолчанию до 15 000 секций. В версиях, предшествующих SQL Server 2012 (11.x), количество секций по умолчанию было равно 1000.
Преимущества секционирования
Секционирование больших таблиц или индексов может дать следующие преимущества в управляемости и производительности.
Это позволяет быстро и эффективно переносить подмножества данных и обращаться к ним, сохраняя при этом целостность набора данных. Например, такая операция, как загрузка данных из OLTP в систему OLAP, выполняется за секунды, а не за минуты и часы, как в случае несекционированных данных.
Операции обслуживания можно выполнять быстрее с одной или несколькими секциями. Операции более эффективны, так как выполняются только с поднаборами данных, а не со всей таблицей. Например, можно сжать данные в одну или несколько секций или перестроить одну или несколько секций индекса.
Можно повысить скорость выполнения запросов в зависимости от запросов, которые часто выполняются в вашей конфигурации оборудования. Например, оптимизатор запросов может быстрее выполнять запросы на эквисоединение двух и более секционированных таблиц, если столбцы секционирования те же, что и столбцы для объединения таблиц. См. подробнее о запросах.
В процессе сортировки данных для операций ввода-вывода в SQL Server сначала проводится сортировка данных по секциям. Для ускорения сортировки данных рекомендуется распределить файлы данных в секциях по нескольким жестким дискам, создав RAID. Таким образом, несмотря на сортировку данных по секциям, SQL Server сможет одновременно осуществлять доступ ко всем жестким дискам каждой секции.
Кроме того, можно повысить производительность, применяя блокировки на уровне секций, а не всей таблицы. Это может уменьшить количество конфликтов блокировок для таблицы. Чтобы снизить состязание блокировок с помощью применения укрупнения блокировок к секциям, задайте для параметра LOCK_ESCALATION инструкции ALTER TABLE значение AUTO.
Секции таблицы или индекса можно разместить в одной ( PRIMARY ) или нескольких файловых группах. При работе с многоуровневым хранилищем использование нескольких файловых групп позволяет назначать определенные секции определенным уровням хранилища. Все прочие преимущества секционирования применяются независимо от количества используемых файловых групп или размещения секций в определенных файловых группах.
Компоненты и основные понятия
Следующие термины относятся к секционированию таблиц и индексов.
Функция секционирования
Схема секционирования
Объект базы данных, который сопоставляет секции функции секционирования набору файловых групп. Главная причина, по которой секции разделяются по разным файловым группам, заключается в необходимости независимого резервного копирования этих секций, поскольку оно всегда выполняется отдельно для каждой из файловых групп.
В База данных SQL Azure поддерживаются только первичные файловые группы.
Столбец секционирования
Выровненный индекс
Индекс, созданный на основе той же схемы секционирования, что и соответствующая таблица. Когда таблица и ее индексы выровнены, SQL Server может при обслуживании структуры секционирования как таблицы, так и индексов быстро и эффективно переключать секции. Для выравнивания с базовой таблицей индексу необязательно использовать функцию секционирования с тем же именем. Тем не менее функции секционирования индекса и базовой таблицы не должны существенно различаться, то есть:
Секционирование кластеризованных индексов
При секционировании кластеризованного индекса столбец секционирования должен содержаться в ключе кластеризации. При секционировании неуникального кластеризованного индекса, если столбец секционирования не указан явно в ключе кластеризации, SQL Server по умолчанию добавляет столбец секционирования в список ключей кластеризованного индекса. Если кластеризованный индекс является уникальным, для него следует явным образом задать наличие столбца секционирования в ключе кластеризованного индекса. Дополнительные сведения о кластеризованных индексах и архитектуре индексов см. в разделе Правила проектирования кластеризованного индекса.
Секционирование некластеризованных индексов
При секционировании уникального некластеризованного индекса столбец секционирования должен содержаться в ключе индекса. При секционировании неуникального некластеризованного индекса SQL Server по умолчанию добавляет столбец секционирования как неключевой (включенный) столбец индекса, чтобы обеспечить выравнивание индекса с базовой таблицей. Если столбец секционирования уже присутствует в индексе, SQL Server его не добавляет. Дополнительные сведения о некластеризованных индексах и архитектуре индексов см. в разделе Рекомендации по созданию некластеризованных индексов.
Невыровненный индекс
Индекс, секционированный независимо от соответствующей таблицы. Т. е. индекс имеет другую схему секционирования или находится не в той файловой группе, где находится базовая таблица. Создание невыровненного секционированного индекса может быть полезно в следующих случаях:
Устранение секций
Процесс, в ходе которого оптимизатор запросов обращается только к определенным секциям в соответствии с фильтром запроса.
Рекомендации по производительности
Более высокое новое максимальное количество секций (15 000) влияет на память, операции с секционированными индексами, команды DBCC и запросы. В этом разделе показано, как влияет на производительность создание более 1 000 секций и как обойти проблемы. Увеличение максимального количества секций до 15 000 позволяет дольше хранить данные. Однако рекомендуется хранить данные ровно столько времени, сколько требуется, и поддерживать баланс между производительностью и количеством секций.
Рекомендации относительно процессорных ядер и числа секций
Чтобы добиться максимальной производительности с помощью параллельных операций, рекомендуется, чтобы число секций и процессорных ядер совпадало, но не превышало 64 (это максимальное число параллельных процессоров, которые SQL Server может использовать).
Использование памяти и рекомендации
При большом количестве используемых секций рекомендуется использовать ОЗУ не менее 16 ГБ. Если у системы недостаточно памяти, возможен сбой инструкций языка обработки данных (DML), инструкций языка описания данных (DDL) и других операций из-за нехватки памяти. В системах с ОЗУ 16 ГБ и большим количеством процессов, интенсивно использующих память, возможны сбои операций, работающих на большом количестве секций, из-за нехватки памяти. Поэтому чем больше у вас памяти сверх 16 МБ, тем меньше вероятность проблем с производительностью и памятью.
Ограничения оперативной памяти могут повлиять на производительность SQL Server при построении секционированного индекса и даже на саму возможность его построения. Такое случается, например, когда индекс не выровнен со своей базовой таблицей или со своим кластеризованным индексом, если такой существует в таблице. В этом случае может оказаться полезным увеличить параметр конфигурации сервера index create memory. Дополнительные сведения см. в статье Настройка параметра конфигурации сервера index create memory.
Операции с секционированными индексами
Создание и перестройка невыровненных индексов для таблицы, количество секций в которой превышает 1000, возможны, но не поддерживаются. Это может привести к снижению производительности или чрезмерному потреблению памяти во время таких операций.
Создание и перестройка выровненных индексов может занимать больше времени по мере увеличения количества секций. Не рекомендуется выполнять одновременно несколько команд создания и перестройки индекса, так как возможны проблемы с производительностью и памятью.
При сортировке, выполняемой при построении секционированных индексов, SQL Server сначала создает для каждой секции по одной таблице сортировки. Затем либо в соответствующей файловой группе каждой секции, либо в tempdb, если задан параметр индекса SORT_IN_TEMPDB, производится построение таблиц сортировки. Для всех таблиц сортировки требуется минимальный объем оперативной памяти. При построении секционированного индекса, выровненного со своей базовой таблицей, таблицы сортировки создаются по одной за раз, экономно расходуя оперативную память. Однако при построении невыровненного секционированного индекса таблицы сортировки создаются одновременно. В результате необходим достаточный объем оперативной памяти, чтобы параллельно их обрабатывать. Чем больше число секций, тем больше требуется оперативной памяти. Для каждой из секций размер таблицы сортировки составляет не менее 40 страниц, по 8 килобайт каждая. Например, для невыровненного секционированного индекса, разбитого на 100 секций, потребуется объем оперативной памяти для одновременной сортировки 4 000 страниц (40*100). Если такой объем памяти доступен, операция создания будет выполнена успешно, но может пострадать производительность. Если же такой объем памяти недоступен, операция построения завершится ошибкой. Для выровненного секционированного индекса, разбитого на 100 секций, для сортировки потребуется всего 40 страниц, поскольку сортировки осуществляются не одновременно.
Как для выровненных, так и для невыровненных индексов может потребоваться больший объем оперативной памяти, если SQL Server применяет степени параллелизма для выполнения данной операции на многопроцессорном компьютере. Чем больше степень параллелизма, тем больше требуется оперативной памяти. Например, если для SQL Server определена степень параллелизма 4, то невыровненному секционированному индексу, содержащему 100 секций, потребуется такой объем памяти, чтобы четыре процессора могли одновременно отсортировать по 4 000 страниц, то есть 16 000 страниц. Если секционированный индекс выровнен, требования оперативной памяти снижаются до 40 страниц для каждого из четырех процессоров, то есть 160 страниц (4*40). С помощью параметра индекса MAXDOP можно вручную снизить степень параллелизма.
Команды DBCC
При большем количестве секций выполнение команд DBCC может занимать больше времени по мере увеличения количества секций.
Запросы
Запросы, использующие функцию устранения секций, могут иметь сопоставимую или более высокую производительность с большим числом секций. Запросы, не использующие функцию устранения секций, могут занимать больше времени по мере увеличения количества секций.
Запросы, в которых используются такие операторы, как TOP или MAX/MIN, в столбцах, отличных от столбца секционирования, могут столкнуться со снижением производительности при секционировании, поскольку вычисляться должны все секции.
При частом выполнении запросов на эквивалентное соединение двух и более секционированных таблиц, их секционированные столбцы должны совпадать со столбцами, по которым производится соединение. Дополнительно: таблицы или их индексы должны быть упорядочены. Это означает, что в них используется либо общая именованная функция секционирования, либо разные, но дающие одинаковый результат. То есть:
Дополнительные сведения об обработке секций при обработке запросов см. в статье Секционированные таблицы и индексы.
Изменения в поведении при статистических вычислениях во время операций с секционированным индексом
Связанные задачи
| Задания | Раздел |
|---|---|
| Описано, как создать функции секционирования и схемы секционирования и применить их к таблице или индексу. | Создание секционированных таблиц и индексов |
См. также
Следующие публикации по стратегиям секционированных таблиц и индексов и примеры внедрения могут оказаться полезными.
Масштабирование производительности PostgreSQL с помощью партицирования таблиц
Классический сценарий

Вы работаете над проектом, где транзакционные данные хранятся в базе данных. Затем вы развёртываете приложение в рабочей среде, и производительность великолепна! Запросы проходят шустро, и задержка при их вводе практически незаметна. Через несколько дней/недель/месяцев база данных становится всё больше и больше, и скорость запросов замедляется.
Есть несколько подходов, с помощью которых можно ускорить работу вашего приложения и базы данных.
Администратор базы данных (DBA) посмотрит и проследит, чтобы база данных была оптимально настроена. Он предложит добавить определённые индексы, убрать логирование на отдельную партицию, подправить параметры движка базы данных и убедиться, что база данных здорова. Можно также добавить выделенных IOPS (Input/Output Operations Per second) на EBS диске, чтобы увеличить скорость дисковых партиций. Это даст вам выиграть время и даст возможность решить главную проблему.
Рано или поздно вы поймёте, что данные в вашей базе данных являются узким местом (botleneck).
В базах данных многих приложений важность информации уменьшается со временем. Если вы сможете придумать способ избавиться от этой информации, ваши запросы будут проходить быстрее, время создания бэкапов уменьшится, и вы сэкономите кучу места. Вы можете удалить эту информацию, однако тогда она пропадёт безвозвратно. Вы можете послать множество DELETE запросов, вызвав создание тонн логов, и использовать кучу ресурсов движка базы данных. Так как же мы избавимся от старой информации эффективно, но не потеряв её навсегда?
В примерах мы будем использовать PostgreSQL 9.2 на Engine Yard. Вам также нужен git для установки plsh.
Партицирование таблиц
Партицирование таблиц является хорошим решением этой проблемы. Возьмите одну гигантскую таблицу и разбейте её на кучу маленьких — эти маленькие таблицы называются партициями и дочерними таблицами (child object). Такие действия, как создание бэкапов, операции SELECT и DELETE, могут быть произведены с индивидуальными или всеми партициями. Партиции также могут быть удалены или экспортированы единичным запросом, что сведёт логирование к минимуму.
Терминология
Начнём с терминологии, которая будет использоваться в этой статье.
Master Table (Главная таблица)
Также именуемая Master Partition Table, это шаблон, по которому создаются дочерние таблицы. Это обычная таблица, но она не хранит никакой информации и нуждается в триггере (об этом позже). Тип отношений между главной и дочерними таблицами является один-к-многим (one-to-many), то есть есть одна главная таблица и множество дочерних.
Дочерняя таблица (Child Table)
Эти таблицы наследуют свою структуру (или другими словами, свой язык описания данных — Data Definition Language или DDL) от главной таблицы и принадлежат одной главной таблице. Именно в дочерних таблицах хранятся все данные. Эти таблицы часто называют партиционными таблицами.
Partition Function
Partition function является хранимой процедурой, которая определяет, какая из дочерних таблиц примет новую запись. Главная таблица содержит триггер, который вызывает функцию партицирования. Есть две методологии для маршрутизации записей к дочерним таблицам:
По значениям данных – примером этого является дата заказа покупки. Когда заказы покупок поступают в главную таблицу, эта функция вызывается триггером. Если вы создаёте партиции по дням, каждая дочерняя партиция будет представлять все заказы пришедшие в определённый день. Этот метод описывается в этой статье.
По фиксированным значениям – примером этого является географическое положение, такое, как штаты. В этом случае, у вас может быть 50 дочерних таблиц, по одной для каждого штата США. Когда запросы INSERT поступают в главную таблицу, функция сортирует каждый новый ряд в одну из дочерних таблиц. Эта методология не описывается в этой статье, так как не поможет нам избавиться от старых данных.
Пора настроить эти партиции
Допущения (Conventions)
Команды выполняемые из под shell, root пользователем имеют следующий префикс:
Команды выполняемые из под shell, non-root пользователем, например postgres, имеют следующий префикс:
Команды выполняемые внутри PostgreSQL базы данных будут выглядеть следующим образом:
Что вам потребуется
В примерах мы будем использовать PostgreSQL 9.2 на Engine Yard. Вам также нужен git для установки plsh.
Резюме
Cоздание главной таблицы
Для этого примера мы создадим таблицу для хранения базовой информации о производительности (cpu, memory, disk) группы серверов (server_id) каждую минуту (time).
Обратите внимание, имя time заключено в кавычки. Это необходимо, потому что time это ключевое слово в PostgreSQL. Больше о ключевых словах Date/Time и их функции вы можете узнать из документации PostgreSQL.
Создаём функцию триггера
Создание триггера для таблицы
Когда функция партиции создана, в главную таблицу нужно добавить триггер ввода. Он будет вызывать функцию партиции, когда будут поступать новые записи.
Теперь вы можете слать строки главной таблице и наблюдать, как они будут помещаться в соответствующие дочерние таблицы.
Создание функции обслуживания партиции
Функция, которую вы видите ниже, тоже является обобщающей и позволяет вам передать имя таблицы, которую вы хотите экспортировать в ОС, и имя
сжатого файла, который будет содержать эту таблицу.
Обратите внимание, что код сверху использует расширение языка plsh что объясняется ниже. Также следует отметить, что в нашей системе bash находится в /bin/bash.
Интересно, не правда ли?
Настройка PostgreSQL и OS
Включение PLSH в PostgreSQL
Расширение PLSH необходимо в PostgreSQL для запуска shell команд. Оно используется в myschema.export_partition(text,text) для того, чтобы динамически создавать shell строки для запуска pg_dump. Из под root, запустите следующие команды
Создайте папку
Проследите за тем, чтобы postgres пользователю принадлежала папка, и чтобы группа deployment пользователя имела доступ для чтения этих файлов. Пользователь для развёртывания по умолчанию в Engine Yard Cloud является пользователь ‘deploy’.
Больше информации о PL/SH вы можете найти в документации проекта plsh.
Планирование обслуживания партиции
Команда ниже запланирует запуск partition_maintenance каждый день в полночь
Просмотрите cron jobs для пользователя postgres, чтобы убедиться, что crontab строка верна:
0 0 * * * /home/postgres/bin/pg_jobs/myschema_partition_maintenance
Убедитесь в том, что сделана резервная копия папки /db/partition_dump, если вы не пользуетесь инстансом на Engine Yard Cloud. Если вам опять потребуется эта информация, вам будут нужны эти файлы для восстановления старых партиций. Это можно сделать с помощью rsyncing (копирования) этих файлов на другой сервер для пущей уверенности. Мы считаем, что для такого архивирования отлично подходит S3.
Итак, мы запланировали, что обслуживание вашей главной таблицы будет совершаться в определённое время, и вы можете расслабиться, зная, что вы сделали что-то особенное: проворную базу данных, которая сама будет придерживаться диеты!
Загружаем старые партиции
Если вас томит разлука по старым данным, или может быть запрос на комплаенс-контроль очутился на вашем рабочем столе, вы всё еще можете загрузить старые партиции из системных файлов.
Для этого мы направимся к папке /db/partition_dump на вашем локальном db сервере и идентифицируем нужный файл. Затем пользователь postgres импортирует этот файл в базу данных.
После того, как файл загружен, к нему опять можно слать запросы из главной таблицы. Не забывайте о том, что в следующий раз когда планировщик запустит обработку партиции, эта старая партиция опять будет экспортирована.
Посмотрим это в работе
Создание дочерних таблиц
Загрузим две строки с информацией, чтобы посмотреть на новую дочернюю партицию в действии. Откройте psql сессию и запустите следующую команду:
Так что же произошло? Предполагая, что вы в первый раз запустили это, две дочерние таблицы были созданы. Смотрите комментарии в sql сообщении по поводу создания дочерних таблиц. Первый insert можно увидеть, выбирая из главной или из дочерней таблицы:
Заметьте, что мы используем двойные кавычки вокруг имени таблицы дочерней партиции. Мы делаем это не потому, что это унаследованная таблица, а из-за дефиса, использованного между год-месяц-день.
Запускаем обслуживание таблиц
Двум строкам, которые мы внесли более 15 дней. После ручного запуска обслуживания партиции (как было бы запущено через cron) две партиции будут экспортированы в ОС, и эти партиции будут опущены (dropped).
postgres$ /home/postgres/bin/pg_jobs/myschema_partition_maintenance
После завершения мы сможем увидеть два экспортированных файла:
При попытке выбрать в главной таблице вернёт вам 0 строк, так что две дочерние таблицы больше не существуют.
Загрузка старых партиций
если вы захотите загрузить старые дочерние таблицы, то сначала gunzip, а затем загрузка с помощью psql:
Если послать select главной таблице, результатом будет 1 строка — дочерняя таблица восстановлена.
Заметки
Наши файлы базы данных находятся на партиции на /db которая отделена от нашей root (‘/’) партиции.
Для дальнейшего ознакомления с PostgreSQL расширениями почитайте следующую документацию.
Движок базы данных не вернёт правильное количество строк затронутых таблиц (всегда 0 затронутых таблиц) после отправки INSERT или UPDATE в главную таблицу. Если вы используете Ruby, не забудьте подправить код, учитывая, что pg джем не будет правильно отображать правильные значения при отчётностях cmd_tuples. Если вы используете ORM, тогда, будем надеяться, они подправят это соответствующим образом.
Не забудьте сделать резервные копии экспортированных партиций в /db/partition_dump, эти файлы лежат вне стандартного пути создания бэкапов базы данных.
Пользователь базы данных, который осуществляет INSERT в главную таблицу, также должен иметь DDL права для создания дочерних таблиц.
При осуществлении INSERT в главную таблицу будет заметно небольшое изменение производительности, так как будет запущена функция триггера.
Проследите за тем, чтобы использовать последнюю версию PostgreSQL. Это гарантирует, что вы работаете с самой стабильной и безопасной версией.
Это решение работает для моей ситуации, ваши требования могут быть другими, так что не стесняйтесь изменять, дополнять, калечить, истерически смеяться или копировать это для своих целей.



